
利用大规模语言模型 PaLM,谷歌正在开发通用人工智能 Med-PaLM M,以协助医生进行诊断。
三个要点
✔️ 推出 MultiMedBench,这是一个包含医学图像和遗传信息等各种医疗数据的新基准。
✔️ 推出 Med-PaLM M,这是世界上首个通用医疗人工智能模型,可在单个模型中处理多项任务。
✔️ 一些任务被证明达到了临床可接受的水平。
Towards Generalist Biomedical AI
written by Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Chuck Lau, Ryutaro Tanno, Ira Ktena, Basil Mustafa, Aakanksha Chowdhery, Yun Liu, Simon Kornblith, David Fleet, Philip Mansfield, Sushant Prakash, Renee Wong, Sunny Virmani, Christopher Semturs, S Sara Mahdavi, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias, Karan Singhal, Pete Florence, Alan Karthikesalingam, Vivek Natarajan
(Submitted on 26 Jul 2023)
Subjects: Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
医疗行业的多模态特性要求人工智能模型能够灵活处理各种数据格式,包括文本、图像和基因组信息。
本文介绍了一种多功能人工智能模型 Med-PaLM Multimodal("Med-PaLM M"),它可以解释多种类型的医疗数据,包括语言、医疗图像和基因信息,并在一个模型中执行多种不同的任务。这是单个人工智能模型能够处理多种医疗数据的首个实例,并显示出比特定任务模型更好的效果。它无需针对特定任务进行调整就能实现这些结果。
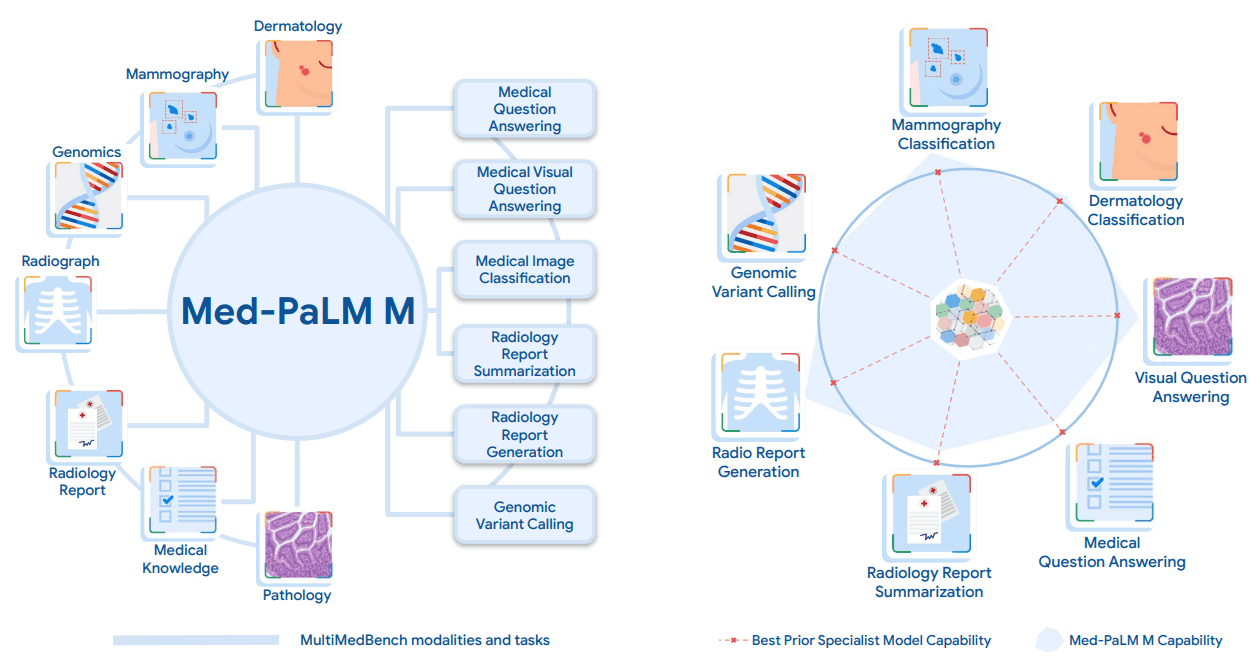
为了开发 Med-PaLM M,我们还建立了一个名为 MultiMedBench 的基准。任务包括
Med-PaLM M在MultiMedBench的所有任务中都达到了最先进的性能,往往明显优于专家模型。MultiMedBench 也是评估人工智能如何准确理解和充分处理现实世界中复杂医疗数据的开源基准,为构建和评估 Med-PaLM M 等多功能人工智能系统的性能提供了有用的工具。Med-PaLM M.
