
VoxelMorph:一个基于UNet的医学成像注册模型!
三个要点
✔️ 为每个图像对解决的昂贵的优化被单一的全局优化所取代
✔️ 工作速度极快,精度与传统方法相当
✔️ 灵活的模型,如果每个图像有部分辅助数据,可以提高精度
VoxelMorph: A Learning Framework for Deformable Medical Image Registration
written by Guha Balakrishnan, Amy Zhao, Mert R. Sabuncu, John Guttag, Adrian V. Dalca
(Submitted on 14 Sep 2018 (v1), last revised 1 Sep 2019 (this version, v3))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
本文介绍了2018年提出的非刚性注册(DIR)的模型,称为VoxelMorph。登记任务,也被称为对齐,目的是确定物体或地点被视为移动的图像之间的对应关系。在医学上,这项任务在核磁共振和CT图像对的临床应用中具有很大的潜力。例如,在肺部CT图像对中,由于呼吸而观察到组织的运动,或者在核磁共振图像中,用于比较不同病人的目标区域的症状,了解图像的各个部分如何相互对应,对诊断有很大帮助。
通过获得位移场可以找到对应关系,位移场表示每个部分在图像之间的移动或变形情况。在VoxelMorph于2018年发布之前,DIR被单独优化每个图像对的方法所主导,而不是学习参数的深度学习模型,从而使单一模型映射整个数据集,基于非学习的方法为每个图像对解决优化问题,如Demons算法,实现了高精确度。取代学习参数的深度学习模型,使单个模型映射整个数据集,非训练型方法,如Demons算法,解决了每个图像对的优化问题,实现了高准确度。在这种情况下,VoxelMorph将DIR任务表述为 "一个参数化的函数,将图像对作为输入并输出一个位移场"。换句话说,VoxelMorph过程是由以下简单的方程式完成的。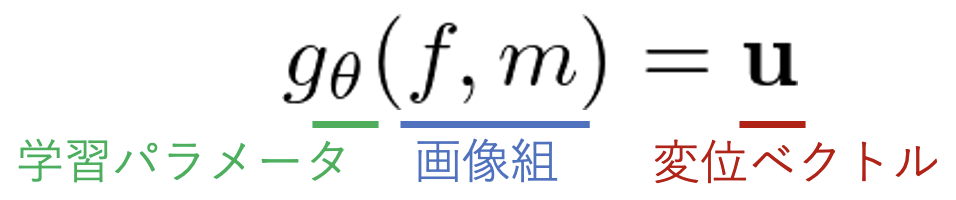
