生成自动驾驶的可变模拟器:DriveGAN!
三个要点
✔️ 创建一个可以控制代理的DIFFERENTIAL仿真。
✔️ 提出DriveGAN生成动力学模拟器的建议
✔️ 成功地生成了高度准确的模拟器,其评价指标包括FVD和行动一致性等。
DriveGAN: Towards a Controllable High-Quality Neural Simulation
written by Seung Wook Kim, Jonah Philion, Antonio Torralba, Sanja Fidler
(Submitted on 30 Apr 2021)
Comments: Published as CVPR 2021 Oral.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
code:

纲要
自动驾驶要怎样才能上公共道路?近年来,在公共道路上测试自动驾驶汽车已成为可能,但仍有一些不足之处,例如最近Waymo的案例,由于一条车道正在施工,汽车开错了方向(Waymo自动驾驶出租车被交通锥体迷惑,逃离帮助)。锥体逃逸的帮助)。)由于在公共道路上进行实验的危险性以及天气条件和车辆数量的物理限制,正在使用模拟器进行实验。在过去,这样的模拟器是手动创建的,但通过使用机器学习,可以直接从数据中学习环境中的行为变化,从而创建一个可扩展的模拟器。

因此,在这项研究中,我们使用机器学习技术来生成一个神经模拟器,可以用来演示自动驾驶。我们提出了DriveGAN,它通过观察一连串未连接的帧和它们相应的行为,直接从像素空间学习模拟动态环境。DriveGAN通过对不同成分的无监督分解(即从图像空间到潜伏空间,再到语义空间的映射,可以看作是独立的集合)获得可控性。除了由手柄控制外,还可以对特定场景的特征进行采样,并有可能控制天气和物体的位置。
由于DriveGAN是一个完全可分的模拟器,当给定一连串的视频时,代理可以重现同一场景,甚至可以在同一场景中执行不同的动作(重新模拟)。此外,DriveGAN使用变异自动编码器和生成对抗网络来学习图像的潜空间,就像动力学引擎学习潜空间的转换一样。
什么是神经模拟器?
神经 模拟器通过组织视频数据与行为,直接从像素空间中学习根据代理人的行为模拟环境。方法。
关于DriveGAN
本研究的目的是通过观察一连串的视频和相应的动作来学习一个高质量的可控神经模拟器。DriveGAN主要从两个方面获得可控性。
- 存在一个可以被特定行动所控制的自我代理。
- 能够控制不同的可能点,如改变当前场景对象或背景的颜色
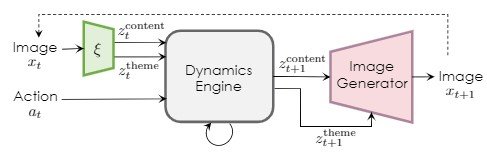
我们将在下文中设置所使用的变量。首先,让$x_t$为时间为$t$的视频帧,$a_t$为动作序列;学习视频帧$x_{1:t}$和从第1秒到第t秒的动作$a_t$来生成下一帧$x_{t+1}$。它通过无监督学习,生成分解的潜在变量$Z^{theme}$和$Z^{content}$。这里,主题指的是与背景颜色或天气像素信息无关的信息,而内容指的是空间元素。
动力引擎由一个递归神经网络组成,从当前的潜变量和行动中生成下一步的潜变量。然后,使用图像解码器将下一步生成的潜变量做成输出图像。
在这项研究中,我们参照世界模型,成功地生成了更准确的时间序列图像序列。接下来,我们描述了编码解码器的结构,该编码解码器经过预训练,可将图像投射到潜空间。
预先训练的潜伏空间
DriveGAN使用StyleGAN的图像解码器,并为主题内容的拆分稍作改进。由于提取输入图像的GAN潜变量并非易事,我们使用编码器$/xi$明确地将图像$x$投射到潜变量$z$。在这里,我们使用$\beta$-VAE 来控制损失函数中的Kullback Leibler项。
我们通过添加以下基于StyleGAN对抗性损失的VAE损失函数来训练发生器。
\begin{equation} L_{VAE} = E_{z \sim q(z|x)}[\log (p(x|z))] + \beta KL (q(z|x)||p(z)) \end{equation}
这里,$p(z)$是标准先验分布,$q(z|x)$是使用编码器$xi$的近似后验分布,KL代表Kullback-Leibler信息含量。在代表重建误差的条款中,我们学习减少输入和输出图像之间的PERCEPTUAL DISTANCE ,而不是像素之间的距离。
为了创建一个可控的模拟,我们设计了一个编码器和解码器。
剥离输入图像的主题和内容。

