
它与GANs有什么不同?你对图像生成模型NeRF熟悉吗?
三个要点
✔️NeRF是一个新颖的视点图像生成网络。
✔️NeRF的输入是5维的(空间坐标为x、y、z,视角为θ、φ),输出是体积密度(≒透明度)和辐射度(≒RGB颜色)。
✔️NeRF已被成功地用于获得具有比以前更复杂的几何形状的物体的新视角图像。
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
written by Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng
(Submitted on 19 Mar 2020 (v1), last revised 3 Aug 2020 (this version, v2))
Comments: ECCV 2020
Subjects: Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
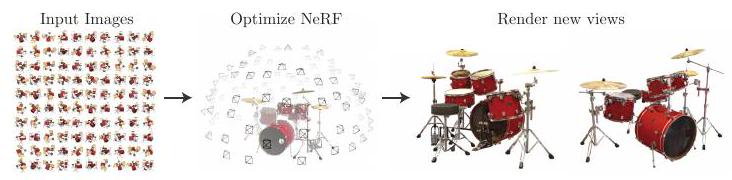
首先看看下面的动画,以了解 "新观点图像生成 "的情况。


上面的动画是由NeRF生成的:一个新的视点是摄像机的位置,而一个新的视点图像的生成是对'当我们从某个位置看一个物体时,我们会得到什么图像?.
制作上述动画最简单的方法是在移动摄像机的同时拍摄一系列的镜头(就像视频一样),也就是说,通过对一个物体拍摄一系列的镜头,同时逐渐改变视角,这个物体看起来就像是在三维空间中被观看。然而,在NeRF中,相机只从三个视点(正面、侧面和背面)进行拍摄,并且有可能从 "未拍摄 "的视点获得图像,如 "斜向前 "和 "斜向后 "之间。这被称为新颖的视图图像生成。
介绍
这项研究通过使用神经网络来优化图像表示的参数,解决了观点合成(view synthesis)中一个长期存在的问题。
作者将静态场景表示为一个连续的五维函数,输出空间中每一点(x、y、z)的辐射度(有方向θ、φ)和密度。这个函数的作用类似于差分不透明度,它可以控制通过每个点的光线储存多少亮度(即多亮)。
该方法通过使用没有卷积层的多层感知器(MLP)进行回归,将五维变量(x、y、z、θ、φ)转换为体积密度和RGB颜色。
在 "三要素 "部分,我写了 "体积密度(≈透明度)"和 "发射辐射度(≈RGB颜色)",但这并不准确。"体积密度是渲染时必须的变量,它控制着光线通过物体时的扩散和反射等。它被简化为透明度,但你可以把它看作是一个与光互动的元素,发射的辐射度也是一个变量,它在渲染时是必要的,控制着光线穿过物体的扩散、反射等。它不等于RGB颜色,而是指物体表面某一点发出的光(该点自身的光源和周围的反射或透射光的总和),应该只理解为渲染所需的一个变量。它应该被理解为渲染所需的一个变量。
为了获得回归的输出,即神经辐射场(NeRF),本研究中的实验进行如下。
- 将摄像机移动到空间的各个位置,并记录摄像机的坐标。
