
未标注的数据是否应该被视为 "平等"?一种扩展半监督学习的方法建议
3个要点:
✔️对每块未标注的数据进行加权后的半监督学习
✔️通过应用影响函数自动对数据进行加权。
✔️还要考虑使所提出的方法更轻便的方法。
Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning
written by Zhongzheng Ren, Raymond A. Yeh, Alexander G. Schwing
(Submitted on 2 Jul 2020 (v1), last revised 29 Oct 2020 (this version, v2))
Comments: NeurIPS camera ready
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
背景
一般情况下,监督学习框架需要大量的训练数据,但人工对每一个数据进行标注是非常困难的。而半监督学习则可以有效降低人工标注的成本,因为它可以在一些未标注的数据下进行训练。
这里有一个想法:未标注的数据真的有助于预测模型的准确性吗?这取决于学习算法,但有时未标记的数据会成为学习的阻碍。例如,如果你使用k-means将未标记的数据拟合到一个类上,就不能保证它是正确的类。根据不一定正确的信息来训练一个预测器可以吗?与标记数据相比,我们很难说在多大程度上可以信任未标记的数据。
在本文中,我们解决了这样的问题,并提出了一种半监督学习的方法,在这种方法中,每个未标记的数据都被赋予一个权重。这个想法本身很简单,但我们应用了一种叫做影响函数的技术来自动获得这些权重。这个想法很简单,但我们应用了一种叫做影响函数的技术,在没有我们直接干预的情况下,自动计算未标注数据的权重。此外,还引入了一种简单的机制,使得本文提出的方法变得轻巧。
先行知识
作为先决条件,我们将简单介绍一下影响函数(在本节中,我们假设是监督学习).影响函数简而言之,就是衡量某个数据$(x,y)$对预测器$\theta$的学习有多大影响。下面,我们将使用标注的训练数据。下面,我们将影响函数$F$表述为:标签训练数据集的$\mathcal{D}$,损失函数的$\ell_{\text{S}}$。
$F(x, y) = \frac{\partial\theta^{*}(\epsilon)}{\partial\epsilon},$
$where\quad \theta^{*}(\epsilon) := \arg\min\limits_{\theta}\sum\limits_{(x', y')\in\mathcal{D}}\ell_{\text{S}}(x', y', \theta) + \epsilon\ell_{\text{S}}(x, y, \theta)$
然而,我们设置$\epsilon>0$。如上定义所示,$\theta^{*}(\epsilon)$表示对某些数据$(x,y)\in\mathcal{D}$略微加权时损失$\ell_{\text{S}}(x, y, \theta)$的最小化。.可以将$\epsilon$解释为数据$(x,y)$的上重损失程度,通过取最小化器的部分导数,表示"对学习的影响程度"。
然而,在计算机上很难计算上式中引入的$\frac{\partial\theta^{*}(\epsilon)}{\partial\epsilon}$。为此,人们积极研究将影响函数近似为可计算形式的方法。下面就是这样一个例子,它在本文中起到了核心作用。
$\frac{\partial\theta^{*}(\epsilon)}{\partial\epsilon} = -H_{\theta^{*}}^{-1}\nabla_{\theta}\ell_{\text{S}}(x, y, \theta^{*}),$
$where\quad\theta^{*}:=\arg\min\limits_{\theta}\sum\limits_{(x', y')\in\mathcal{D}}\ell_{\text{S}}(x', y', \theta)$