典型的深度模型是基于单一的图像输入(尽管进行了小批处理),而VoxelMorph使用图像对作为输入。通过这种方式,可以建立一个模型,其中参数θ可以在整个数据集中被学习和优化,而不是单独优化每个图像对。f是要转化的目标图像(固定),m是要转化的参考图像(移动)。
VoxelMorph就是这样一个著名的基于学习的DIR模型,但日文的解释文章并不多。VoxelMorph的主要优点如下
- 对整个数据集进行全局优化的深度学习模型。
- 可以在小型数据集上进行训练
- 在与传统方法相同的精度下,速度快得多
- U-Net的使用使学习能够捕捉到特征的确切位置。
- 如果有每幅图像的辅助数据,可以增加监督损失的内容
- 同时支持2D和3D图像
实验分析了外观损失、是否存在辅助数据及其权重设置对准确性的影响,以及准确性对数据集大小的影响。让我们先来详细了解一下VoxelMorph。*本评论是基于论文发表时的2018年19的技术。
系统定位
首先解释该方法的系统定位。登记任务所处理的变换大致分为刚性和非刚性。刚性套准处理的是仿生变换,其中没有观察到图像中的部分或物体的形状变化,只有平移和旋转。相比之下,大多数医学图像是非刚性注册(DIR)。人体的组织比我们想象的更自由运动,有许多非线性变形,随着呼吸和身体运动而改变形状,而且不同的对象的图像也不同。
然而,DIR也可以分两个阶段处理仿生和非线性变换。VoxelMorph专注于DIR任务的第二步,目标是图像对,其中图像的整体平移和旋转已经事先通过仿生变换减少。VoxelMorph任务的重点是DIR任务的第二步,目标是图像对,其中图像的整体移动或旋转已经通过仿生变换而减少。
建筑
VoxelMorph的结构如下图所示。
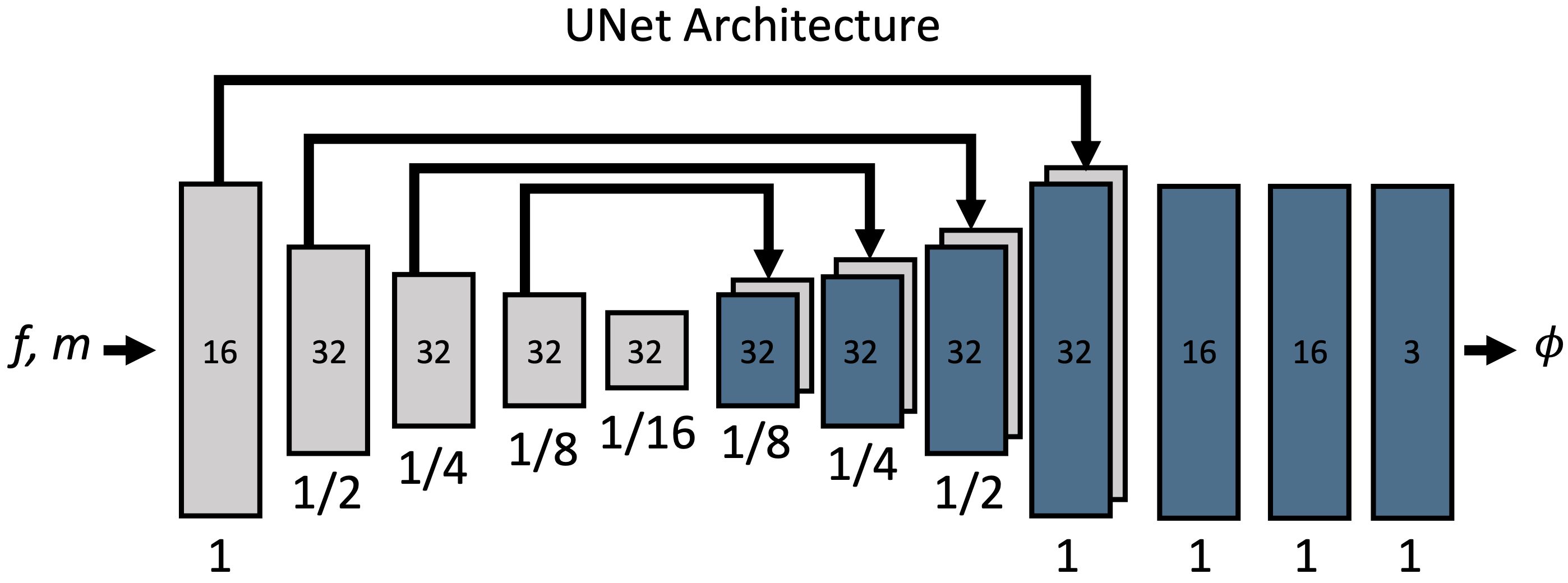
Φ指的是位移场。没有位移或变形的部分也应该是一个常数图(Id),而不是零,所以Φ=Id+u,而不是严格意义上的u。Φ和f,m的大小相同。可以看出,g(f,m)=u,它把一对图像作为输入,输出一个位移矢量,可以实现。块中的数字是通道的数量,下面是相对于输入尺寸的比例。详细的设置显示如下。
