
LLM 是否具有因果推理能力?
三个要点
✔️ 测试大规模语言模型因果推理能力的拟议基准数据集
✔️ 对现有的 17 个大规模语言模型进行了评估
✔️ 发现当前模型的因果推理能力较差
Can Large Language Models Infer Causation from Correlation?
written by Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Spencer Poff, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, Bernhard Schölkopf
(Submitted on 9 Jun 2023)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
导言
因果推理能力是人类智慧的关键能力之一。这种能力由两部分组成:一部分源于经验知识,另一部分源于纯粹的因果推理。
大规模语言模型(LLM)可以从海量语言数据中捕捉术语之间的相关性,但从中提取因果关系的能力仍是一个重要问题。
本文提出了一个数据集 CORR2CAUSE,以测试推断纯粹因果关系的能力。
然后,它将调查当前 LLM 的能力,以及他们能否通过再学习提高自己的绩效。
数据集
术语的组织
基于图论描述因果关系。例如,当两个事件(节点)$X_i$和$X_j$之间的关系(边)$e_{i,j}$为$X_i \rightarrow X_j$时,表示$X_i$是$X_j$的直接原因。这里假设没有循环。
换句话说,当 $X_i \rightarrow X_j$ 时,我们说 $X_i$ 是 $X_j$ 的父系,反之,$X_j$ 是 $X_i$ 的子系。当有一条有向路径从 $X_i$ 通向 $X_j$ 时,我们也说 $X_i$ 是 $X_j$ 的祖先,反之,$X_j$ 是 $X_i$ 的子孙。
