
法律硕士的 "出现 "是一种幻觉吗?
三个要点
✔️ 验证了在大规模语言模型中观察到的涌现现象
✔️ 提出,LLM 中的涌现现象可能是评价指标呈现的假象
✔️ 在非 LLM 模型中使用特定评价指标,成功地再现了故意不实际出现的涌现现象
Are Emergent Abilities of Large Language Models a Mirage?
written by Rylan Schaeffer, Brando Miranda, Sanmi Koyejo
(Submitted on 28 Apr 2023 (v1), last revised 22 May 2023 (this version, v2))
Comments: Published on arxiv.
Subjects: Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
新出现指的是,当大量元素组合在一起时,会出现在单个元素中无法看到的效果和现象。在最近的大规模语言模型(LLMs)中,即预先训练好的具有大量参数的变换器解码器(如 GPT)中,许多研究发现,增加参数数量可以解决较小模型中无法解决的任务,或者精确度显著提高。研究发现,随着参数数量的增加,变压器能够解决较小模型中无法解决的任务,而且精度也会显著提高。这些现象通常表现为当参数数增加时,得分突然增加,在图表中,横轴为对数刻度的参数数,纵轴为特定任务的评价指标得分(见下图)。
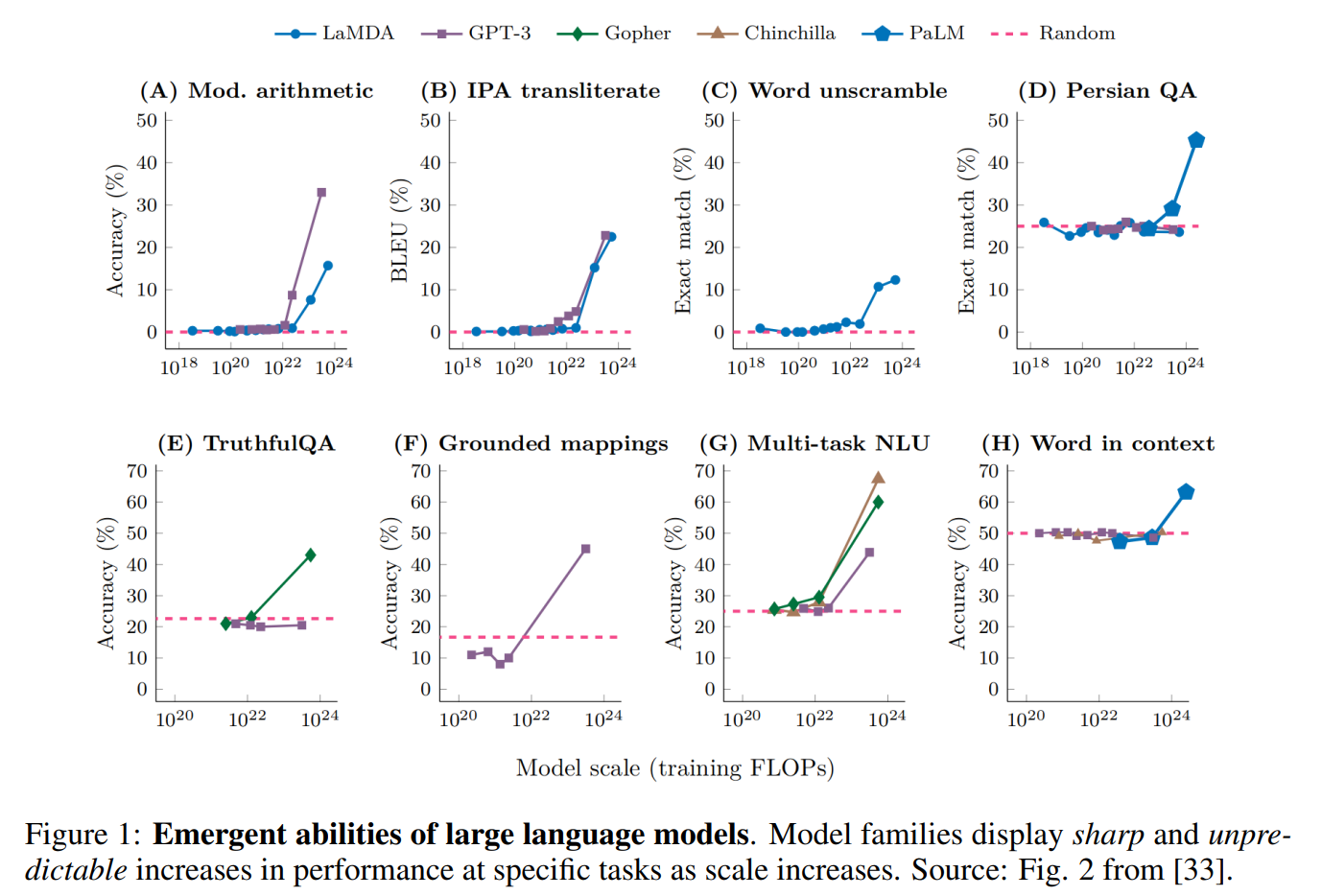
然而,本文认为,法学硕士的 "出现 "是通过研究者人为选择的评价指标看到的 "幻影"。本文就是其中之一
出现的真正本质
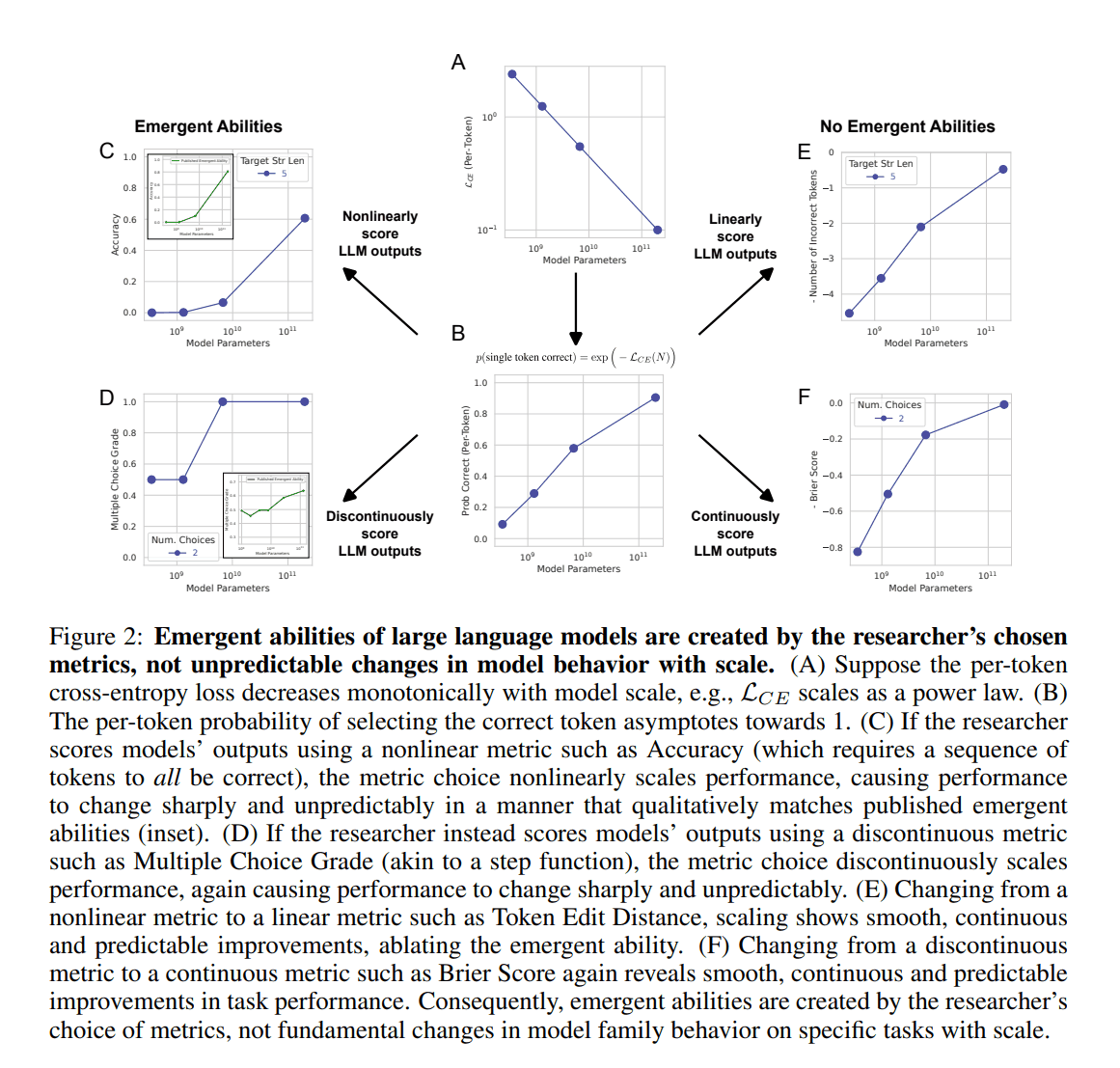
首先,解释模型中参数数量与预测精度之间的关系。一般来说,众所周知,随着参数数量的增加,测试数据的损失也会减少。这就是所谓的缩放定律。假设参数数为 $N$,常数为 $c>0,且 α < 0$,则参数与性能之间的关系可表示如下。
$$mathcal{L}_{CE}(N) = \left(\frac{N}{c} \right)^\alpha$$
CE 是交叉熵,通常用作损失函数。换句话说,这个等式表示参数数量越多,损失越小(见图 2-A)。
假设 $V$ 是假定词汇(标记)的集合,$p(v) \ in \Delta^{|V|-1}$ 是标记 $v$ 的未知真实概率,$what{p}_N(v) \ in \Delta^{|V|-1}$ 是预测概率,则每个标记的交叉熵为每个标记的交叉熵可表述如下
$$mathcal{L}_{CE}(N) = - \sum_{v \in V} p(v)\mathrm{log} \, \hat{p}N(v)$$
但实际上,在大多数情况下,词集的真实概率分布并不为人所知,因此我们使用经验观察到的词块 $v^*$ 的单次分布来对其进行近似,如下所示。
