ATC:将无监督学习与强化学习分开!
三个要点
✔️ 一种可以与RL代理学习解耦的表征学习方法的建议。
✔️ 提出了一个新的无监督学习任务Augmented Temporal Contrast。
✔️ 使用ATC预先培训的编码器实现高性能,以完成各种任务。
Decoupling Representation Learning from Reinforcement Learning
written by Adam Stooke, Kimin Lee, Pieter Abbeel, Michael Laskin
(Submitted on 9 Mar 2020)
Comments: Accepted at arXiv
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
Paper Official Code COMM Code
介绍:
本文讲述的是Decoupling Representation Learning From Reinforcement Learning,在传统的、基于端到端的、基于像素的RL(输入是图像)中,用RL训练Encoder的回报而不是学习驱动的特征,他们提出了一篇论文,表明使用无监督学习(unsupervised learning)来解耦Encoders与强化学习的预训练Encoders的性能与传统方法一样好或更好。以前的一些论文除了在RL中使用原始损失函数外,还使用了无监督任务,如学习特征。通过引入辅助损耗,他们通过引入辅助损耗让它学习,提高了性能。此外,最近计算机视觉界的论文表明,使用无监督和自监督学习可以有效地进行分类,例如,在对ImageNet进行分类。因此,如果有一种不使用奖励的学习特征的方法,RL在提高性能方面也会非常灵活。所以,在本文中,他们使用了一种卷积编码器,称为增强时间对比(ATC),通过将某一时间的图像与稍远时间的图像配对,具有图像增强和对比度损失的功能他们提出了一个新的无监督学习任务,该任务是由在这将详细介绍新的无监督学习方法及其结果。
技巧
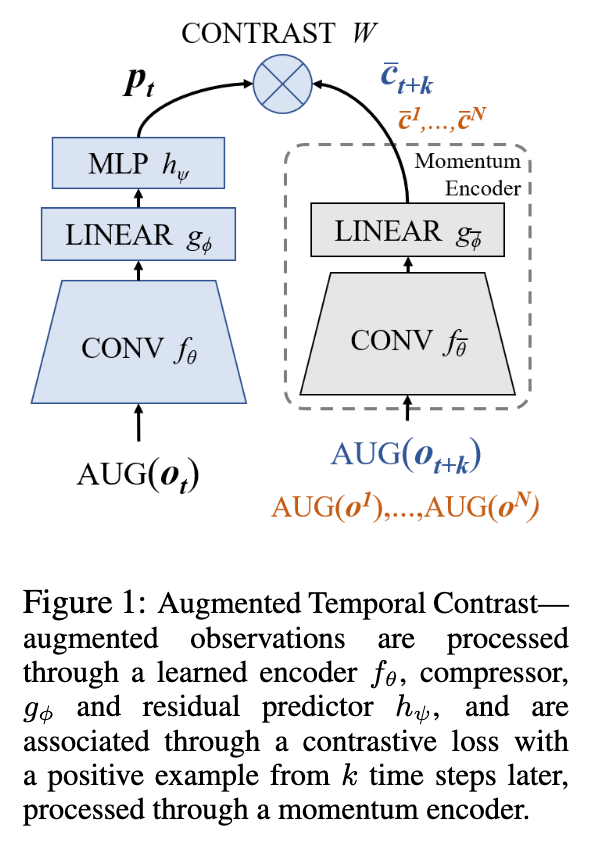
在本章中,我们将介绍新提出的增强时间对比(Augmented Temporal Contrast,ATC),其结构如下图所示,输入一对观测值$o_{t}$和一对近期的观测值$o_{t+k}$。然后,对每个训练批次的观测值应用随机数据增强。对每个训练批次的观测值应用随机数据增强。本文采用的是随机移位,非常简单,容易实现。然后由编码器将增强后的观测值移入一个小的潜伏空间,并使用对比损失来计算特征的损失。这个任务的目标是让编码器从观测值中提取关于MDP结构的有意义信息。
这个ATC可以分为四个部分,如下图所示:第一个是卷积编码器$f_{\theta}$,以观测值$o_{t}$为输入,潜伏特征$z_{t} = f_{\theta}(\text{AUG}(o_{t}))$.