总结了Transformer为医学成像带来的成就。
三个要点
✔️ 医学成像和变压器的全面回顾
✔️对检测、分类、重建、综合、注册、临床报告和其他任务进行了审查,最新信息可在作者的GitHub上找到。
✔️变压器已经渗透到医学影像领域的所有领域,并被发现进展过快。为了解决这个问题,应该在会议上组织研讨会,在期刊上刊登特写,并向社会迅速传播相关研究。
Transformers in Medical Imaging: A Survey
written by Fahad Shamshad, Salman Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, Huazhu Fu
(Submitted on 24 Jan 2022)
Comments: Published on arxiv.
Subjects: Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
摘要
变换器在自然语言领域取得了成功,也被应用于计算机视觉(CV)领域,其中卷积神经网络(CNN)占主导地位,虽然变形金刚正在吸引越来越多的兴趣。在医学领域也是如此,本文全面回顾了变形金刚在捕捉整个图像中的局部环境方面是如何优于具有局部感受区的CNN的。
简介
CNN对医学成像领域产生了重大影响。在许多领域,包括放射摄影、内窥镜、CT、MRI、乳腺摄影、PET和超声,都有明显的改进报告。然而,CNN由于其本身的性质,并不擅长捕捉局部图像与整个图像的关系,或者图像中的远处物体之间的关系。
另一方面,由注意力机制(注:文中写成Attention)启发的新架构已经在CV领域进行了探索。然后,基于注意力的变形器使得学习长距离的依赖关系作为有效的特征表征成为可能,这是解决上述问题的一个有吸引力的方案。最近的研究表明,标准的CNN可以完全被变形器所取代,从而产生了视觉变形器(ViTs),自其诞生以来,已经取得了显著的成绩。分类、检测、分割和色彩化。研究还表明,ViTs的预测误差与人类的预测误差相似,这也引发了人们对医学领域的兴趣。
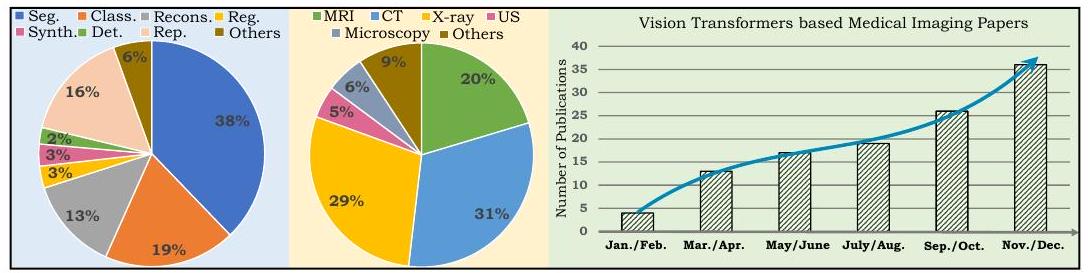
左边的饼图显示了本综述所涉及的论文分类,其中Seg表示分割,Class表示分类,Recons表示重建,Reg表示注册,Synth表示合成,Det表示检测,Rep表示报告,US表示超声。右边的图表显示了2021年发表的关于ViT在医学成像中的应用的论文数量,显示了快速增长。