$$\mathcal{L}_{CE}(N) = -\mathrm{log} \, \hat{p}N(v^*)$$
基于上述,每个标记的预测正确概率可表示如下(见图 2-B)。
$$p(\text{single token correct}) = \exp(-\mathcal{L}_{CE}(N)) = \exp(-(N/c)\^alpha)$$
考虑衡量每一系列输出标记是否与正确答案完全一致,例如衡量 $L$ 位整数加法的解是否正确。当每个输出标记被视为独立时,模型的 $L$ 长度预测正确的概率(正确率)为
$$operatorname{Accuracy}(N) \approx p_N(\text{single token correct})^{text{num. of token}} = \exp \left(-(N/c)^alpha \right)^L$$
该指标的性能随着序列长度的增加而非线性增加(见图 2C)。将其绘制在对数刻度图上,会出现尖锐的 "浮现"。现在,让我们改用线性评价指标,例如下式中的 "标记编辑距离"。
$$operatorname{Token Edit Distance}(N) \approx L(1-p_N(\text{single token correct})) = L(1-\exp(-(N/c)^\alpha))$$
如图 2E 所示,在这种情况下,成绩出现了平滑而持续的增长。同样,如果用连续的指标(如布赖尔得分(图 2F))代替不连续的指标(如多项选择成绩(图 2D)),"突现 "现象就会消失。