同样,对于三个元素 $X_i,X_j,X_k$,当 $X_k$ 有共同的父元素 $X_i,X_j$(即共同的原因)时,$X_k$ 被称为混杂者;反之,当 $X_k$ 是 $X_i,X_j$ 的子元素(即共同的结果)时,$X_k$ 被称为碰撞者。而当 $X_i \rightarrow X_k \rightarrow X_j$ 时,$X_k$ 被称为中介。
任务设置
一对陈述 $\mathbf{s}$ 描述了 $N$ 元素之间的相关性 $\mathbf{X}=\{X_1, ..., X_N\}$ 和一个假设 $\mathbf{h}$ 描述了其中元素 $X_i$ 和 $X_j$ 之间的因果关系$(\.mathbf{s}, \mathbf{h})$,任务是预测表示假设正确与否的标签 $v$。如果假设正确,则预测 $v=1$;如果假设错误,则预测 $v=0$。
创建数据集
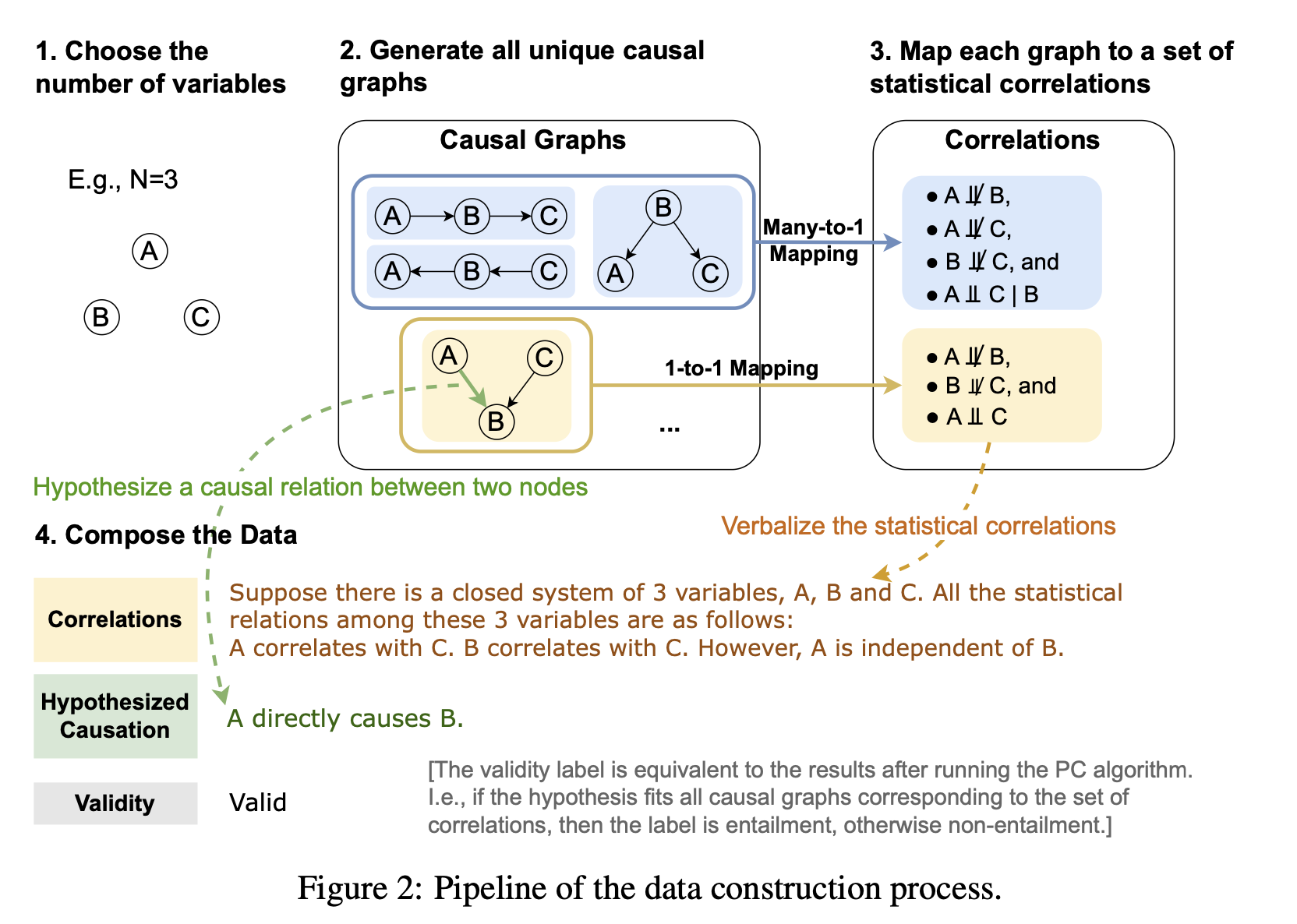