背景介绍
手工制作的数学模型
医学成像任务中的传统算法是基于专家设计的数学模型(手工制作的方法)。这种方法朝着计算密集度低和适用于更多组织的方向进行了改进。其结果是建立了具有数学基础的可解释和稳健的模型,并在医学领域得到广泛使用。该方法与今天的深度学习不同,不需要大型数据集或注释。
基于CNN的方法
CNN是一种从大型数据集中自动学习判别特征的方法。它们在医学成像方面表现良好,是现代基于人工智能的医疗系统的一个组成部分。然而,CNN的性能依赖性(基本上)取决于数据集的大小,这限制了它们对医学领域的适应性。此外,CNN的推断结果一般很难解释,而且经常以黑箱方式运作。
基于变压器的方法。
在自然语言领域,Transformer被报道为一个注意力驱动的块。注意力是一个从整个输入序列中聚合信息的NN,自从引入注意力以来,一些模型已经改写了最佳性能。它现在是模型选择的第一选择。
ViT是一个通过连接多个Transformer层来捕捉输入图像的全局背景而建立的模型。
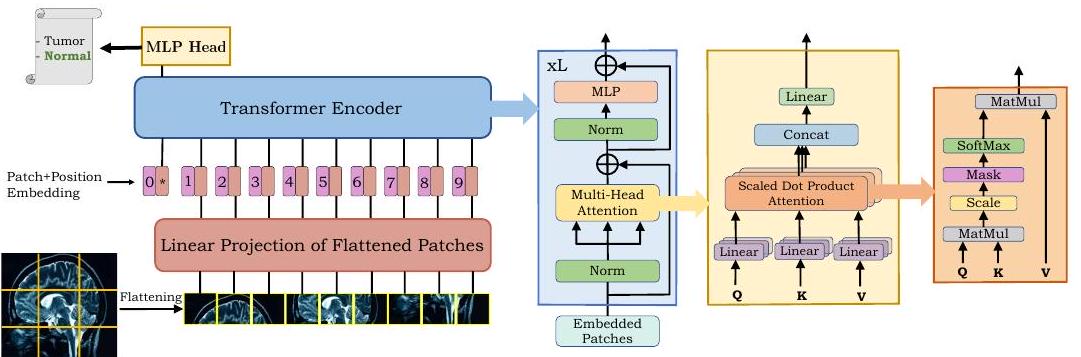
如上图所示,ViT将图像分为瓦片(patches)并按顺序排列。这个序列由Transformer进行编码,以产生最终的输出。
自我关注
Transformer的成功归功于自我注意机制(self-attention, SA),它建立了长距离依赖的模型。自我注意的关键思想是确定整个序列中单个标记的相对重要性。
多头自留地
多头自我注意(MHSA)由多个块(头)组成,以模拟输入序列的复杂依赖关系;MHSA允许学习复杂的上下文,但注意的计算成本很高,这可能是医学上的一个限制。这是医学成像的一个限制,因为在医学成像中,像素的数量往往很高。因此,人们提出了改进的、更有效的医疗图像处理的注意。
分割领域
首先概述了医学图像的分割。分割在计算机辅助诊断(CAD)、图像引导的手术和治疗计划中非常重要。例如,器官有很大的空间范围,所以需要对遥远的像素之间的关系进行建模。这就是Transformer的全局上下文建模能力的用武之地。相反,超声图像的背景是嘈杂和散乱的。对背景进行建模使其有可能识别出诊断所需的区域。
器官分类。
二维分割
Wang等人将ViT应用于皮肤病变。
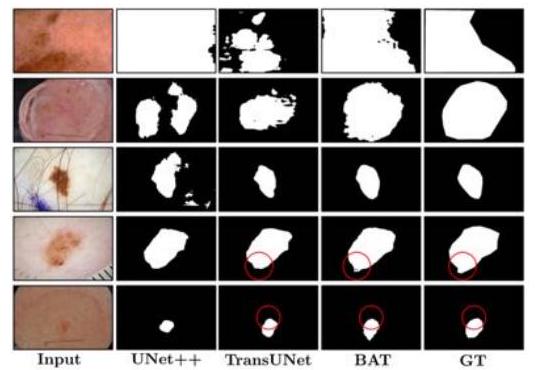
他们提出了边界感知变换器(BAT),并成功地提取了黑色素瘤和正常皮肤之间的清晰边界。