- 该实现只是把它当作一个有两个通道的图像。
- 图中显示了一个三维图像的例子,所以输出的位移场有三个通道
- 每个卷积层默认为3x3内核,跨度为2,但有人认为这应该被改变,以符合CNN假设的位移大小。
- 在每个卷积层之后,应用α=0.2的LeakyReLU。
但为什么这种机制能成功地学习到输出图像间位移场的参数θ?关键在于UNet。
联合国网
虽然一般的回归任务可以假设多维输出,但这个任务需要输出g(f,m)=u。这意味着,如果图像大小为256x256,考虑到二维移位,输出必须是256x256x2-dimensional,并且必须详尽地捕捉每个体素的变形。
然而,CNN假定了特征的局部性,并且随着层的深入,CNN的结构是为了捕捉全局特征。这意味着无论解码器有多好,随着图层深度的增加,特征的位置变得模糊不清,无法输出准确的位移场。这就是UNet发挥作用的地方。
UNet是一个由编码器和解码器组成的神经网:编码器由卷积和最大集合组成,解码器由卷积和升频组成。在这里,不是直接连接它们,而是进行跳过连接(Skip-Connection),即保留编码器特征图,并将其连接到相同大小的解码器特征图。通过这种方式,编码器捕获的局部低级特征可以与解码器的精炼特征一起输出,从而形成一个保持准确位置信息和特征质量的特征图。因为它们的连接方式看起来像字母U(在上图中不可见)...它被称为UNet。
UNet主要用于分割任务,而VoxelMorph将其优势应用于DIR。在参考图像m和目标图像f中分别提取的不同粒度的特征的基础上,它输出的位移场还有几层卷积。
空间变换器网络(STN)
VoxelMorph输出位移场,但为了实际评估其准确性,有必要根据位移场对m进行变换,并评估其是否与f相匹配。因此,VoxelMorph使用了一个空间变换器(Spatial Transformer,STN),它与我们熟悉的Attention中的Transformer不同,只是一个基于位移场进行空间变换的网络。对于一个体素p,它对其进行如下转换。

