TAPAS:表格数据推理语言模型。
三个要点
✔️ 用于表格数据问题解答的拟议语言模型 TAPAS
✔️ 在大型文本-表格对数据集上进行预训练,并在语义解析数据集上进行微调
✔️ 在语义解析任务上的表现优于现有方法在语义解析任务上的表现优于现有方法。
TAPAS: Weakly Supervised Table Parsing via Pre-training
written by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno, Julian Martin Eisenschlos
(Submitted on 5 Apr 2020 (v1), last revised 21 Apr 2020 (this version, v2))
Comments: Accepted to ACL 2020
Subjects: Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
导言
迄今为止,在表格数据上用自然语言回答问题的问题一直被视为语义解析问题。(语义解析是用逻辑运算替换问题的过程)。在监督学习中处理这一问题时,缺乏注释数据一直是个难题。
在本文中,我们提出了一个弱监督学习模型 Table Parser (TAPAS),它可以对表格数据进行推理并回答问题。
模型实施
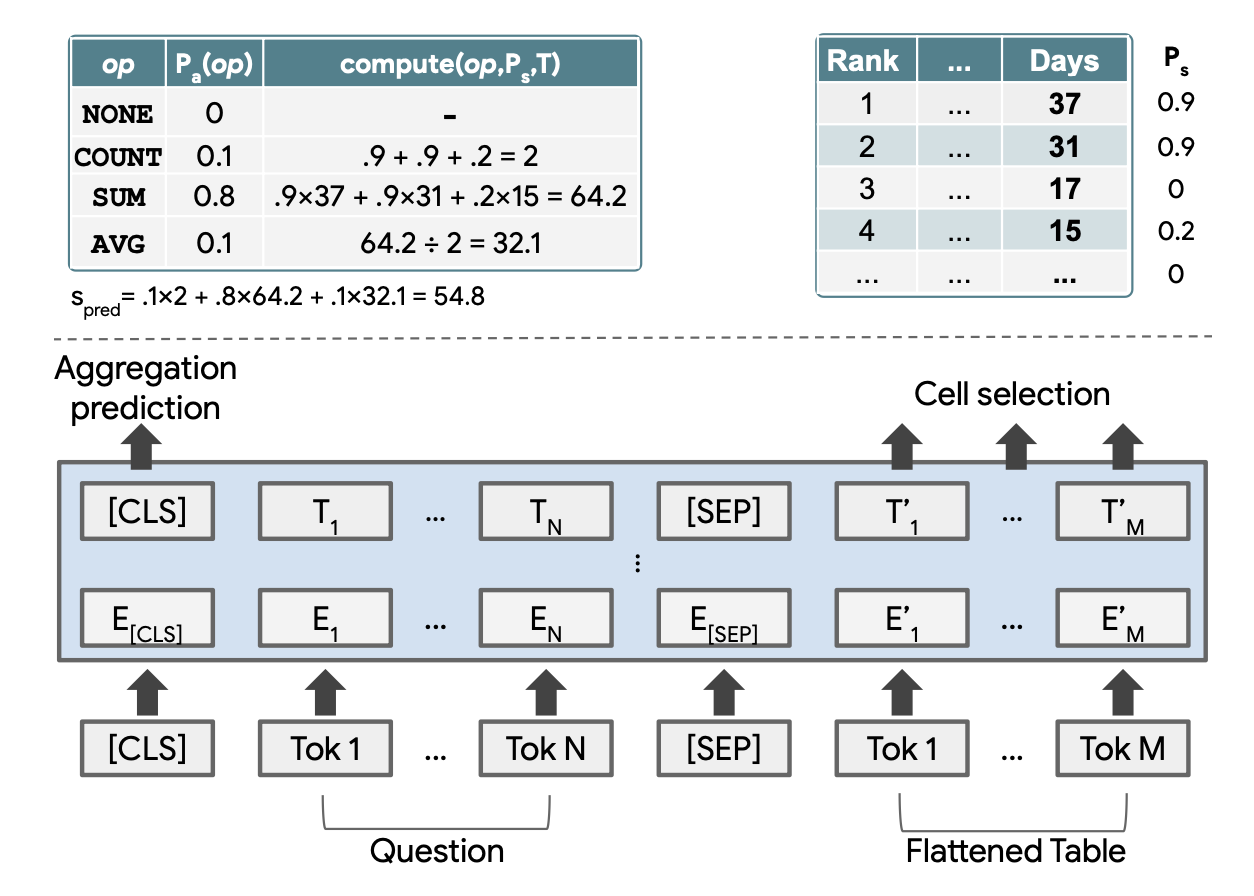
上图概述了拟议模式的流程。
为了对表格结构进行编码,该结构在 BERT 编码器模型中添加了自己的位置编码。
表格形式被平滑处理成一系列单词,这些单词与问题文本和输入内容连接在一起。输出部分增加了一个输出层,用于选择要处理的单元格和预测算术运算。
附加位置编码
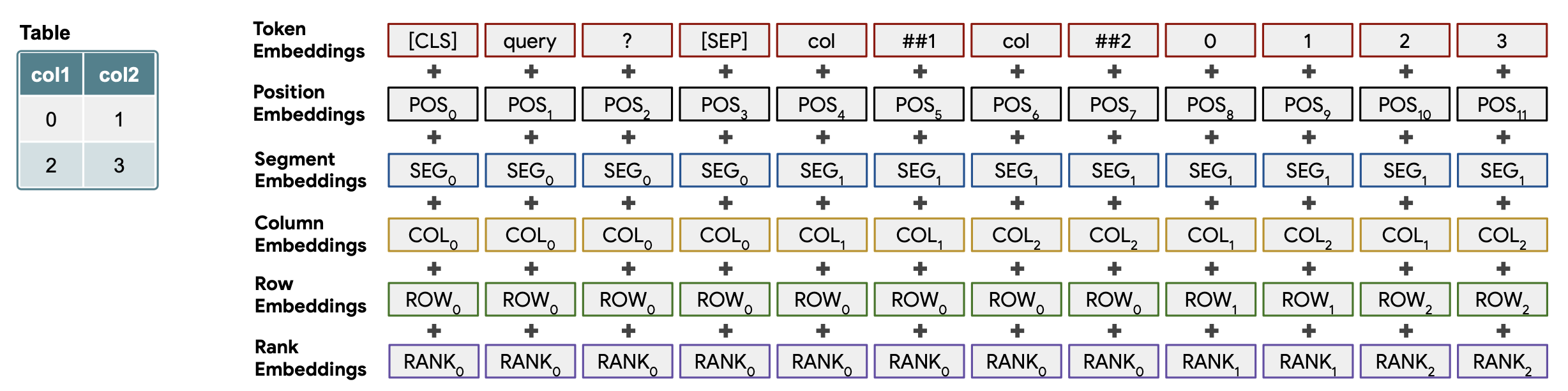
如上图所示,在一系列单词和表格数据(标记嵌入)中添加了多个嵌入。
位置嵌入
与 BERT 类似,这些都是系列中的位置嵌入。
分段嵌入
嵌入来区分问题和表格数据。前者对应 0,后者对应 1。
列嵌入/行嵌入
嵌入是表中行和列的索引(从 1 开始)。对于查询语句,它们对应于 0。
Rank Embeddings