编码器$xi$由一个特征提取器$xi^{feat}$、两个编码头$xi^{content}$和$xi^{theme}$组成。 $xi^{feat}$由多个卷积层组成,这样,图像$x$被输入,输出被传递到两个头。 $xi^{content}$产生了一个$N×N$维度的$z^{content} \in \mathbb{R}^{N x N x D_1}$。 另一方面,$xi^{theme}$生成一个单一的矢量,即$z^{theme} \in \mathbb{R}^{D_2}$,这样,输出图像的主题是可控的。 这些潜变量统统用$z = \{ z^{content}, z^{theme} \}$表示。
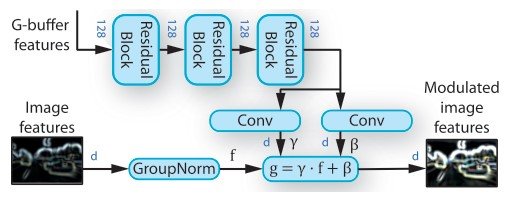
接下来,生成的潜变量$z$被输入到StyleGAN的解码器,它可以通过在生成器的每个卷积层之后使用自适应实例归一化(AdaIN)来控制生成图像的外观。 AdaIN适应了与归一化特征图的空间位置相似的缩放和偏置。
\begin{equation}AdaIN (m, \alpha, \gamma) = \mathcal{A}(m, \alpha, \gamma) = \alpha \frac{m - \mu(m)}{\sigma(m)} + \gamma \end{equation}
$m\in\mathbb{R}^{NxMx1}$是特征图,$alpha,\gamma$是对应于缩放和偏差的常数。通过将这个$z^{theme}$输入MLP,我们得到了AdaIN层中使用的缩放和偏置的值。
然后,从$z^{content}$的形状,我们可以对$N x N$的网格位置所对应的内容信息进行编码。在StyleGAN中,我们使用$z^{content}$作为输入,而不是通常的块状输入。
此外,我们从标准先验分布中抽出一个新的向量$v\in\mathbb{R}^{1x1xD}$来替代网格位置内容。编码方面的这些创新使我们能够在有多个物体的场景中获得详细的信息,因为缩放和偏向与AdaIN层中空间的位置相对应。此外,还采用了多尺度多斑块判别器作为判别器,它可以生成更复杂场景的高度精确图像。对于损失函数,我们使用与StyleGAN相同的对抗性损失函数,最终的损失函数是$L_{pretrain} = L_{VAE} + L_{GAN}$。
作为一个简单的实验结果,我们发现,通过减少KL项中使用的$/beta$的值,重建的质量得到了改善,但我们也发现,当动态模型难以学习动态时,学习到的潜空间离先验分布很远。这意味着$Z$对$X$是过度学习的,而从过度学习的潜空间中学习过渡是未来的任务。
动力引擎
在用上述编码器-解码器进行预训练后,这里介绍的动力学引擎根据编码器-解码器得到的潜在变量,学习每一步的行动$a_t$的转换。为了只学习动态引擎的参数,编码器和解码器的参数是固定的。这使得在训练之前提前提取数据集的潜在变量成为可能。由于输入是一个潜在的变量,它比用图像学习要快得多。此外,我们将从潜在变量$Z^{content}$中获得的内容信息分解为行动依赖和行动无关的特征。