第二种输出一个小的潜码向量,称为线性全局压缩器$g_{\phi}$,这是一个小的潜码向量;第三种输出一个残差预测器MLP $h_{\psi}$,它表示一个正向模型,执行$p_{t} = h_{\psi}(c_{t})+c_{t}$这样的操作。最后,对比变换矩阵$W$。$o_{t+k}$ 是 $\bar{c}_{t+k}=g_{\bar{\phi}}\left(f_{\bar{\theta}}\left(\operatorname{AUG}\left(o_{t+k}\right)\right)\right.$.然后用目标代码表示。处理这一观测结果的参数$o_{t+k}$,$\bar{\theta}$和$\bar{\psi}$,称为动量编码器,它是所学参数$\theta$和$\psi$的移动平均。它的计算方法是
而在使用这个任务来预训练编码器后,RL代理中只使用$f_{\theta}$。这个任务的损失函数可以用InfoNCE表示如下所示。
$$\mathcal{L}^{A T C}=-\mathbb{E}_{\mathcal{O}}\left[\log \frac{\exp l_{i, i+}}{\sum_{o_{j} \in \mathcal{O}} \exp l_{i, j+}}\right]$$
其中$l$表示为$l=p_{t} W \bar{c}_{t+k}$。
实验
用于评价的环境和算法