如果表格中的列数据是浮点数或日期,则按升序分配序号。无法比较的数字分配为 0,从 1 开始的数字从最小值开始依次递减。这就解决了数字数据作为语言信息难以直接比较的问题。
上一个答案
嵌入,用于在以交互方式重复问题和答案时引用上一个问题或答案。为答案赋值 1,为其他内容赋值 0。
在输出层选择单元格
输出给操作员的部分,输出要操作的单元。
每个单元格都被模拟为一个独立的伯努利变量,并输出该单元格被选中的概率。概率大于 0.5 的单元格将被选中。
关于预测算术运算的输出层
输出操作,如 SUM、COUNT、AVERAGE 和 NONE�
先前学习
TAPAS 模型使用维基百科中的大型表格数据集进行预训练。
为此,我们从维基百科中提取了成对的文本和表格数据,创建了一个数据集。
表格标题、文章标题和描述被用来代替问题文本。
然后,这些数据将用于训练掩码语言模型任务。
微调
假设训练数据集由 $N$ 样本组成。样本是由表格数据 $T$、问题 $x$ 及其答案 $y$ 组成的对 $(x,T,y)$。
该模型的目的是,在给定表格数据 $T$ 和问题 $x$ 的情况下,能够选择适当的单元格并执行适当的操作 $z$ 以生成正确的答案 $y$。
下面将详细介绍每项任务。假设答案 $y$ 是由待选单元坐标 $C$ 和正确标量值 $s$ 组成的元组($y = (C,s)$)�
细胞选择
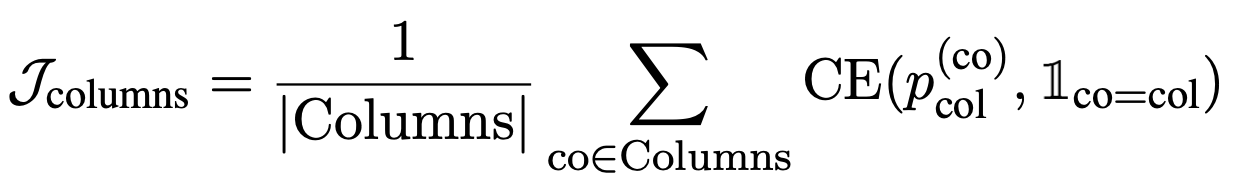
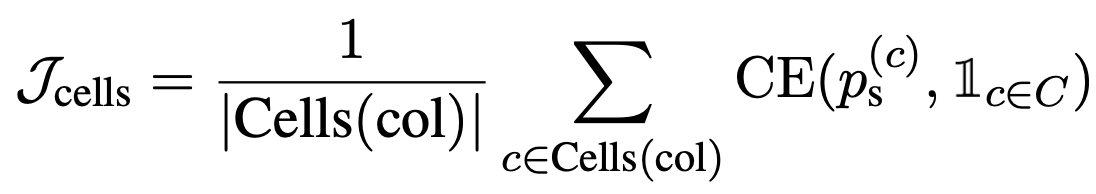
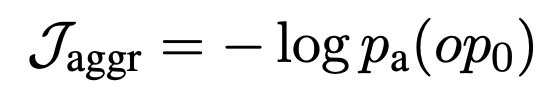
损失 $\mathcal{J}_\mathrm{columns}$ 和 $\mathcal{J}_\mathrm{cells}$ 表示是否选择了合适的列和合适的单元格,加上损失 $\mathcal{J}_\mathrm{CS}$ 表示是否选择了合适的操作 NONE。aggr}$ 加上损失 $mathcal{J}_\mathrm{CS} = \mathcal{J}_\mathrm{columns} + \mathcal{J}_\mathrm{cells} + \alpha \mathcal{J}_\mathrm{aggr} ,优化就完成了。进行优化。
