
评估一个模型的架构性能,不需要学习! NASWOT简介
三个要点
✔️ 神经网络结构搜索(NAS)在计算上很耗时,需要加速。
✔️ 建议的评分方法,其中网络性能是指网络中的ReLU的激活量,为一个小批量的。
✔️ 无学习的神经网络评估
Neural Architecture Search without Training
written by Joseph Mellor, Jack Turner, Amos Storkey, Elliot J. Crowley
(Submitted on 8 Jun 2020 (v1), last revised 11 Jun 2021 (this version, v3))
Comments: ICML 2021
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
研究概况
在这项研究中,我们加快了神经网络结构搜索(NAS)的速度:在NAS中,搜索过程中对模型的性能评估需要对模型进行训练,而训练模型的时间一直是一个瓶颈。在这项研究中,我们专注于网络中的ReLU,并使用模型的分数作为衡量ReLU在没有经过训练的迷你批次数据集中的活跃程度。这种类型的评分允许在不让网络学习的情况下对其进行评估,并允许进行非常快速的探索。
研究背景
什么是NAS?
神经结构搜索(NAS)是一种自动探索神经网络结构的方法。一些著名的有:。Zoph&Le(2017)(https://arxiv.org/abs/1611.01578)。在这种方法中,一个候选网络由一个使用RNN的生成器生成,然后进行实际训练以评估其架构。根据评估值,通过强化学习探索下一个候选网络。这种方法是一种可以自动探索神经网络架构的创新方法,但它的计算成本很高,需要相当多的计算资源,因为对候选架构的评估是通过实际训练来进行的。
无学习,架构得分
在NAS中,候选架构的评分是搜索过程中的一个瓶颈,因此需要加快这一部分的进程。因此,本研究提出了一种无需实际训练候选架构的评分方法。
作者在数据集上的架构性能方面提出了一个假设。就是说,一个架构越能反映输入数据的差异,这个架构的性能就应该越好。这来自于这样的想法:如果输入数据不同,但模型有类似的输出,那么对于不同的输入数据来说,将更难学习到其中的差异,因此不太可能产生好的结果。为了在方法论中反映这一假设,作者把重点放在模型中是否存在ReLU的激活。
