
DeepFoids:使用深度强化学习模拟鱼群的行为。
三个要点
✔️ 提出了一种通过深度强化学习自主获取适应各种环境的鱼群行为的方法
✔️ 使用提出的方法和Unity模拟的合成数据集与真实的数据集非常相似
✔️ 深度学习模型成功地被训练来计算海湾中的各种类型的鱼类
DeepFoids:Adaptive Bio-Inspired Fish Simulation with Deep Reinforcement Learning
written by Yuko Ishiwaka , Xiao Steven Zeng, Shun Ogawa, Donovan Michael Westwater, Tadayuki Tone, Masaki Nakada
(Submitted on 01 Nov 2022 (v1), last revised 24 Dec 2022 (this version, v2))
Comments: NeurIPS 2022
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
提出了一种利用深度强化学习(DRL)自主生成鱼群行为的方法。这产生了多种不同的集体行为模式,取决于种群密度。然后,通过使用Unity中的环境模拟创建一个高质量的合成数据集,成功地训练了一个深度学习模型来计算鱼塘中的各种鱼的种类。
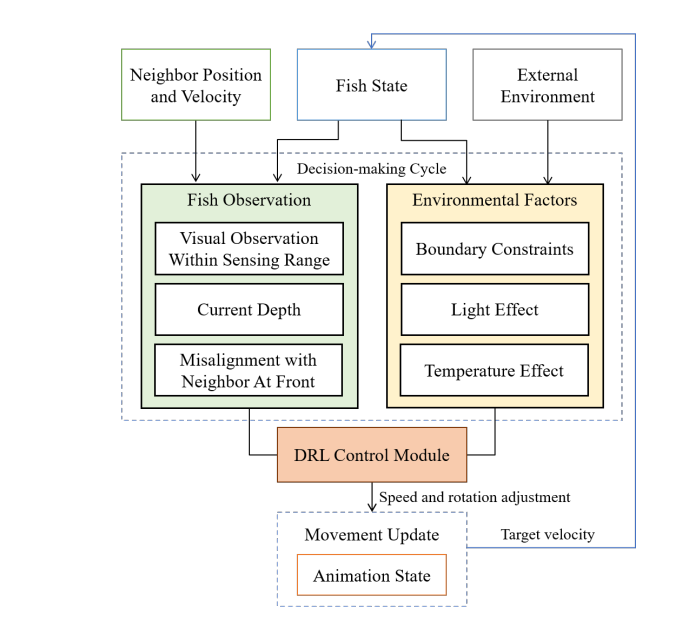
例如,与相邻的鱼保持舒适的距离,并使它们的行进方向与前面相邻的鱼一致。其他因素包括,例如,笼子里的鱼被分成优势和劣势群体,优势成员积极地接近劣势成员并发起攻击性行为。这些因素被纳入学习控制策略的过程中,该策略在每个时间步长t产生鱼的速度Δ$v_t^f$。(更多细节见下文)