作者总结了出现的三个原因
- 研究人员使用非线性或不连续的评价指标。
- 实验中使用的模型(参数变化)数量不足
- 测试数据不足。
具体来说,1.出现是某些评价指标所显示的假象;2.在结果图的横轴上,可以通过更详细地为每个参数准备一个模型来进行评价,从而避免精度的快速变化;3.在结果图的纵轴上,可以通过增加测试数据和进行更精细的评价来消除性能停滞在 0 左右的情况。通过增加测试数据和进行更精细的评估,可以消除 0 附近的性能停滞现象。
对观察到的出现情况进行分析
例如,本节将分析现有 LLMs 计算任务中出现的评价指标发生变化时的结果变化。
在实验过程中,根据上述三个与萌发有关的因素提出了以下假设
- 当评价指标从非线性和不连续变为线性和连续时,新兴现象就会消失。
- 即使采用非线性评估指标,增加测试数据和执行更高分辨率的评估也会导致性能的(可能)线性提升。
- 无论采用哪种评估指标,加长要预测的词块都会对性能变化产生重大影响(准确度呈几何级数变化,词块编辑距离呈线性变化)。
使用的模型是 InstructGPT 和 GPT-3。计算问题要求对两位数之间的乘法和四位数之间的加法进行两次预测。
按评价指标分列的 "消失的出现"
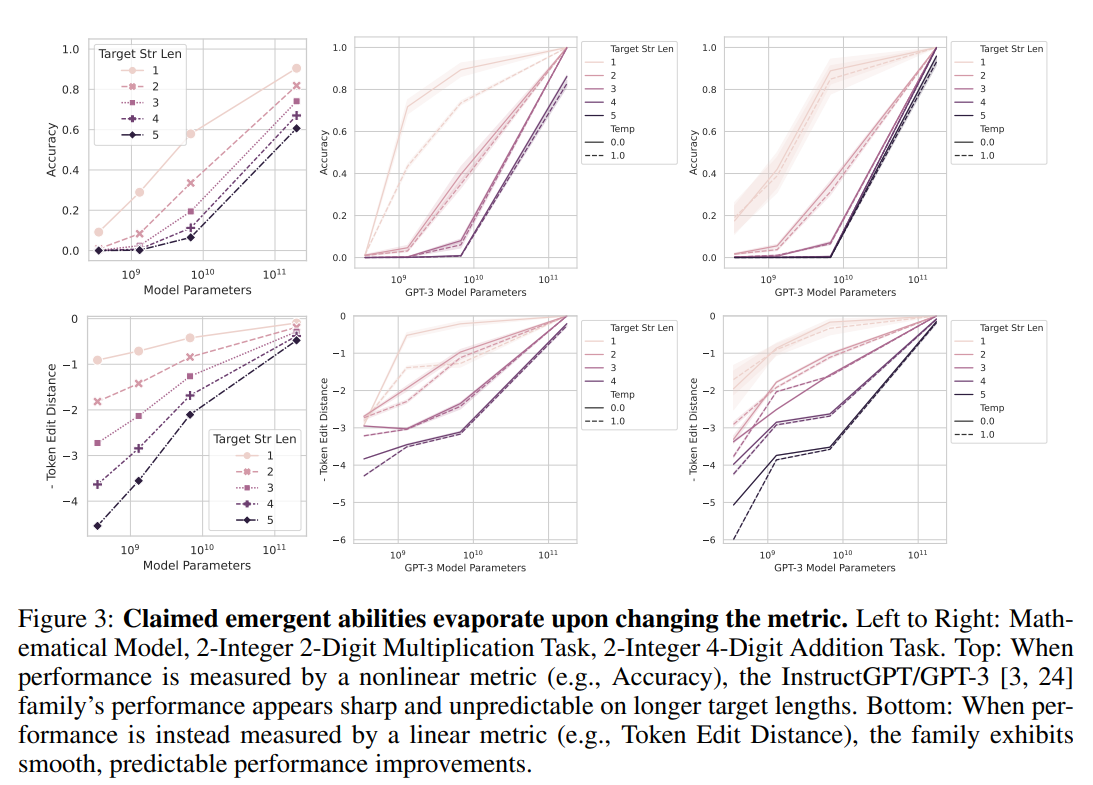
