
使用少量数据也能获得高性能?
三个要点
✔️ 展示多重标记模型的有效性
✔️ 改善 PET/CT 病灶的错误识别
✔️ 展示纳入多重标记以及附加数据的重要性
Improving Lesion Segmentation in FDG-18 Whole-Body PET/CT scans using Multilabel approach: AutoPET II challenge
written by Gowtham Krishnan Murugesan, Diana McCrumb, Eric Brunner, Jithendra Kumar, Rahul Soni, Vasily Grigorash, Stephen Moore, Jeff Van Oss
(Submitted on 2 Nov 2023)
Comments: AutoPET II challenge paper
Subjects: Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
利用深度学习模型自动分割 FDG-18 全身 (WB) PET/CT 扫描中的病灶有助于确定治疗反应、优化剂量测定并推进肿瘤治疗的应用。然而,由于肝脏、脾脏、大脑和膀胱等器官对放射性示踪剂(其中一个或多个原子被放射性核素取代的化学物质)的吸收增加,深度学习模型可能会将这些区域错误地识别为病灶,这就带来了挑战。
针对这一问题,本文提出了一种同时分割器官和病灶的新方法,旨在提高自动病灶分割方法的性能。
PET/CT 的现状和挑战
正电子发射断层扫描/计算机断层扫描(PET/CT)是肿瘤成像的重要工具,有助于早期发现转移性疾病,量化代谢增生性肿瘤,并对癌症诊断、分期、治疗计划和复发监测做出重要贡献。
与此同时,深度学习算法的发展也为医学成像领域带来了革命性的变化,有助于更准确、更高效地分割获取图像中的癌症病灶。即使在传统方法因病变的复杂性、多变性和微妙性而无法分割的情况下,这些算法也能自主描绘肿瘤边界。