- 上述摄像机的位置和相关的注视方向是神经网络的输入,而该位置的图像是输出(教师)。
- 从颜色和亮度生成二维图像的过程使用了经典的体积渲染,它是可分的,可以通过神经网络进行优化。
通过这些步骤,模型的优化实际上是使观察到的图像和输出结果之间的差异最小化;协议流程如下所示。
相关研究
这个领域最近一个有前途的方向是使用MLP进行场景编码,但它还不能再现具有复杂形状的现实场景,而不是图像(2D)。ShapeNet以研究三维形状的表示方法而闻名,但首先对准教师数据的困难一直是研究的障碍。ShapeNet系统是这方面的一个好例子。
随后,通过制定一个可微调的渲染函数,有可能只用二维图像来优化一个三维神经隐含形状表示法(神经隐含形状表示法)。Niemeyer等人将物体表面视为一个三维专有场(占位场),用数值方法计算每条射线的表面交点,并通过隐式计算精确计算出然后,每条射线的交叉点的位置被用作神经三维纹理的输入,预测该点的漫反射颜色。Sitzmann等人提出了一个可微调的渲染函数,它使用神经三维纹理在连续的三维坐标中输出特征向量和RGB颜色。
神经辐射场场景表征
作者将连续场景表示为一个五维矢量值函数,其输入是坐标(x、y、z)和视线(θ、φ),其输出是颜色(r、g、b)和体积密度σ。
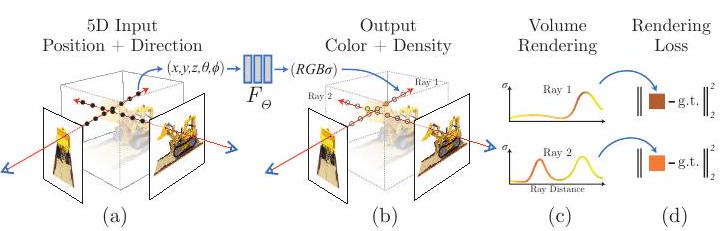
上图显示了用NeRF进行场景表示和可区分渲染的概况:5维输入(位置和视线)允许相机射线(相机射线,在图中由眼睛和红色箭头表示)沿相机射线(x, y, z, θ, φ)被输入到MLP(F_Θ),它输出RGB颜色和体积密度(R, G, B, σ)。
用辐射场进行体积渲染
体积密度σ(x)可以被解释为一个有一条射线的无限小的粒子最终在x点的差分概率。
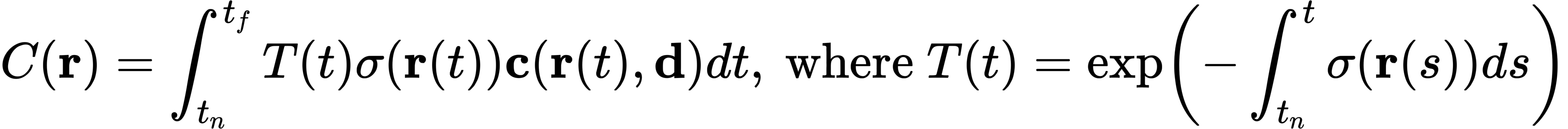
C(r)是相机射线r(t)的预测颜色,近端为t_n,远端为t_f。函数T(t)是射线从t_n到t_f而不与其他粒子碰撞的概率,表示为沿射线的累积传输量为了渲染一个连续的NeRF(神经辐射场)的视图,它必须对所需的虚拟摄像机经过的每个像素进行整合。
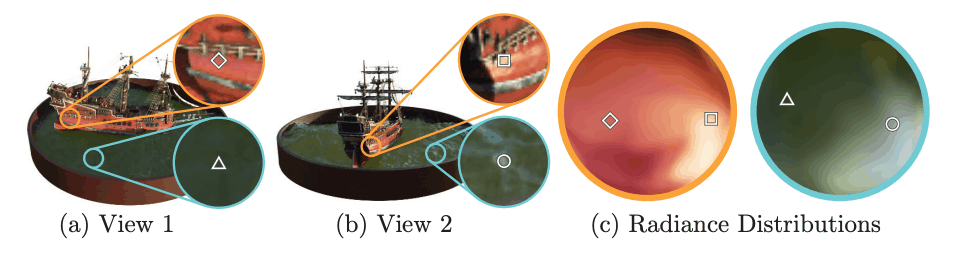
上图是一个例子,说明当视角发生变化时,同一个点的颜色会发生变化;在NeRF中,颜色是由辐射度和视线方向决定的;因此,即使在同一坐标上,当视线发生变化时,颜色也会改变。NeRF:图像的颜色由辐射度和目光的方向决定。
神经辐射场的优化
虽然在上一节中介绍了渲染,但在实践中,要达到最先进的水平(SOTA,最高质量)是不够的。在上一节中,xyzθφ被输入到网络F_Θ,它被以下复合函数所取代。
![]()
F'_Θ是一个多层感知器。
![]()
γ是一个高频函数,表示方法同上。
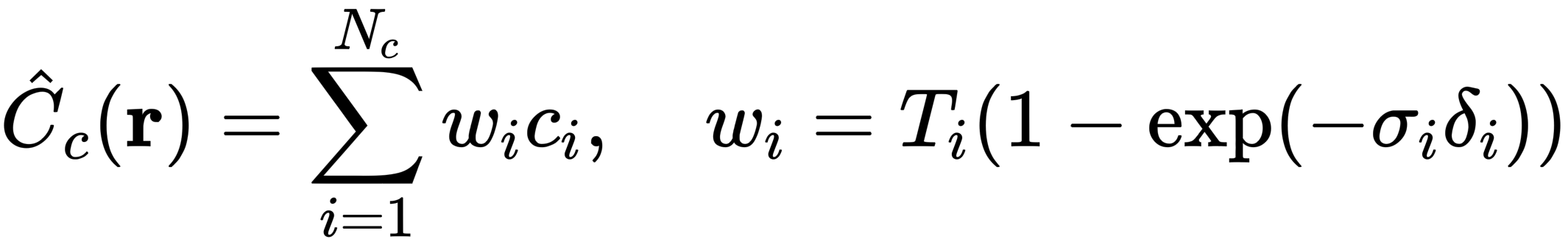
同样地,C也被简化为上述情况。
结果