答案为标量值
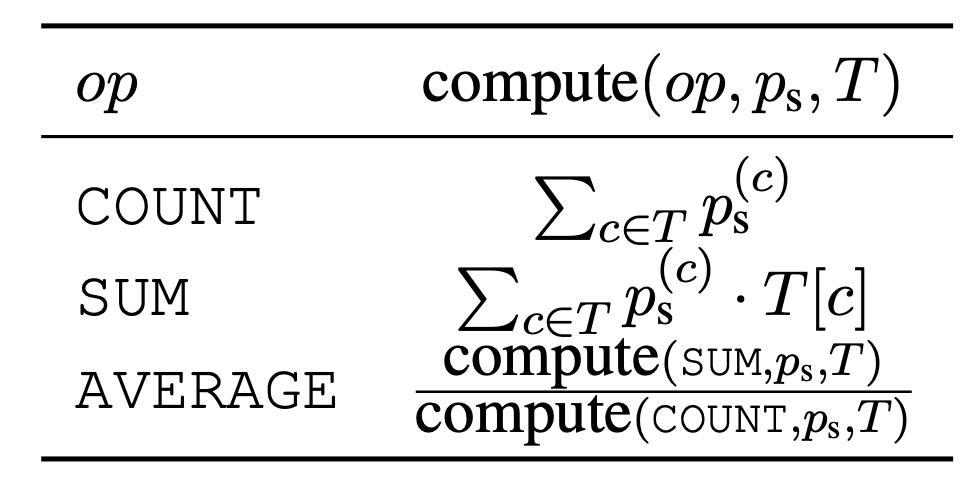
如上表所示,用可微分的形式表示各种运算(计数、求和、求平均数)�
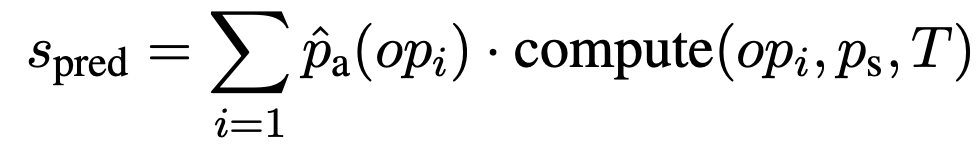
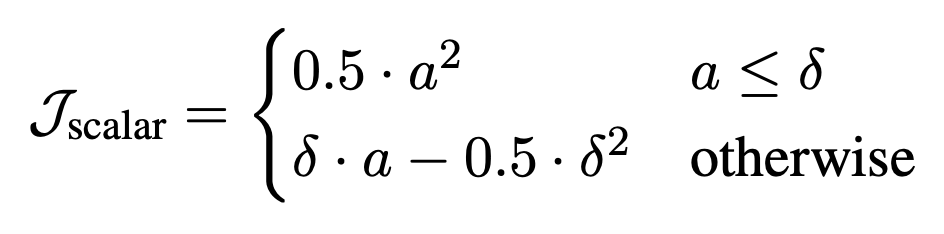
然后计算出应用于选定单元格的选定操作的结果 $S_{mathrm{pred}}$ 与正确标量值 $S$ 之间差值的绝对值为 $A$,损失 $mathcal{J}_\mathrm{scalar}$ 表示操作的标量值是否合适�
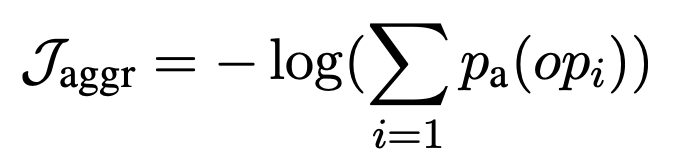
此外,计算损耗 $\mathcal{J}_\mathrm{aggr}$ 以表明是否选择了合适的操作,并将两个损耗相加:损耗 $\mathcal{J}_\mathrm{SA} = \mathcal{J}_\mathrm{aggr} + \beta \mathcal$ 使用 ${J}_mathcal{J}_\mathrm{scalar}$ 进行优化。