鱼类也有喜欢的光照度和水温范围,并会改变它们的垂直位置以保持在它们舒适的范围内。在本文中,它们被表示为Δ$v_{light}$和Δ$v_{temp}$。除了上述组成部分外,我们还将鱼的决策区间纳入框架,以模拟它们对环境变化的延迟反应。模拟决策区间∆$t_{res}$是根据以前的研究预先确定的。给定一个模拟步骤的时间间隔∆$t_{sim}$,鱼在每⌊∆$t_{res}$/∆$t_{sim}$⌋步更新它对环境的观察,并在更新之间采取行动。然后,在每个模拟步骤中要应用的累积速度(∆$v_t^a$)被推导为:
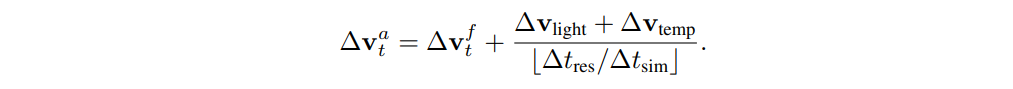
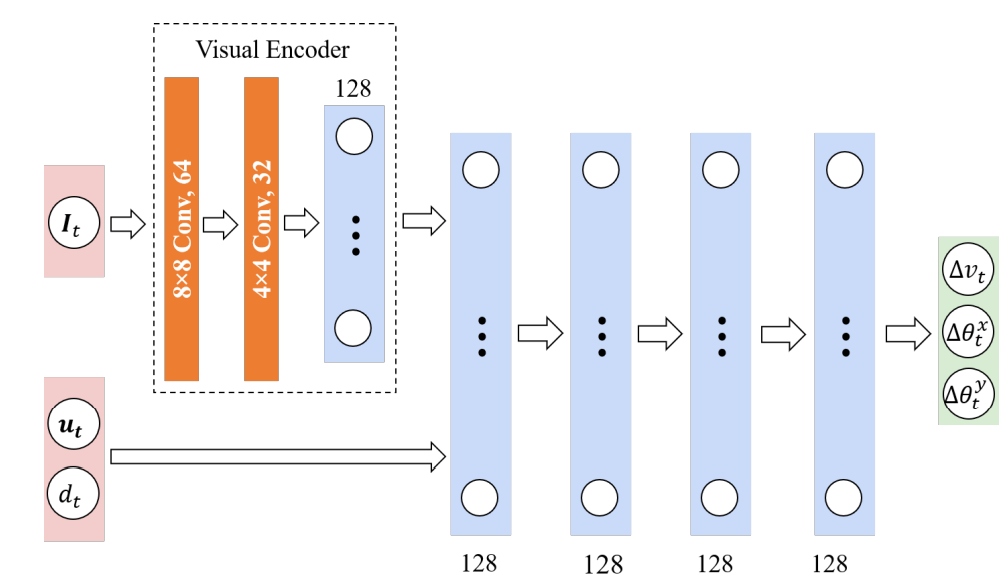
每个状态$s_t$由一个元组($u_t,d_t,I_t$)表示。其中$u_t$是当前时间步长t时代理的前进方向与前面最近的邻鱼之间的差异,$d_t$是代理相对于水面的深度,$I_t$是与视觉信息有关的观察张量。在搜索过程中,鱼代理用空间网格传感器收集视觉观察结果,这些传感器模仿真实鱼的感知区域。视觉观察是一个立方张量,其尺寸是网格的宽度、网格的高度和通道的数量。宽度和高度由网格分辨率定义,网格分辨率被设定为34×20。有六个通道,分别是鱼群感应范围内最近检测到的物体与代理的距离(归一化)$d_{sense}$和物体类型(鱼、边界、障碍物等)的一热编码。对于黄鱼(yellowtail),$d_{sense}$设置为两个体长,对于普通鲨鱼和红鱼,设置为三个体长。所有的状态分量都在代理的本地坐标系中计算,原点位于身体的中心,Z轴与鱼的方向平行。
行为$a$是速度(Δ$v_t$)和围绕x轴(Δ$\theta_t^x$)和y轴(Δ$\theta_t^y$)的旋转角度;围绕z轴的旋转角度被固定在一个小角度$theta^{zt}$以避免不自然的行为。另外,Δ$v_t$被固定在笼子环境中允许的最大速度Δ$v_{max}$。措施网络的结构也显示在下图中。
奖励
每个时间步骤的奖励$r_t$定义如下,以鼓励畜群行为,同时避免冲突。每个人都会逐一解释。