其他基于ViT的方法已被提议用于牙根、血管、肾脏肿瘤、细胞和病变。
三维分割
Wang等人利用Transformer对脑瘤的空间特征进行建模。他们提出的TransBTS使用一个三维CNN来提取局部三维空间,而Transformer编码更多的全局特征。与简单的CNN相比,TransBTS值得注意的是它的有效性,以及消除了在大型数据集上进行预训练的需要,而传统的ViT需要预训练。
Zhu等人在乳腺癌中进行了三维分割。所提出的方法,RAT-Net,优于以前提出的CNN和基于ViT的方法。
多器官分割
多器官分割涉及到一次对几个器官的分割。由于类别之间的不平衡,器官大小、形状和对比度的差异,它是一项比单器官分割更困难的任务。
纯粹的转化器。
纯粹基于变压器的架构只包括一个ViT层。由于分割需要两个角度,即全局和局部,混合CNN-变换器架构经常被提出,基本上Karimi等人提出了一个由纯ViT层组成的模型,并在三个基准上显示了其有效性。他们在三个基准集上证明了其有效性:大脑皮层、脾脏和海马体。
混合结构
已经提出了混合架构,使用变形金刚来模拟全局环境,并使用CNN来精确分割。最早提出的方法是TransUNet,它使用12个变压器层。
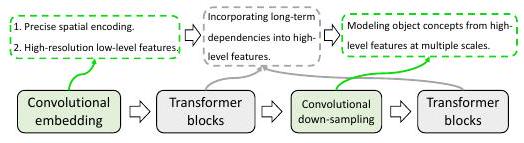
如上所述,Transformer和CNN被连接在一个混合架构中,这样它们就可以展示各自的优势。
分割中的混淆。
基于ViT的细分已经得到了极大的关注,每年有50多份报告。在这个领域,简单地将基于CNN的方法转换为基于Transformer的方法,在大多数情况下都能提高性能。然而,高计算成本是医学成像领域的一个限制。
许多ViT模型也利用了ImageNet中的预训练模型。然而,有人指出,自然图像和医学图像之间存在着模式上的差距,这使得它们不适合用于预训练。最近关于预训练中使用的图像模式的研究表明,在CT上预训练的模型在应用于MRI时表现并不令人满意。这种模式上的差异是未来研究的课题。
医学图像分类
肿瘤是身体组织的异常生长,可以是良性的也可以是恶性的。他们的诊断对治疗计划至关重要,并对病人的生存率有很大的帮助。
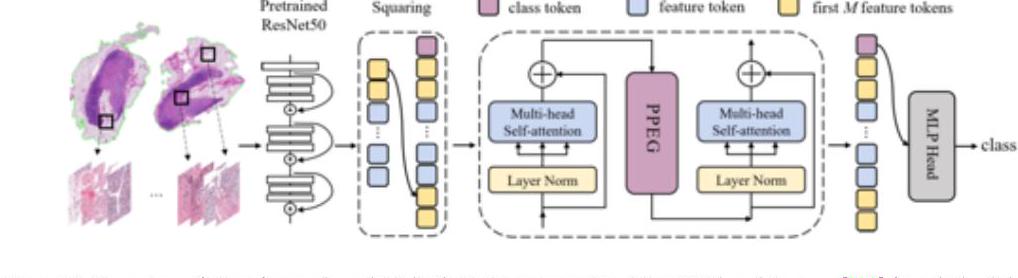
在上面的TransMIL中,整个幻灯片图像(WSI)的补丁被嵌入到ResNet-50特征空间中;TransMIL实现了乳腺、肺和肾脏三种组织的SOTA。
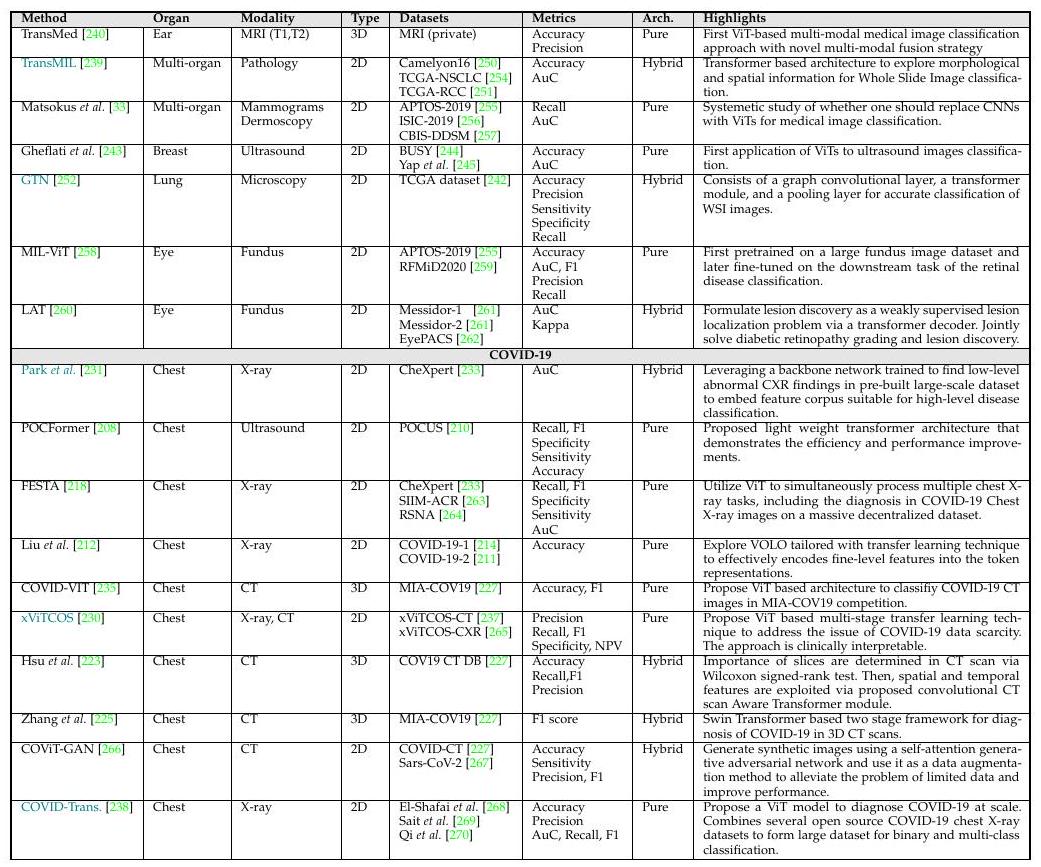
