对深度强化学习算法的评估是否准确?
三个要点
✔️ 检验深度强化学习的评价标准的偏差和不确定性
✔️ 重新审视现有的算法评估
✔️ 提出低运行次数下更有效的评价标准
Deep Reinforcement Learning at the Edge of the Statistical Precipice
written by Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, Marc G. Bellemare
(Submitted on 30 Aug 2021 (v1), last revised 13 Oct 2021 (this version, v3))
Comments: NeurIPS 2021.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Methodology (stat.ME); Machine Learning (stat.ML)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
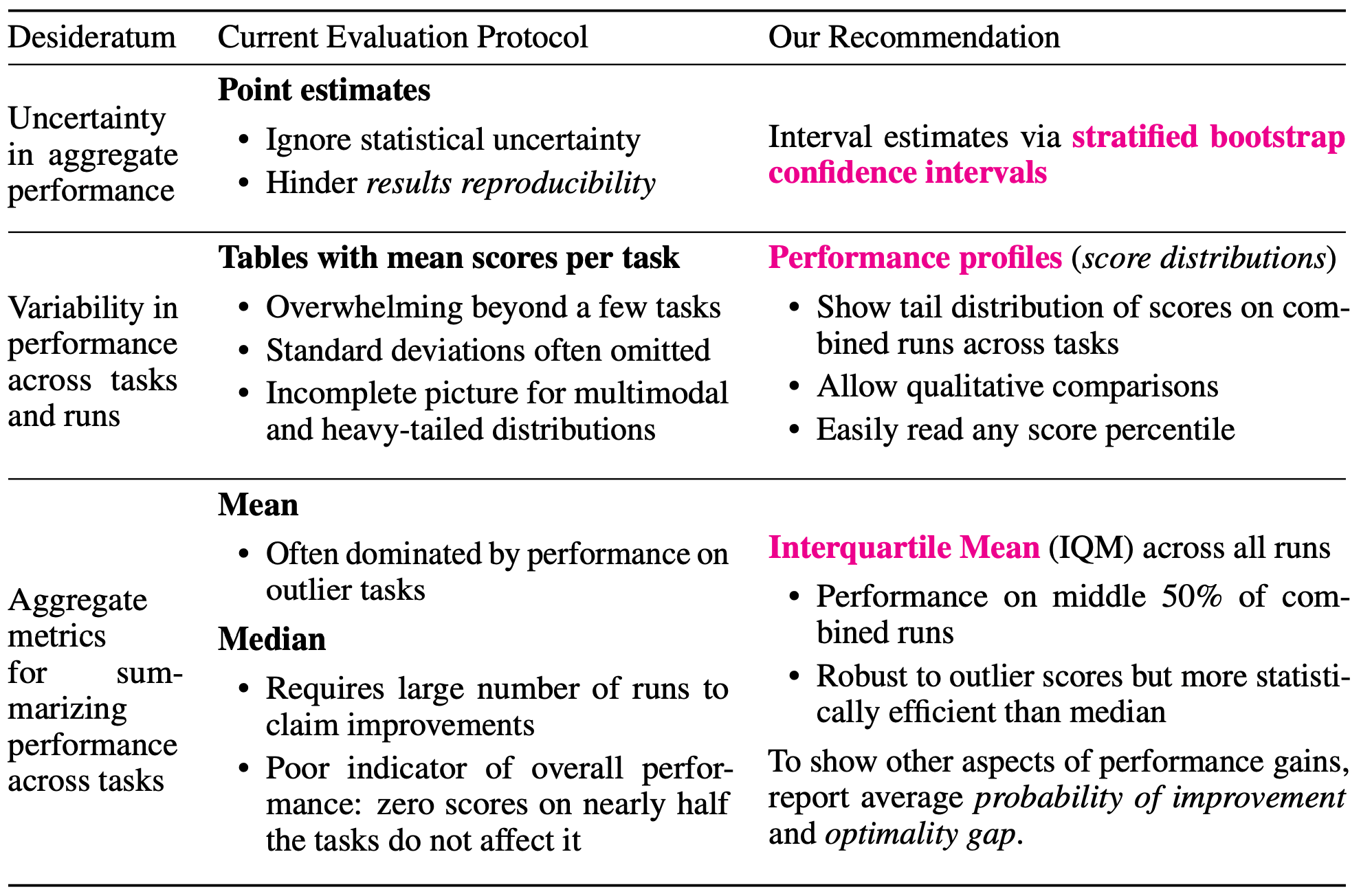
现有的深度强化学习(RL)算法的评估依赖于点估计的比较,如平均和中位任务性能,并倾向于忽略统计的不确定性。
随着基准的计算负荷越来越大,增加性能评估的运行次数变得越来越困难,这种趋势也变得越来越严重。
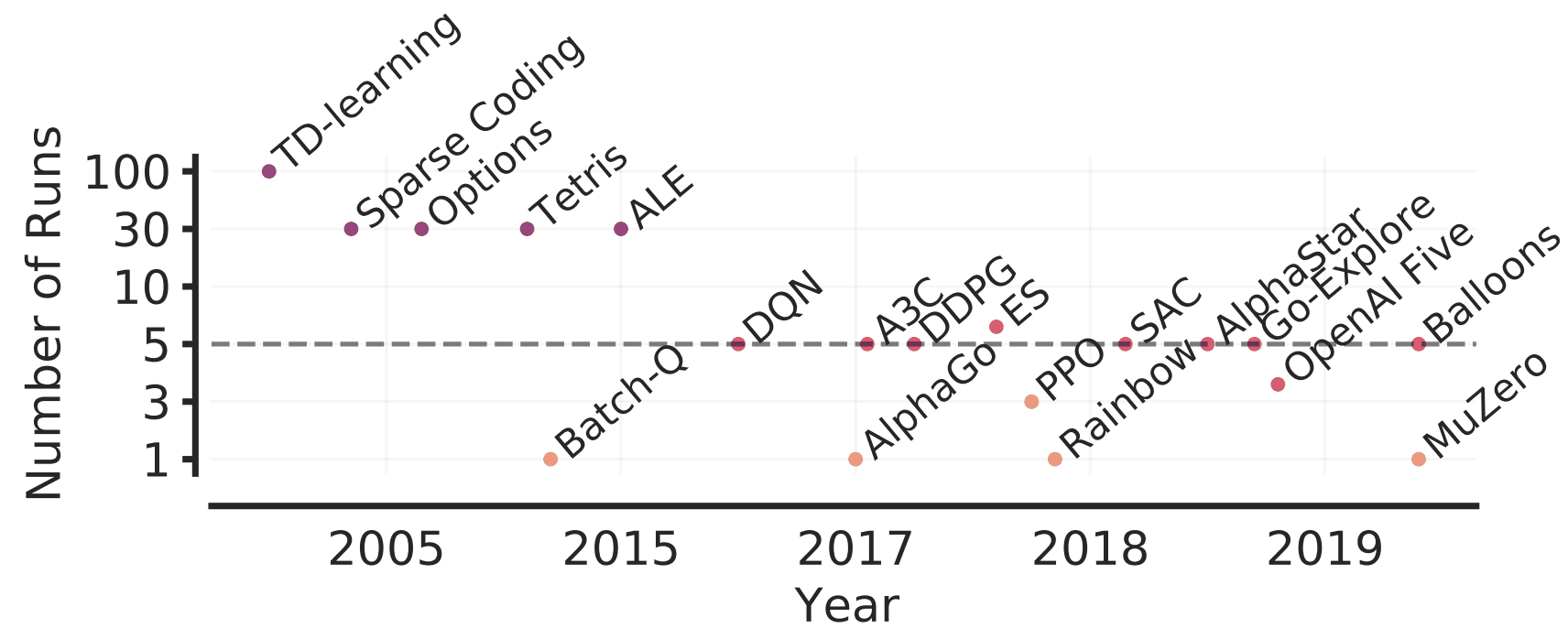
在这篇文章中,我们表明了现有的依靠点估计的评价方法存在的问题,并提出了一个更严格的评价方法。下面我们就来看看。
关于强化学习算法的性能测量
对于一个强化学习算法,要执行$m$任务N$次,并用于评估其性能。
其中每个归一化的分数用$x_{m,n}$表示($m=1,.,M, n=1, ...,N$),这些集合用$x_{1:M,1:N}$表示,第m$个任务的归一化分数的概率变量用$X_m$表示。