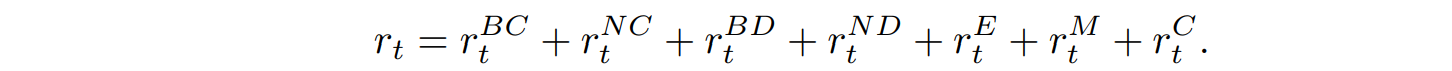
$r_t^{BC}$表示由于与空间边界(如笼壁或水面)的碰撞而产生的惩罚。如果发生边界碰撞,它是一个-300的固定值,否则为0。
$r_t^{NC}$代表与相邻鱼碰撞的惩罚。它用权重$w^{NC}$给出,并根据碰撞代理的数量$N_{hit}$进行累积。
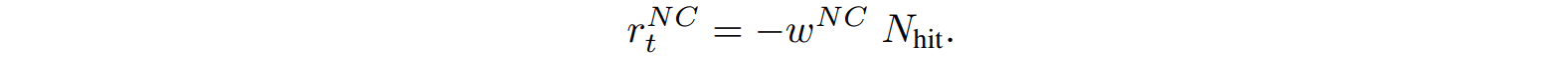
边界规避奖励$r_t^{BD}$鼓励代理人与检测到的空间边界保持距离。其值取决于代理人的感应范围$d_{sense}$、检测到的边界数量$N_{bnd}$、与边界i的距离$d_i$和边界规避权重$w^{BD}$。
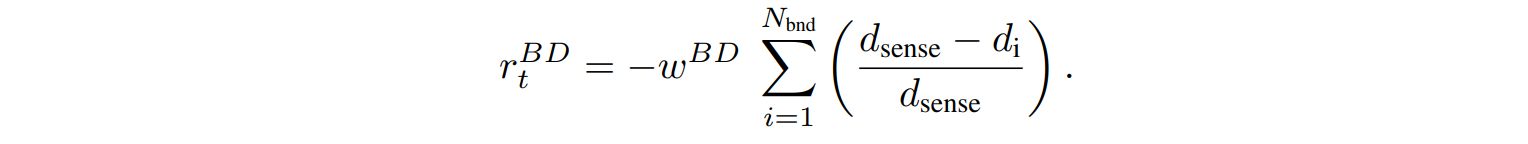
$R_T^{ND}$提示鱼接近其感应范围内的邻鱼,并使其方向与邻鱼的方向一致。代理人与它的每条$N_{nei}$体邻鱼的方向之间的角度∆$theta_i^{mov}$(单位:度),用权重$w^{ND}$计算。
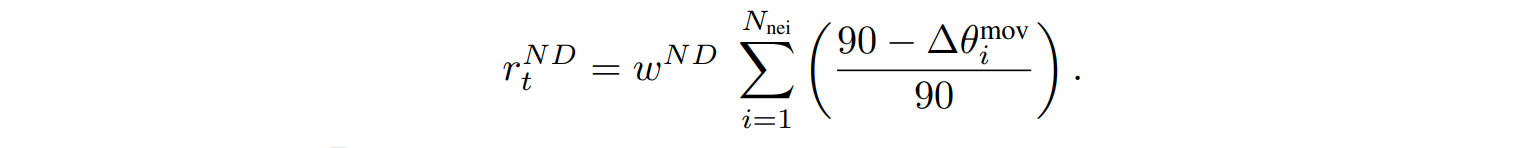 另一方面,$r_t^E$用于惩罚鱼在旋转身体或调整速度时的能量消耗。它由旋转惩罚权重$w^r$、速度惩罚权重$w^s$以及当前时间步长的身体旋转角差Δ$theta_t$和累积速度差Δ$v_t^a$计算得出。
另一方面,$r_t^E$用于惩罚鱼在旋转身体或调整速度时的能量消耗。它由旋转惩罚权重$w^r$、速度惩罚权重$w^s$以及当前时间步长的身体旋转角差Δ$theta_t$和累积速度差Δ$v_t^a$计算得出。
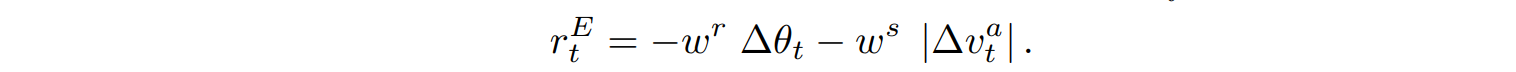
运动奖励$r_t^M$鼓励鱼游得比最低速度快,并惩罚由于积极的俯仰运动(围绕局部X轴)而导致的快速深度变化。在以下公式中,变量$theta^{rt}$代表俯仰角阈值,$v^{st}$代表速度阈值,$theta_t^x$代表当前俯仰角,$v_t^a$代表当前累积速度。