以上是基于ViT的医学图像分类的概述。蓝色显示的方法是同时显示Grad-CAM可解释性的模型。
分类讨论
在分类任务中,我们发现大多数研究都使用了原始的ViT,没有做任何改变(即插即用)。因此,希望增加特定领域的架构、损失函数设计等,在未来能提出有效的基于ViT的模型。
医学成像中的物体检测。
医学成像中的物体检测是指感兴趣区域(ROI)的定位,例如,在胸部X光片中寻找肺部结节。变压器以达到更高的性能。其中许多方法都是基于检测转化器(DETR)框架。
Shen等人提出的COTR已被应用于T2加权MR图像的息肉检测和淋巴结检测,并显示出比DETR更好的性能。
关于物体检测的讨论
与分割和分类研究相比,基于变换器的物体检测模型数量很少,这与基于CNN模型的物体检测的早期发展形成鲜明对比。因此,预计在不久的将来,会有更多基于变压器的研究报告。
医学成像中的重建。
重建领域的目标是从退化的输入中获得一个干净的图像(注意:重建的字面翻译是reconstruction,它的含义很广。(最好把它看成是恢复和纠正的一个通用术语)。
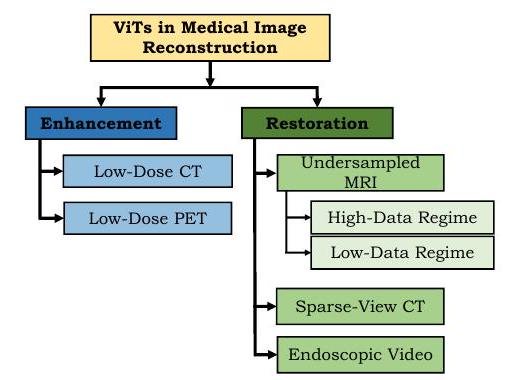
ViT在图像增强方面取得了显著的成果。低剂量放射线照片是模糊的,但通过提高图像质量,有可能保持或提高诊断的准确性,同时减少辐射暴露。
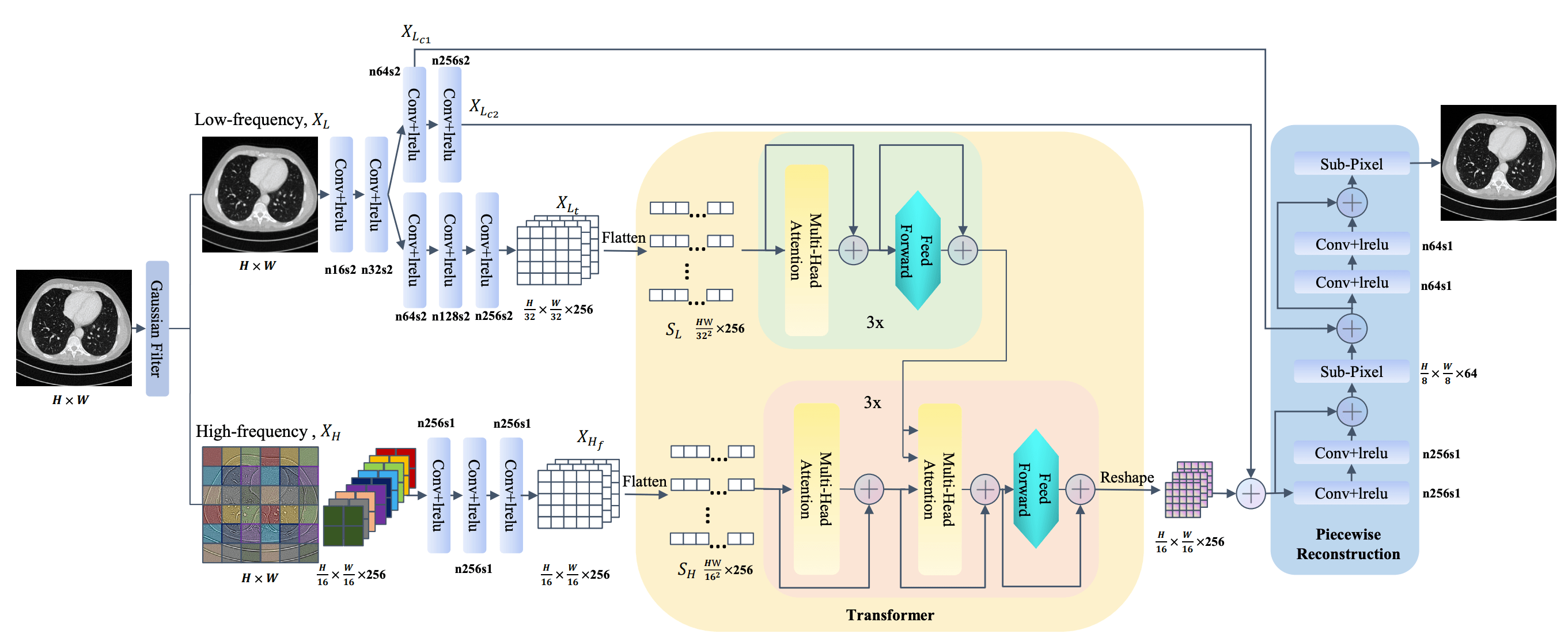
如上所示,Zhan等人提出了TransCT,有效地增强了低剂量CT图像。
同样,减少MR中每个截面的测量次数也可以减少由于身体运动造成的伪影;Feng等人提出了MTrans,与传统方法相比取得了良好的效果。
重新配置的讨论
我们在本综述中调查了12篇论文,其中许多是针对CT图像的。此外,由于该方法是通用的,我们预计未来的工作将在损失函数和架构方面更加针对具体任务,这将导致进一步的性能改进。
医学图像合成
在将ViT应用于医学图像合成时,许多方法都加入了对抗性损失。这个领域有两大类:模式内(intra-modality)和模式间(inter-modality)合成(注:模式是指成像的类型,如CT、MR)。
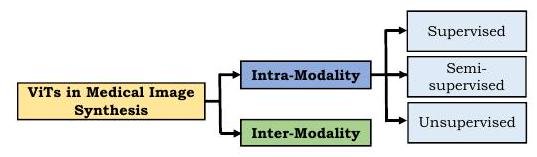
有人提出了监督、半监督和无监督的学习方法,用于同一模式的合成。监督学习需要一对教师图像和相应的目标图像,这是很昂贵的,不仅是对医学图像。医学图像因收集的难度和注释的成本而受到额外限制。然而,Zhang等人提出了PTNet来合成婴儿大脑MRI,并证明该模型在质量和数量上都优于之前提出的pix2pix和pix2pixHD。此外,PTNet不仅因其高性能而引人注目,而且其执行时间适中,每幅图像的合成时间约为30秒。
