寥寥数语的对象检测,也不会忘记基类
三个要点
✔️ 我们开发了一个物体检测模型--Retentive R-CNN,它也可以在不忘记所学到的基类信息的情况下检测出少许拍摄类。
✔️ Retentive R-CNN在基准上记录了SOTA的几率检测。
✔️ 在基类检测方面,性能完全没有恶化。
Generalized Few-Shot Object Detection without Forgetting
written by Zhibo Fan, Yuchen Ma, Zeming Li, Jian Sun
(Submitted on 20 May 2021)
Comments: CVPR 2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
深度学习在大量的训练数据上训练时表现出很高的性能,但有些情况下只有有限的数据可用。然而,在某些情况下,只有有限的数据量可用,有人提出了一种称为 "少量学习 "的方法,以便在这种情况下进行检测。然而,传统的方法只擅长于检测少数几张照片的类别,而致命地忘记了基本类别信息。物体检测需要对两类都有很高的检测性能,因为一张图像可能包含两类。这样的研究被称为 "广义的少数镜头检测"(G-FSD)。在这项研究中,在发现基于过渡学习的基类检测器包含可以提高两类检测性能的信息后,利用它们开发了一个由偏见平衡的RPN和Re-detector组成的Retentive R-CNN。
解决问题
让$C_b$为基数类,$C_n$为几率类,$D_b$和$D_n$为包含各自类的数据集。让$D_b$包含足够数量的训练数据,$D_n$只包含少量的训练数据。我们的目标是训练一个模型$f$,在不忘记$D_b$中的训练信息的情况下检测$D_n$中的数据。在这项研究中,我们采用了过渡学习基础,它需要较少的训练时间,预计会比元学习基础表现更好。首先,用$D_b$训练基类检测器$f^b$,用$D_n$微调,得到$f^n$。然而,在微调阶段,基类的检测性能会恶化。为了解决这个问题,我们分析了以前研究中的两阶段微调方法(TFA),TFA首先被训练成一个常规的R-CNN,有$D_b$,最后一层的分类头和盒式回归头用$D_n$进行调整。将微调后的权重和基础检测器的权重结合起来,在含有相同数量$D_n$和$D_b$样本的数据集上再次进行微调。
Retentive R-CNN
本文提出的用于G-FSD模型的Retentive R-CNN包括一个Bias-Balanced RPN和Re-detector,它利用了上述的$f^b$信息。下面是一个原理图。
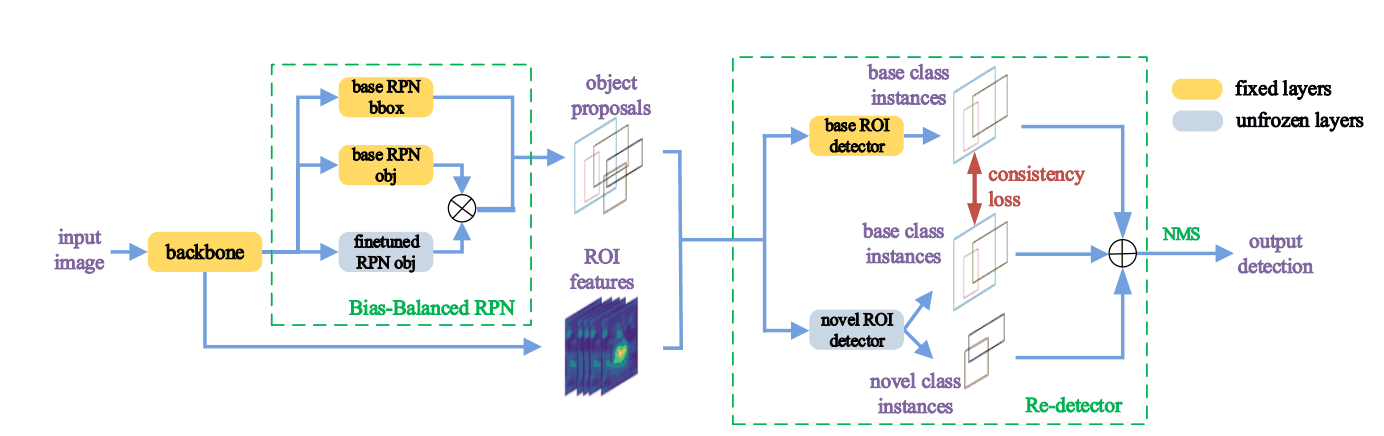
再检测器
Re-detector由两个探测头组成,一个预测具有$f^b$权重的$C_b$对象($det^b$),另一个预测具有微调权重的$C_b /cup C_n$对象($det^n$)。 检测这两个类别可以减少误报:与TFA一样,只对最后一层的$det^n$分类和盒式回归进行了微调。 为了使$det^n$正规化,这里引入了一个辅助的一致性损失。 如果$p_c^b, p_c^n$是被$det^b, det^n$预测为最终类别$c$的概率,一致性损失如下。