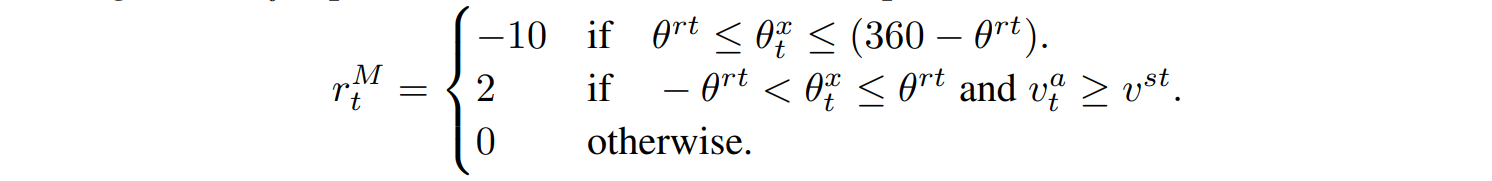
最后,$r_t^C$是一种跟踪奖励,鼓励基于鱼的社会地位的攻击或逃跑行为。优势鱼(攻击者)以小概率$p_a$随机启动追逐模式,对最近的从属鱼(目标)发起攻击。这导致被追赶的鱼启动逃跑模式并游离攻击者。如果攻击者与目标相撞,它就会得到一个固定的大数值的奖励。这个过程用攻击者的速度$v_t^a$、从攻击者到目标的归一化矢量d、攻击者的跟踪奖励权重$w_{agg}$和目标的逃脱惩罚权重$w_{tar}$表示如下。

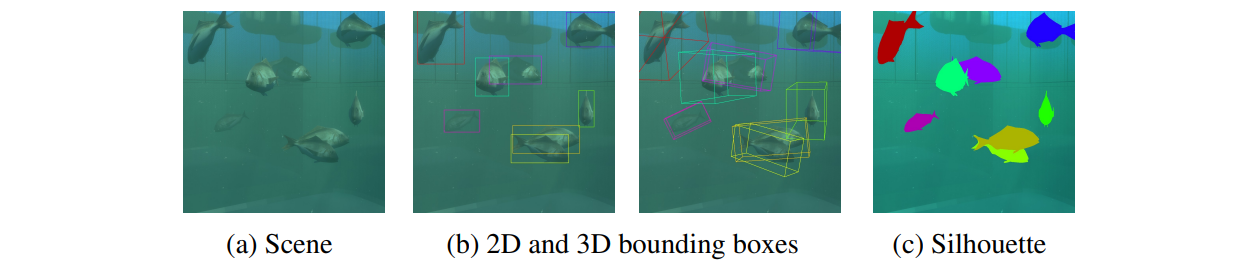
鱼类计数系统由三个模块组成:i)图像预处理模块,将输入视频转换为图像序列并进行去噪;ii)鱼类检测模块,使用合成数据集训练一个基于YOLOv4的网络;以及iii)鱼类计数模块。
培训
研究中使用了三个鱼种:凌波鱼、黄鱼和红鱼。我们首先对每个物种进行了单独的预学习,然后在具有不同鱼种、鱼的大小、鱼的数量、笼子的大小和笼子的几何形状的环境中进行转移学习。我们发现,使用这种两阶段的学习方案比在每个环境中从头开始学习,收敛速度更快,整体性能更好。我们还允许代理人在与笼壁或水面相撞时提前终止一个情节。在这种情况下,代理人从笼子里的一个随机位置恢复新的情节,具有随机有效旋转和初始速度$v_0$。
鱼类行为
从模拟得到的图像和水下拍摄的图像之间的定性比较见下图。这些图像显示,这三种鱼的游动方式不同。这些行为的差异和环境的变化,如照明、水色和浊度,在模拟中成功地再现了。
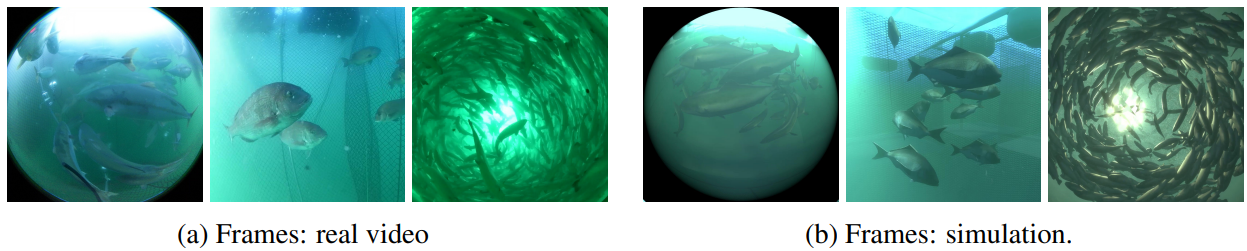