强化学习算法的一个常用性能指标是归一化分数的样本平均值或样本中位数。
这表示为$Mean(bar{x}_{1:M})$或$Median(bar{x}_{1:M})$,其中$m$任务的平均得分是$bar{x}_m==frac{1}{N}\sum^N_{n=1}x_{m,n}$。
这些值对应于$Mean(\bar{X}_{1:M})$和$Median(\bar{X}_{1:M})$的点估计。
关于Atari 100k基准中的点估计
雅达利100k基准在26个不同的游戏上评估了该算法,每个游戏只有100k步。在以前使用该基准的案例中,使用3、5、10或20次运行来评估性能,大多数情况下只运行3或5次。使用的主要评价指标是样本的中位数。
这里我们比较了五种最近的深度RL算法的性能,作为在低运行次数下使用点估计进行评估的一个具体例子。
在我们的实验中,我们对DER、OTR、DRQ、CURL和SPR这五种算法各运行100次,对其中一部分进行子抽样,并测量结果的中位数。
我们将利用这一点来研究少量运行的中位数。
点估计的变异程度
在次抽样时,我们收集的结果数量与论文中的运行数量相同:DER、OTR和DRQ的中位数为5次,CURL为20次,SPR为10次。
实验结果如下
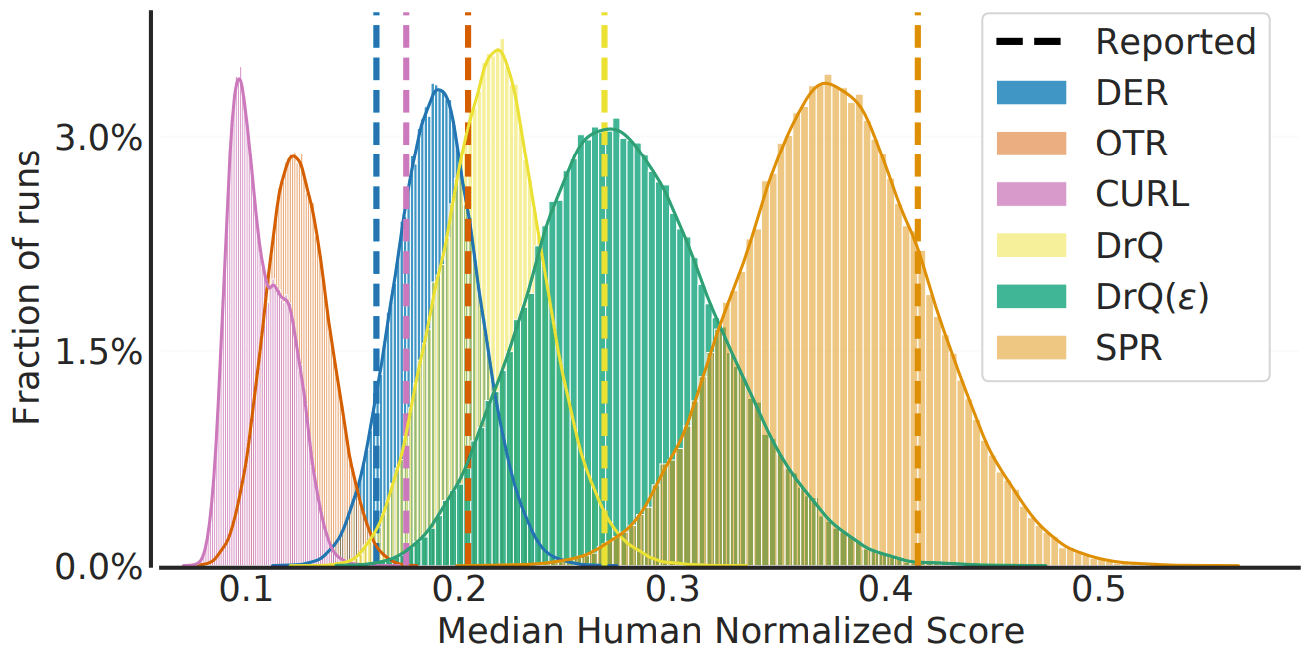
该图显示了获得的中位数和论文中报告的数字的分布。总的来说,可以看出,从小样本中得到的样本中位数有很大的变异性,基于点估计的比较可能导致错误的结论。
评价协议的变化对算法的比较也有很大影响。
虽然通常使用最后一次训练的分数来评估强化学习算法,但也可以报告训练期间的最高分数或多次运行的分数。事实上,当DER的评价协议改为CURL/SUNRISE的评价协议时,结果发生了很大变化,如下图所示。

因此,除了在运行次数少的情况下,点估计的可变性外,评估协议的变化也对强化学习算法评估的准确性有很大影响。