模态间方法接收不同模态的图像并输出一个目标图像;模态间方法只使用监督学习,因为它是一个模态转换任务。
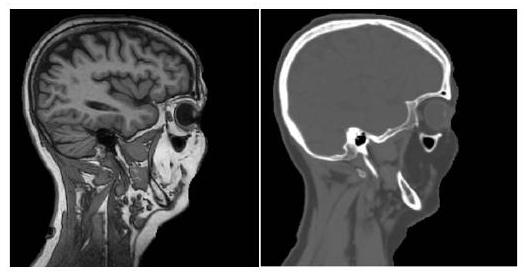
如上图所示,跨模式方法将MRI(左)转换为CT图像(右)。结果是非常好的,外观完全不同。
医学图像合成的讨论
一般来说,临床决策涉及到多种模式的图像,以互补的方式进行(注意:CT观察硬组织,如骨骼和牙齿,而MRI观察软组织,如肌肉、大脑和肿瘤)。然而,从成本的角度来看,多模态图像并不总是可用的;人们发现基于变换器的图像合成比基于GAN的方法能产生更真实的图像,有效避免了这些问题。
医学图像的注册
注册是指两个图像之间的对齐。例如,如果CT和MR图像是为同一个病人拍摄的,由于图像的位置和身体的细微扭曲,两个图像不会完全重叠;在登记领域的目的是确定两个图像的位移并建立对齐。
Chen等人提出的TransMorph揭示了静态图像和视频之间的对应关系。为了捕捉输入图像和视频之间的语义对应关系,它由Swin Transformer进行编码,随后的解码器推断出位移。
关于注册的讨论
在目前阶段,Transformer在注册领域的应用并不广泛,很难进行总结。然而,基于变压器的一般成像方法正在发展,预计未来将在医学领域发展。
报告
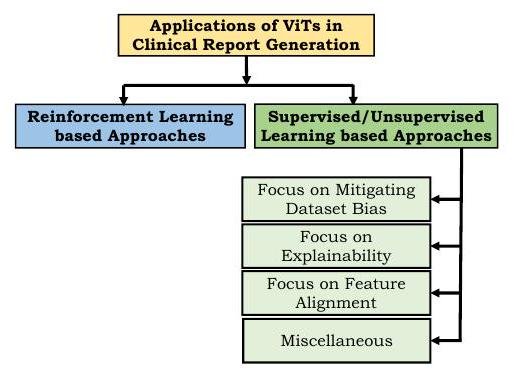
近年来,从医学图像中自动生成报告的研究领域得到了发展。然而,创建阅读报告或添加标题的任务是非常具有挑战性的,因为人类(放射科医生)写的报告本身是多种多样的,而且长度不一。
这项任务要求两点:第一,语言表达是人类可读的,第二,内容在医学上是准确的。
基于强化学习的方法使用所使用的医学术语、人类评分等作为奖励;最早尝试使用Transformer的方法之一是由Xiong等人提出的用于医学图像字幕的强化转化器(RTMIC)。(RTMIC)。它包括一个密集网络来识别医学图像的ROI,以及一个基于变形器的编码器来提取视觉特征,而解码器部分则是生成字幕。
监督和非监督学习方法使用可区分的损失函数来训练诊断写作的模型。然而,许多医疗报告中描述正常的句子远远多于描述异常的句子,导致了数据集的偏差。为了减少这种偏差,Srinivasan提出了一种使用Transformer作为解码器的分层分类方法。该架构由异常检测部分(对图像进行正常或异常分类)、图像的标签生成部分、以及由图像特征和标签生成句子部分组成,并在胸片上证明了其有效性。