然而,不同患者对放射性示踪剂的吸收存在差异,而且放射性示踪剂的固有特性可能会导致其在大脑等新陈代谢活动旺盛的正常器官以及肝脏、肾脏和膀胱等净化器官中积累较多。这给自动病变分割算法带来了重大挑战,因为很难区分这些器官对放射性示踪剂的正常吸收和真正的病变。
假设与验证
在本文中,我们假设要解决病灶自动分割算法的问题,可以沿病灶分割出放射性示踪剂摄取量高的器官,这样模型就能结合器官是否为病灶的判别能力,我们测试了几种正在使用的我们已经测试了几种方法来验证这一点。
方法
数据和预处理
本文使用了来自 900 名患者的全身 FDG-PET/CT 数据(包括 AutoPET challenge II 2023 提供的 1,014 项研究)作为数据。此外,为评估本文所提算法的稳健性和通用性,本文还使用了一个由150 项研究组成的保留数据集(其中 100 项研究与训练数据库来自同一家医院,50 项研究来自另一家具有类似采集协议的医院),作为测试数据集。使用了由 150 项研究组成的保留数据集(其中 100 项来自与训练数据库相同的医院,50 项来自具有相似采集协议的另一家医院)。
作为预处理步骤,CT 数据被重新采样并归一化为 PET 分辨率。此外,两位专家分别对训练数据和测试数据进行了标注,其中一位是在混合成像 (一种医学成像技术,结合两种或多种不同的成像模式,更全面地反映人体内部结构和功能)领域有 10 年经验的放射科医生,另一位是图宾根大学医院的放射科医生。大学医院和慕尼黑 LMU 大学医院的一名分别在混合成像领域和机器学习研究领域拥有 5 年经验的放射科医生对所有数据进行了标注。
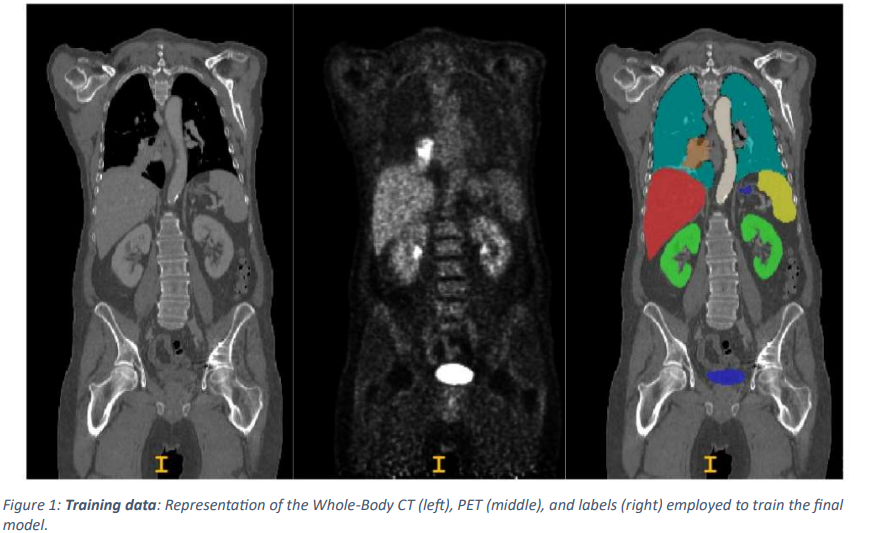
本文将训练数据随机分为五个部分,并在 nnUNet 框架内训练 3D UNet 模型,以分割多个器官和病变。
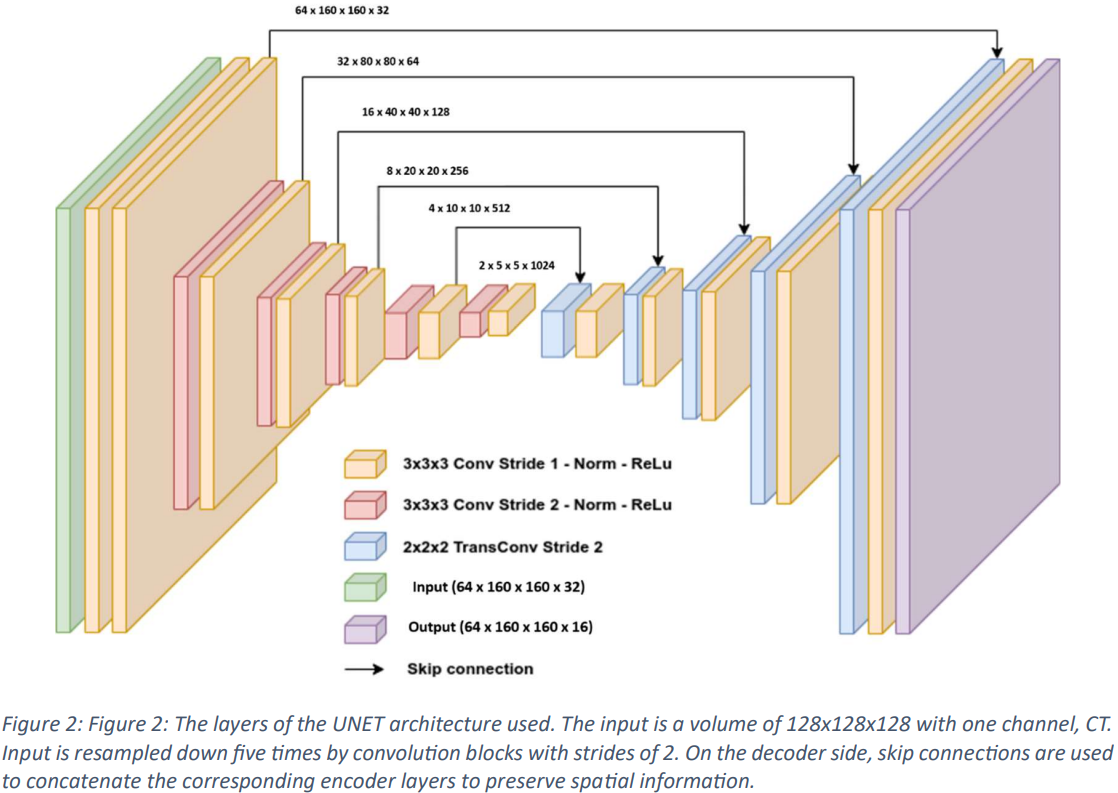
添加多个标签和数据的影响