当数据被输入模型时,模型中的每个ReLU用一个二进制值表示,如果它是活动的,则为1,否则为0,表示它是否活动。对每个ReLU的这些值进行检查和排序,可以得到一个矢量,即当一个数据被输入模型时,模型中ReLU的数量长度。这样得到的向量被认为是该数据中模型的行为。我们比较每个数据的这个向量,看它是否反映了与输入数据的差异。
现在我们将解释具体如何做到这一点。对于数据i,我们考虑一个向量ci,列出模型的ReLU的激活或不激活。这里ReLU的激活或不激活被认为是二进制的,即如果ReLU的输出小于或等于0,它就是不激活的,否则它就是激活的。然后,向量ci是一个二进制代码序列。这个向量ci将代表这个模型对数据i的激活程度。我们从数据集中随机抽取一个由N个数据组成的小批,并为小批中的所有数据计算这个向量c。这就得到了一个从矢量c1到cN的二进制代码序列。作者的假设是,由于输入数据导致的模型的不同行为程度会被打分,所以需要对这些二进制代码序列的差异进行量化。在量化矢量之间的差异时,作者使用了汉明距离。对每一个数据组合都要计算汉明距离,并考虑用一个KH矩阵来排列它们。
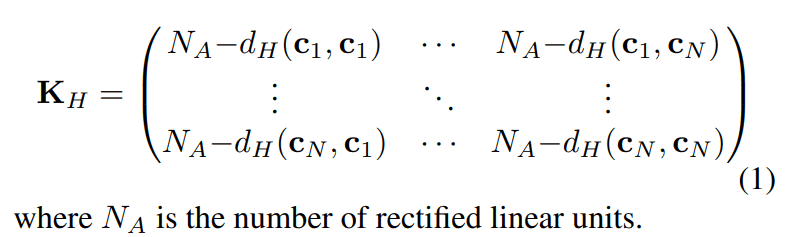
由于这个KH是一个矩阵,所以不方便把它当作一个分数。为了将其转换为标量值,得到KH的行列式并转换为对数标度。

这个s是这个模型的得分。从这一点开始,将对评分方法进行测试,看它是否能正常工作。
验证计分方法
KH的相关性
对于两个数据集(NAS-Bench-201,NDS-DARTS),我们计算了多个架构的KH;在对KH的每个元素进行标准化后,结果如下图所示。

最上面一行显示了模型训练后的最终准确性。图中显示,KH对于实现高最终精度的架构和不实现高最终精度的架构有很大的关联性。那些达到低精确度的人有更多的深色(数值接近于0),而那些达到高精确度的人有更多的白色(数值接近于1)。这表明,在训练之前,模型中输入数据的激活程度与最终的准确性有很大关系。
打分的充分性
对于每个数据集,下图显示了从所提出的方法的评分和架构的最终验证准确性之间的关系。
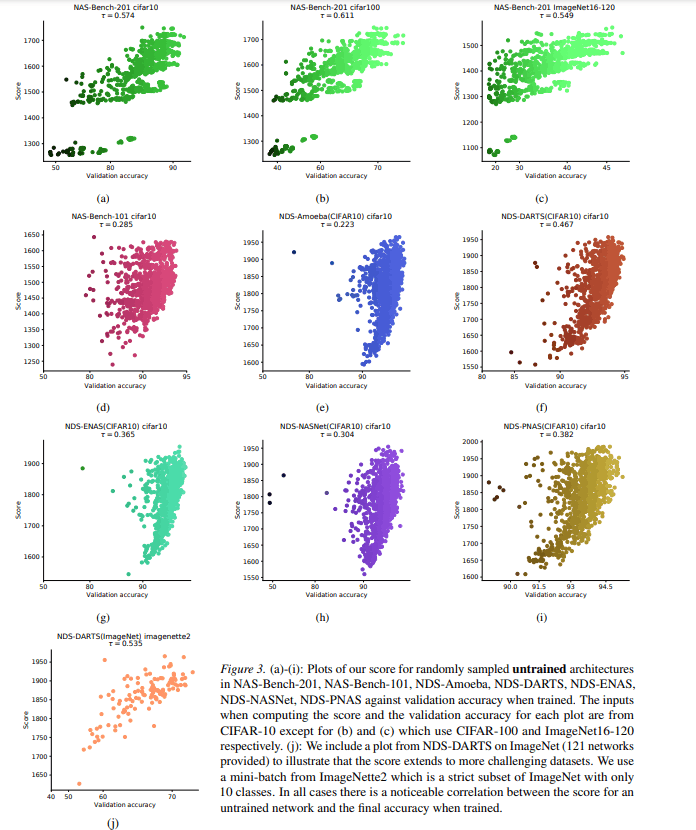