第一个假设的实验结果如上图 3 所示。当评价指标为准确率(答案完全一致)时(图的上半部分),我们可以看到性能在参数 $10^{10}$ 附近迅速上升。另一方面,当评价指标改为代币编辑距离时(图的下半部分),"准确度 "的性能变化消失了,出现了平滑的性能变化。
通过逐个参数的详细评估来确定新出现的物种灭绝情况
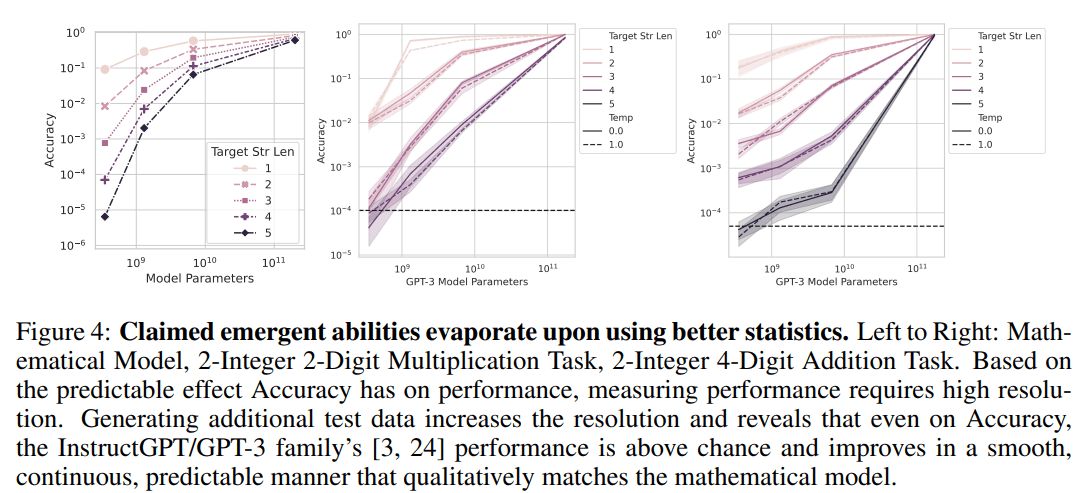
为了验证第二个假设,图 4 显示了上述假设在测试数据上的实验结果。通过增加测试数据,可以计算出更精细(更小)的精度值。
在图 3 的上半部分,小模型似乎长时间停留在 0,看起来似乎没有能力回答相关任务。然而,通过增加测试数据并将准确度计算到更小的值,可以看出实际上并不缺乏响应能力,而且随着参数的增加,性能也会相应提高。
在证实第三个假设的实验中,似乎观察到随着目标标记长度的增加,性能随准确率呈几何级数下降,随标记编辑距离呈线性下降,但论文中没有提供图表或其他信息。
对宣称的新兴能力进行元分析
由于各种限制,到目前为止,我们只使用 GPT-3.5/4 进行了实验。为了证明突发幻觉并非只在特定模型中才能观察到,而是取决于一系列指标,我们测试了常用于评估 LLM 的 BIG-bench 指标中每个指标的幻觉程度。
幻现得分是对特定指标产生幻现可能性的衡量。让$y_i$成为模型尺度$x_i \; (x_i < x_{i+1})$下相关评价指标的值,定义如下。
$$