可靠评估的建议和工具
由于该基准的高计算负荷,增加运行次数来解决上述问题并非不切实际。
为了解决这个问题,原论文提出了三个工具来可靠地衡量运行次数。
分层引导法的置信区间
第一种是使用分层抽样的引导法来获得置信区间。
由于在$N$较小的情况下,使用自举法计算单个任务的平均得分并不有用,我们在$N$的每个任务的$N$运行中进行抽样,并以此来获得置信区间。
业绩概况
第二种是使用性能配置文件,用来为优化软件设定基准。
更具体地说,有人提议使用分数分布(或运行分数分布),它表示具有某种规范化分数或更高的运行比例。这由以下公式给出
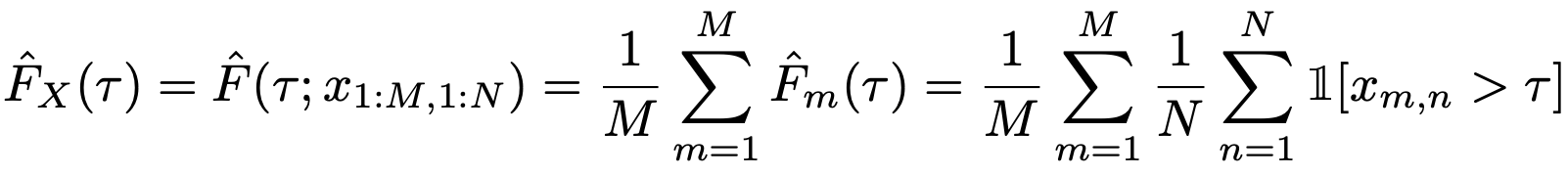
比较的实际结果也显示在下面。
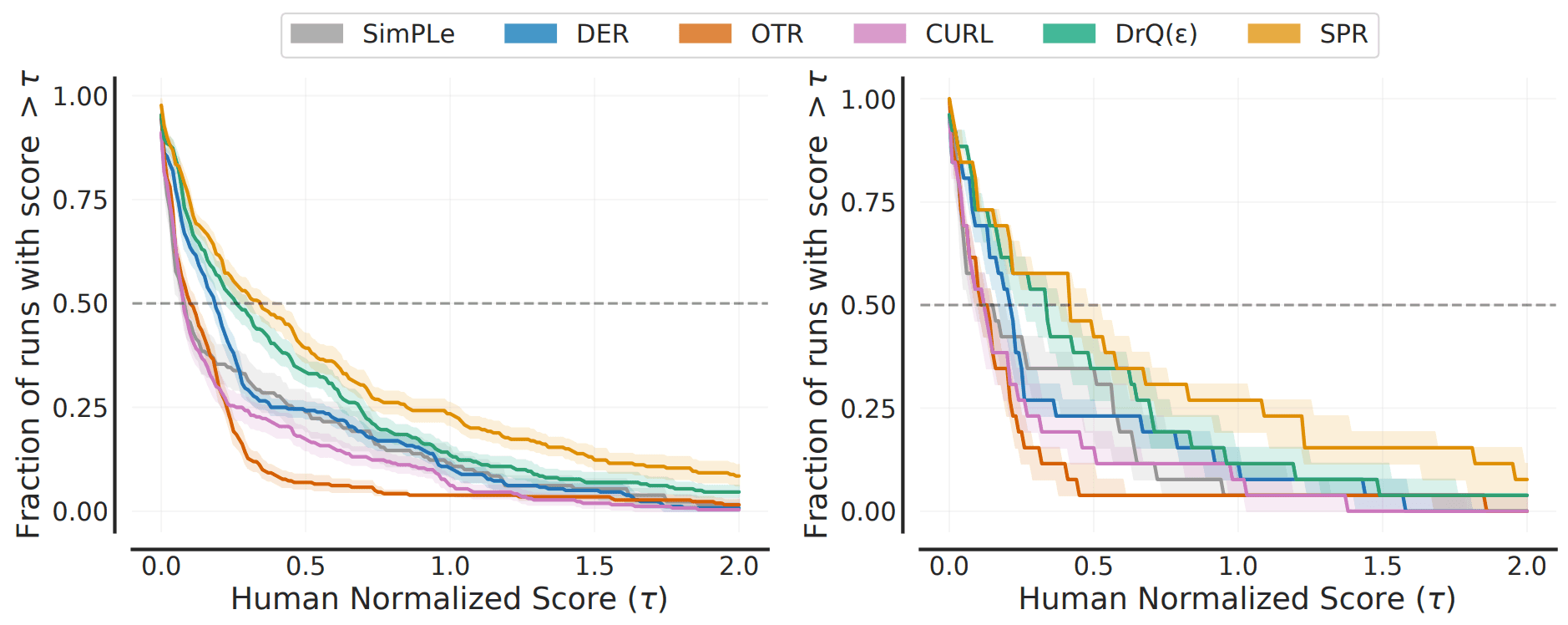
对于这个图,左边显示的是分数分布,右边显示的是平均分数分布(表现在某个归一化分数以上的任务的百分比),其中分数分布的方差较小,是一个更稳健的衡量标准。