但是,假设$\ell_{\text{S}}$是二阶可微分的,$H_{\theta^{*}}$是$\ell_{\text{S}}$的黑森。要想更深入地理解影响函数,下面这篇论文很有用:通过影响函数理解黑箱预测。
建议的方法
在介绍所提出的方法之前,我们先回顾一下半监督学习的总体情况。半监督学习有几种公式,以下是其中一种。
$\min\limits_{\theta}\sum\limits_{(x, y)\in\mathcal{D}}\ell_{\text{S}}(x, y, \theta) + \lambda\sum\limits_{u\in\mathcal{U}}\ell_{\text{U}}(u, \theta)$
然而,在上式中,未标记的训练数据集为$\mathcal{U}$,未标记的训练数据的损失函数为$\ell_{text{U}}$。$\lambda$是一个超参数,它出和的事实表明,我们对所有未标记的训练数据都给予了同等的信任。另一方面,本文提出的方法可以表述为:。
$\min\limits_{\theta}\sum\limits_{(x, y)\in\mathcal{D}}\ell_{\text{S}}(x, y, \theta) + \lambda\sum\limits_{u\in\mathcal{U}}\ell_{\text{U}}(u, \theta)$
和之前一样,$\lambda_{U}$是一个超参数,但我们可以看到它被唯一地分配给所有未标记的训练数据。这是否意味着你需要为每个未标记的训练数据$\mathcal{U}$手动设置超参数?你可能会这么想,但事实并非如此。我们将测试数据集$\mathcal{V}$与$\mathcal{D}$和$\mathcal{U}$分开准备,并寻找能使损失最小的超参数。
在上述基础上,提出的方法通过求解以下层次优化问题来优化预测因子$\theta$和超参数$\Lambda=\{\lambda_{1}, \cdots, \lambda_{|\mathcal{U}|}\}$。
$\min\limits_{\Lambda}\sum\limits_{(x, y)\in\mathcal{V}}\ell_{\text{S}}(x, y, \theta^{*}(\Lambda)),$
$where\quad\theta^{*}(\Lambda) := \arg\min\limits_{\theta}\sum\limits_{(x, y)\in\mathcal{D}}\ell_{\text{S}}(x, y, \theta) + \sum\limits_{u\in\mathcal{U}}\lambda_{u}\ell_{\text{U}}(u, \theta)$
为了以后的方便,我们将用另一种表达方式来重新表述。
$\min\limits_{\Lambda}\sum\limits_{(x, y)\in\mathcal{V}}\mathcal{L}_{\text{S}}(\mathcal{V}, \theta^{*}(\Lambda)),$
$where\quad\theta^{*}(\Lambda) := \arg\min\limits_{\theta}\mathcal{L}(\mathcal{D}, \mathcal{U}, \theta,\Lambda )$
在解决上述优化问题时,我们需要找到$\lambda_{u}$的梯度$\mathcal{L_{\text{S}}}(\mathcal{V}, \theta^{*}(\Lambda))$。这是在电脑上计算的一种不方便的形式。在本文中,我们使用一种称为Danskin定理的技术和本文开头介绍的影响函数来将这种梯度近似为可计算的形式。
$\frac{\partial}{\partial\lambda_{u}}\mathcal{L}_{\text{S}}(\mathcal{V}, \theta^{*}(\Lambda)) = \nabla_{\theta}\mathcal{L}_{\text{S}}(\mathcal{V}, \theta^{*})^{\mathtt{T}}\frac{\partial\theta^{*}(\Lambda)}{\partial\lambda_u}\quad$ (Danskin's Theorem)