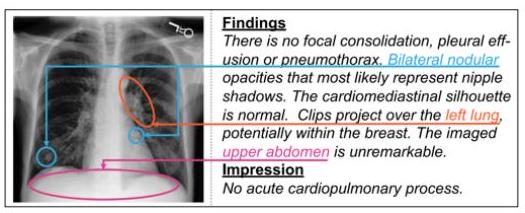
为了提高对模型的信心,还试图指出图像的哪些部分对所产生的文本有意义。
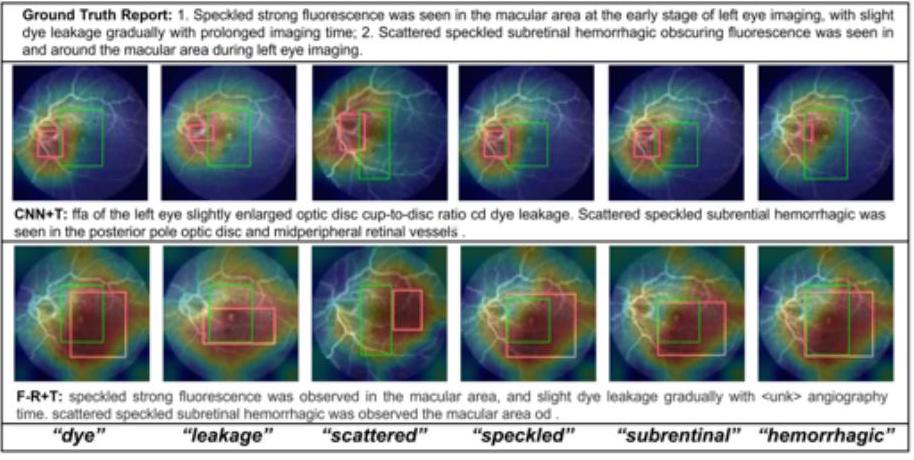
如上图所示,在CNN+变换器和Faster-RCNN+变换器模型中,可以显示文字和焦点区域之间的对应关系:很明显,染料(染色)和泄漏(渗漏)这两个词是从图像的哪个部分被召回的。染料和泄漏这两个词可以从图像的哪个部分清楚地识别出来,它们是被召回的。
关于报告写作的讨论
到目前为止,对ViT的审查主要集中在Transformer作为报告时的强大语言模型;尽管自2017年以来Transformer的影响惊人,但关于临床报告的报告数量一直是报告很少。
基于转化器的模型使用自然语言生成(NLG)指标,如CIDEr和BLEU。然而,NLG指标并不能很好地评估临床表现。相比之下,基于强化学习的方法使用人类的主观评分作为奖励,所以生成的报告能更好地捕捉到疾病和解剖结构。
此外,每一种模式,如CT、MRI和PET,都有不同的临床成像目的,因此特定的模式存在着特定的临床背景。因此,从每种模式生成报告有其自身的挑战,因为每种模式都需要单独评估。
其他。
下面将介绍变压器的其他应用。近年来,Transformer在预测癌症死亡的相对风险的回归任务中取得了显著的成功。Chen等人提出了一种名为MCAT的方法,该方法基于多模态信息--遗传信息和活检标本--预测生存率。
其他建议包括PubMedCLIP(对比性语言-图像预训练),用于从PubMed文章中学习图像和标题,以及3DMPT用于分析3D医疗数据。
未来的方向。
本节介绍了ViT在医学成像方面的前景。
先前的学习
ViT对局部视觉特征的建模没有归纳偏向,因此需要在大型数据集上进行预训练。然而,在医学领域收集大型(注:在Transformer的背景下,数千万到数亿张图像被认为是大型)数据集是很困难的,而且会成为一种限制。许多报告在ImageNet上使用预训练,但自然图像和医学图像有不同的特点。CNN和ViT的特点总结如下。
- 当用随机权重初始化时,CNN在医学图像分类任务中的表现优于ViT。
- 在医学图像分类中,CNN和ViT也可以从ImageNet的初始化中大大受益。特别是,ViT似乎通过过渡学习在医学和自然图像之间架起了桥梁。