试验
数据集
我们对多个数据集进行了语义解析实验,其中包括以下三个数据集
WIKITQ 是一个数据集,包含维基百科中的表格数据以及各种问题文本和答案。
SQA 是一个数据集,它分解了 WIKITQ 问题,并用简单的问题取而代之。
WIKISQL 是一个包含 SQL 操作和问题的数据集�
实验装置
我们使用由 32 000 个单词组成的词性标记器(标准 BERT 标记器);我们开始使用 BERT-Large 模型进行预训练和微调。
实验结果
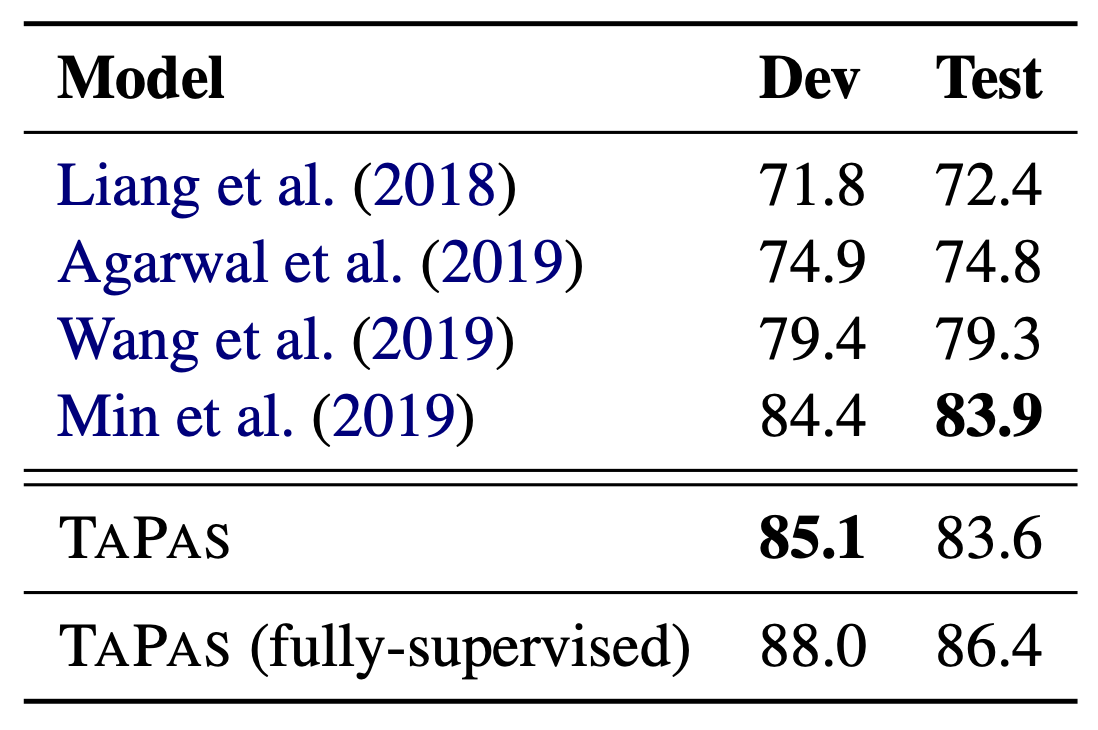
上表显示了与 WIKISQL 相比的性能,表明 TAPAS 的性能与最先进的方法不相上下。
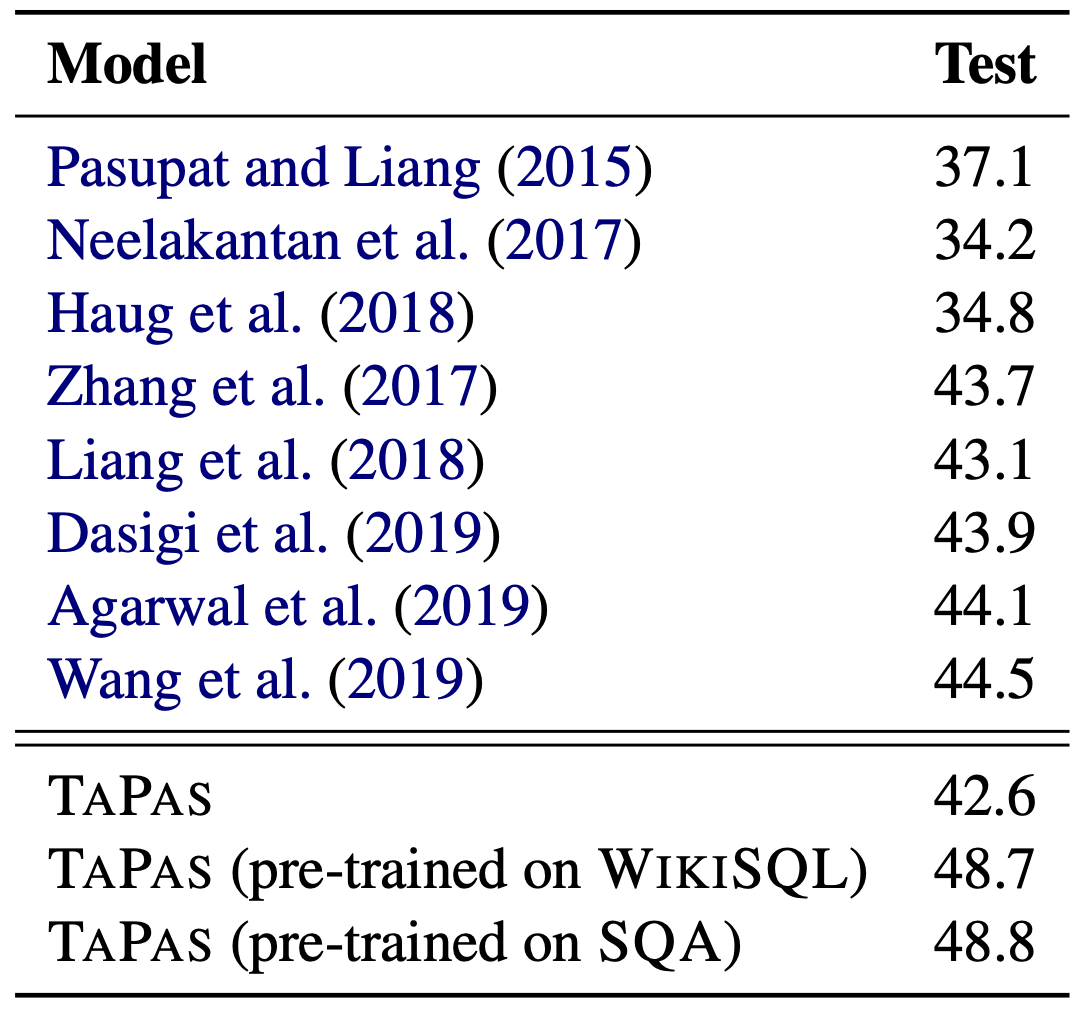
上表显示了 TAPAS 与 WIKITQ 的性能对比,其中 TAPAS 在使用 WIKISQL 或 SQA 进行预训练时表现最佳。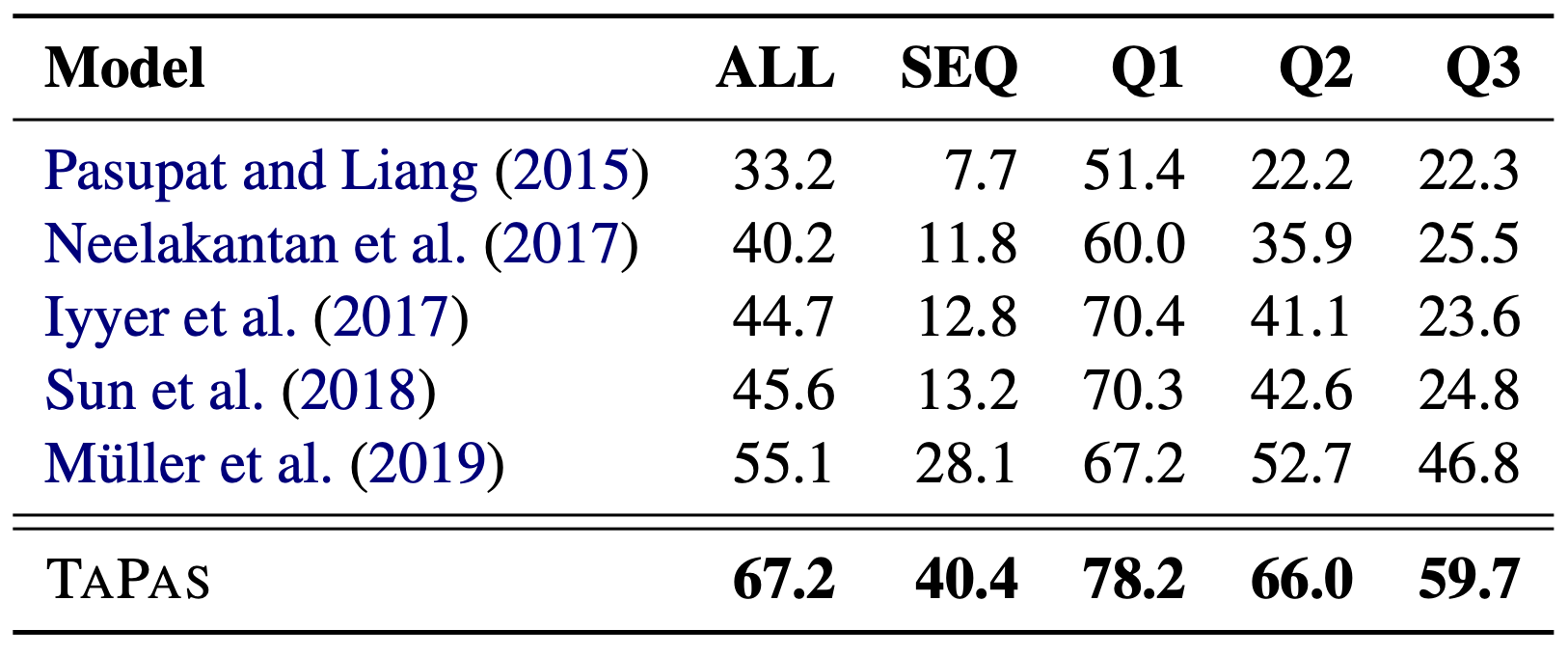