为了评估所提出的方法,我们首先将训练数据分成两组实验(一组包含 819 项研究,另一组包含 195 项研究),然后在分割病变时添加更多标签(肝脏、脾脏、肾脏和膀胱)和更多数据,以提高模型性能。目前正在进行研究,以评估
本文特别关注两种不同的三维 UNET 模型,这些模型是为病变分割而设计的,并利用五段交叉验证法对模型进行了全面的训练和评估。
一个模型用于分离病变(单标签),另一个模型用于结合其他高摄入器官分割病变(多标签)。不过,高摄入器官的标签是使用已发布的总分割器得出的。这两种模型首先在由 819 项研究组成的数据集上进行训练,然后在由 195 项不同医学研究组成的另一个数据集上对其性能进行严格评估。通过评估,可以对模型在真实世界中的有效性进行评估。
此外,为了研究数据集大小对模型性能的影响,我们从最初的 819 项研究中随机选取了 100 项研究的子集,针对相同的分割目标(仅分割病灶:单标签模型;分割病灶和高摄入器官:多标签模型),训练了两个不同的模型。多标签模型),分别训练两个模型。然后使用相同的 195 项研究保留数据集对这些模型进行评估,以了解数据集大小对分割功能的影响。
AutoPET II 挑战赛
AutoPET II 挑战赛使用来自所有1,014 项研究的训练数据来训练多标签模型。另外八个器官(肝脏、肾脏、膀胱、脾脏、肺脏、大脑、心脏和胃)已被提取出来,并使用公开的 totalsegmentator 软件包添加到训练数据集中。
模型结构
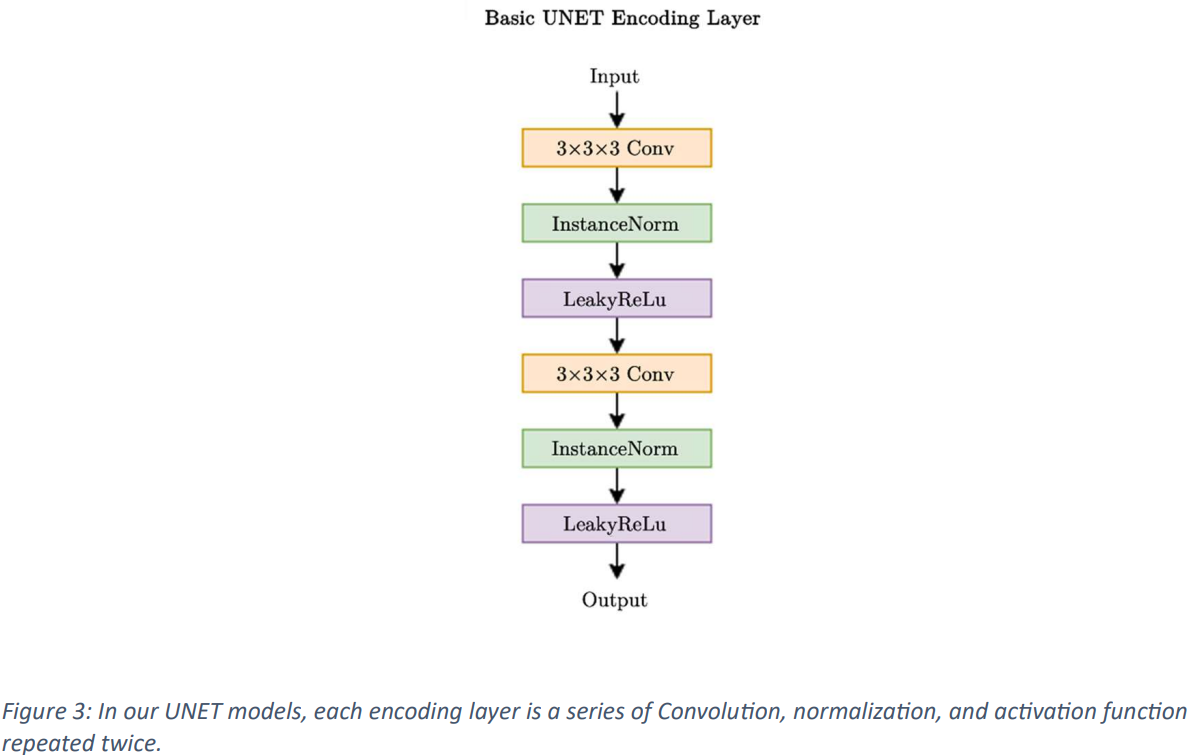
如图 2 和图 3 所示,本文使用的是标准变体 3D UNet 模型,其中包含用于训练的跳接连接。输入图像的尺寸设定为单通道 128x128x128,并使用 CT 扫描作为输入数据。输入数据通过 2 倍跨度的卷积块逐步降采样,经过五个阶段,在解码器一侧,相应的编码器层通过跳过连接进行组合,以存储空间信息。网络层结合了 InstanceNorm 并使用了 LeakyReLu。
