
首先提高仿生精度:使用ViT进行登记:C2FViT。
三个要点
✔️ 建议用卷积和MHSA进行粗到细定位的C2FViT
✔️ 对现有方法所忽视的单纯仿生登记的性能进行定量分析
✔️ 与基于CNN的方法相比,性能和泛化表现更好,与不基于训练的方法相比,精度相当。
Affine Medical Image Registration with Coarse-to-Fine Vision Transformer
written by Tony C. W. Mok, Albert C. S. Chung
(Submitted on 29 Mar 2022 (v1), last revised 30 Mar 2022 (this version, v2))
Comments: Accepted by CVPR2022.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
粗细视觉变换器(C2FViT)是一种最先进的仿生登记方法,它结合了ViT和卷积的优点,以高精确度进行全局和局部配准,然后在多个分辨率下进行粗细变换,在脑部MRI数据上的表现优于现有的基于学习的方法。通过结合ViT和卷积的优势,准确地进行全局和局部配准,并在多个分辨率下以从粗到细的方式进行这些配准,所提出的方法在脑MRI数据上优于现有基于学习的方法。虽然所提出的方法的性能很重要,但也要注意到,单独的仿生登记的性能也已经用现有的方法进行了评估,这一点被忽视了。我们觉得这篇论文对于理解仿生注册的趋势至关重要。
主要贡献如下。
- 三维脑MRI图像中现有仿生登记方法的准确性、稳健性和泛化性能的定量分析。
- 拟议的C2FViT用于卷积ViT中的粗到细(粗到细)定位。
- 通过将仿生矩阵分解为平移、旋转、尺度和剪切参数,并对每个参数进行估计来进行概括。
- 在对MNI152模板进行标准化和基于图集的登记的两个实验中,表现出色,具有普遍性
让我们快速浏览一下C2FViT。
仿生登记
本文的重点是仿生登记。注册是在两个图像之间进行对齐的任务。通过了解一幅图像的一个区域在另一幅图像中的对应位置,它在医学上有广泛的应用,如监测同一病人的进展或比较不同病人的症状。该模型的目标是学习一个位移场A,使某个图像的移动变形,以匹配一个固定的FIXED。下面是本文中使用的数据集和模型注册的例子。

位移场所处理的变形大致可分为仿生变形和非线性变形。有两种方法,取决于如何处理它们。下表给出了每种情况的概述和缺点。

除非捕获仿生变形,否则对准的性能会大大降低。许多现有的方法包括一个两阶段的过程,首先通过仿生注册进行全局对齐,如平移、旋转和缩放,然后应用可变形注册来消除精细的非线性变形。这种方法的缺点是,第一阶段的仿生变换往往是在没有学习的情况下单独优化的,如凸优化或自适应梯度下降,这导致了巨大的处理时间。
另一方面,最近有一些方法不区分仿生和非线性变换,而是在CNN中单步学习和处理这些变换。虽然这种方法是快速的,但仿生变形也需要被CNN捕获。一般来说,图像之间的仿生变形往往是全局性的,所以只能捕捉内核局部变化的CNN方法并不合适。实验表明,现有的基于CNN的方法在具有较大错位的未知图像上表现不佳。
从粗到细的视觉变换器(C2FViT)。
基于以上原因,本文重点关注第一阶段的仿生登记,并提出了C2FViT,这是一个新的仿生登记模型 ,与现有的基于CNN的方法不同,它使用视觉变换器.它还引入了一个卷积层,以引入适度的归纳偏差,并且是一个从粗到细的估计模型,使用多个分辨率,从全局变化中反过来估计局部的变化。
仿生矩阵的分解
C2FViT独立估计仿生矩阵的四种参数矩阵。仿生变换用以下公式表示。这个方程可以用来平移、旋转、缩放和剪切图像。(x,y)是要应用的图像中每个像素的位置,(x',y')是仿生变换之后的坐标。仿生登记的目的是估计这个矩阵的参数。
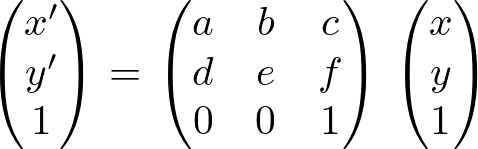
现有的方法经常估计上述方程,但上述方程的通用性较差,因为它是一个同时进行四种不同类型转换的方程。由于仿射变换允许四个不同的变换中的每一个独立进行,所以最好能够独立地估计平移、缩放、旋转和剪切,以增加登记的范围。例如,可以通过将缩放矩阵和剪切矩阵从四个变换中排除来进行刚体登记。因此,C2FViT独立地估计翻译、缩放、旋转和剪切参数。
注意力和折叠之间的兼容性
(下图中的(c)是所提方法的概览图,而(a)和(b)是现有的基于CNN的方法。基于串联的方法(a)在同一个单一网络中处理移动和固定,但自然不适合仿生登记,因为它不能捕捉大于核大小的依赖关系。在(b)中,为固定和移动准备了单独的网络。每个网络都通过最后的全局平均汇集来整合特征,所以在一定程度上可以进行全局估计,但另一方面,局部关系被忽略了。
另一方面,所提出的C2FViT方法同时处理图像对,但在MHSA层捕捉全局关系,同时也在卷积层平衡局部特征。变化是在补丁嵌入和前馈层。普通的ViT使用线性投影将输入图像中的局部斑块转换为Q、K和V,而C2FViT使用三维卷积层获得斑块嵌入,以强调局部特征。此外,虽然正常的ViT将每个补丁独立地通过前馈层,但C2FViT将MHSA层的输出重新定位在三维空间,并应用三维深度卷积来进一步加强模型的定位。它在图中表示为卷积前馈(Convolutional Feed-Forward)。

