这次我们能否彻底改变强化学习,变形金刚的挑战?
三个要点
✔️ 决策转化器,将强化学习作为自回归模型的同步概率分布序列建模。
✔️ 一个对GPT的因果转化器进行简单改编的架构。
✔️ 在离线RL设置中实现无模型方法的SOTA
Decision Transformer: Reinforcement Learning via Sequence Modeling
written by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch
(Submitted on 2 Jun 2021 (v1), last revised 24 Jun 2021 (this version, v2))
Comments: Accepted by arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:

介绍:变形金刚也能彻底改变RL吗?
最近的工作,包括Zero-shot语言生成模型GPT-3和out-of-distribution图像生成模型DALL-E,表明变形金刚可以学习高阶语义概念,这是受NLP出生的变形金刚在CV世界中非常活跃这一事实启发。Transformer是否也能彻底改变强化学习的世界?在这个问题上,我们介绍了有可能做到这一点的研究。
以前曾有过将有希望的变压器应用于强化学习的尝试。与他们不同的是,这项工作提出了一个决策转化器,它将状态、行动和奖励的同步概率分布视为自回归模型,改变了强化学习的处理方式。决策转化器旨在将先验学习与微调相结合。在离线RL问题设置中,它取得了与现有的无模型SOTA方法相当的精度。
