HyperCLOVA简介:韩国GPT-3
三个要点
✔️ 一个名为HyperCLOVA的GPT3大小的韩语语言模型
✔️ 不同规模的HyperCLOVA在各种NLP任务上的实验情况
✔️ HyperCLOVA Studio,一个用于分发HyperCLOVA提供的服务的平台。
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
written by Boseop Kim, HyoungSeok Kim, Sang-Woo Lee, Gichang Lee, Donghyun Kwak, Dong Hyeon Jeon, Sunghyun Park, Sungju Kim, Seonhoon Kim, Dongpil Seo, Heungsub Lee, Minyoung Jeong, Sungjae Lee, Minsub Kim, Suk Hyun Ko, Seokhun Kim, Taeyong Park, Jinuk Kim, Soyoung Kang, Na-Hyeon Ryu, Kang Min Yoo, Minsuk Chang, Soobin Suh, Sookyo In, Jinseong Park, Kyungduk Kim, Hiun Kim, Jisu Jeong, Yong Goo Yeo, Donghoon Ham, Dongju Park, Min Young Lee, Jaewook Kang, Inho Kang, Jung-Woo Ha, Woomyoung Park, Nako Sung
(Submitted on 10 Sep 2021)
Comments: Accepted to EMNLP2021.
Subjects: Computation and Language (cs.CL)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
简介
GPT-3是一个庞大而强大的语言模型,吸引了人工智能界内外的大量关注:GPT-3使用语境中的信息(由任务描述和几个镜头的例子组成的离散提示)来推断目标任务的预测。然而,我们认为仍然存在一些挑战:GPT-3的训练数据严重偏向于英语(92.7%),使得它难以应用于其他语言并进行测试。因此,我们开发了HyperCLOVA,一个韩国的话里有话我们将训练一个大规模的模型。目前,有参数达到13B的模型,有175B的GPT-3,但没有对13和175B之间的模型进行彻底分析。因此,我们也用39B和82B来训练模型,这样我们就可以对处于中间位置(相对而言)的模型进行分析。我们还对特定语言的标记化的影响和HyperCLOVA的零次拍摄和少数次拍摄功能。最后,我们试验了先进的基于提示的学习方法,这些方法需要在大型语言模型上进行输入的后向梯度。
HyperCLOVA
训练数据集和模型
GPT-3的训练数据中只有0.02%的韩文数据是由字符组成的。因此,我们在互联网上建立了一个庞大的学习数据库,包括用户生成的内容和外部合作伙伴提供的内容。结果,我们获得了大约561B个韩语数据,使用的架构与GPT-3相同,配置如下对中型模型的分析很重要,因为尽管缺乏对中型模型的研究,但对于现实世界的应用来说,中型模型的大小更合理。
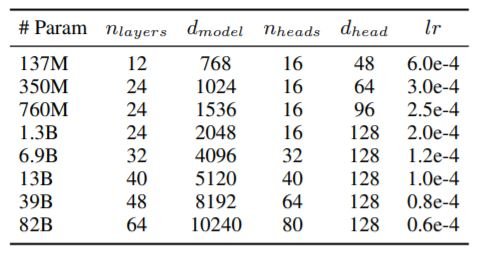
我们使用Megatron-LM在NVIDIA Superpod上训练模型,该模型包含128台强集群的DGX服务器和1024个A100 GPU。作为一个优化器,我们使用余弦学习率和重量衰减并使用AdamW,小型批次大小为1024。
韩文符号化
韩语是一种凝集性语言,名词后面有粒子,动词和形容词的词干后面有尾音,并有各种语法性质的表达。对韩语使用类似英语的标记化已被证明会降低韩语语言模型的性能。因此,我们使用语素感知的字节级BPE作为标记化的方法。