为不同鱼种、鱼的大小、鱼的数量、笼子的大小和形状设置的五个不同环境的模拟结果如下图所示。根据收集到的现场数据,灵鱼、黄鱼和鲷鱼的默认体长分别被设定为0.49米、0.52米和0.34米。鱼类的游动方式取决于场景的构成,这是由于前面所描述的各种因素的组合。例如,图a中的10条红鱼(左边三个板块)由于笼子的尺寸较小,学会了围绕笼子中心缓慢游动,而图a中同样的10条鱼(右边三个板块)由于笼子尺寸大得多,学会了远离中心快速游动。相比之下,图b中的红鱼由于体积较大,形成了一个更紧凑的鱼群,慢慢地绕过了整个小笼子。我们还模拟了两个虚构的场景,其中有不同大小的鱼(图c)和多个物种(图d)。不同大小和种类的鱼以不同的方式游动,影响了同一笼子里其他群体的游泳行为。

模拟与现实
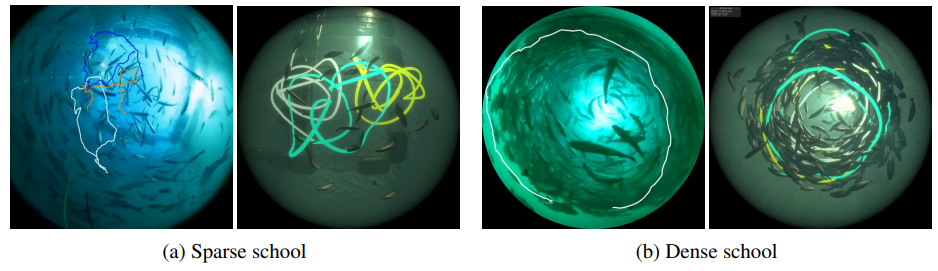
笼子里的鱼的密度和鱼的游动状况之间的关系是研究的重点,将模拟结果与真实数据进行比较。在模拟中使用了两种类型的笼子:稀疏的(0.59条鱼/$m^3$)和密集的(14.7条鱼/$m^3$)。在实际养殖场中,稀疏笼子是6.5米×6.5米的正方形,深6米,可容纳272条鱼,而密集笼子是八角形,边长6.5米,深10米,可容纳约3000条鱼。下面的数字显示了鱼在(a)稀疏和(b)密集情况下的轨迹。左图为实际图像,右图为模拟结果,显示绘制的轨迹是相似的。
数鱼
在合成数据集上训练的YOLOv4模型被应用于真实镜头。下图显示了使用凌波微步、黄鱼和红鱼镜头的结果。训练好的鱼类计数算法被用来估计下图中每一帧的鱼类数量。凌波鱼、黄鱼和红鱼的计数结果分别为69:61、22:32和7:7(左:学习模型,右:人工计数)。这表明,当鱼的密度高,闭塞现象普遍时,计数的准确性较低。

本文介绍了DeepFoids,一种利用深度强化学习自主获取适应各种环境的鱼群行为的方法。在一个任意环境的鱼塘中,利用多代理DRL实现了蜂群行为的再现。此外,纳入基于物理学的模拟,能够直观地再现不同地点和季节的水下景观,使生成的图像数据集与真实情况非常相似。
一个挑战是奖励函数的权重是手动设置的,有人提到他们计划探索允许动态调整权重的技术,因此我们期待着未来的进一步发展。



与本文相关的类别