什么是 MultiMedBench?
MultiMedBench "是为开发和评估 Med-PaLM M 而建立的基准,包含 12 个不同的数据集和 14 个不同的任务。下表和下图概述了这些数据集和任务。该基准总共包含 100 多万个样本。
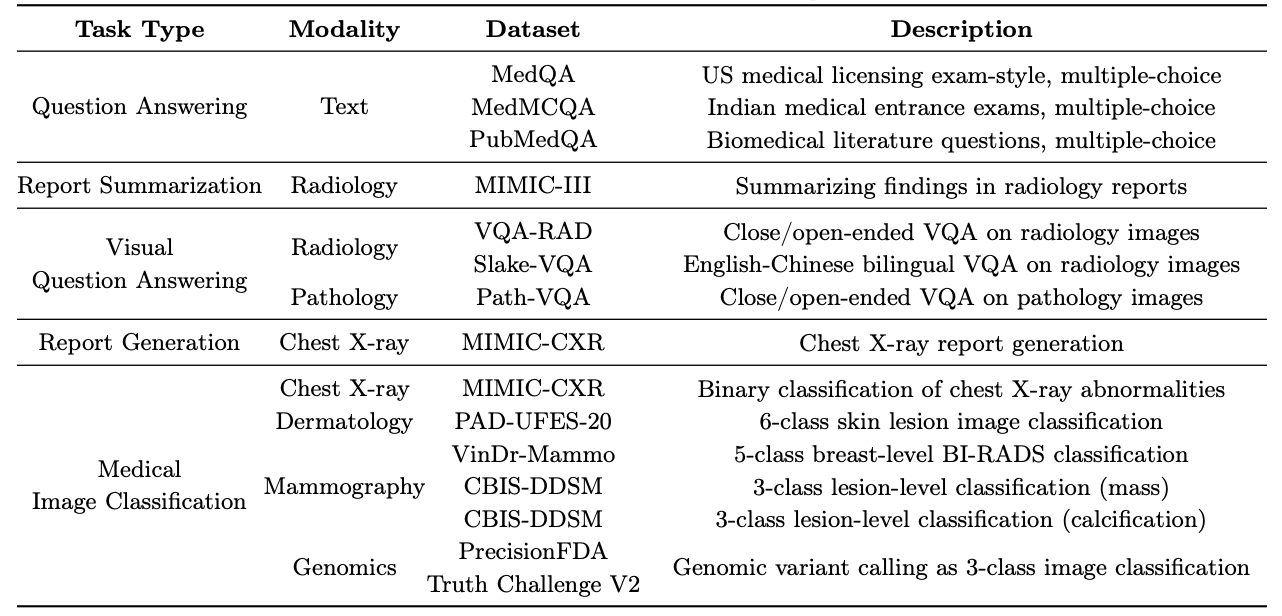
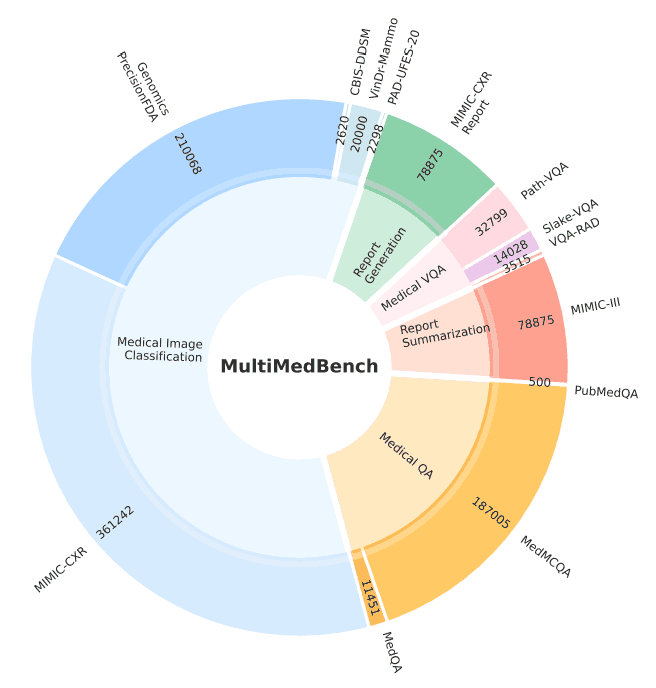
什么是 "Med-PaLM M"?