在本节中,我们将使用玩具数据,以直观的方式说明决策转化器。
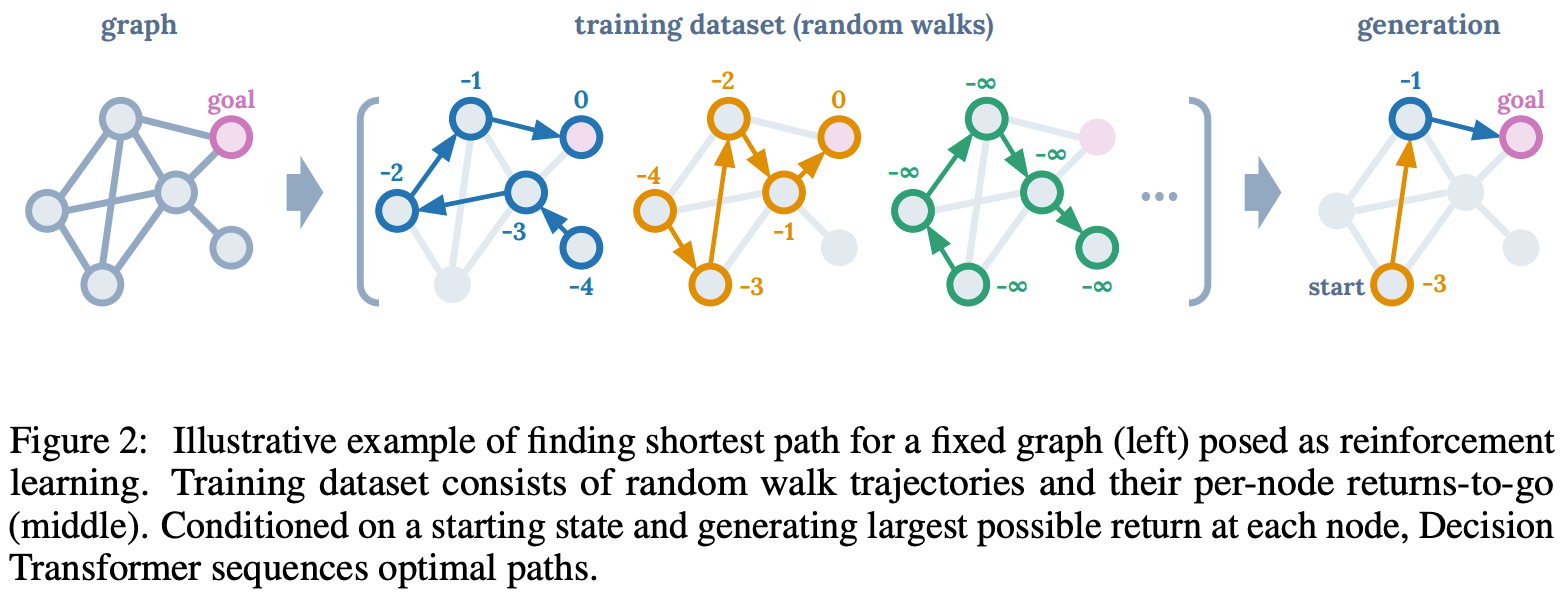
考虑在图2(左)所示的有效图中寻找最短路径的任务。作为一个强化学习问题,如果代理到达目标节点,我们给予的奖励是0,否则是-1。使用 "回归 "的概念,我们会有一个像图2(中间)那样的数据集,其中有随机措施。例如,一个带有-2的节点意味着在轨迹数据中经过两步就能到达目标节点。现在我们已经训练了一个自回归模型,在一系列以状态、行动和未来收益为标记的数据上,使用语言生成模型GPT预测下一个标记。在评估时,模型被要求根据当前状态、目标奖励和过去的信息来预测下一个节点(行动)。因此,我们能够从训练数据集中预测与状态和目标奖励对相关的令牌的行动。我们还可以在图2(右)中看到,有可能学习到比简单模仿训练数据更好的策略。
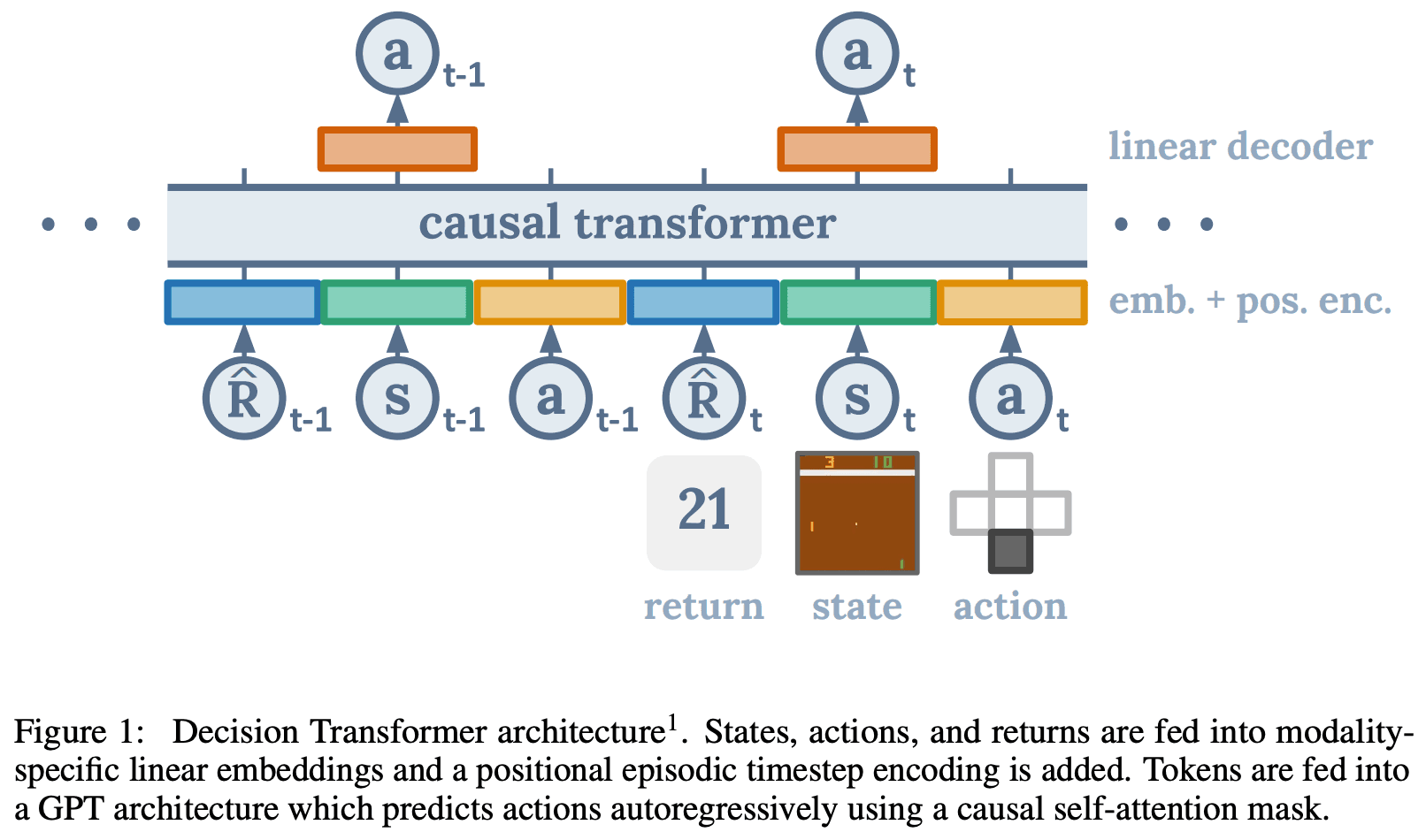
建议的方法:决策变压器
所提出的方法的结构相当简单。我们考虑了一个设定,其中给定了以下轨迹序列数据。我们把时间t的状态和行动以及返回-去的情况视为代币,并把K代币输入到GPT的因果转化器。通过将状态S与卷积层(CNN)相连接,以及将返回去和行动与线性层相连接,就可以得到令牌。
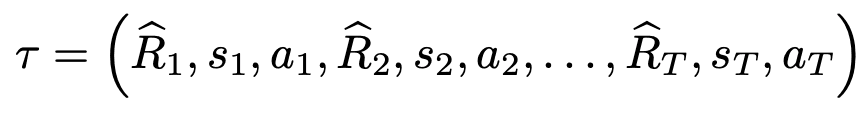