$$L_{con}=\sum_{c \in C_b}\tilde{p_c^n}\log(\frac{\tilde{p_c^n}}{\tilde{p_c^b}})$$
然而,同样适用于$\tilde{p_i^n}=\frac{p_i^n}{\sum_{c \in C_b}{p_c^n}}, \tilde{p_i^b}$。最终微调时再检测器的损失函数为
$$L_{det}=L_{cls}^n+L_{box}^n+\lambda L_{con}$$
这将是一种情况。然而,$\lambda$是一个平衡参数。
偏压平衡的RPN
在R-CNNs中,RPNs的准确性非常重要,因为RPNs会产生对象建议。 然而,最后一层是微调的,因为训练好的RPN会错过几张照片级别的物体。 为了保持基础类的准确度,我们提出了一个Bias-Balanced RPN,它整合了训练过的和微调过的RPNs。 给定一个大小为$H\times W$的特征图,基础RPN生成一个对象图$O_b^{H\times W}$,微调RPN生成$O_n^{H\times W}$,最终输出$O^{H\times W}=max(O_b^{H\times W}, O_n^{H\times W})$是取的。 最终的Retentive R-CNN损失函数如下。
$$L_{ft}=L_{obj}^n+L_{det}$$
然而,$L_{obj}^n$是微调RPN的对象层的二元交叉熵。
实验结果
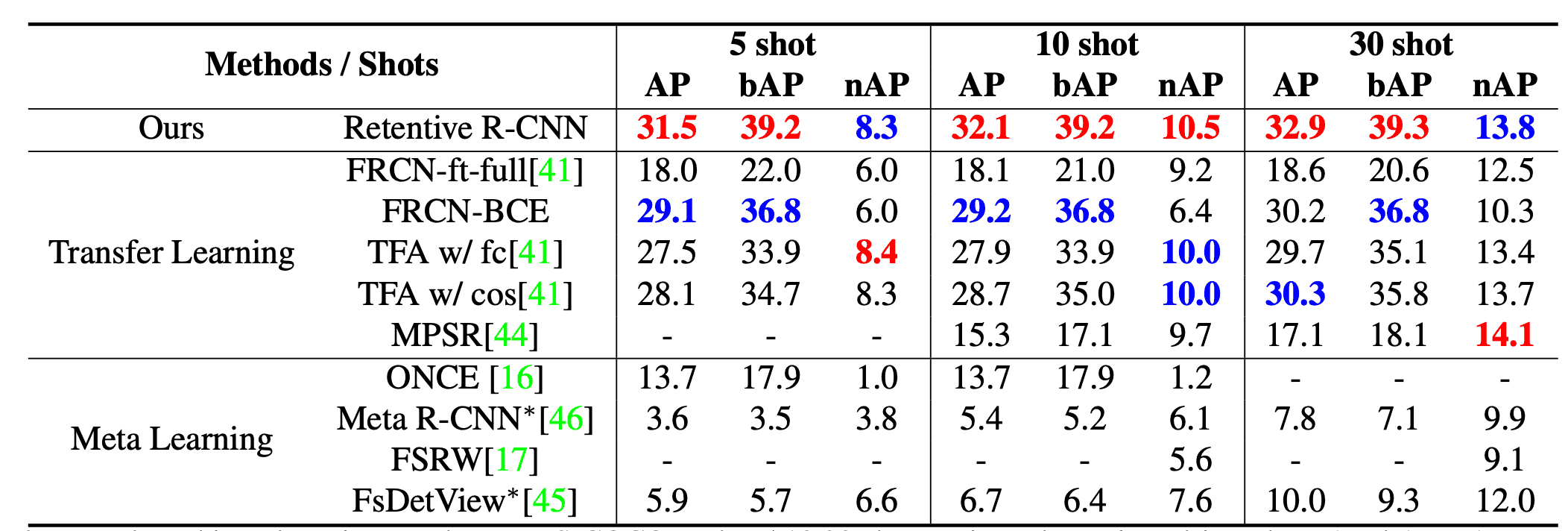
MS-COCO数据集的每个模型的结果如下表所示,其中AP、bAP和nAP分别是总体、基础和少数几个镜头类别的平均拟合率。特别是,Retentive R-CNN在所有拍摄次数的AP和bAP方面表现最好;另一个nAP稍好的模型在bAP方面的表现也明显较差,我们的模型在G-FSD方面表现最好。
下图是Retentive R-CN和TFA w/cos在10次拍摄中的预测结果的一个例子。从图中可以看出,TFA经常漏掉难以理解的物体和包含多个物体的图像,而我们的模型却能很好地检测到它们。

结论
本文开发了一个Retentive R-CNN来实现G-FSD。它是一种基于过渡学习的方法,利用以前被忽视的信息,据此,偏见平衡的RPN减轻了所学RPN的偏见,而重新检测器则以高精确度检测这两个类别。在检测基准上的SOTA,基类的检测性能没有下降。然而,少许照片类和基本类之间的检测性能差距仍然很大,预计未来会有进一步的改进。



与本文相关的类别

![[PETRv2] 仅使用摄像机图像估算物](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/petrv2-520x300.png)