Med-PaLM M 是现有 PaLM-E 模型的医疗定制版本,以 PaLM 和 ViT 的结构和模型参数为基础。
PaLM 是一个大规模语言模型,在大量数据(7800 亿个词块)上进行了训练,其中包括互联网网页、维基百科、源代码、社交网络帖子、新闻和不同规模的书籍(80 亿、620 亿和 540 亿个参数)。它在复杂推理任务中的表现超过了人类的平均水平。ViT 也是一种图像识别模型,被称为视觉转换器(Vision Transformer)。本文使用了两个分别拥有 40 亿和 220 亿个参数的 ViT。它们在大约 40 亿张图像上进行了训练。
PaLM-E 将 PaLM 与 ViT 相结合,建立了一个多模态语言模型,该模型还能理解文本、图像和来自传感器的数据,Med-PaLM M 就是在此基础上建立的。本文使用了三种不同模型大小的 PaLM 和 ViT 组合模型(12B、84B 和 562B)。
Med-PaLM M 是通过使用 MultiMedBench 对 PaLM-E 进行微调而构建的。 Med-PaLM M 也有三种不同尺寸的型号(12B、84B 和 562B)。相关任务,如问题解答、放射报告生成、图像分类和基因突变识别。
基准
本文将 Med-PaLM M 与两个基线进行了比较。一个是针对 MultiMedBench 中每个任务的特定任务模型,该模型实现了 SOTA;另一个是 PaLM-E(84B),该模型未针对医疗领域进行微调。请注意,由于计算资源的限制,PaLM-E 使用的模型大小为 84B 而不是 562B。
结果如下表所示。从表中(粗体)可以看出,Med-PaLM M 在 MultiMedBench 中的许多任务上都优于现有的 SOTA。它使用相同的模型权重,无需针对特定任务进行微调,就能在多个任务中实现 SOTA。
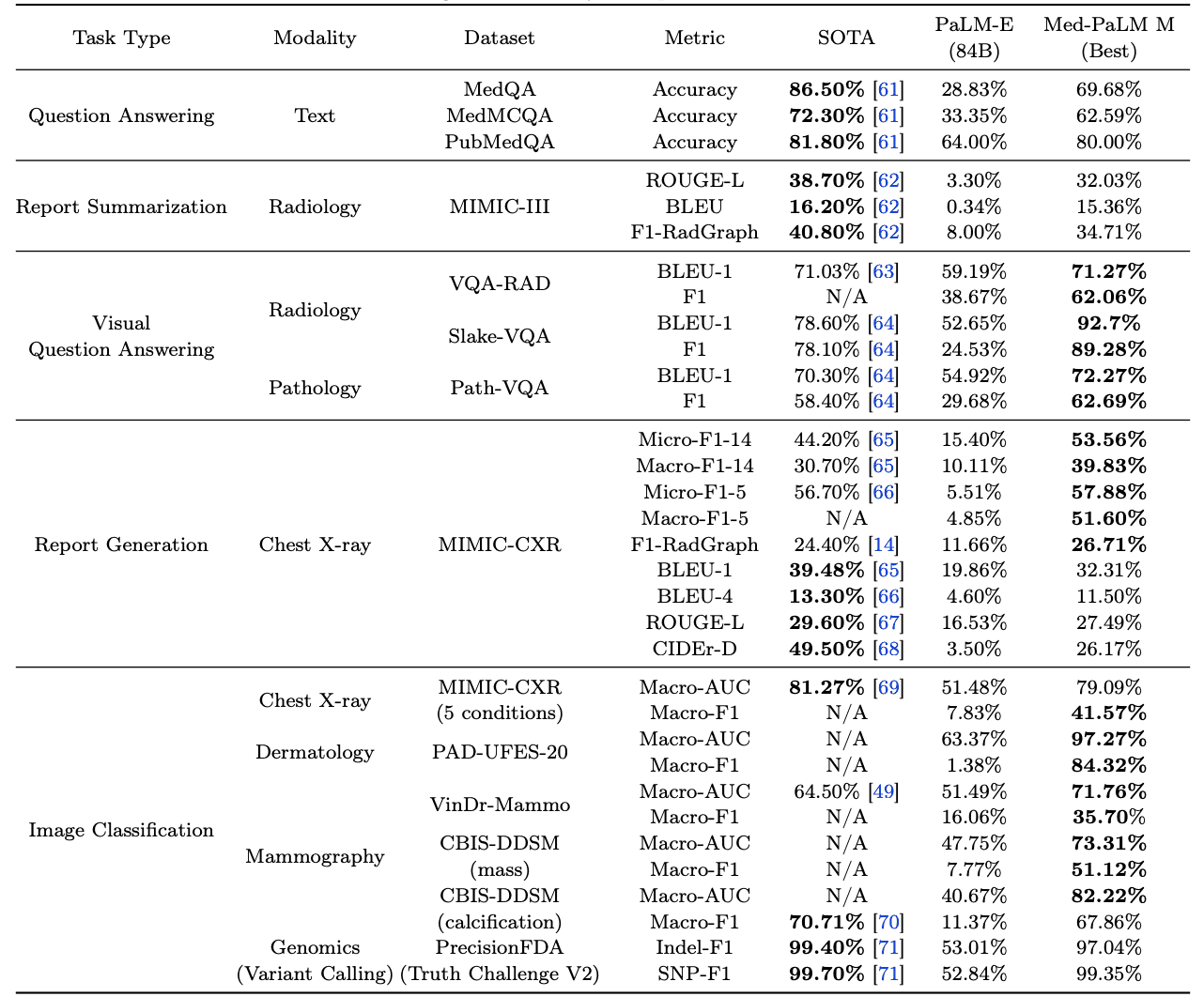
还可以看出,与未针对医疗领域进行微调的 PaLM-E(84B)相比,Med-PaLM M 在所有 14 项任务中的表现都更好。Med-PaLM M 在大多数任务中都有明显改善,这表明它是一个有用的通用人工智能模型。
此外,本文还研究了其对新的、未学习过的医疗任务和概念的适用性(与零投篮相比的性能)。
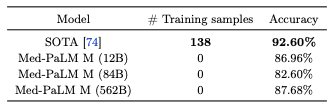