上图概述了数据集创建过程。首先,确定元素(节点)的数量 $N$,并列出可能的关系(图)。然后,从每个图(关系)中提取两个元素,并按照以下六种模式对它们之间的因果关系做出假设。
Is-Parent (是父母):是否是父母。
Is-Child (是子女):是否是子女。
Is-Ancestor (是祖先):是否是祖先。Is-Ancestor: 是否祖先,但不是父母。
Is-Descendant: 是否后代,但不是子女。 Has-Confounder: 是否混杂因素。
Has-Confounder:是否有混杂因素(共同原因)。
Has-Collider:是否有碰撞因素(共同结果)。
如果假设正确,则标记为 "1";如果假设错误,则标记为 "0"。
如下表所示,用自然语言对上述关系(图表)和假设进行了解析。

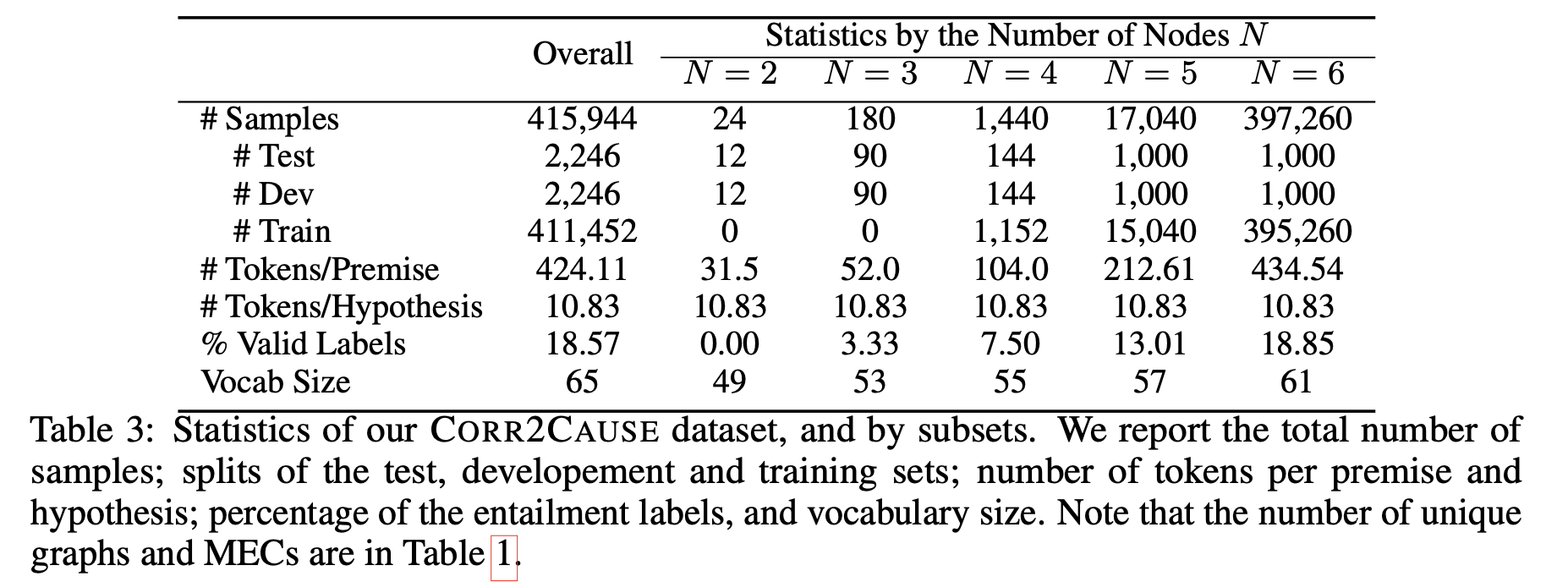
数据集的统计信息