归去来兮: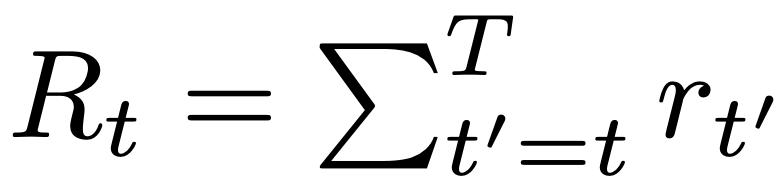
在训练过程中,我们首先从离线数据集中抽出一个序列长度=K的小型批次。然后,从时间t之前的信息中获得的标记被输入到GPT中提出的因果转化器,该转化器被训练为预测下一个行动的自回归模型。换句话说,时间t的状态、该时间之后获得的返回-去向以及过去的信息被输入,以预测时间t的行为,而预测的行为被用来预测下一个时间。
最后,对离散行为使用交叉熵损失函数,对连续行为使用均方误差损失函数进行训练。
 然而,在评估过程中,上下文长度K和目标收入是作为超参数给出的。具体流程见算法1。
然而,在评估过程中,上下文长度K和目标收入是作为超参数给出的。具体流程见算法1。

离线RL基准测试实验和评价
对于比较方法,我们选择了一种专门用于离线RL和行为克隆的算法。由于所提出的决策转换器是一种无模型的方法,我们将其与无模型的SOTA模型Conservative Q-Learning(CQL)、BEAR和BRAC进行比较。
实验任务是Atari和OpenAI Gym,前者有一个离散的行动空间,有高维的图像观察和长期的信用分配,后者需要细粒度的连续控制。
图3显示,在两次实验中,决策变压器的准确性与现有的SOTA方法相当,证明了所提方法的有效性。

雅达利
我们使用由DQN策略获得的500万条轨迹的数据集的1%进行训练。我们还引入了专业玩家的评分,即100分,随机策略为0分。