$=-\nabla_{\theta}\mathcal{L}_{\text{S}}(\mathcal{V}, \theta^{*})^{\mathtt{T}}H_{\theta^{*}}^{-1}\nabla_{\theta}\ell_{\text{U}}(u, \theta^{*})\quad$ (influence function)
然而,我们定义$H_{\theta^{*}}=\nabla_{\theta}^{2}\mathcal{L}(\mathcal{D}, \mathcal{U}, \theta^{*}, \Lambda)$。影响函数自然包含在由Danskin定理得到的第一个方程中,这是一个整齐的形式。这种转换将一个在计算机上本质上无法计算的公式,变成了一个寻找损失函数梯度的问题,就像人们在一般问题环境中会发现的那样。
为了解决所提出的优化问题,我们需要找到$H_{\theta^{*}}^{-1}$,但反矩阵的计算一般需要很大的计算成本。在本文中,作为这个问题的解决方案,只对预测器的参数$\theta$进行部分优化。具体来说,只调整DNN最后一层的参数$\hat{\theta}\subset\theta$,就可以减少维数,减轻反矩阵计算。这是一种非常剧烈的方法,但后来的数值实验表明,它是有用的。
数值实验
文中描述的一些实验如下所示。
在第一个实验中,我们使用二进制分类的合成数据来展示所提出的方法的有用性。在本实验中,标注的训练数据数量为10个,未标注的训练数据数量为1000个(即我们假设未标注的数据数量非常多,以至于我们无法手动为每个数据提供超参数$\lambda_{u}$的情况)。我们还假设测试数据的数量为30个,模型为MLP(100个隐藏单元,ReLU)。现在让我们继续来看看实验结果。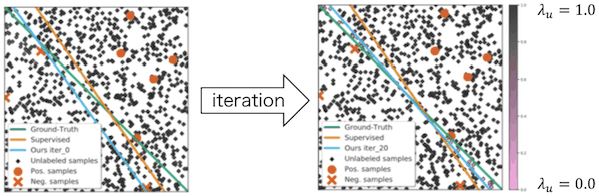
橙色圆圈和Xs分别代表正/负标签数据。另一方面,黑点和粉点代表未标记的数据,当它们接近$\lambda_{u}=1.0$时为黑色,当它们接近$\lambda_{u}=0.0$时为粉红色。绿线代表真正的决策边界。橙线代表了只使用标签数据时的决策边界(监督学习)。最后,浅蓝色的线代表了同时使用标记和未标记数据时的决策边界(半监督学习)。从图中我们可以看到,随着迭代次数的增加,浅蓝色的线越来越接近绿色的线,靠近决策边界的未标记数据的颜色越来越接近粉红色。
作为参考,我们还展示了使用不同合成数据集的实验结果。
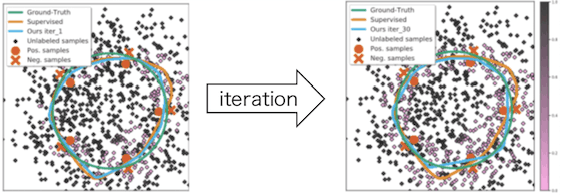
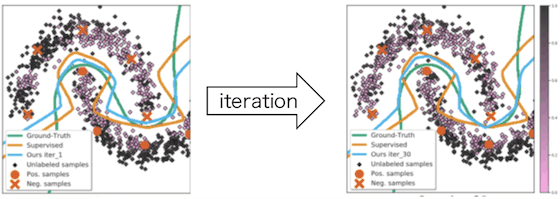
接下来,我们介绍的实验结果显示了本文介绍的$H_{\theta^{*}}^{-1}$的近似方法的有效性。虽然还有其他方法来近似黑森,但我们将把我们的方法与其中的两种方法(Luketina等,Lorraine等)的准确性进行比较。数据集为CIFAR-10,预测模型为ResNet。
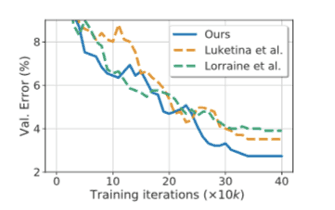
蓝色的断线是本文提出的方法。横轴代表迭代,纵轴代表测试数据集的误差。从这个结果可以看出,本文提出的黑森近似方法比其他方法更准确。
摘要
我们引入了一种扩展半监督学习的方法,以自动对每个未标记的数据进行加权。该方法本身的思想非常简单,但通过引入Danskin定理和影响函数,我们已经将其简化为一个可计算的公式。由于长期以来,关于降低标签成本的研究一直在积极进行,因此,分析一下与其他方法的关系和组合是很有意义的。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别

![[DeepCRE]最先进的计算模型正在彻](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/May2024/deepcre-520x300.png)



![[RL-GPT]在 Mincraft 中](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/March2024/rl-gpt-520x300.png)