创建的 CORR2CAUSE 数据集共有 415944 个样本,其中 411452 个样本用作训练数据。(见下表)
实验结果
我们制作了几个基于 BERT、GPT 和 LLaMa 的模型,并对它们在 CORR2CAUSE 数据集上的性能进行了研究。
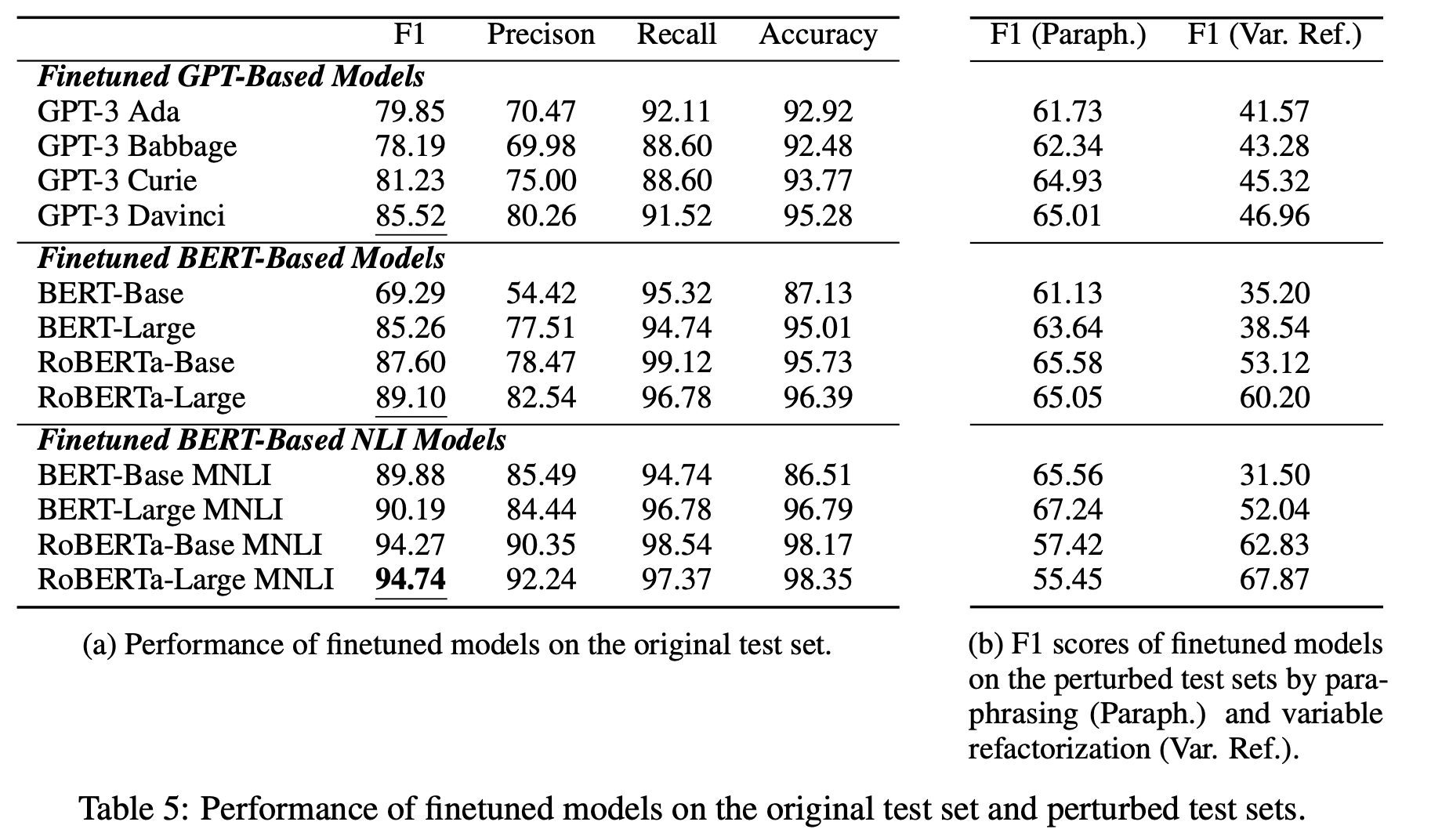
针对受过培训的法律硕士
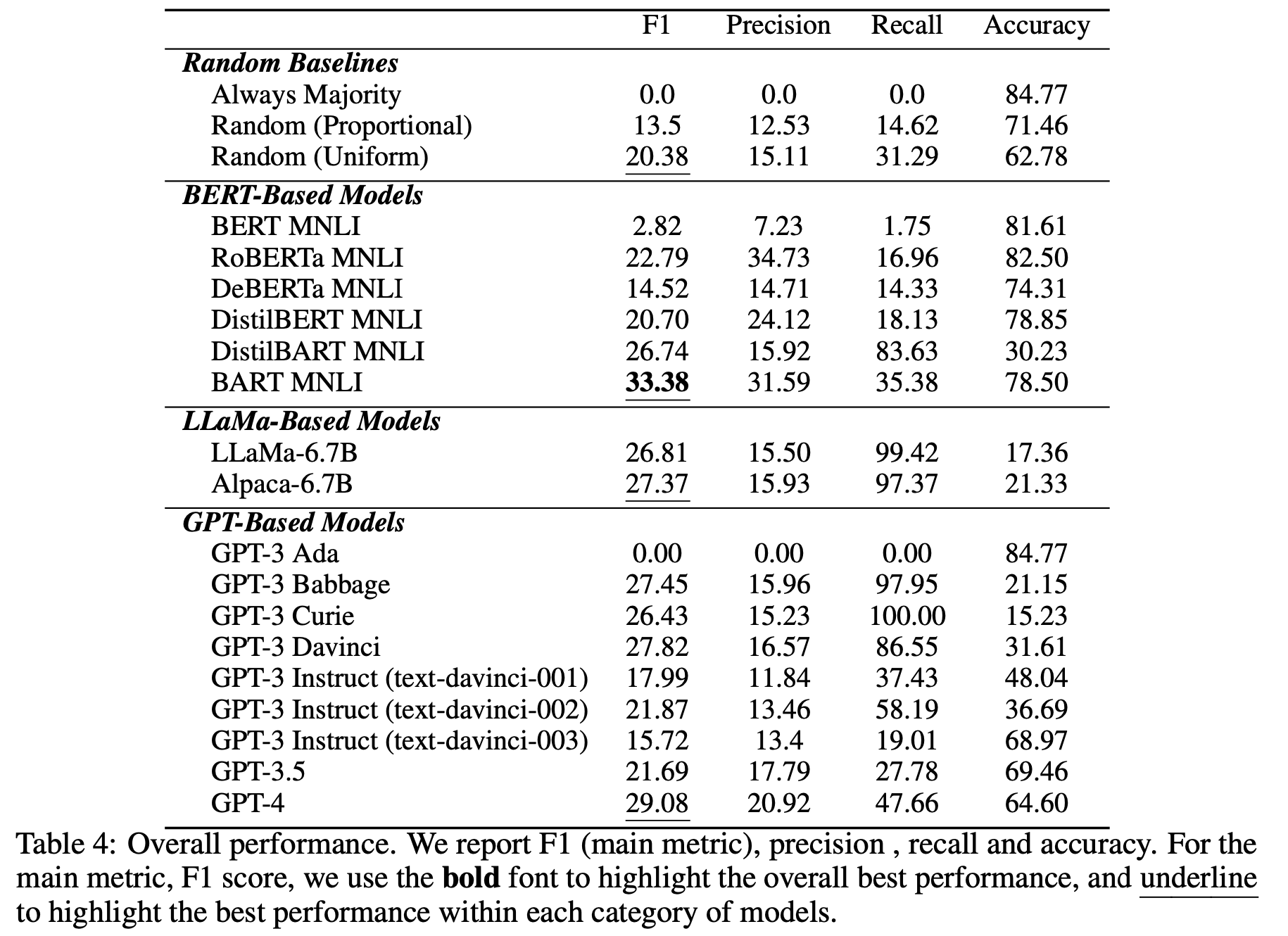
上表显示了经过公开训练的 LLM 的性能。所有模型都在 CORR2CAUSE 任务中表现不佳,最好的一个模型的 F1 分数仅为 33.38%�
如果进行微调
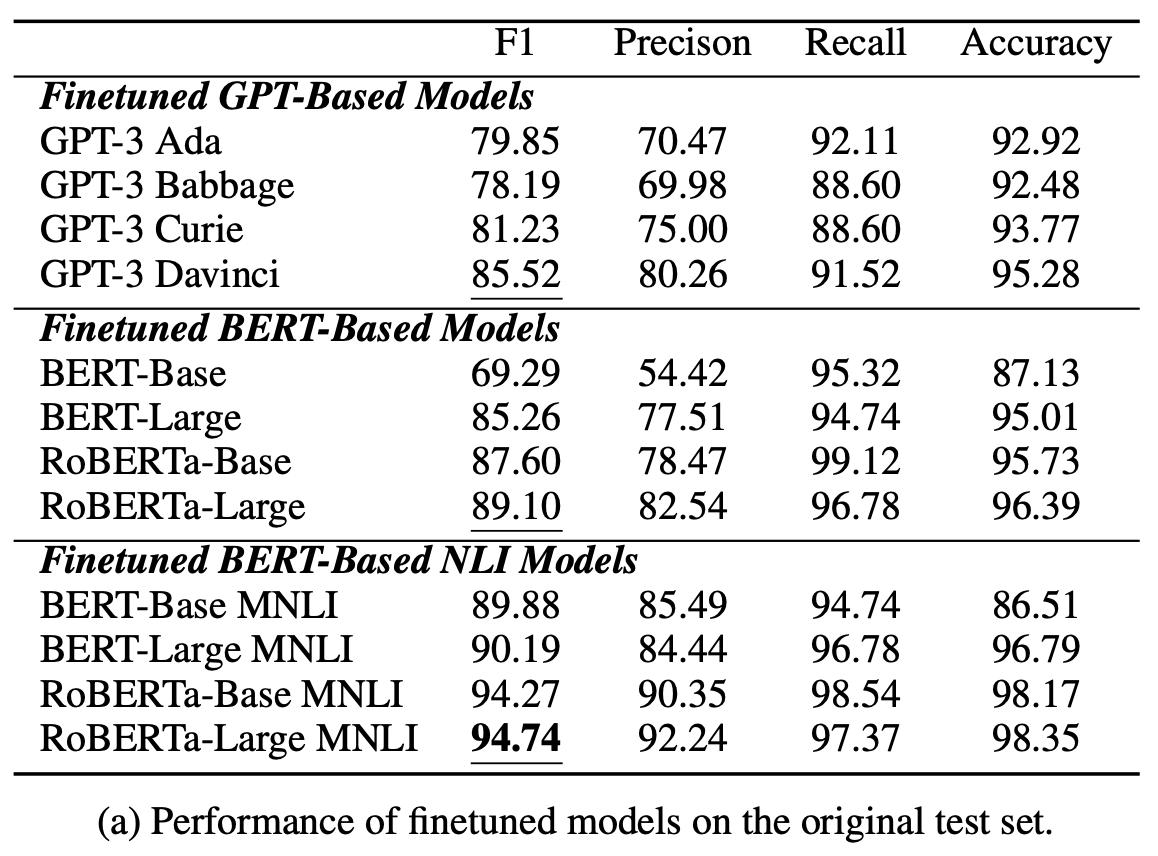
上表显示了在 CORR2CAUSE 数据集上微调后 LLM 模型的性能。与微调前相比,所有模型的性能都有显著提高。