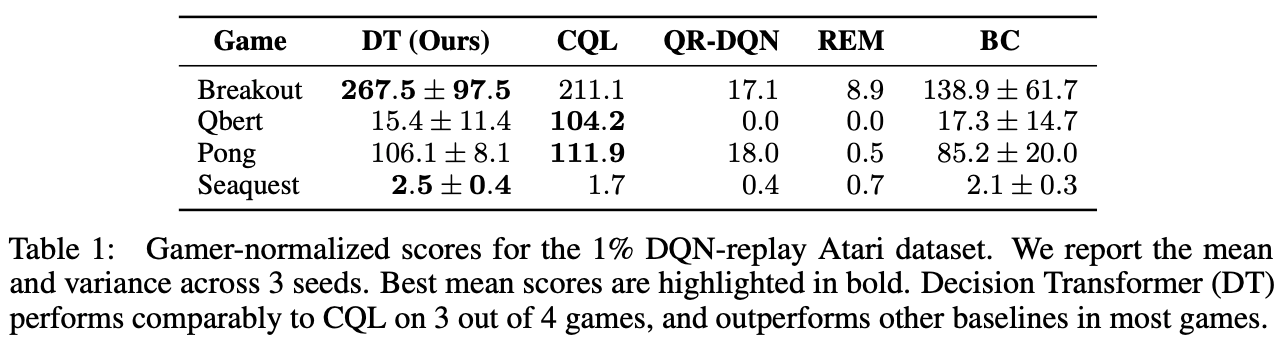
我们对四个Atari任务(Breakout、Qbert、Pong和Seaquest)进行了评估实验(表1),发现其中三个任务的准确性与SOTA的CQL相当,在所有任务中都优于其他方法。
开放式人工智能体育馆
在这次会议上,我们对D4RL基准和二维伸手环境进行了实验,与其他任务不同的是,二维伸手任务是一个目标导向的任务,奖励是不连续的。我们使用了下面描述的三个数据集。
1.中等:由 "中等水平 "措施收集的100万个时间段的数据集,就得分而言,使用SAC达到专家水平的1/3。
2.中度重放:在达到SAC中的 "中度水平 "之前存储在缓冲区中的所有数据集。
3.中级-专家:由 "中级 "和 "专家级 "措施分别收集的100万个时间步骤的数据集
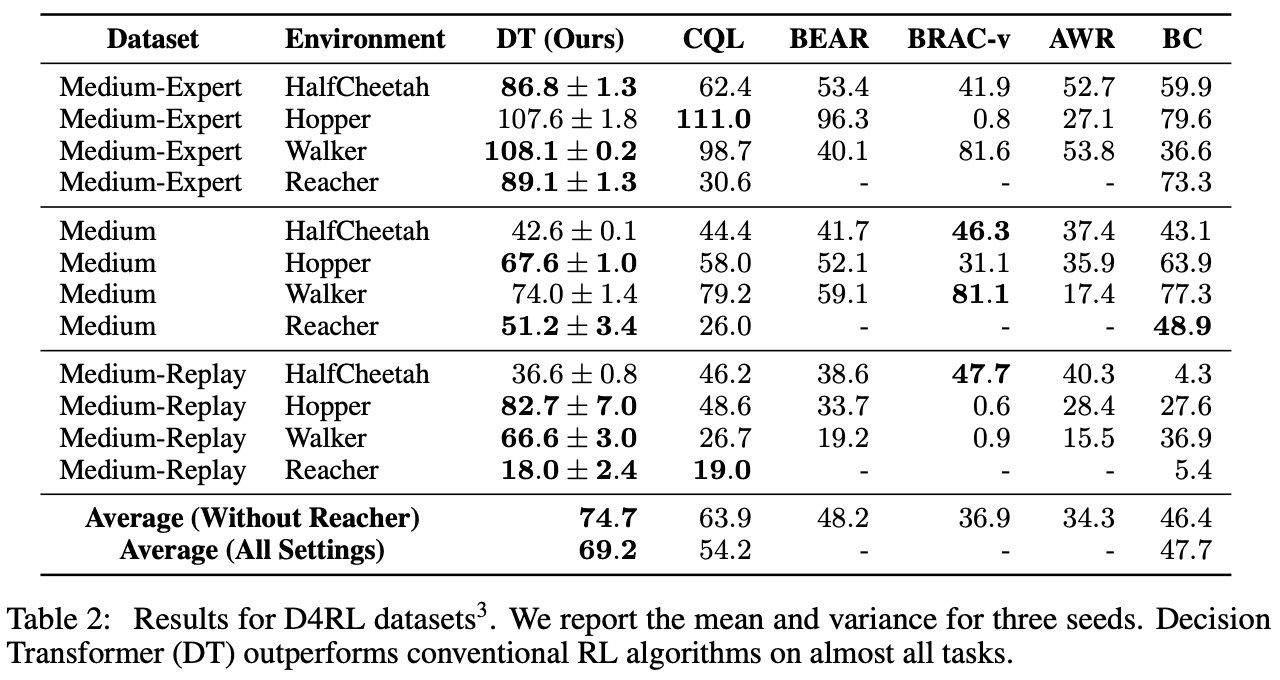
如表2所示,将无模型SOTA模型CQL与最近提出的所有有前途的方法进行比较,我们可以看到,所提出的方法DT在大多数任务中都更准确。
OpenAI体育馆能够比Atari更清楚地证明所提出的方法的有效性。
考虑因素
本文在一些实验中研究了决策变压器的特性。如果你想知道更多,请阅读该文件。
这里我们从两个角度进行讨论:分析所提出的决策转换器的特性,如它与模仿学习有什么不同,目标收入和上下文长度K如何影响结果,以及分析这些特性给长序列任务带来的优势。
1.在对某些数据集获得特定收益的情况下,决策转化器与模仿学习有什么不同?