如公式所示,这个过程实际上不是对m进行变形,而是将体素p'的值分配给变形后的体素p的值。在这种情况下,p'不能被直接引用,所以它被八个方向上最近的邻居像素q加权,因为VoxelMorph输出的u不一定是整数,所以如果它位于像素之间,必须由邻居像素来插值。|如果q恰好是整数,则只对中心坐标的权重为1,对其他坐标的权重为0,否则就根据距离加权和加码。
根据这样估计的位移矢量,在STN中对m进行转换后,要进行损失和评级。
损失函数
每幅图像有两种VoxelMorph损失函数:有监督的和无监督的。无监督损失产生足够的准确性,但如果每张图像都有显示解剖结构的分割数据,则可以通过增加监督损失来提高准确性,因为监督损失要求它们进行匹配。
无监督的损失
无监督的损失是DIR中常见的一种损失。它包括一个对转换后的图像对进行视觉匹配的外观损失和一个抑制位移向量局部变化的正则化项。外观损失可以设置为任何可微调的误差函数,本文使用MSE(平均平方误差)和NCC(归一化交叉相关)损失:MSE是简单的像素到像素的平方误差,而NCC是归一化交叉相关损失。NCC是对与网站结构无关的亮度值差异的稳健测量。

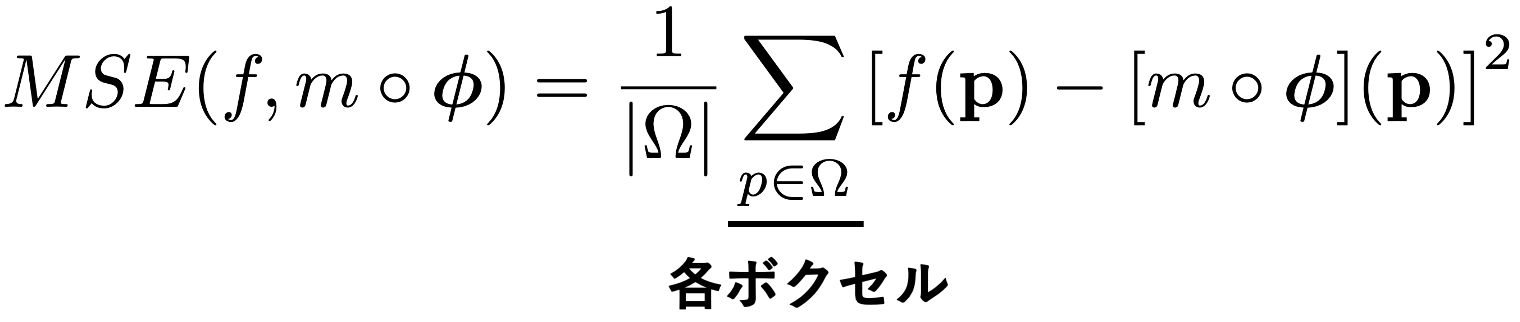

然而,仅凭这一点并不能输出不自然的矢量,迫使外观匹配。只要我们处理的是真实世界的图像,向量在局部地区具有相同的大小和流动方向是很自然的。实验证实,这样的正则化是比较准确的。正则化项由以下公式表示:通过设置u的梯度大小作为损失,可以抑制矢量的局部突然变化。
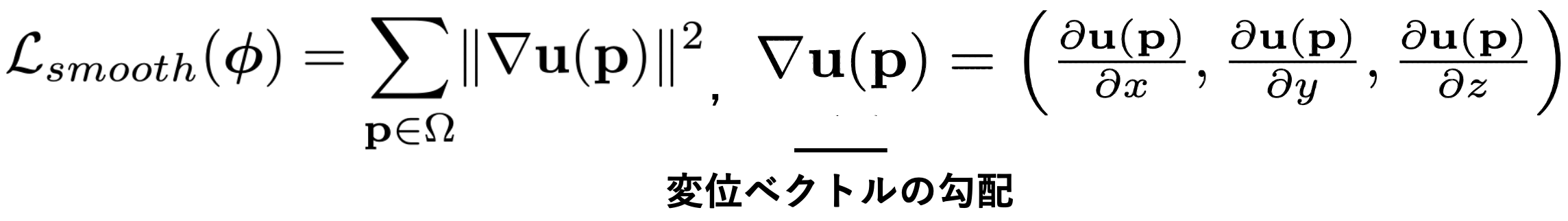
被监督的损失
如果存在代表解剖结构的分割数据,不仅外观损失,而且结构匹配也被视为损失。在这种情况下,分割掩码的Dice系数被当作损失,这是衡量两个掩码之间重叠程度的一个标准。当一个图像对中有K个分割数据时,损失表示为:。
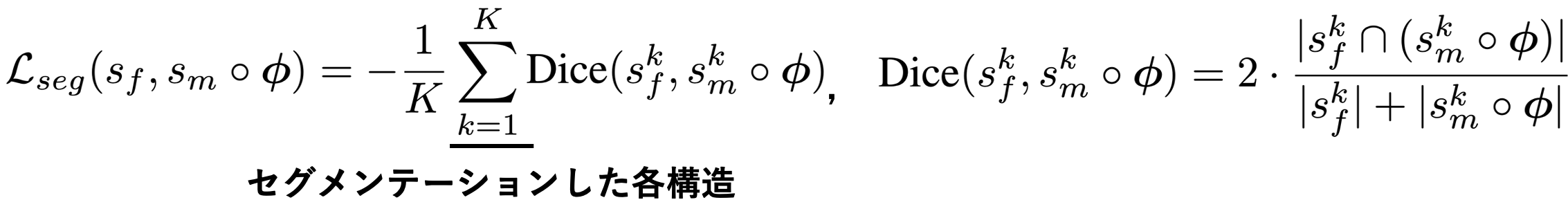