所提出的方法将这个卷积补丁嵌入和N个变换器编码器过程作为一个单一阶段来建立。
多分辨率战略
C2FViT采取一步步的方法来消除多个分辨率下的仿生形变。首先,对移动的固定集合M,F以不同的尺度下采样,创建图像金字塔Mi,Fi,其中i的范围是1~L,Mi,Fi以0.5^(L-i)的尺度下采样。这意味着较小的i会导致较低的分辨率、全局注册,而i=L会导致在原始图像尺寸下的高分辨率注册。

建议的方法执行L(=3)个阶段的逐步排列,每个分辨率有一个阶段的处理。最初,最低分辨率的F1和M1被对齐。这时得到的位移场A1由空间变换反映在下一个分辨率M2中,以便进一步对准。此外,前一个分辨率的特征被添加到下一个卷积补丁嵌入中,使粗到细的登记考虑到前一个低分辨率的特征和排列。
无监督的损失
对齐的损失是通过评估实际的移动变换图像是否与估计的参数FIXED匹配而得到的。在这个模型中,在每个分辨率i上计算出相似性度量NCC的负值,并将其相加:NCC的索引w是局部窗口,Mi(Φ)是对齐后的图像。
![\begin{align*}
\mathcal{L}_{sim}(F,M(\phi))=
\sum_{i\in[1...L]}-\frac{1}{2^{(L-i)}}\mathrm{NCC}_w(F_i,M_i(\phi))
\end{align*}](https://texclip.marutank.net/render.php/texclip20230122232944.png?s=%5Cbegin%7Balign*%7D%0A%20%20%5Cmathcal%7BL%7D_%7Bsim%7D(F%2CM(%5Cphi))%3D%0A%20%20%5Csum_%7Bi%5Cin%5B1...L%5D%7D-%5Cfrac%7B1%7D%7B2%5E%7B(L-i)%7D%7D%5Cmathrm%7BNCC%7D_w(F_i%2CM_i(%5Cphi))%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
半可教化的损失
之前介绍的DIR模型VoxelMorph可以在半监督的情况下进行训练,如果固定和移动有典型的几何结构的分割掩码,这个模型也可以做到。这是因为通过评估对齐后的分割掩模的重叠情况,可以更直接地评估登记情况。它可以通过在无监督损失Lsim的基础上增加以下Lsig来扩展到半监督学习。损失是通过计算每个分辨率下的分割掩码SFi和SMi重叠的负值来计算的,其中K是分割掩码的数量。假设权重λ=0.5。
![]()
![\begin{align*}
\mathcal{L}_{seg}(S_F,S_{M}(\phi))=
\frac{1}{K}\sum_{i\in[1...K]}\left(1-\frac{2(S_F^i\cup S_M^i(\phi))}{|S_F^i|+|S_M^i(\phi)|}\right)
\end{align*}](https://texclip.marutank.net/render.php/texclip20230122235000.png?s=%5Cbegin%7Balign*%7D%0A%20%20%5Cmathcal%7BL%7D_%7Bseg%7D(S_F%2CS_%7BM%7D(%5Cphi))%3D%0A%20%5Cfrac%7B1%7D%7BK%7D%5Csum_%7Bi%5Cin%5B1...K%5D%7D%5Cleft(1-%5Cfrac%7B2(S_F%5Ei%5Ccup%20S_M%5Ei(%5Cphi))%7D%7B%7CS_F%5Ei%7C%2B%7CS_M%5Ei(%5Cphi)%7C%7D%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
详细设置
卷积补丁嵌入的输出通道数d被固定为256,地图大小被扁平化为4096维。看来,跨度和填充核的大小是相对于输入地图的大小确定的,以始终保持一个恒定的维度嵌入。在常规的ViT中采用了层归一化,但由于它在这个方法/任务中不起作用而被删除。
实验
实验验证了所提方法在标准化的三维脑磁共振图像任务和基于图集的仿生注册任务上的性能,以验证所提方法的优越性。
任务概述。
标准化到MNI 152。
MNI152是一个脑部成像的模板。它将每个受试者的大脑标准化,以匹配一个标准的大脑(模板),以便整合对大脑的不同研究。这可以实现统一的坐标系统和比例及解剖学上的对应。由于将所有人类的大脑合并为一个大脑是很奇怪的,因此进行了改进,使用几个已经标准化的人的大脑的平均值作为模板。这个过程进行了多次改进,最后152个大脑被标准化,形成了平均大脑,也就是MNI152。本文将OASIS数据集注册到MNI152,并验证了一个有代表性的注册任务的性能。
基于地图集的登记
这项任务涉及到对数据集中的每幅图像本身的登记,而不是对平均大脑的登记。在训练中,这些配对是在OASIS数据集上随机选择的。在测试时,我们在OASIS数据集和一个未知的LPBA数据集上注册。其目的是通过将模型应用于相同和未知的数据集来测试模型的性能和泛化性能:从OASIS中随机选取三个,从LPBA中随机选取两个作为图集,将每个数据集的测试数据注册到图集中。
数据集
OASIS数据集。
这个数据集由414张T1加权的脑部MRI图像组成。在本文中,使用FreeSurfer进行了重采样和填充等预处理;按Train:Valid:Test=255:10:149划分。
LPBA数据集。
这个数据集由40张脑部MRI图像组成。本文都是作为测试数据使用的。
基准线
所有模型都在三种分辨率下进行了优化。建议的方法中,L=3。
非学习型
传统的基于非训练的注册使用ANTs和Elastix作为SoTA模型;两者都是通过适应性梯度下降法使用相互信息内容进行优化。
以学习为基础
现有的两种方法是ConvNet-Affine和VTN-Affine。每个人都只参照论文构建仿生网络。所有基于学习的方法都被扩展到半监督状态,并分别表示为ConvNet-Affine-semi、VTNAffine-semi和C2FViT-semi。
评价
进行了四项评估:Dice相似性系数(DSC)、所有案例中最低的30%的DSC(DSC30)和Hausdorff距离的95%的百分位数(HD95)是注册精度第四个是T检验,它描述了执行时间,它在未学习和学习基础之间有显著的差异。标准化包括用于的4个皮层下结构--尾状核、小脑、枕叶和丘脑的掩模,用于OASIS的23个皮层下结构,以及用于LPBA的。
这是因为CoM初始化通常是在。
准确性和稳健性
第一个结果是当CoM初始化没有被执行时。可以看出,在预定位状态下,所有数据任务的Dice得分都很低,说明错位很大。所提出的方法在DSC、DSC30和HD95三个任务中都优于ConvNet-Affine和VTN-Affine,表明它在大错位的仿生登记中是稳健和准确的。相反,现有方法的仿生子网络被发现对大的错位是不够的。