- CNN和ViT在自我监督的预训练中表现良好,如DINO和BYOL,ViT在这种情况下似乎略胜于CNN。

以上是ViT在医学图像上的预训练的性能评估。该图比较了在CT图像上预训练的Swin UNETs的模子系数(蓝色)和没有预训练的Swin UNETs的模子系数(橙色),显示Swin UNETs在医学图像上预训练时表现更好。
可解释性
变形器在医学成像领域也取得了成功,但在可解释性方面没有产生令人满意的结果。尽管ViT具有良好的性能,但它在医学影像领域是以黑箱方式使用的,尽管一些研究提到了可解释性,但总体上它仍处于起步阶段。目前仍不可能明确地对图像的不同部分如何相互作用进行建模。尽管注意力在本质上适合于可解释性,但医学图像的可解释性是一个开放的问题。
稳健性
敌意攻击的进展表明,现有的成像网络很容易受到扰乱。不可避免的是,医学影像领域的巨大研究资金,特别是与诊断有关的研究资金,使其成为攻击的目标。例如,攻击者可能会篡改医疗成像系统并伪造报告,以欺诈性地获得保险和医疗报销费用。
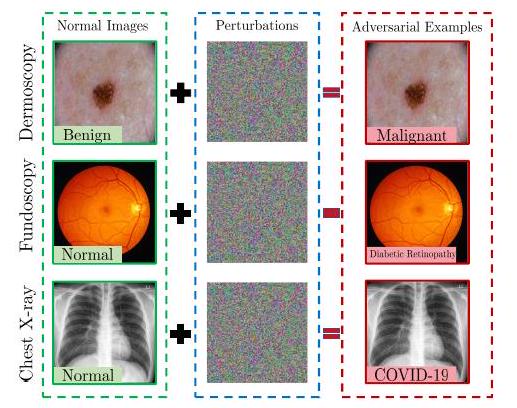
虽然有大量关于CNN稳健性的报告,但据我们所知,还没有关于ViTs的此类报告。近年来,人们对针对ViT的攻击和鲁棒性进行了一些尝试,当总结出一些差异时,发现ViT对对抗性攻击比CNN更鲁棒。如前所述,由于自然图像和医学图像的特点不同,对抗性攻击也需要针对医学图像,而采用ViT的医学图像处理系统的稳健性还有待评估。
边缘人工智能与ViT。
尽管ViT在医学成像方面已经取得了成功,但它的计算成本仍然很高。这阻碍了它在资源有限的边缘计算中的部署。然而,医疗保健领域对边缘计算有很高的需求,希望在保护病人隐私的同时处理、转换和分析医疗图像。近年来,在压缩基于Transformer的模型方面已经做出了一些努力,但迫切需要设计领域优化的架构。
使用ViT的分布式医疗成像解决方案。
健壮的机器学习模型的构建取决于训练数据的数量和多样性。学习可靠和稳健的模型被严格的隐私规定所阻碍,这是矛盾的。
因此,联合学习(FL)已被提出用于多中心模型的建立:在FL中,一个共享的模型是使用来自多个仪器的分布式数据建立的,每个仪器在其本地数据上进行学习。这使得学习可以在不共享病人数据的情况下进行,但通过与中央模型共享参数。
以上是联盟学习的框架;Park等人提出了一个基于ViT的系统,通过联盟学习来诊断一个系统中的COVID-19。然而,这个模型只是一个示范,还需要进一步的临床验证。