在本文中,他们在三种不同的环境中评估了ATC:DeepMind控制套件(DMControl)、Atari游戏和DeepMind实验室,其中Atari使用了离散控制(离散动作如右、左等)。在游戏中,DMLControl是一款采用连续控制的游戏。而DMLab,DMLab是RL Agent在视觉复杂的3D迷宫环境中行动的任务。
对于算法,他们使用并评估了政策上和政策外RL算法的ATC,对于DMMontrol,他们使用了名为RAD-SAC的随机移位增强,用于软行为者使用了基于批评的算法;对于Atari和DMLab,他们使用PPO来评估它。
在线RL和无监督学习
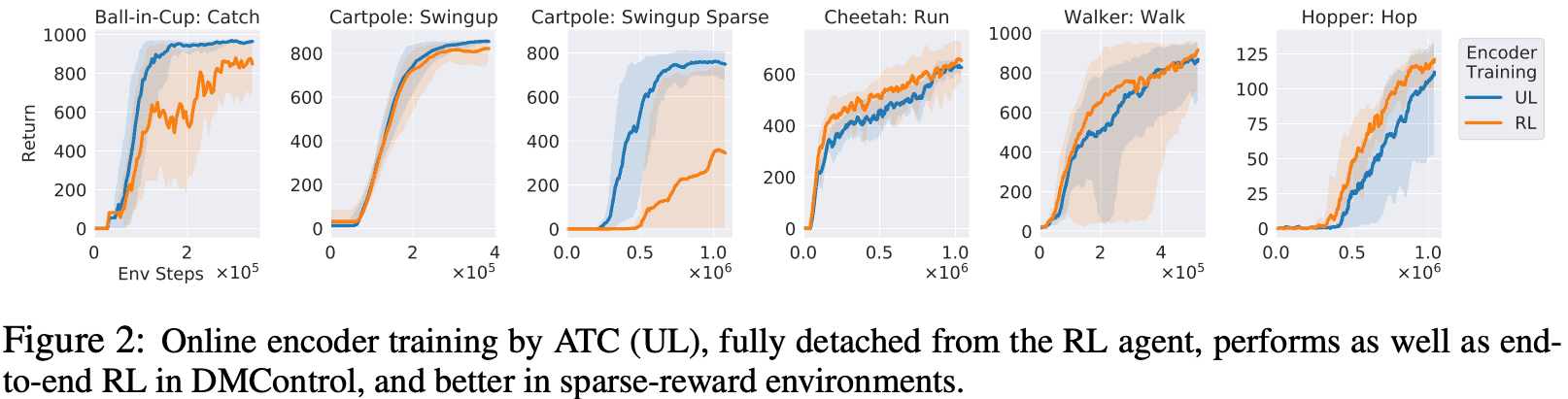
DMControl。在整个实验过程中,如果编码器与RL代理分离,编码器在线学习ATC任务,同时RL代理接收编码器的介绍并学习,则端到端的RL情况(以下结果表明,其性能等于或优于传统方法(即不使用ATC的学习)。
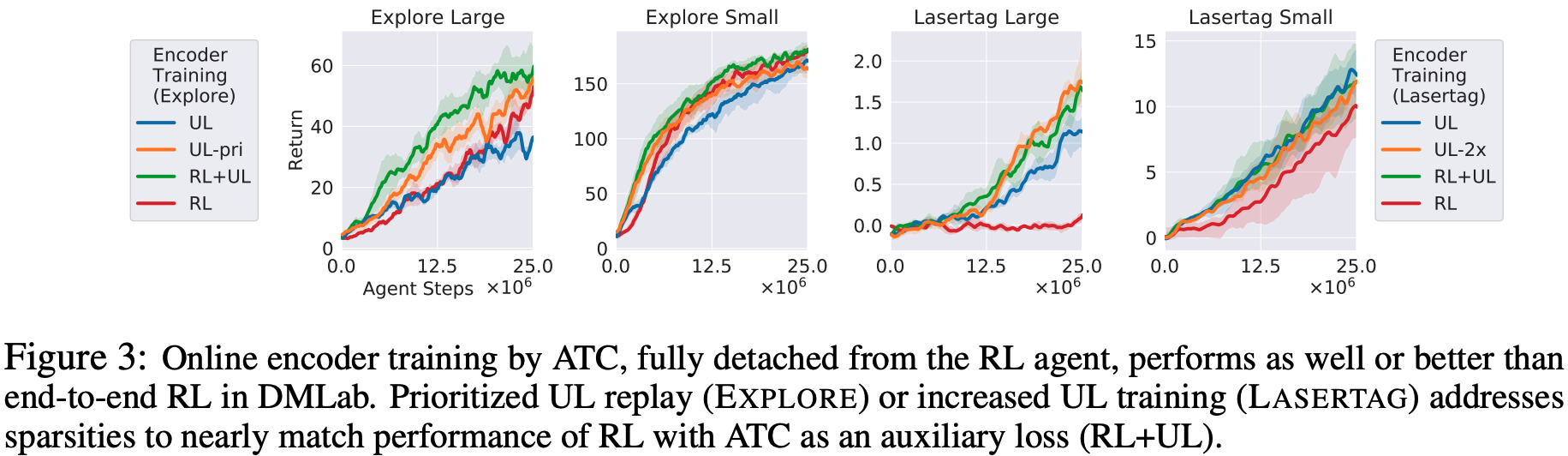
DMLab: 在DMLab的实验中,他们使用了两个任务:EXPLORE_GOAL_LOCATIONS,即在迷宫中移动寻找目标;LASERTAG_THREE_OPPONENTS,即快速追逐敌人并标记它们。他们用两个不同程度的任务进行实验,共四个任务:在EXPLORE的任务中,目标被发现的频率较低,学习的进度也较低,所以$p \propto 1+R_{abs}$(其中$R_{a b s}=\sum_{t=0}^{n} \gamma^{t} \mid r_{t}$)的值进行优先级排序的方法,并通过抽样进行训练,将优先级较高的值进行优先级排序。