下图显示了性能最佳的 RoBERTa-Large MNLI 的表现,针对每种因果模式进行了评估:它在 Is-Parent、Is-Descendant 和 Has-Cofounder 模式中表现出色,但在 Has-Collider 模式中稍显吃力。下图显示,该系统在应对 Has-Collider 模式时略显吃力� 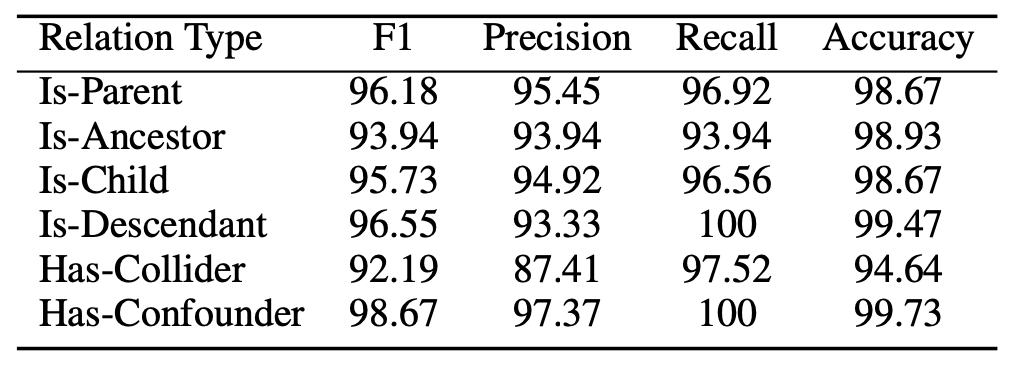
稳健性研究
由于微调大大提高了性能,因此出现了以下问题:该模型能否稳健地推断因果关系?为了研究这个问题,我们又进行了两次实验。
转述:重新表述假设并再次询问模型,如下图所示。
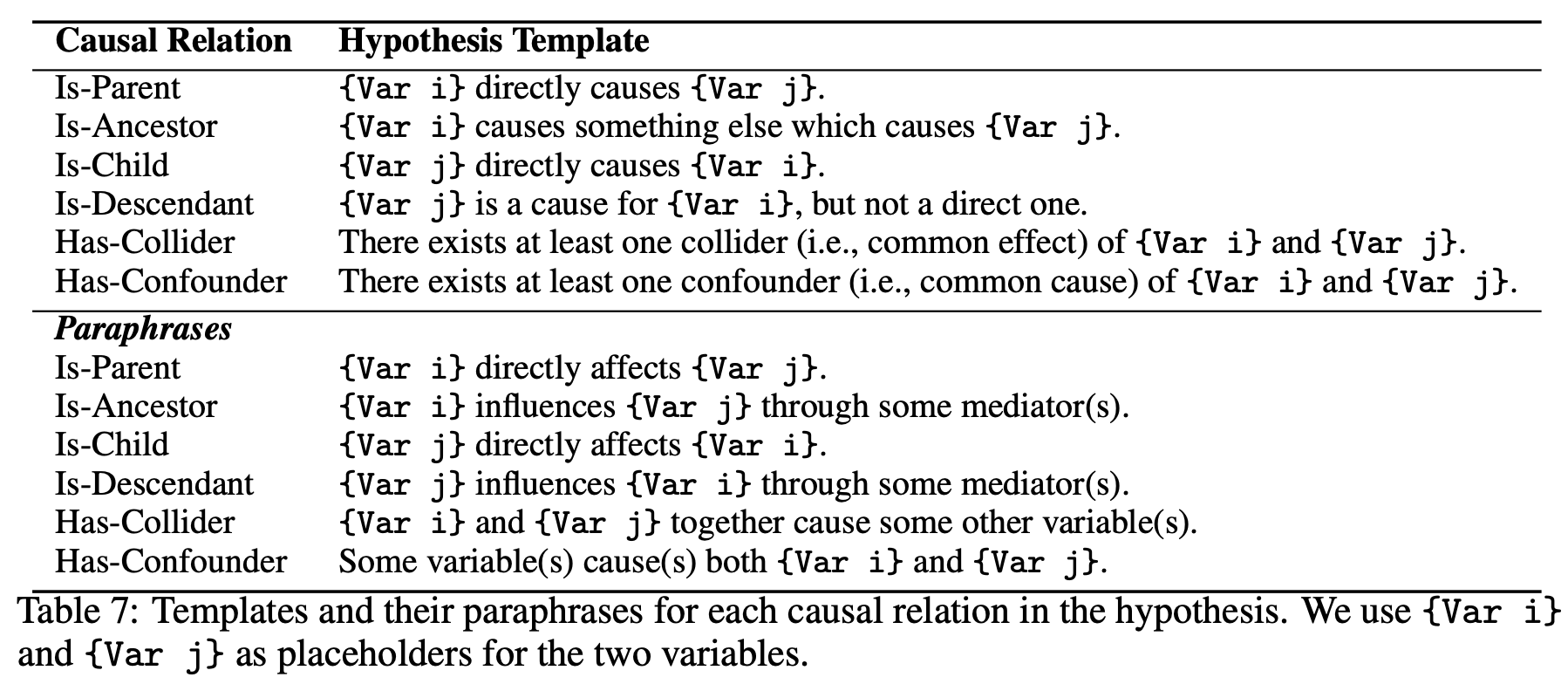
变量替换:只需用 A、B、C 中的 X、Y、Z 替换所用变量名称中的字母即可�
附加实验的结果见下表右侧 (b) 部分。我们可以看到,转述和变量替换大大降低了所有模型的性能。我们可以看到,这些模型并不能泛化到训练数据分布之外的数据。
商讨
在本文中,我们提出了一个数据集 CORR2CAUSE 来研究因果推断能力。这是一个由 400 000 多个样本组成的大型数据集。由于它没有用于训练原始 LLM,因此是研究因果推理能力的合适数据集。其局限性包括节点数量有限(2 到 6 个),以及没有假设隐藏的共同原因。
在该数据集上进行的实验表明,现有的 LLM 在因果推理方面很吃力:虽然微调能提高性能,但措辞上的细微变化也会降低性能,这一现象需要在今后的研究中进行更详细的调查。
摘要
本期,我们介绍了一篇论文,该论文提出了一个数据集 CORR2CAUSE,用于研究 LLM 的因果推理能力。目前的 LLMs 似乎仍有较差的因果推理性能。如何提高 LLM 的因果推理能力?还需要继续研究。



与本文相关的类别
![[Libra] 利用解耦视觉系统对大规模](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