四分位数间平均值(IQM)
对于像分数分布这样的衡量标准,当这两条曲线在几个点上相交时,可能很难分辨出哪条曲线是主导的。
因此,有人建议使用四分位数间平均数(IQM)作为综合衡量标准,可以代替中位数使用。这是以剩余50%人口的平均数计算的,不包括最低的25%和最高的25%。
IQM对离群值更为稳健,是比中位数更好的整体性能衡量标准,因为中位数在很大程度上取决于任务之间的顺序。事实上,对于上述五种强化学习算法,平均值和IQM的95%置信区间如下所示
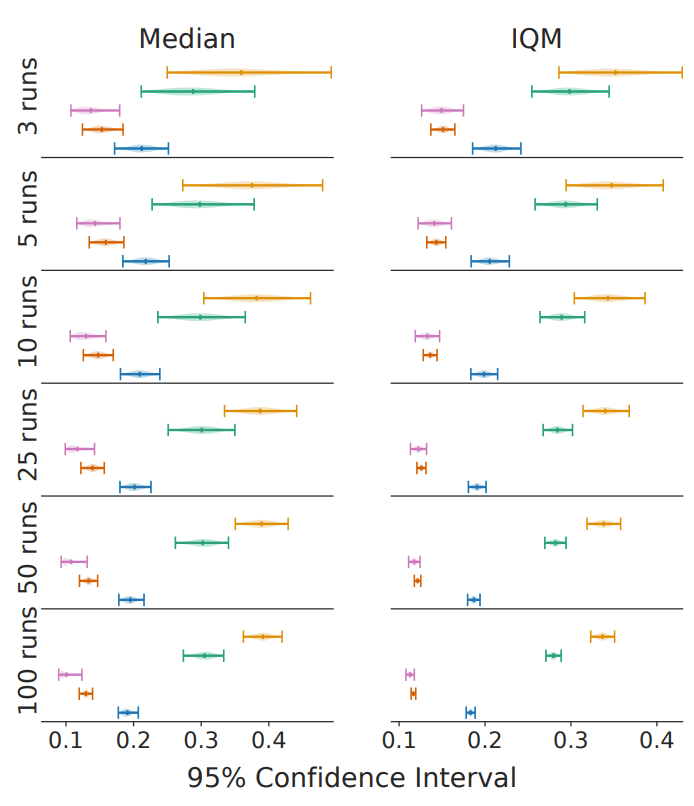
该图显示,即使试验次数少,不确定性也保持得很小。
关于对深度强化学习基准的评估
最后,我们讨论了对几个现有的深度强化学习基准的评估。
拱廊学习环境(ALE)
ALE中200M框架的学习基准被广泛认可。对于这个基准,我们衡量了现有算法在各种指标上的性能,具体如下