\operatorname{Emergence Score} \left(\left\{(x_n, y_n)\right}_{n=1}^N \right) = \frac{\operatorname{sign}(\mathrm{argmax}_i y_i -\mathrm{argmin}_i y_i(\mathrm{max_i}y_i -\mathrm{min}_i)}{sqrt\{Emergence Score} }mathrm{argmin}_i y_i(\mathrm{max_i}y_i - \mathrm{min}_i)}{sqrt{operatorname{Median}(\{ (y_i - y_{i-1})^2} _i)}}
$$
乍一看,这似乎很复杂,但实质上它显示了参数变化时评价指标值的非线性变化程度(即形成一条曲线),值越大,变化越大。
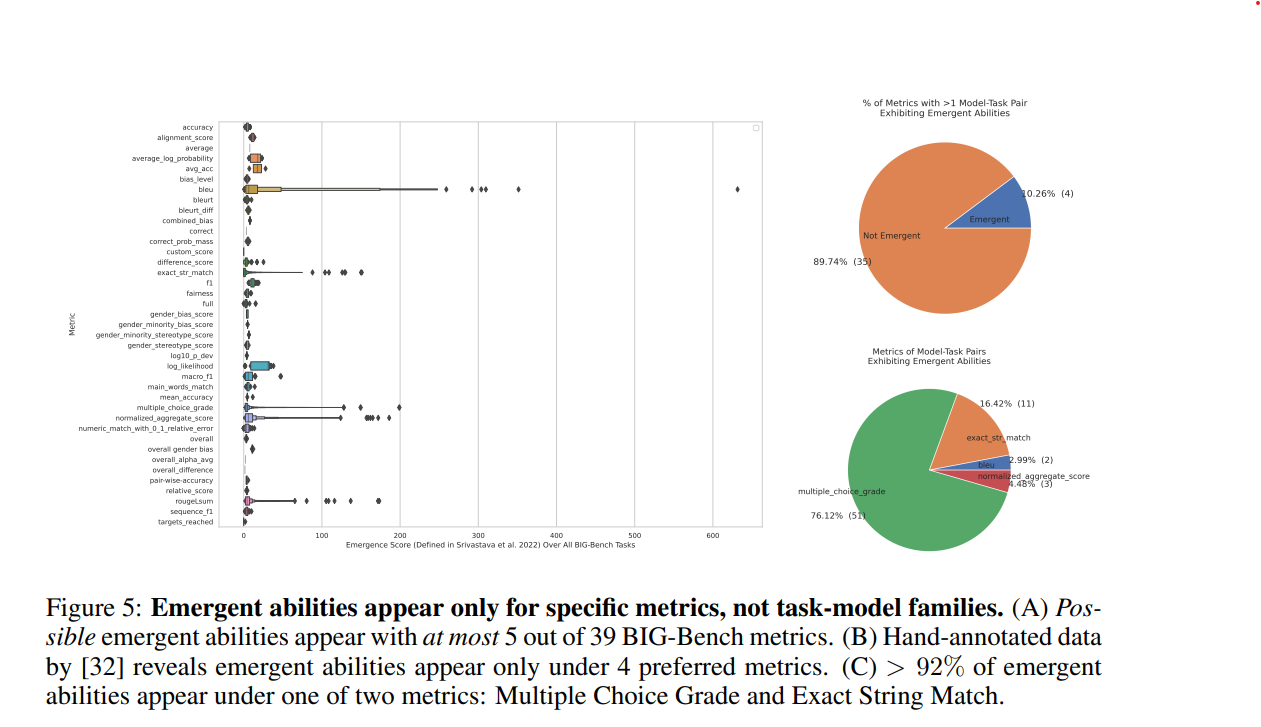
实验结果表明,BIG-Bench 中的大多数评估指标并未显示出任务-模型配对的涌现能力:39 个评估指标中有 5 个显示出较高的涌现得分,其中许多是非线性的。对任务-模型-评估者三元组的分析还显示,39 个评估指标中有 4 个显示了突现能力,其中超过 92% 的指标是多选等级和精确字符串匹配。总之,研究发现,在 BIG-Bench 的 39 个评价指标中,只有一小部分是非线性的,足以显示出新兴性。
我们还进行了一项实验,以了解当 BIG-Bench 中的评价指标发生变化时,新出现的问题是否会消失。使用 LaMDA 作为模型,并通过将多选等级改为布赖尔分数来分析结果。结果表明,在使用布赖尔得分时,不再观察到使用多选等级时观察到的非线性性能变化。这说明出现是评价指标选择的函数