这可以被加权并添加到无监督损失中以提高准确性。在这种情况下,我们有两个权重作为超参数:λ为约束项,γ为监督损失。
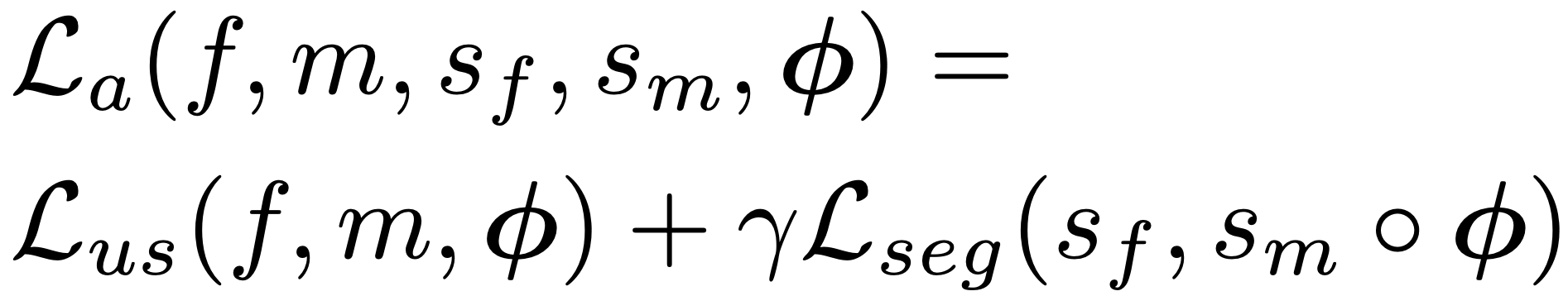
VoxelMorph通过采取这种结构和损失来进行全局优化。
实验
在实验中,VoxelMorph的准确性在前面描述的损失选择和权重的各种设置下得到了验证。在所有的实验中,假定在第一步进行仿生变换以捕捉线性变形。已经进行了各种分析,但这里只介绍有代表性的实验。
设置
比较法
比较方法采用了2019年最先进的对称归一化(SyN)和NiftyReg,这是一个执行DIR的免费软件。SyN似乎是一种寻找位移场的方法,利用欧拉-拉格朗日方程使图像之间的交叉相关性最大化。NiftyReg似乎在第一阶段捕获了仿生变形,在第二阶段通过自由形态变形(FFD)捕获了非线性变形。
VoxelMorph是用Adam来训练的,但批量大小为1。
数据集
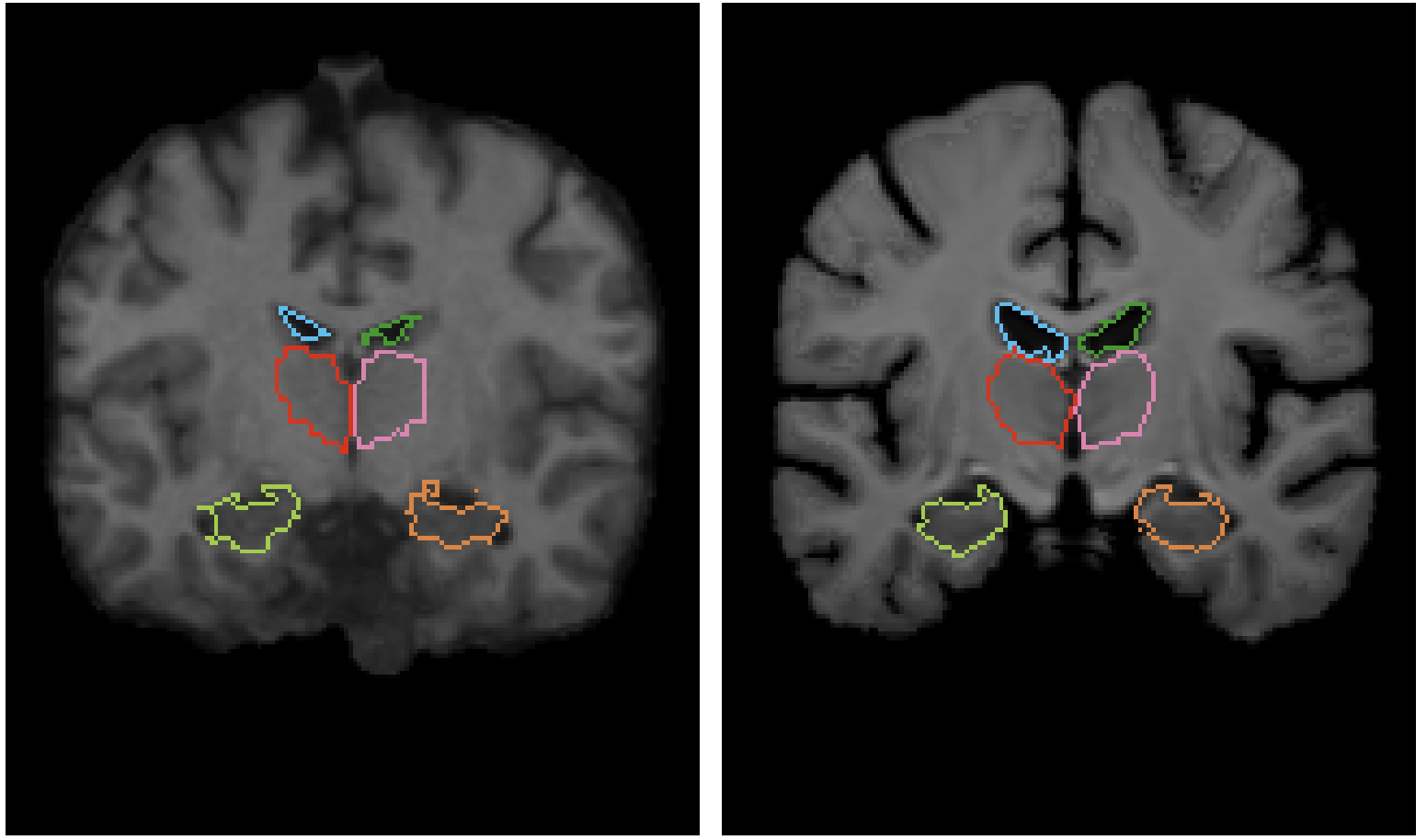
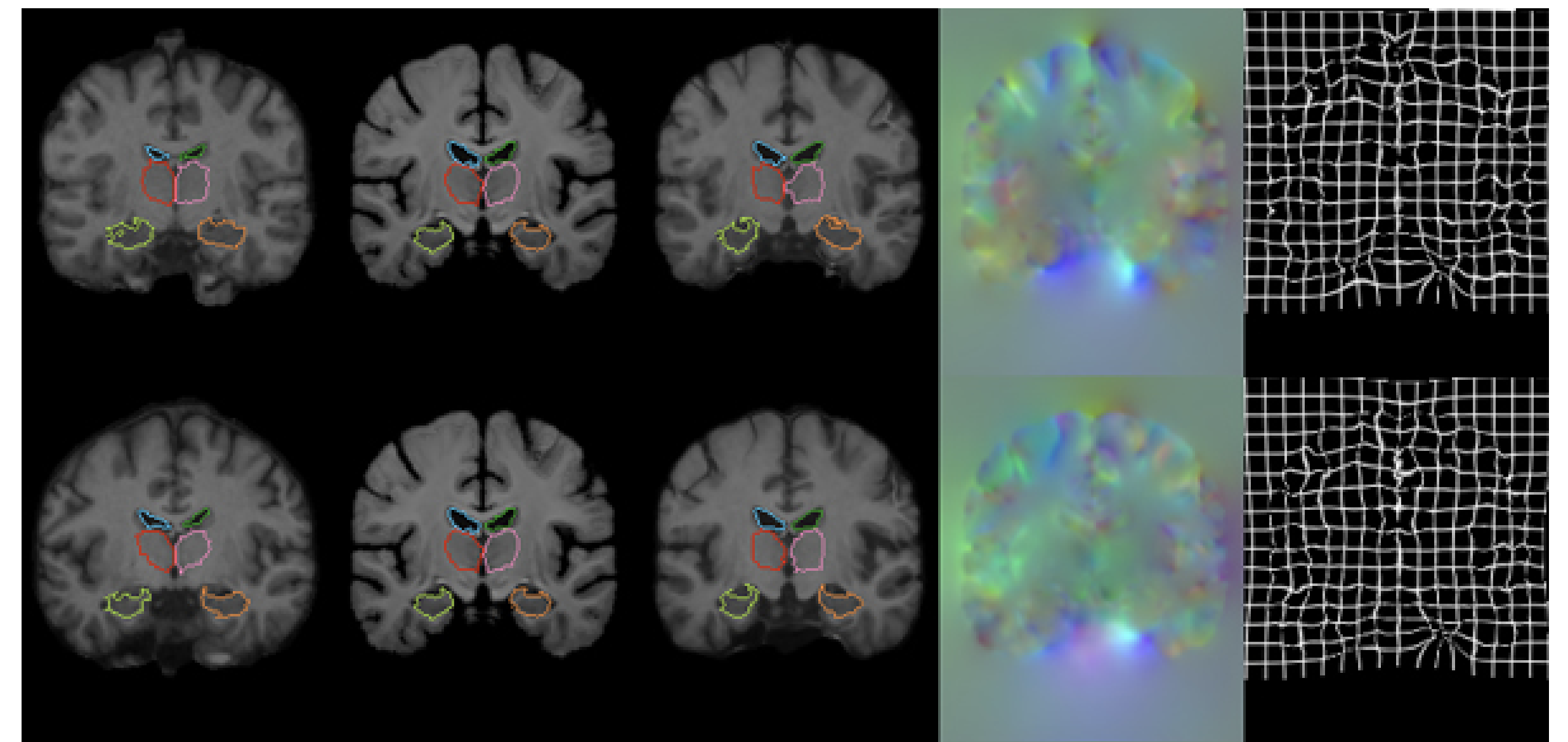
在3,731张头部MRI(T1加权)图像上进行了实验,包括八个数据集。为了验证辅助数据,使用工具FreeSurfer(见下文)为每个数据集获取了分割数据,还应用了仿生变换。Buckner40数据集只用于测试,作为对一个完全未知的手工分割数据集的准确性验证。它使用获得的30个不同解剖结构的分割数据,按Train:Valid:Test=3231:250:250划分。
估值指数
评估是基于上述创建的分割图的Dice得分。另外,雅可比矩阵被用来评估是否已经生成了自然向量。如果雅可比矩阵是正的,它可以被看作是一种衍射,即证明位移场是平滑的。这里用雅可比矩阵小于或等于零的体素数来衡量位移场的好坏。雅可比矩阵表示如下
![]()
无监督损失的准确性验证。