接下来是有CoM初始化的准确性。对齐重心后,Dice得分分别从0.14、0.18和0.33提高到0.49、0.45和0.45,这表明对齐只通过平移大致实现。所有基于学习的方法在CoM初始化的情况下都有明显的精度提高,但特别是,所提出的方法在无监督模型C2FViT方面达到了与ANTs和Elastix相同的精度,而半监督模型C2FViT-semi被标准化为MNI152和OASIS的基于Atlas的登记,并取得了最高的准确性。

归纳性能
LPBA数据集的准确性与其他两个任务的准确性不同。可以看出,现有的ConvNet-Affine和VTN-Affine方法在有无CoM和扩展到-semi的情况下都完全不能对齐,Dice得分与初始值几乎没有变化。另一方面,C2FViT的准确度略低于Elastix,但几乎能够对准,考虑到Elastix是一个单独的优化,而C2FViT将OASIS-only学习应用于LPBA,C2FViT与现有方法相比具有很强的泛化性能。可以看出,。
结果显示,与具有巨大执行时间的ANT、Elastix和不太健壮的学习基础相比,在执行时间、准确性和泛化性能方面有明显优势。
仿生矩阵的分解
我们还对所提出的直接估计仿生矩阵的方法和DECOUPLY估计方法进行了准确的比较,DECOUPLY被分解成前面描述的平移、旋转、缩放和剪切。如表所示,发现decentouple估计更准确,而且还具有通用性,可以很容易地应用于其他参数化注册。

摘要
本期介绍了用于三维医学图像仿生登记的粗-细视觉变换器(C2FViT)。与以往使用基于CNN的仿生登记的研究不同,全局重点是通过自我关注进行全局特征提取。通过卷积的适度定位与粗到细的定位相结合,C2FViT取得了比基于CNN的方法更好的注册精度。在大错位的数据下,C2FViT与现有方法的差异特别大,而且它还显示出对未知数据集的鲁棒性。半监督的C2FViT-semi通过利用数据集的特定信息,在准确性、稳健性、运行时间和泛化性能方面显示出优势,超越了非训练的方法。
作为一项挑战,它提高了基于无监督学习的方法和传统的非训练方法之间的准确性差距。报告指出,针对特定任务的数据增强可能会导致准确性的提高。我们期待着未来的发展。



与本文相关的类别

![[DrHouse]利用传感器信息和专业知](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/drhouse-520x300.png)
![[SA-FedLoRA] 降低联合学习通](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/sa-fedlora-520x300.png)


![[SpliceBERT]使用生物物种遗传](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/splicebert-520x300.png)
![[IGModel]提高基于 GNN+At](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/igmodel-520x300.png)