初始架构采用 32 个特征图,在编码器的每次降采样操作中,特征图都会增加一倍,在解码器的反向卷积过程中,特征图又会减半,最后达到最大 1024 个特征图。解码器输出保持与输入相同的空间维度,然后经过 1x1x1 卷积产生单通道输出,并由 SoftMax 函数进行处理。在训练过程中,模型要经过五次以上的训练,使用的损失函数结合了杜斯-索伦森系数(DSC)和加权交叉熵误差,以确保不会出现训练过度的情况。
此外,还采用了随机旋转、随机缩放、随机弹性变形、伽马校正、镜像和弹性变形等扩展技术,以提高模型的鲁棒性。 使用学习率为 0.01 的 SGD 优化器,对五个模型中的每个模型进行了 1,000 次历时训练,批量大小为 8。性能评估包括骰子相似系数(DSC)和归一化表面骰子(NSD)等指标,以评估分割方法的不同方面。
核查结果
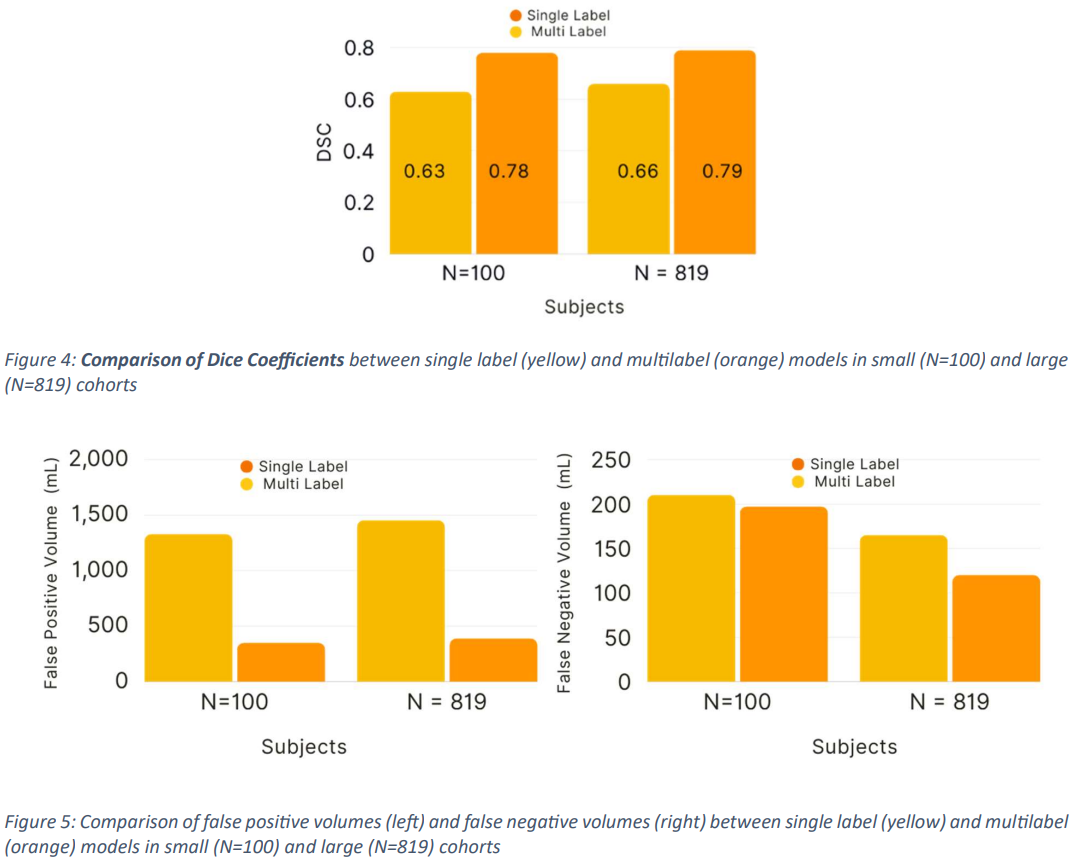
添加多个标签和数据的影响
本文采用骰子相似系数(DSC)、假阳性卷(FPV)和假阴性卷(FNV)作为评估方法。
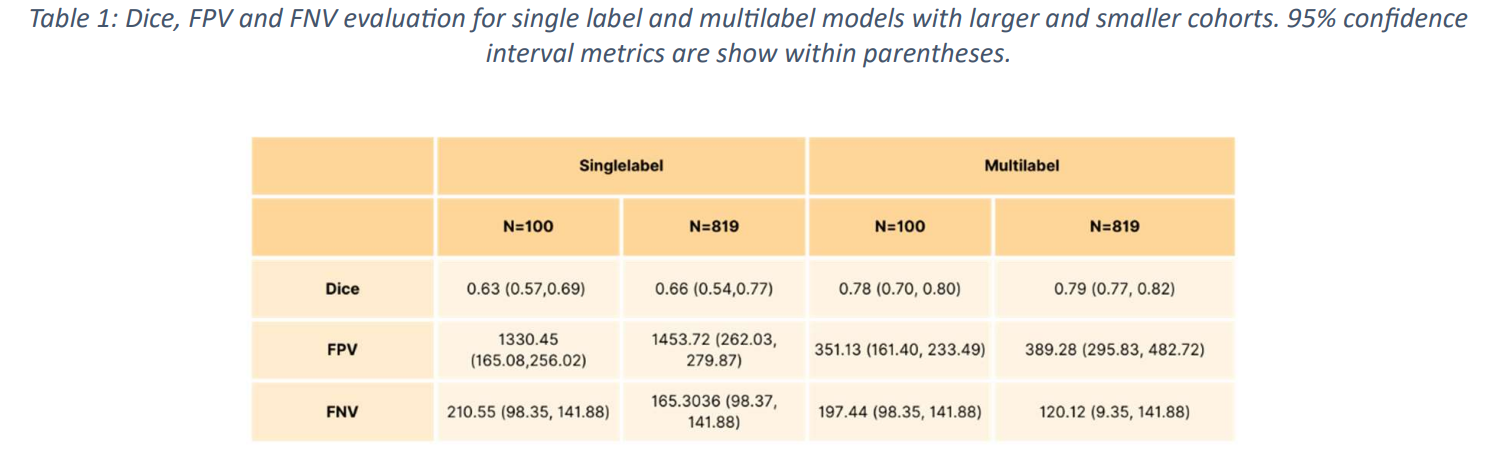
使用 100 项研究子集训练的模型显示,DSC 为 0.63+/-0.04(95% 置信区间 (CI):0.57, 0.69),FPV 为 1330.45(95% CI:165.08, 256.02),FNV 为 210.55(95% CI:98.35, 141.88)。%CI:98.35,141.88),而对于多标签分割,DSC 0.78+/-0.02 (95% CI:0.7,0.80)、FPV 351.13 (161.40,233.49) 和 FNV 197.44 (95% CI:98.35、141.88).
使用 819 项研究的整个数据集训练的模型也显示出较高的 DSC 分数,具体而言,单标签分割的 DSC 为0.66+/-0.08 (95% CI: 0.54, 0.77),FPV 为 1456.72 (95% CI: 262.03, 279.87),FNV 为 165.30 (95% CI: 98.37, 