显示了整个数据集的结果。括号内是标准偏差。从上到下:仅有仿生变换,现有方法(均使用CC)和VoxelMorph(CC和MSE)。下图进一步说明了应用实例,VoxelMorph比仿生变换提高了准确性,并取得了与SyN和NiftyReg相当的Dice分数。然后,CPU的计算速度显示,VoxelMorph是迄今为止最快的:VoxelMorph比SyN大约快150倍,比NiftyReg快40倍。这与现有的方法对每个图像对进行优化有关,所以执行时间根据数据变形的程度而有很大的不同。相比之下,VoxelMorph在训练过程中进行了全局优化,因此速度明显更快。

显示了雅可比矩阵低于零的体素的数量,应用结果表明,正则化项效果很好,产生了一个平滑的位移场。
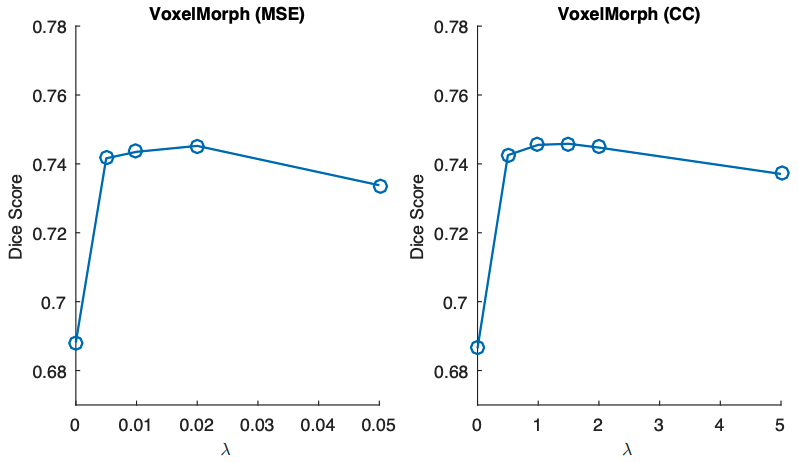
正则化项的权重λ的敏感性分析。
这里分析了不同的λ值下Dice系数的变化。首先可以看到的是,与单纯的外观损失(λ=0)相比,正则化提高了准确性。还可以看出,无论是对MSE还是CC,变化都是稳健的,对λ的选择不太敏感。
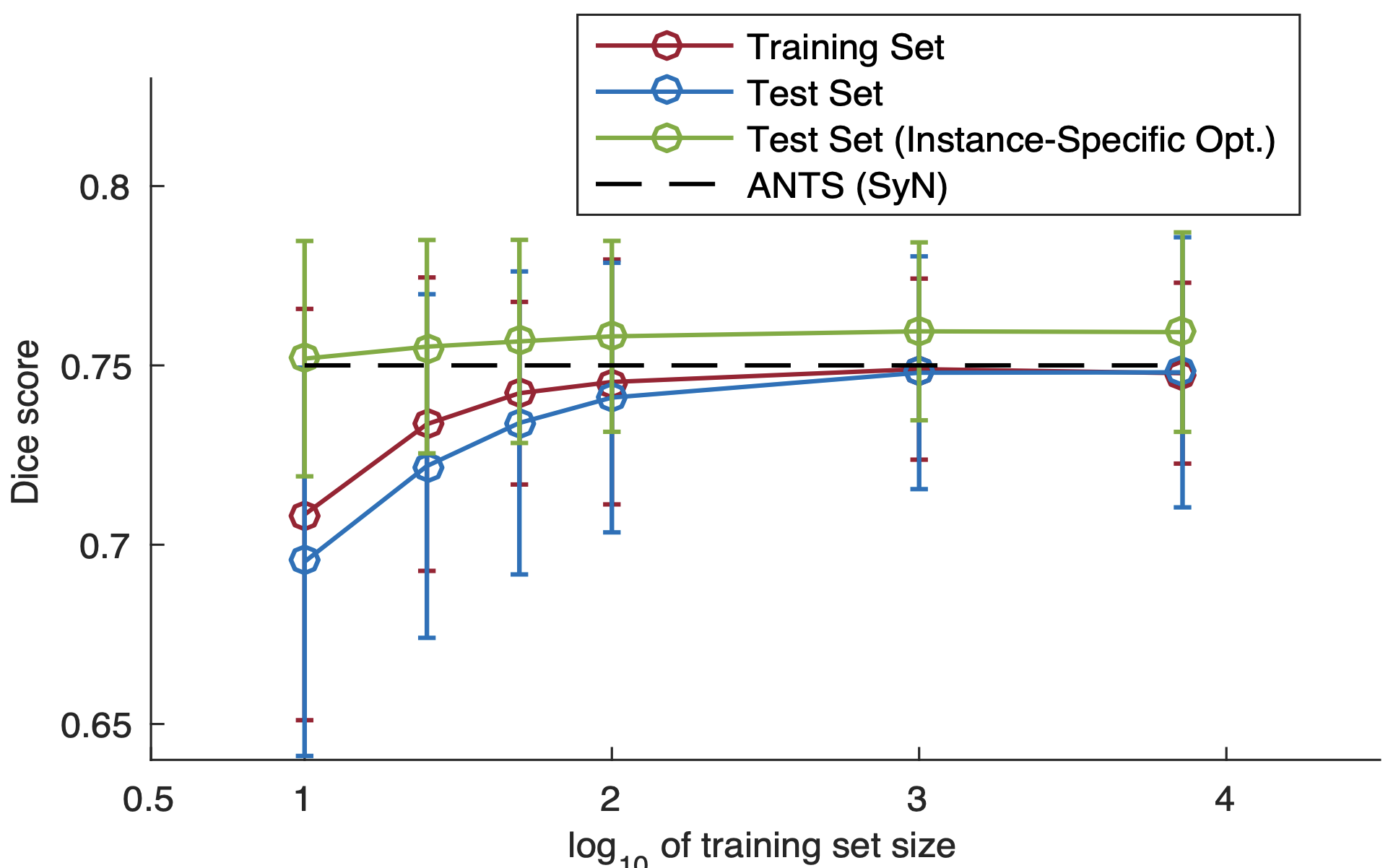
对数据集大小的分析和个别优化
接下来是优化过程中数据集大小的影响:虽然只需要一次全局优化,但如果需要太大的数据集,应用范围就会受到限制。因此,本实验分析了当用于训练的数据从10、100、1000和10000变化时,准确性的变化。表中的横轴是普通对数。作为比较,虚线表示SyN。可以看出,如果只有10对数据,准确率太低,但如果有100对数据,Dice系数大致相同,准确率也基本相同。绿线还显示了测试数据进一步单独训练时的准确度:在VoxelMorph的全局优化后,像以前一样对数据进行单独优化时,准确度进一步提高。在这种情况下,数据集的大小就不那么重要了。
监督损失的准确性验证。
接下来是比较使用辅助数据增加监督损失后的准确性。 由于MSE和CC在无监督损失的情况下都有类似的准确性,这里使用λ=0.02的MSE。对于辅助分割数据,假设有四种模式。分割数据是一个沉重的注释负担,假设总是有方便的数据是不现实的。因此,当只获得所创建的30个解剖分割的一部分时,假设有三种模式,而对于具有粗略分割的数据,则假设有一种模式。