在使用数据集蒙哥马利县(Montgomery County,MC)从胸部 X 光图像中检测肺结核的任务中,对零镜头的性能评估结果如下表所示,SOTA 模型的性能具有竞争力。
此外,Med-PaLM M 还能分析胸部 X 光图像,并报告是否存在异常,如肺结核。因此,放射科医生正在检查人工智能生成的报告中是否有疏漏和错误;为了进一步了解 Med-PaLM M 的临床应用,放射科医生正在对 Med-PaLM M 生成的胸部 X 光报告(和人类参考值)进行评估。
测量了三个不同模型大小的 Med-PaLM M(12B、84B 和 562B)生成的报告中的疏漏和错误数量,结果表明,平均而言,12B 和 84B 模型的疏漏最少,其次是 562B 模型的疏漏略多。结果表明,在疏忽方面,12B 和 84B 模型平均疏忽最少,其次是 562B 模型略多。在误差方面,84B 模型的误差最小,12B 模型的误差稍大,562B 模型的误差最大。这些错误率与以往研究中人类放射科医生的错误率相似,表明该人工智能系统的错误率可能与人类专家的错误率一样高。
最后,下图显示了 Med-PaLM M 在不同尺寸机型上生成胸部 X 光报告的具体示例。
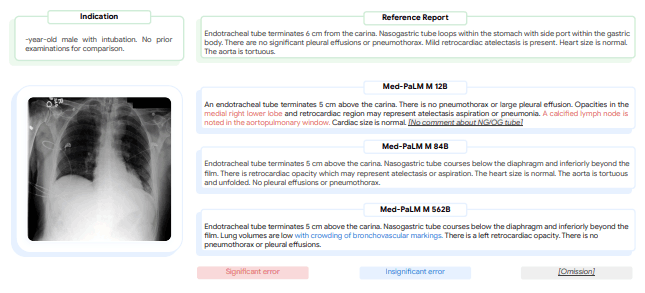
在这个例子中,放射科医生将 12B 模式生成的报告评为有重大错误和疏漏,84B 模式将报告评为没有错误或疏漏,562B 模式将报告评为有一个不明显的错误但没有疏漏。
摘要
论文介绍了 Med-PaLM M(一种用于医学的通用模型)和 MultiMedBench(一种用于开发和评估该模型的基准):一种模型在许多任务中的表现与 SOTA 或 SOTA 相当,而另一种模型在许多任务中的表现与 SOTA 相当。未来,我们希望这种多功能人工智能能与更专业的人工智能合作,并与实际的临床医生和研究人员共同应对重大的医学挑战。
能够整合各种医疗数据并快速应对新情况的多功能人工智能对于建立更好的医疗保健系统至关重要;Med-PaLM M 是创建此类人工智能的重要一步,预计将进一步开发和验证其实际用途。



与本文相关的类别

![[Libra] 利用解耦视觉系统对大规模](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