如果把这种方法指定为优先级-UL(下图橙线),它的性能和传统RL(下图红线)一样好,甚至更好,它是一个辅助任务,Unsupervised与使用Learning相比,准确率差不多,即把编码器与RL代理分开,不对其进行训练(绿线)。
另外对于LASERTAG来说,学习代理可以很好地看到敌人,但对敌人进行标记是很难发生的事件。在传统RL(下图右边红线)的情况下,性能非常差,特别是对于大型迷宫,采用ATC来分离代理和RL代理。我们还发现,通过加倍更新编码器的频率,与不将编码器与RL代理分离的训练相比,性能相似。
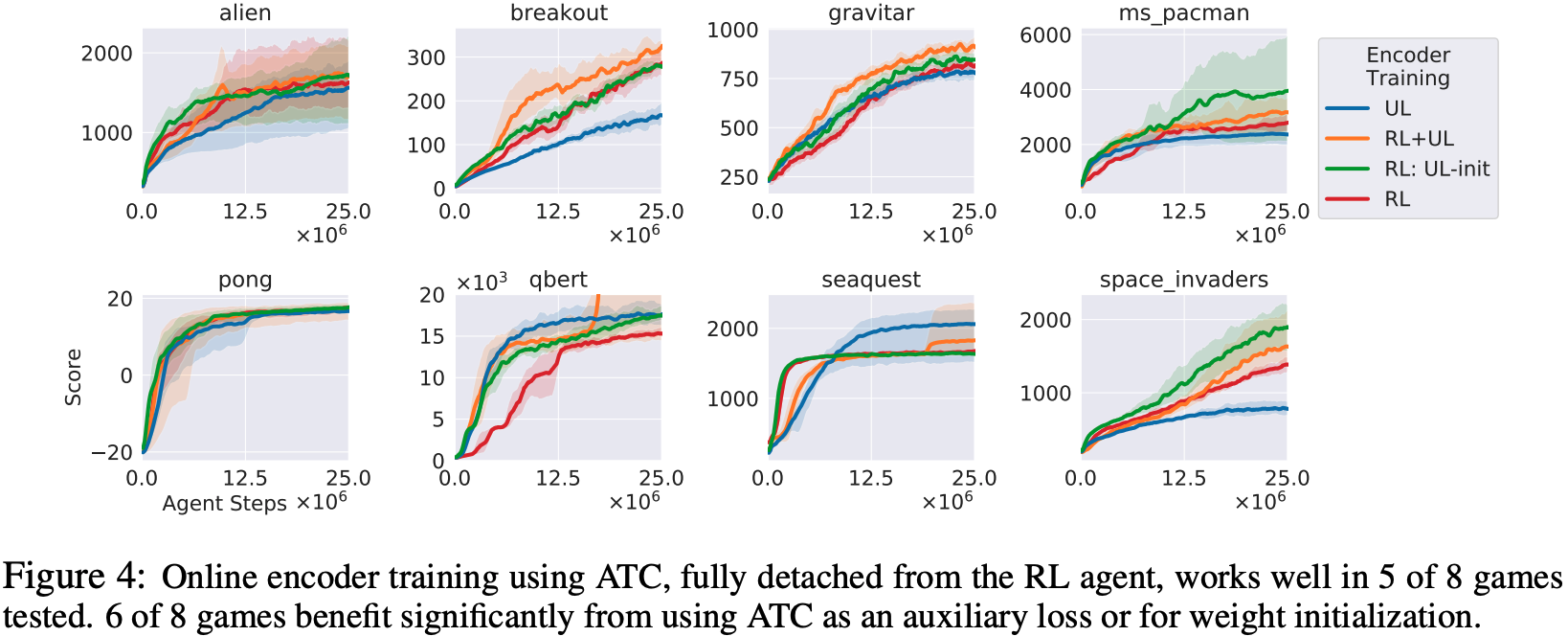
Atari: 在对Atari的实验中,评估了8款游戏,发现当Encoder与RL Agent解耦并使用ATC任务进行训练时,其中有5款游戏的表现优于端到端RL。不过,《BREAKOUT》和《SPACE INVADERS》的表现却不如RL代理。然而,当ATC作为辅助任务进行训练而不将其与RL代理分离时,这些任务和其他任务的性能更好。此外,当ATC用于训练前10万次转换的编码器并初始化权重时,结果表明ATC在一些游戏中是有效的。
编码器前期培训的基准
在本文中,他们提出了一种新的评价方法,作为针对RL的不同无监督学习算法的评价。该评价按以下程序进行。
- 收集每个环境的专家示范
- 利用从CNN编码器收集到的数据,采用无监督学习进行预训练。