在三维环境中,视点根据自我代理的运动而改变。由于这种变化在空间上自然发生,我们行使卷积LSTM模块来学习每个时间步骤的空间转换。
我们还增加了一个LSTM模块,它只接受$z_t$作为输入。这使我们能够处理与行动$a_t$无关的信息。
直观地说,$Z^{a_{indep}}$是用来确定空间张量$Z^{a_{dep}}$通过AdaIN层的风格。由于$Z^{A_{indep}}$本身不能提供行动信息,所以它不能学习下一帧的寻求。这种结构使我们能够将行动相关的特征(如场景的布局)与行动无关的特征(如物体的类型)分开。因此,引擎只需要考虑与行动相关的特征来学习动态。这是用较小的模型进行学习的更好方法。
接下来是学习。在训练中,我们扩展了GameGAN在潜伏空间的训练程序,用对抗性损失和VAE损失进行训练。对抗性损失$L_{adv}$由两个网络组成①潜伏判别器②时间性的以行动为条件的判别器。
\begin{equation} L_{DE} = L_{adv} + L_{latent} + L_{action} + L_{KL} \end{equation}
我们用$L_{adv}$是铰链损失与对抗性损失。我们还对$R_1$进行梯度正则化,对真实数据的判别器的梯度进行惩罚。$L_{action}$通过将时间判别器特征$z_{t, t-1}$通过具有动作重建损失的线性层来重建输入动作$a_{t-1}$,并计算其平均平方误差。在$L_{latent}$中,损失函数衡量生成的$z_t$是否与输入的潜变量相匹配,并被训练为减少KL惩罚。
差异化的模拟
由于DriveGAN是可分的,因此可以通过找到构成视频的一些因素来重现场景和情景,甚至是代理人的行动。我们称这种模拟为可微调模拟。一旦找到可配置的参数,代理可以使用DriveGAN在同一场景中重新模拟不同的动作,由于DriveGAN还可以对场景中的各种组件进行采样和改变,因此可以使用同一场景在不同的天气条件和物体下重新模拟代理。同样的场景可以用来实验不同天气条件下和不同物体下的代理。
这里对AGENT的测试是用一个公式表示的。
\begin{equation} \underset{a_{0 . . T-1}, \epsilon_{0 . . T-1}}{\operatorname{minimize}} \sum_{t=1}^{T}\left\|z_{t}-\hat{z}_{t}\right\|+\lambda_{1}\left\|a_{t}-a_{t-1}\right\|+\lambda_{2}\left\|\epsilon_{t}\right|| \end{equation}
$epsilon$是一个随机变量,在模拟中概率性地生成未来的场景。真实世界的视频是$x_0, \ldots, x_T$,$z_t$是模型的输出,$hat z_t$是使用编码器编码$x_t$的潜变量,$lambda_1, lamda_2$是用于规范化的超参数。 行动。为了保持一致性,我们使用$a_t$和$a_{t-1}$的正则化项。
实验和评估
实验设置
我们使用了几个数据集:卡拉模拟器,这是一个自动驾驶的模拟器;吉布森环境,它用物理引擎和可控制的虚拟代理来模拟真实世界的室内建筑环境;以及真实世界驾驶(RWD),它记录了人类在多个城市和高速公路的驾驶。行动是二维的,由代理人的速度和角速度组成。
定性评价
模拟器的质量方面从两个方面进行评估:一个是模拟器生成的视频是否真实,其分布是否与真实视频的分布相匹配,另一个是ACTION是否真实可接受。为了衡量这些,我们创建了两种评价方法来评估它们。
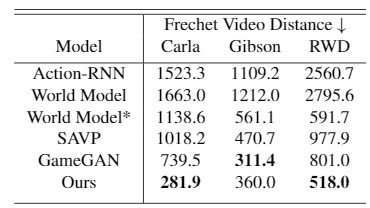
基准模型是Action-RNN,一个简单的动作跟随RNN模型,随机对抗视频预测(SAVP),GameGAN,和一个用基础RNN训练的混合分布网络。世界模式。以下是结果。
第一种评估方法是使用Fr ́echet VideoDistance(FVD )测量地面真相和生成视频分布之间的距离。
在人类评价中,其结果也是高质量的。

第二种是行动一致性的测量,用CNN训练从真实世界视频中提取的两幅图像,以预测代表图像中一个过渡的行动。然后对模型进行训练,以减少输入动作和预测动作之间的平均平方误差。

差异化的模拟
DriveGAN允许你使用从先验分布中采样的潜变量$z^{a_{dep}}, z^{a_{indep}}, z^{content}, z^{theme}$来控制模拟。
在下图中,背景颜色和天气可以通过采样$Z^{theme}$并改变它。
通过对不同的$Z^{A_{DEP}}$进行采样,我们可以对内部进行如下改变。

同时,$Z^{content}$可以通过改变空间张量中的每个网格单元来改变相应单元的成分。
在最后
DriveGAN提出了一个可控的、高质量的模拟,它使用编码器和图像GAN来生成一个潜伏空间,动态引擎可以在其中学习帧之间的转换。我们已经成功地对场景的不同组成部分进行了无监督的分解和采样。这允许用户在模拟过程中交互式地编辑场景,并创建独特的场景。在未来,这项研究有望创造一个环境,在这个环境中,可分化的模拟可以用于昂贵的实验,如机器人和自动驾驶。
另外,一旦现在发布了代码(在写作时:2021年6月7日),我想我们就可以用以下的用户界面来使用模拟器,这应该很有趣




与本文相关的类别