上表显示了 SQAs 的绩效;可以看出,TAPAS 在所有指标上的绩效都是最高的。
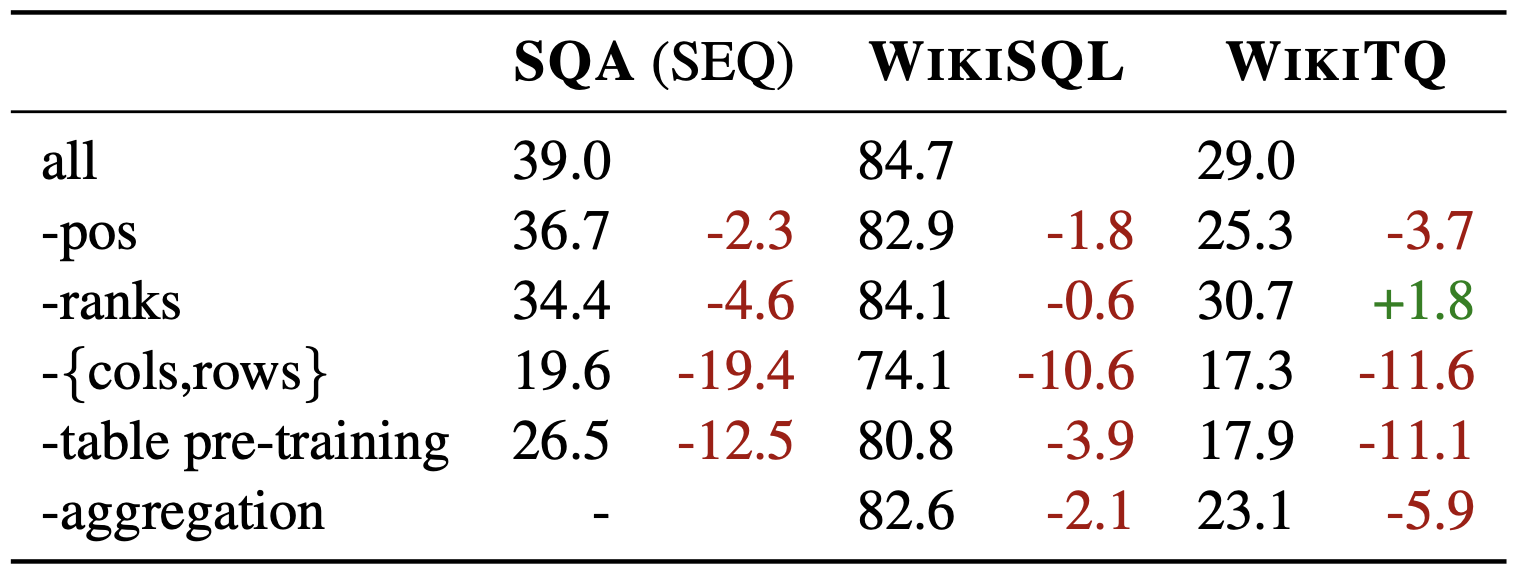
上表显示了一项消融研究的结果,该结果表明,当省略每个嵌入、预培训等操作时,性能会如何下降。
可以看出,对表格数据集进行预训练以及对列和行进行位置嵌入对提高性能非常重要。
限额
本文提出的方法是将单个表格数据以字符串形式输入模型,这限制了可处理的表格数据的大小,也不适用于包含多个表格的数据。此外,由于其表述方式,它无法处理需要两个以上步骤的复杂过程,例如平均值的比较。
摘要
这里介绍的 TAPAS 模型是一个基于 BERT 的模型,它提出了一种嵌入表格数据的有效方法,不过还需要针对具体任务进行微调。预计未来这一领域将有进一步的发展。



与本文相关的类别
![[Libra] 利用解耦视觉系统对大规模](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