- 一个观察到的数据:只有一种类型的 "海马、皮质、白质和脑室 "的结构的数据。
- 观察到的一半:从30个不同的结构中获得的数据,其中15个是随机的。
- 全部:已获得所有结构的数据。
- 粗略分割:30个精细注释的数据大致分为四个粗略分割:白质、灰质、脑脊液和脑干。
模式1至3分析了分割量的影响,而模式4分析了分割粗糙度对精细结构估计系统的影响。监督损失的权重γ是不同的:对于模式1到3,有分割数据的结构为观察结构,没有分割数据的结构为非观察结构;用FreeSurfer(FS)注释的7个数据集的准确率,以及在这些数据集中,有分割数据的结构的准确率。手动注释的Buckner40的准确度如下图所示。
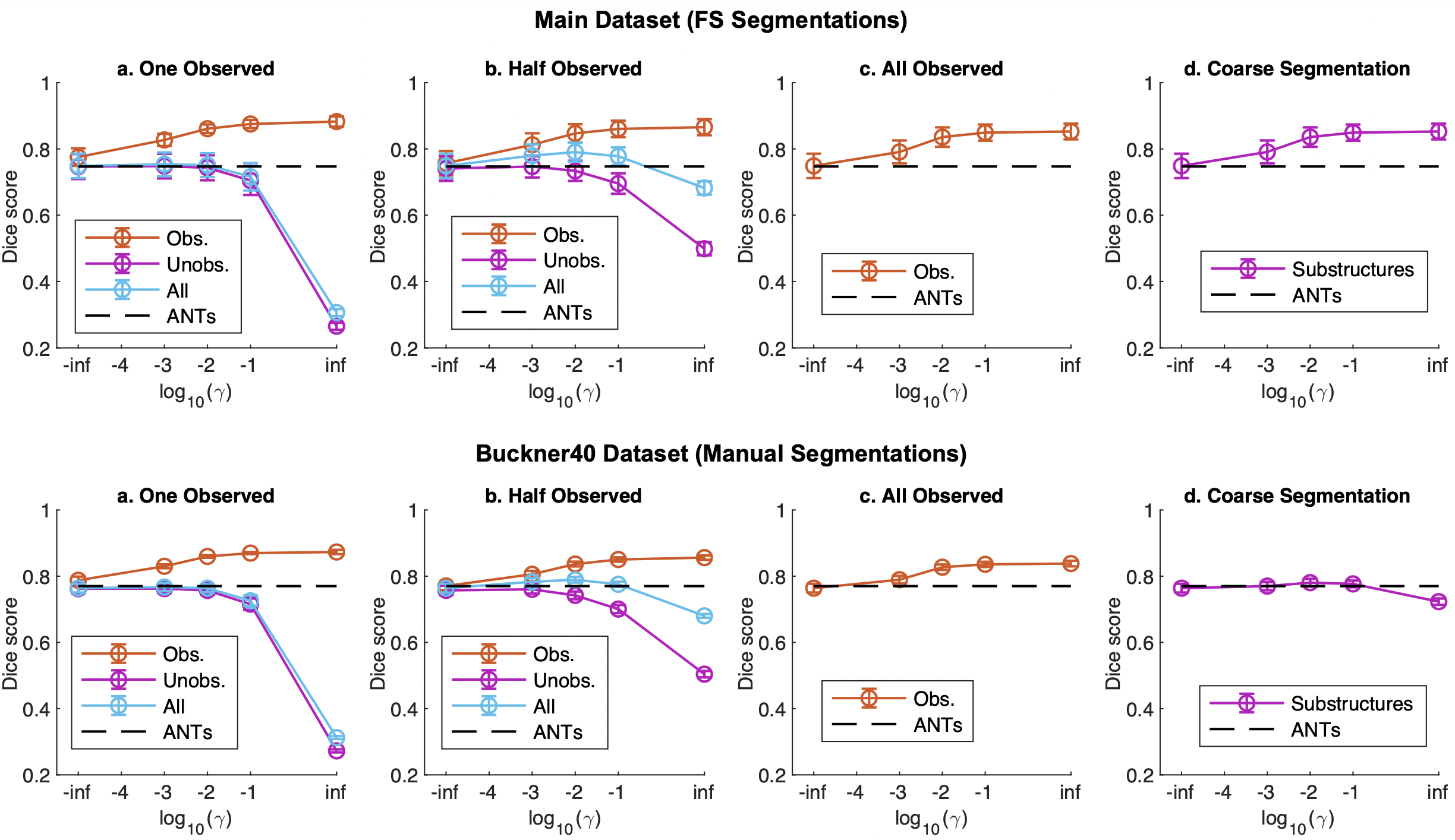 尾数是正态的对数,所以-inf表示无监督损失,inf表示只有监督损失;γ的数值太大,会导致对Observed的过度学习,从而降低Unobserved的准确性,但如果适度调整,它可以超过无监督损失和ANTs(SyN)的表现。所有的观察数据,即所有的结构都是可用的,给出了更高的准确性,但特别重要的是对未观察数据的贡献,即没有结构可用;Corase Segmentation在颗粒度上比较粗糙,但与无监督相比,显示出更高的准确性。Buckner40显示了类似的趋势,但对于粗略分割,Dice得分从一开始就比较高,所以增幅似乎比较小。
尾数是正态的对数,所以-inf表示无监督损失,inf表示只有监督损失;γ的数值太大,会导致对Observed的过度学习,从而降低Unobserved的准确性,但如果适度调整,它可以超过无监督损失和ANTs(SyN)的表现。所有的观察数据,即所有的结构都是可用的,给出了更高的准确性,但特别重要的是对未观察数据的贡献,即没有结构可用;Corase Segmentation在颗粒度上比较粗糙,但与无监督相比,显示出更高的准确性。Buckner40显示了类似的趋势,但对于粗略分割,Dice得分从一开始就比较高,所以增幅似乎比较小。
其他。