考虑到韩语的语言特点,我们在KorQuAD和两个AI Hub翻译任务上测试了我们的标记化方法。我们还将我们的标记化方法与字节级BPE和字符级BPE标记化进行了比较,这两种标记化方法被广泛用于韩语标记化。字符级标记化可能导致词汇外(OOV)或韩语字符的遗漏。在所有其他任务中,我们的方法都优于字节级BPE和字符级BPE,只是在韩语到英语的翻译中,语态分析器表现不佳。这说明了大规模语言模型中特定语言标记化的重要性。
实验和评估
五个不同的数据集被用于模型评估。NSMC是一个电影评论的数据集。KorQuAD 1.0是一个韩语机器阅读的数据集,AI Hub Korean-English corpus是一组从各种来源收集的韩英平行句子,YNAT是一个由七个类别组成的主题分类问题,KLUE-STS是一个句子相似度预测的数据集。
语境中的少数人学习
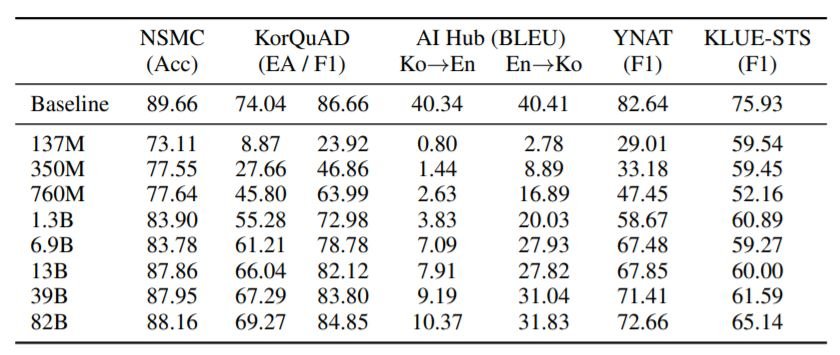
上表显示了各种语境中学习任务的结果。正如预期的那样,性能随着模型大小的增加而单调地提高。然而,对于KLUE-STS和翻译任务,其性能远远低于基线。我们希望更复杂的提示工程将在未来改善这些结果。
基于提示的调谐(P-调谐)
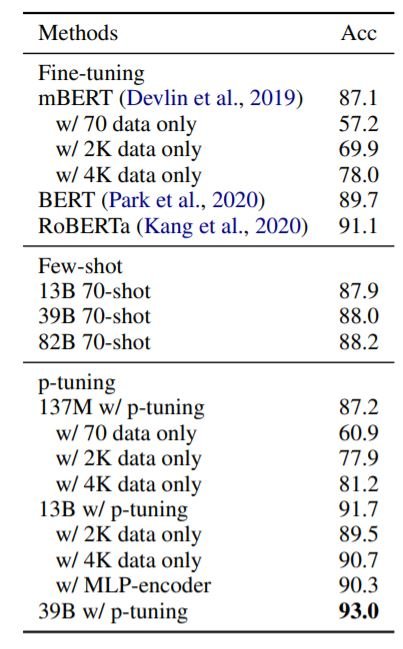
上表显示了NSMC中p-tuning的结果。p-tuning使HyperCLOVA在不改变模型参数的情况下超过了所有其他模型。通过p-tuning,HyperCLOVA能够在不改变模型参数的情况下胜过所有其他模型。p-tuning仅用4K实例就能胜过用150K实例微调的RoBERTa。
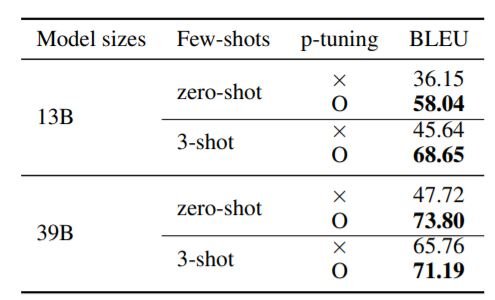
上表显示,p-tuning显著提高了我们在内部进行的查询修改的零点和三点性能。这表明,访问GPT3尺度模型的输入数据的后向梯度可以提高模型对任务的代表性。这对那些没有资源来训练GPT3尺度模型的研究人员有很大好处。
超强的创造力
为了分发这个强大的模型,我们介绍了HyperCLOVA工作室,这是一个建立和交流由HyperCLOVA生成的共享工件的地方。这使得人工智能服务的快速原型化,而人工智能工程师的参与程度最低。下面几节描述了HyperCLOVA的一些用例情况。

角色机器人:HyperCLOVA已经表明,只用几行描述和几个例子的对话,就可以创建一个具有特定个性的聊天机器人。上面的图片(a)是一个例子(提示为斜体,输出为正常字体)。
零距离传输数据增强:这里的目的是根据用户的意图来调整语音。例如,对于 "自己预订查询 "的意图,我们将输出一个句子,如 "自己预订可以吗?意图可以不同,可以短到 "预订查询"。
生成事件标题:HyperCLOVA对生成事件标题的任务非常有用。例如:在产品促销活动的情况下,HyperCLOVA以5个产品实例为提示,包括活动日期和关键词,并输出适当的活动标题(Jewellery for you who shinesely)。HyperCLOVA也可以用最小的努力适应其他领域,例如为广告生成标题的任务。
除了这些,HyperCLOVA还提供了一个输入梯度API,这有助于利用p-tuning提高局部下游任务的性能。它还提供了输入和输出过滤器,以防止HyperCLOVA的误用。
我们相信,像HyperCLOVA这样的大规模模型将有利于加速NLP操作的生命周期。开发和监测ML系统是一个迭代的过程,目前需要专家多次执行特定的任务。这样做的成本很高,也阻碍了公司将人工智能与他们的产品相结合。虽然目前是一个挑战,但HyperCLOVA有助于低/无代码的人工智能范式,并可以通过允许非专家开发ML系统而从根本上降低开发成本。
摘要
本文通过强调特定语言标记化、p-tuning等的重要性,为大型特定语言模型的开发提供了有价值的见解。HyperCLOVA(Studio)背后的目的是通过使非专业人士能够建立自己的人工智能模型,使韩国的人工智能开发民主化。HyperCLOVA(工作室)背后的目的是通过允许非专业人士建立自己的人工智能模型,使韩国的人工智能发展民主化。同时,我们需要意识到这些模式的滥用、公正性和偏见等问题,并不断努力朝着正确的方向前进。



与本文相关的类别