领域适应性和通用性
最近基于ViT的医学成像系统主要集中在提高准确度,缺乏评估泛化能力的机制。Sandhu的研究表明,测试误差通常与训练和测试数据的分布差异成正比增加。在医学成像方面,这种分布差异可能是由以下因素造成的。
- 在不同设施和不同设备上获得的图像。
- 训练数据中不存在的疾病被包括在测试数据中。
- 图像模糊,对比度低
然而,另一方面,已经表明,在大型数据集上预先训练的ViTs在不同的模式上表现良好。然而,这些模型大多是在玩具数据上训练的,如CIFAR-10和CIFAR100,并不能应对复杂的模式和局部特征,如医学图像。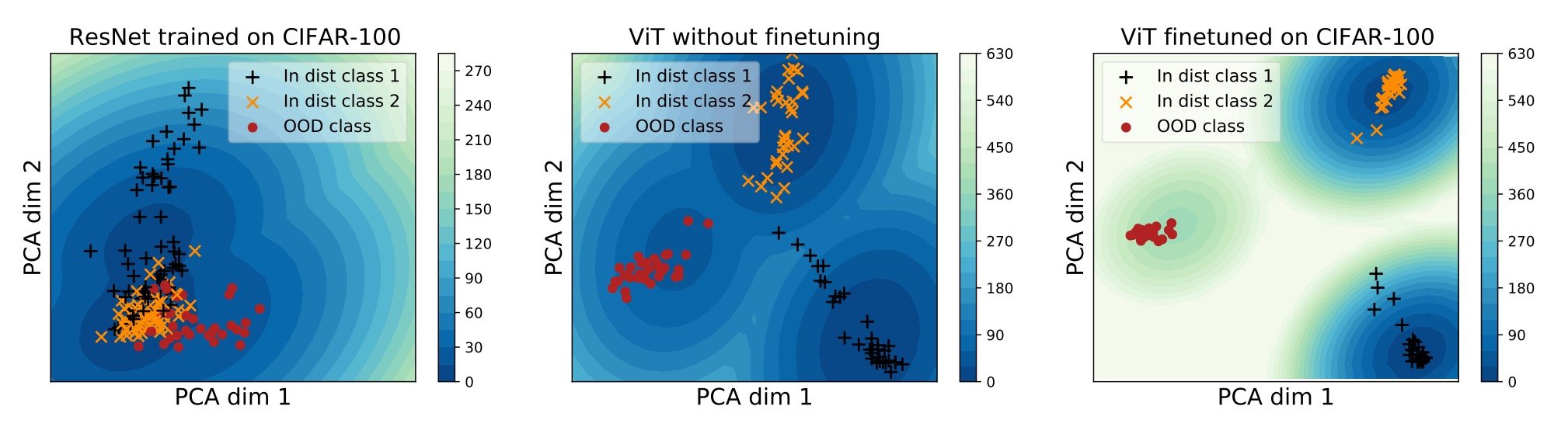
上面是三个模型的嵌入向量空间的PCA投影,是二维的。左边的ResNet无法将三者(黄色、黑色和红色)分开,而中间的ViT则能够分类(尽管有些黑色接近于黄色)。因此,用CIFAR-100对ViTs进行微调可以使它们的分类更加完善。
讨论和结论
本文表明,ViT正在渗透到医学成像领域的所有领域。希望在CV和医学影像会议上组织研讨会,并在期刊上发表专题文章,以支持这一快速发展。
在Transformer成功的背景下,本文对Transformer在医学成像中的分类、检测、分割、重建、合成、注册、报告生成和其他任务进行了全面回顾。变形金刚在医学成像方面还有很多需要探索的地方,我们希望本文能够为正在进行的研究提供一个更好的路线图。



与本文相关的类别

![[DrHouse]利用传感器信息和专业知](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/drhouse-520x300.png)
![[SA-FedLoRA] 降低联合学习通](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/sa-fedlora-520x300.png)


![[SpliceBERT]使用生物物种遗传](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/splicebert-520x300.png)
![[IGModel]提高基于 GNN+At](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/igmodel-520x300.png)