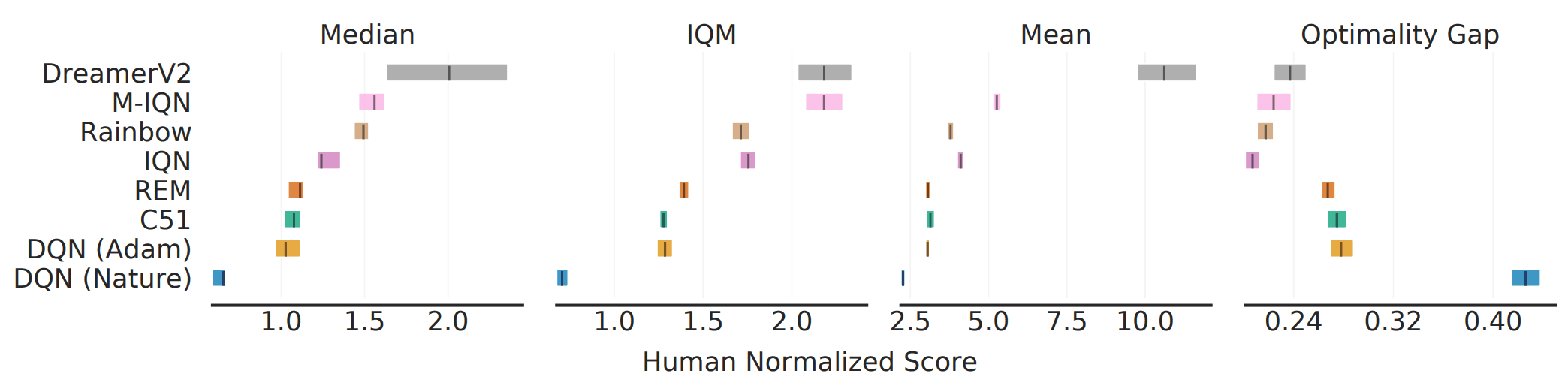
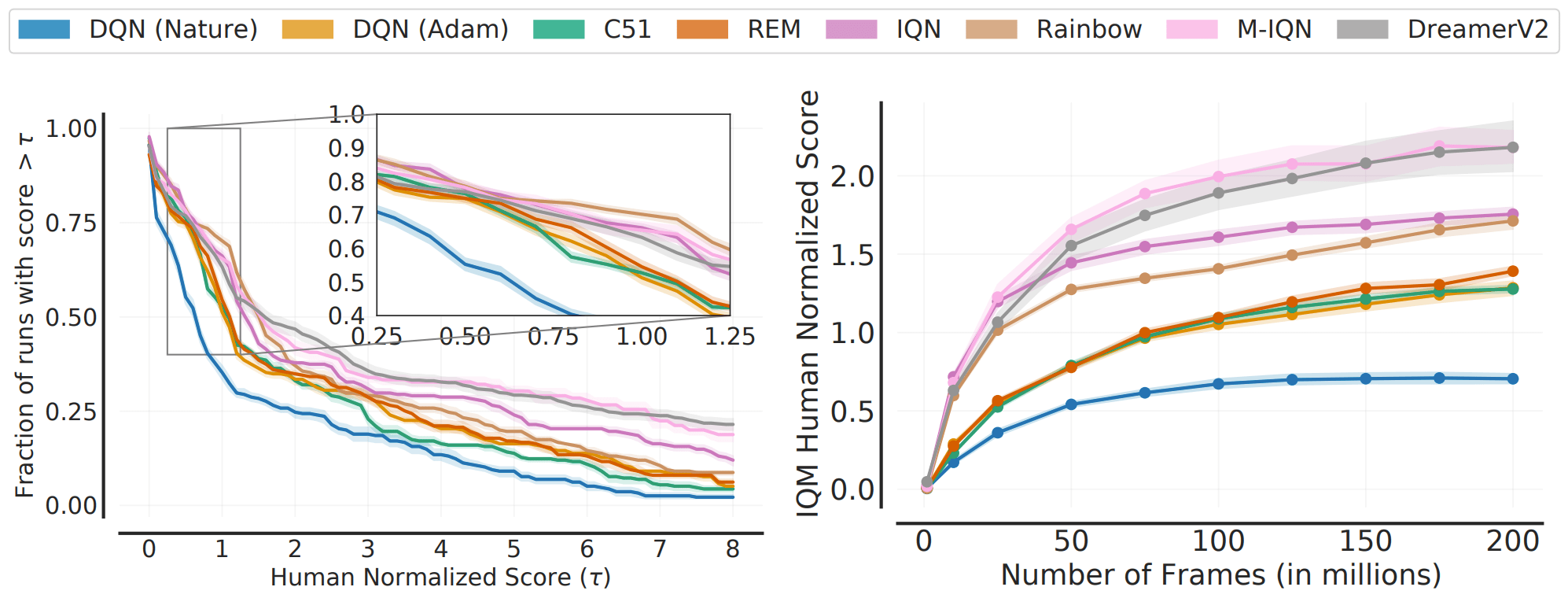
如图所示,有些情况下,指标的选择会改变算法之间的排名(如中位数和IQM)。这表明,综合指标并不能反映整个任务/执行的所有性能。
DeepMind控制套件
接下来,连续控制任务--DM控制的结果如下
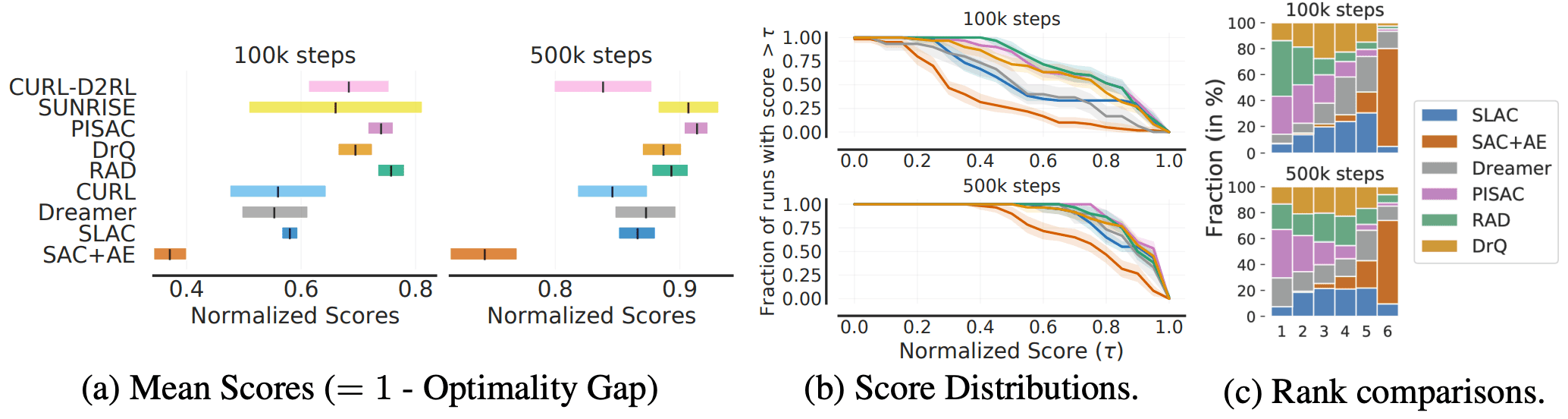
图中的算法是按照论文中宣称的相对性能顺序排列的,但实际上由于不确定性,有很多变化,实际性能和报告性能之间可能存在差异。
摘要
对于深度强化学习算法,有人认为其报告的性能受到偏见和不确定性的严重影响。本文介绍了减少偏差和不确定性的衡量标准,以及减少偏差和不确定性的建议。
还有一个库可以用来对强化学习进行更准确的评估和分析。请连同原始文件一起看一下吧。



与本文相关的类别