其他工作包括寻找与λ和γ兼容的参数,以及比较不同站点的准确性。有意者请参考该文件。
印象
外观损失值得尝试不同的东西;SSIM损失很可能表现得与MSE不同,因为它从亮度值、方差和结构三个角度捕捉领域基础上的差异。
我个人对对抗仿生变换的有效性感兴趣。我专注于在第一阶段应用仿生变换后的处理,但我对在不应用仿生变换的情况下进行端到端处理的效果很感兴趣。我们将其应用于手头的MNIST,它能够处理相当大的仿生变换。
摘要
描述了基于UNet的DIR模型VoxelMorph。VoxelMorph的运行速度和准确度与传统方法相同,而且可以用较少的数据集进行训练,它具有高度的灵活性,可以用辅助数据进一步改进。还有人称
- 虽然在实验中只测试了一种类型的辅助数据,但即使使用不同的模式,它也能发挥作用,而且可以使用各种类型的辅助数据,如特征点,来代替分割。
- VoxelMorph具有多功能性,对其他登记处如心脏MRI和肺部CT很有用。
这个模型是2019年的,但最近提出了一个改进的方法,叫做VoxelMorph++;虽然基于GAN的方法在DIR中也很强大,但它仍然是一个实用的方法,有可能实现更快的处理。



与本文相关的类别

![[DrHouse]利用传感器信息和专业知](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/drhouse-520x300.png)
![[SA-FedLoRA] 降低联合学习通](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/sa-fedlora-520x300.png)


![[SpliceBERT]使用生物物种遗传](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/splicebert-520x300.png)
![[IGModel]提高基于 GNN+At](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/igmodel-520x300.png)