数据集按每集收入的顺序排列,并使用百分位数行为克隆(%BC),只用数据的前X%进行模仿训练,以分析所提出的方法与BC有什么不同。结果表明,决策变压器与10%BC一样准确。这表明,学习好策略的信息集中在数据集的前10%。
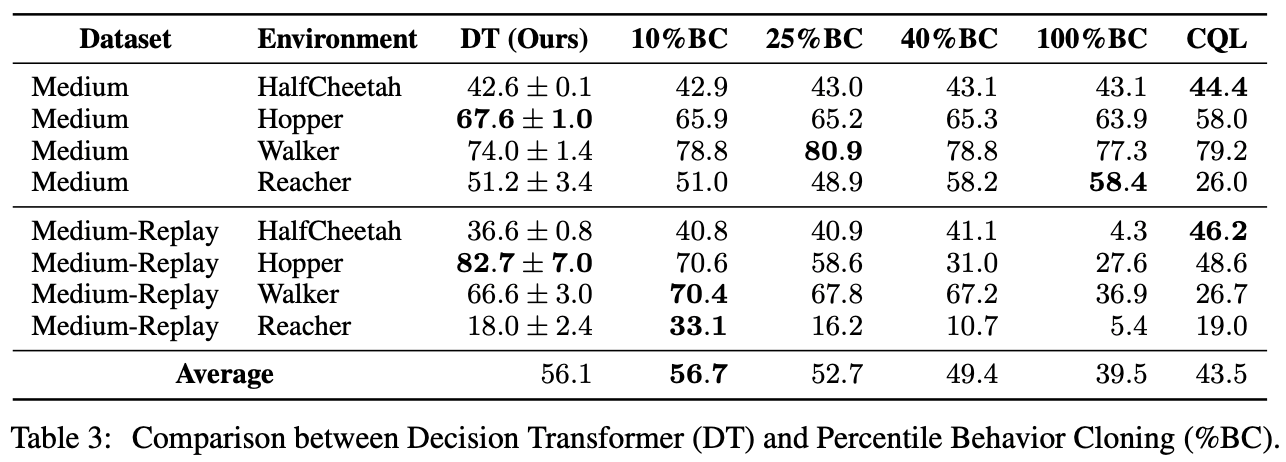
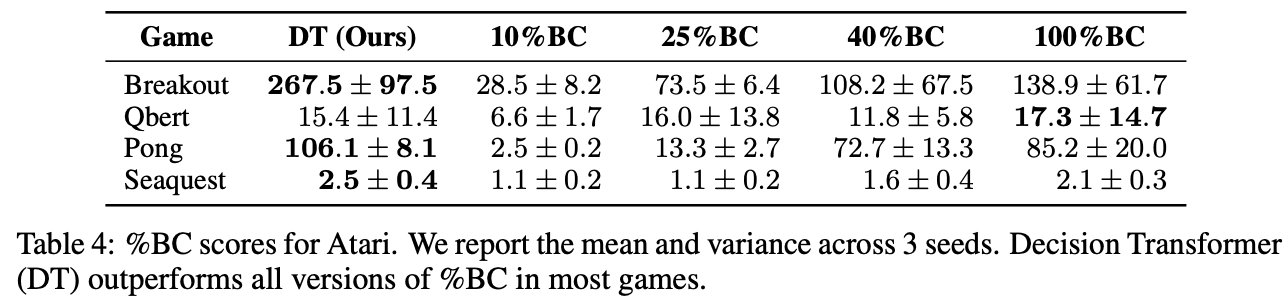
另一方面,在与雅达利公司的实验中,只使用了重放缓冲区中1%的数据,我们发现%BC的准确度较低,而决策转化器则更好。因此,可以推断出,在使用少量数据时,决策转化器可以有效地选择最佳数据进行模仿学习。
2.决策转化器根据目标收入和状态预测行为,但目标收入如何影响结果?