在视觉任务中诱导网络的新兴能力
作者认为,模型的出现取决于评价指标。因此,他们预测非语言模型可以 "再现 "模型的出现。为了证明这一点,他们使用各种神经网络(全连接、卷积、自注意)进行实验,以刻意产生涌现。
关于 MNIST 的 CNN
LeNet 是一种 CNN,在数据集 MNIST 上使用标有手写数字的手写数字图像进行训练,以完成对输入的手写数字进行分类的任务。
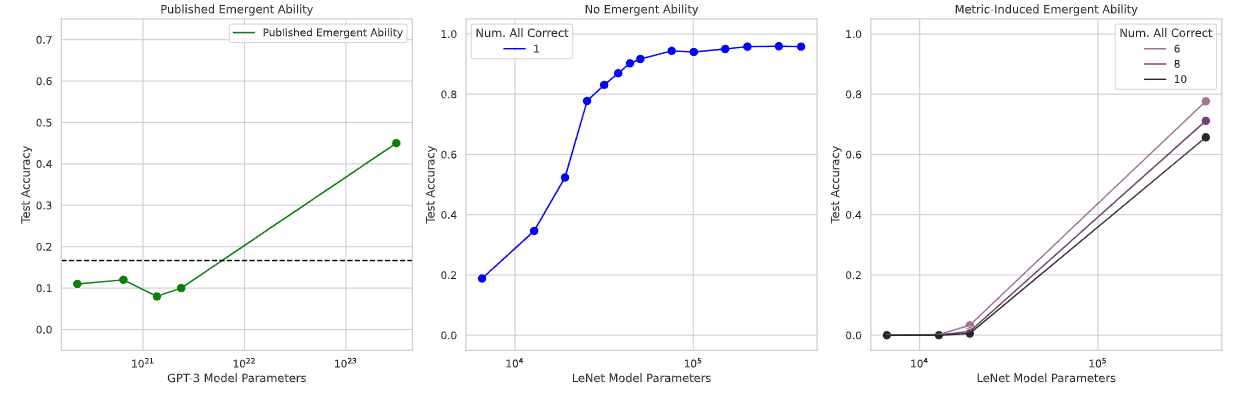
结果如上图所示。中间的 B 图是准确度图,显示了准确度随着参数的增加而平稳上升。另一方面,最右边的 C 图使用了一个名为 "子集准确度 "的评估指标,如果所有类别(在本例中为 0 到 9 的数字)都被正确分类,则输出 1,否则输出 0(即在每个类别分类中不允许出现任何错误)。当参数数量增加时,可以看到这样一个现象:准确率突然从某一点开始上升,而之前一直保持在 0 附近。如图中最左侧的 A 所示,这种突然增加的现象与已报道过的出现情况类似,可以说出现情况已经再现。
CIFAR100 上的自动编码器
使用 CIFAR100 对具有一个隐藏层的浅层自动编码器进行训练,以重建图像;定义了一个名为 "重建 "的易出现评价指标,与之前一样,当参数发生变化时,会观察到数值的变化 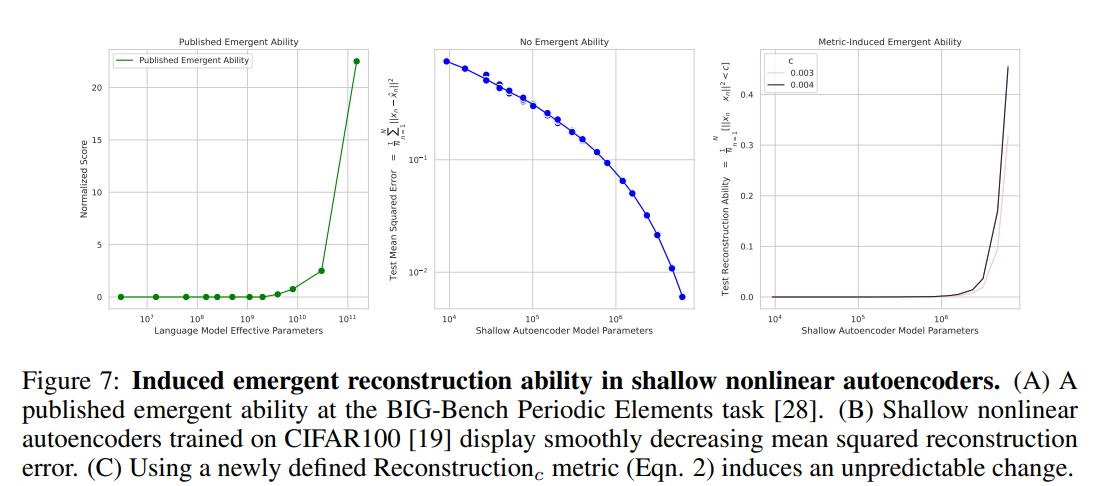