与神经体积(NV)、场景表示网络(SRN)和局部光场融合(LLFF)的比较 两幅图像均为与NeRF相比较,它扭曲了,细节也被打碎了。

上表概述了比较结果。
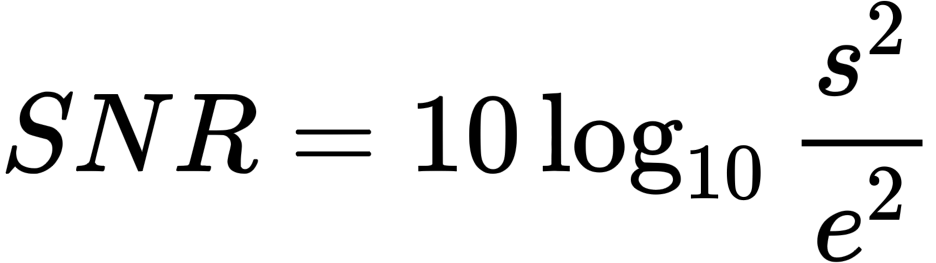

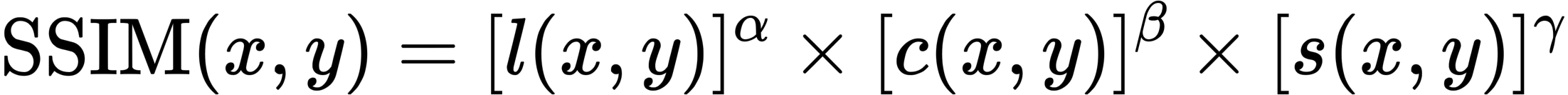
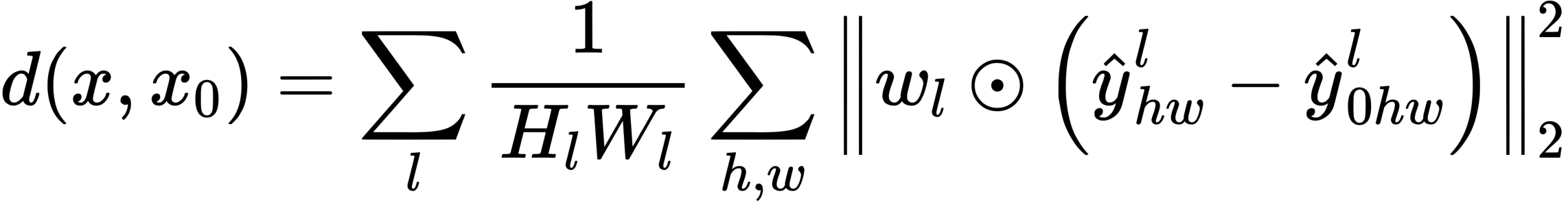
每个指标都是一个损失函数,从某种角度比较GT和生成的图像:PSNR和SSIM越大越好,而LPIPS越小越好。这表明NeRF优于所有现有的方法。
结论
在这项研究中,作者解决了现有MLPs将物体和场景表示为连续函数的问题:通过将场景表示为一个5D神经辐射场,作者这使他们能够推进图形管道,从真实物体中生成新的视点图像。



与本文相关的类别