我们进行了一项实验,以评估决策转化器是否通过调整客观奖励设置来理解后续收益的影响。
如图4所示,对于大多数任务,给出的目标收入与获得的实际收入是相关的,表明决策转换器可以根据目标收入选择适当的行动。
此外,在雅达利公司的Seaquest任务中,收入高于数据集中最高收入的事实意味着决策转化器具有探索能力。
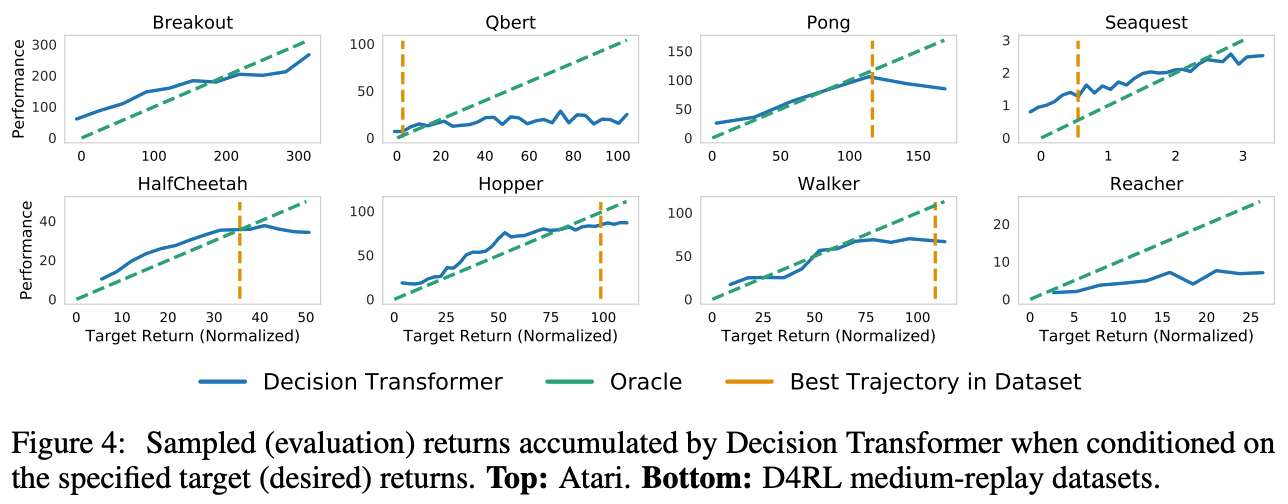
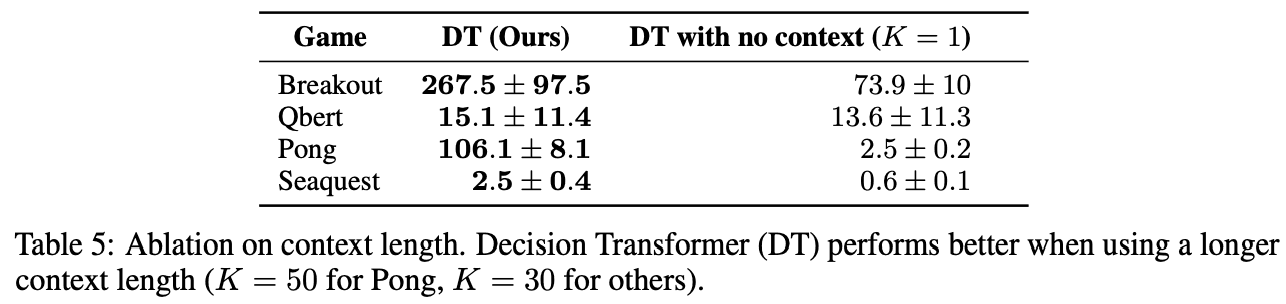
3.决策转换器的上下文长度K如何影响结果?