上图显示了结果。中间的 B 图显示了使用均方误差时的变化,并显示出平稳的下降。然而,在使用最左侧的 "重构 "时的变化图 C 中,可以看到几乎没有任务能力的状态突然开始显示出能力。这与图 A 中已知的出现案例非常相似,表明出现是可以重现的。
Omniglot 上的自回归变压器
嵌入在一个卷积层中的图像由一个纯解码器变换器进行分类,该变换器与 CNN 一样,试图通过对 L 长度的字符串进行分类,并使用子集准确度度量来重现出现。
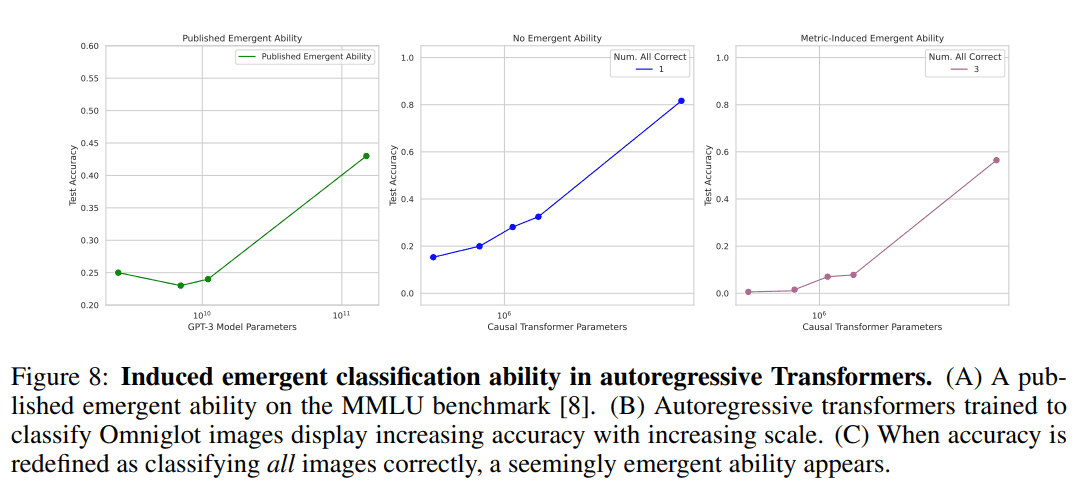
虽然中间正常精度的性能随着参数的增加呈线性增长,但使用最右侧子集精度的结果与之前报告的最左侧 MMLU 基准的出现情况相似,表明出现是人为再现的。结果表明,出现是人为再现的。
从上述多个架构的实验中可以发现,无论模型的大小,都可以通过人为地选择评价指标,使涌现看起来像是正在涌现。
结论
本文认为,关于语言模型的出现,有些是可见的,有些则是虚幻的,这取决于评价指标的选择。
不过,作者指出,这并不意味着在语言模式中没有通过涌现获得的能力,而只是说目前所认识到的涌现实际上可能并非如此。
通过本研究可以了解到,在任何实验中都应谨慎选择评价指标。



与本文相关的类别
![[Libra] 利用解耦视觉系统对大规模](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