141.88);多标签分割的 DSC 为 0.79+/-0.02 (95% CI: 0.54, 0.77)对于多标签分割,DSC 0.79+/-0.02 (95% CI: 0.77, 0.82),FPV 389.28 (95% CI: 295.83, 482.72),FNV 120.12 (95% CI: 98.35, 141.88 )(图 4 和图 5)(表 1)。
由此可见,本文提出的多标签分割方法的准确性优于传统方法。
AutoPET II 挑战赛
本文所提方法的验证结果在 AutoPET II 挑战赛中取得了 xx 骰子、yy FPV 和 zz FNV 的优异成绩。
摘要
本文以分割医学图像数据中的病灶为目的, 训练并评估了两种不同的深度学习模型:一种是单标签模型,旨在只专注于病灶分割;另一种是多标签模型,旨在分割病灶和其他解剖结构 。研究结果表明,多标签模型效果明显。
它还证明了在增强深度学习模型的病变分割能力时,结合多个标签和额外数据的重要性。
多标签方法因其有效性和多功能性,有望得到进一步发展。



与本文相关的类别
![[DrHouse]利用传感器信息和专业知](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/drhouse-520x300.png)
![[SA-FedLoRA] 降低联合学习通](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/sa-fedlora-520x300.png)


![[SpliceBERT]使用生物物种遗传](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/splicebert-520x300.png)
![[IGModel]提高基于 GNN+At](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/igmodel-520x300.png)