在使用帧跟踪的一般强化学习中,人们认为一个先前状态(K=1)就足够了。然而,在决策转化器中,实验显示了获得过去信息的重要性,可以推断,过去的信息对雅达利游戏是有用的。
4.决策转化器能否成功处理长期的信用分配问题和稀疏的报酬设置?
如何处理具有长序列的问题设置一直是强化学习的一个主要挑战。在这里,我们考虑一个基于网格的 "钥匙到门 "环境,代理人在一个有钥匙的房间里采取行动,然后通过一个空房间进入一个有门的房间。如果代理人在第一个房间没有得到钥匙,就不能打开最后一根头发的门,任务就会失败。为了评估在很长一段时间内随时间分配信用的能力,我们有一个空房间。
在这个实验中,我们在一个通过随机移动措施收集的数据集上训练了决策转化器。情境的长度被设定为剧集的长度(K=剧集长度)。可以看出,只有%BC和决策转化器,只模仿成功的数据,能够有效地学习措施。另一方面,TD学习(CQL)不能在长的时间步骤中传播Q值,因此产生低的准确性。

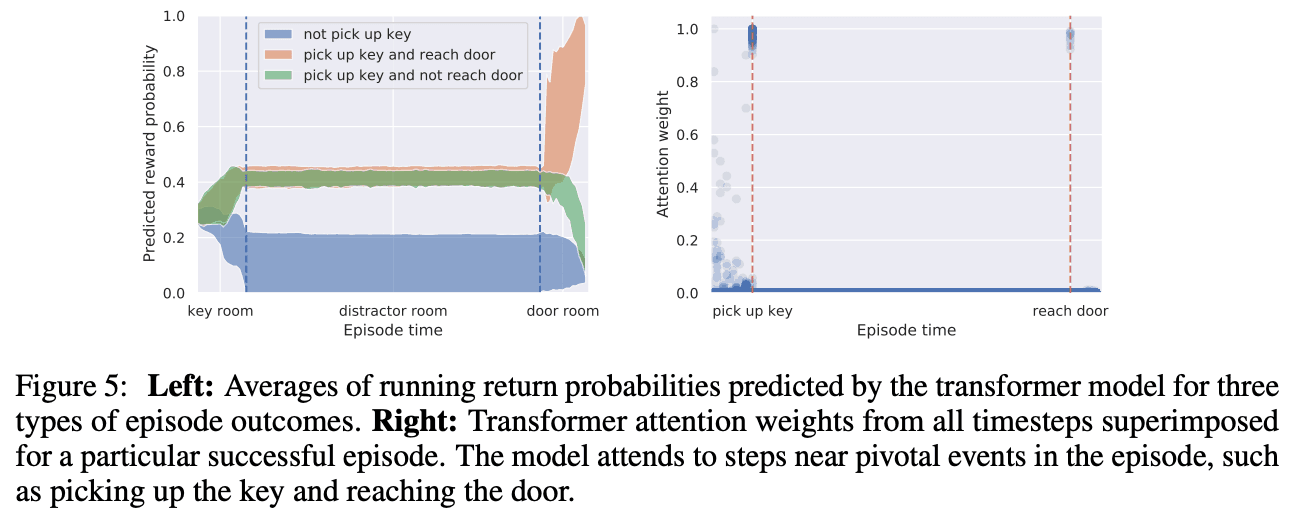
在这里,我们修改了决策转化器,使其在预测奖励的同时预测动作,以评估其是否能准确捕捉状态,并要求参与者从一开始就预测奖励,而不给予奖励。图5(左)显示,当房间发生变化时,决策变换器会更新预测的奖励。我们还可以看到,当拿起钥匙和打开门时,"注意 "的重量会被激发,这表明该机制工作正常。
摘要
在这篇文章中,我们介绍了Decision Transformer,它的动机是使语言序列模型适应强化学习的想法。决策转化器不以任何方式改变语言模型的结构,在标准离线RL基准上的表现与无模型SOTA方法一样好。
虽然这是一个简单的方法,但我们认为Decision Transformer最重要的贡献是,它表明强化学习可以从自然语言处理的技术进步中获益。特别是,决策转化器的架构自然适合离线RL,其目的是将大规模预学习和微调结合起来,我们希望这项研究将导致强化学习的重大创新。



与本文相关的类别