这张图显示横轴代表模型的验证准确性,纵轴代表模型的得分。图中显示,得分较高的架构更有可能在两个数据集中获得较高的验证准确率。这证实了所提方法的评分是有效的。下图也验证了分数的变化程度,这取决于为小批量选择的数据、模型参数的初始值和小批量的大小的差异。
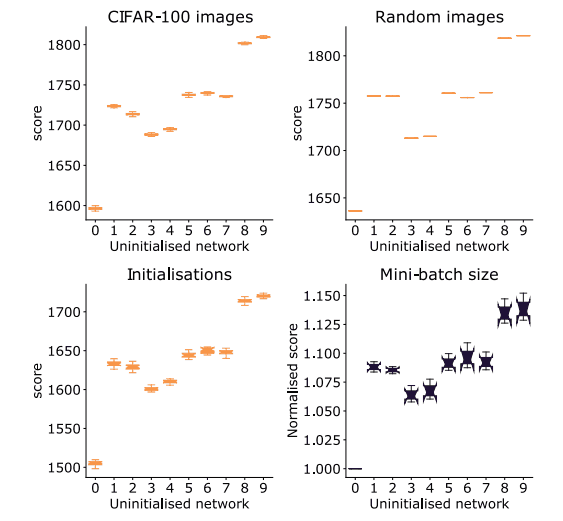
该图将网络标识符放在横轴上(该图中比较了10个不同的网络),将这些网络的分数放在纵轴上。从图中可以看出,每个人都有一些变化,但得分没有相对差异,说明无论如何,评分都是稳健的。
下图还比较了模型参数最初设置为初始值时的分数和随着训练继续进行的分数,以观察分数的排名是否会出现波动。
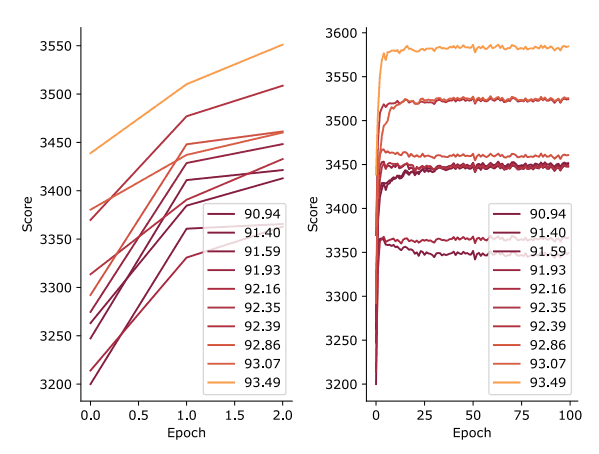
这张图的横轴是历时的数量,纵轴是该点的分数。从图中可以看出,随着学习的深入,分数本身都有所提高,但相对排名方面的变化不大,说明学习前状态下的分数可以用来确定架构的得分。
无需训练的神经结构搜索 - NASWOT
从这里开始,利用上述评分进行架构探索,以验证性能良好的架构可以被探索出来,以及这种探索涉及多少时间和计算成本。
作为一种搜索方法,我们使用Zoph&Le(2017)的著名NAS方法。在这种方法中,候选架构被训练并通过其验证准确性进行评分,但只有儿童评分部分被提议的方法所取代。采用这种替换的方法被称为NASWOT。
下图比较了每个数据集的现有方法和NASWOT。
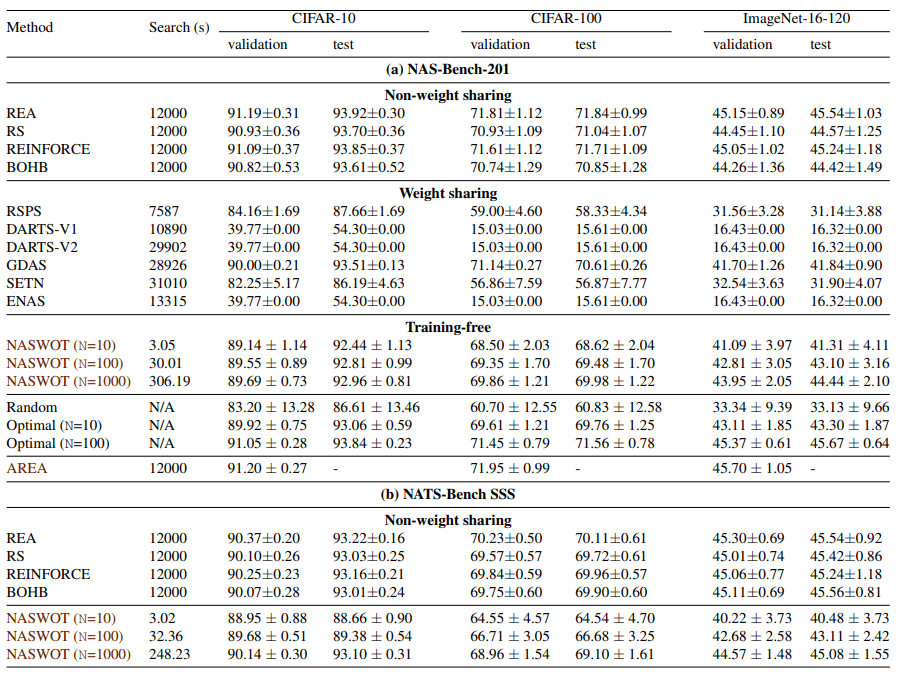
该图显示,NASWOT首先在搜索时间上非常快。也可以看出,NASWOT在所探索的架构的测试准确性方面并不比其他方法差。
接下来,研究了搜索时间和测试准确性之间的关系。下图说明了搜索时间和测试精度之间的关系。
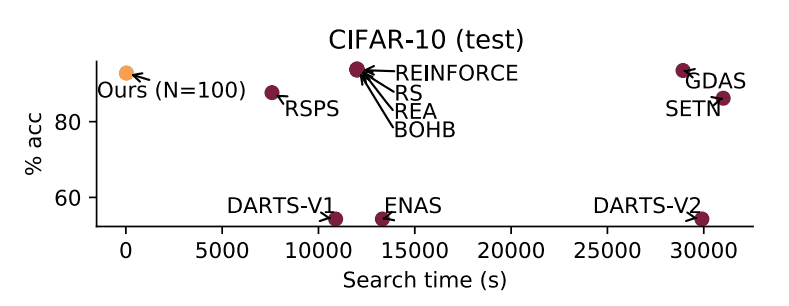
该图在横轴上标出了搜索时间,在纵轴上标出了最终达到的测试精度。图中显示,最终达到的测试精度是相当的,而且搜索速度非常快。
摘要
传统上,NAS一直遭受着难以解决的搜索空间和非常高的搜索成本。在这项研究中,我们提出了一种在初始化状态下对神经网络架构进行轻松评分的方法,并将这种方法纳入传统的NAS方法中,以大幅减少搜索时间。



与本文相关的类别