- 用固定权重的编码器训练RL代理,并评估其性能。
以下是各环境的结果。
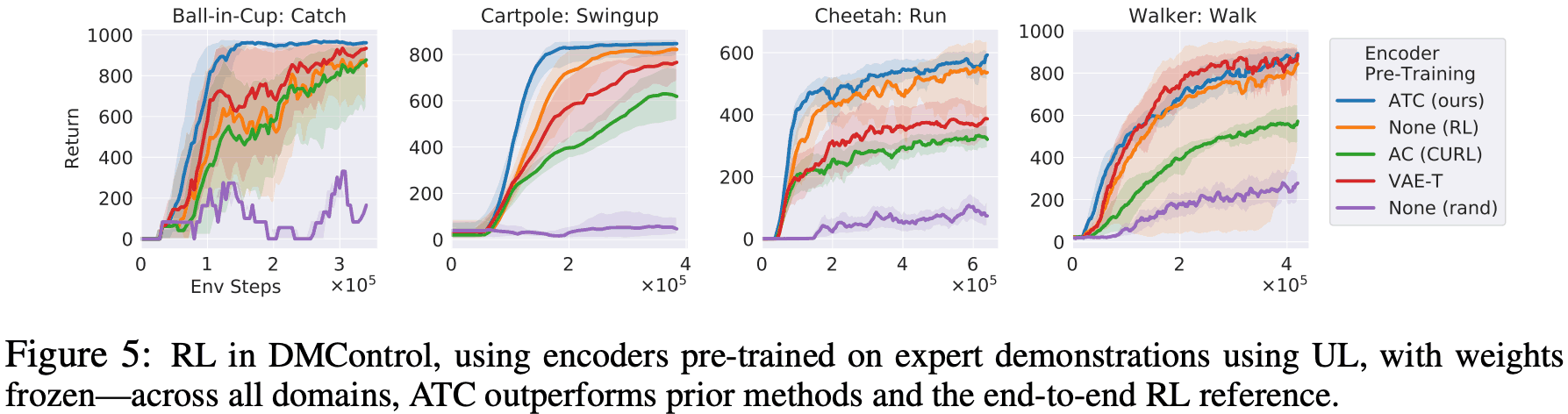
DMControl。 在本实验中,他们使用了CURL中主要使用的增强对比(Augmented Contrast,AC),VAE作为一种无监督的学习算法,与ATC相比。如下图所示,ATC的性能与其他无监督算法基本相同或更好。另外,与端到端RL相比,ATC在所有任务中都表现出同等或更好的性能。
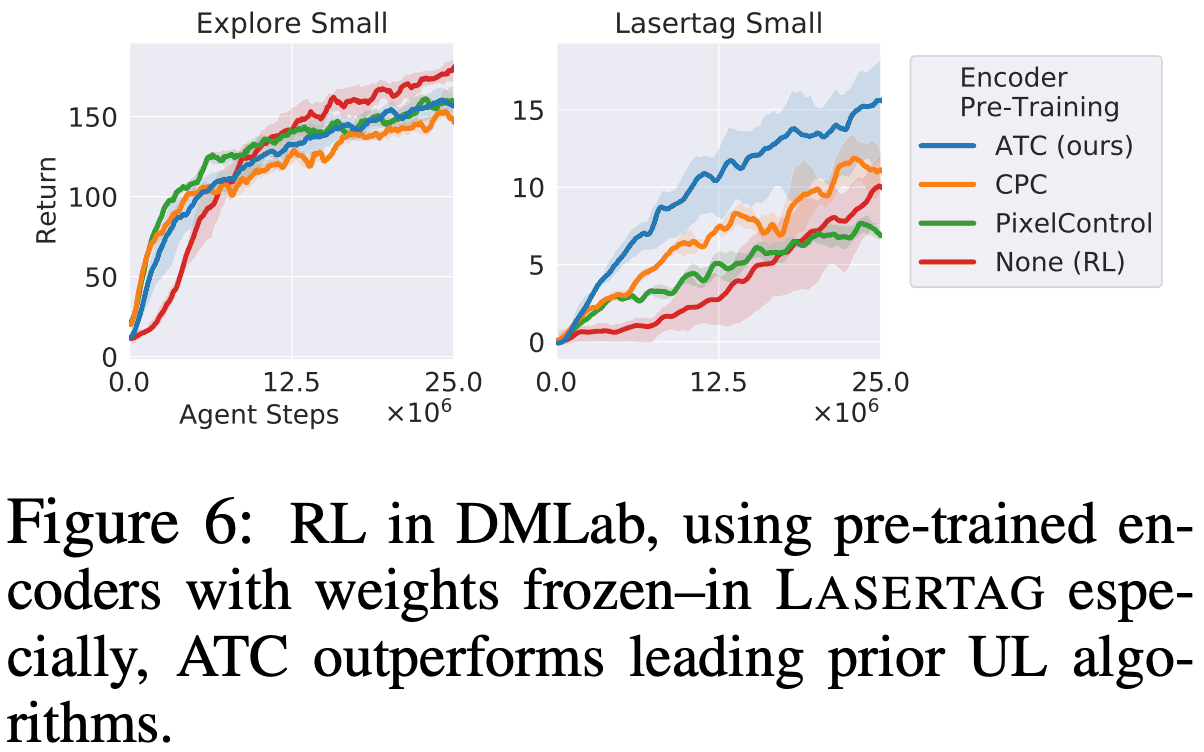
DMLab: 下图是DMLab的结果。对于EXPLORE任务,所有任务的表现都差不多,但对于Lasertag来说,ATC那个是最好的。从下图可以看出结果。
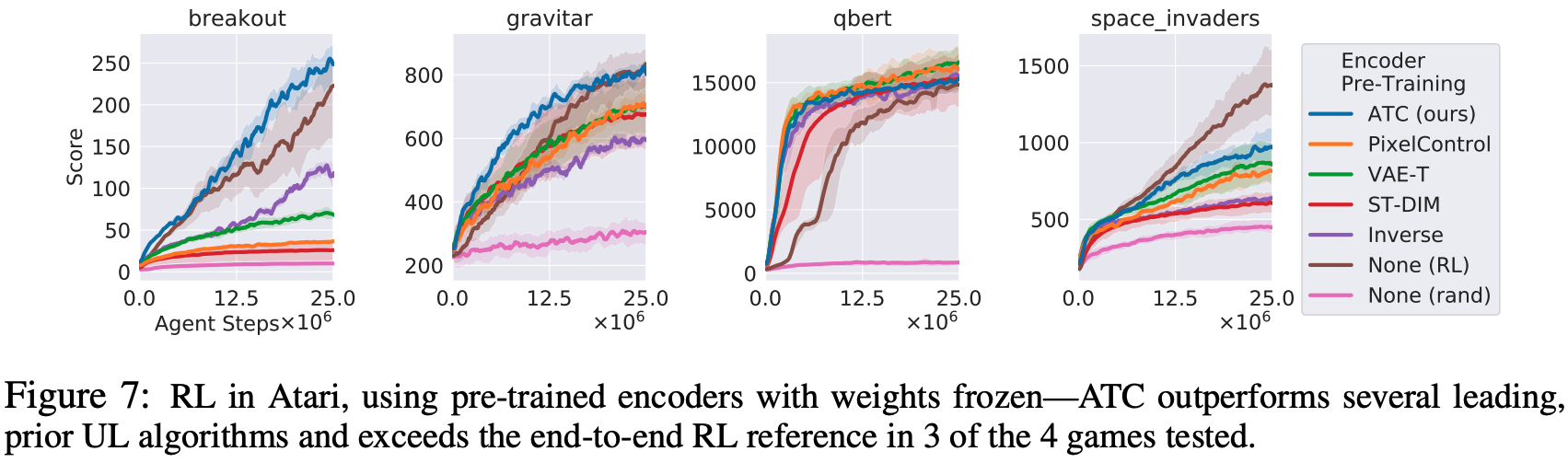
雅达利: 对于雅达利来说,在四款游戏中,ATC是由Pixel Control、VAE-T和Inverse模型(给定两个连续的观察值,预测过渡到对的动作)来训练的。模型),并与一种名为时空深度信息模型(ST-DIM)的方法进行比较。结果显示,在三场比赛中,只有ATC代表的性能高于端到端RL,如下图所示。
多任务编码器
本实验旨在评估ATC是否可以训练多任务编码器,通过在多个环境下使用专家演示预先训练编码器,并固定编码器的权重,然后使用RL它对代理进行另一项任务的训练,并评估其性能。
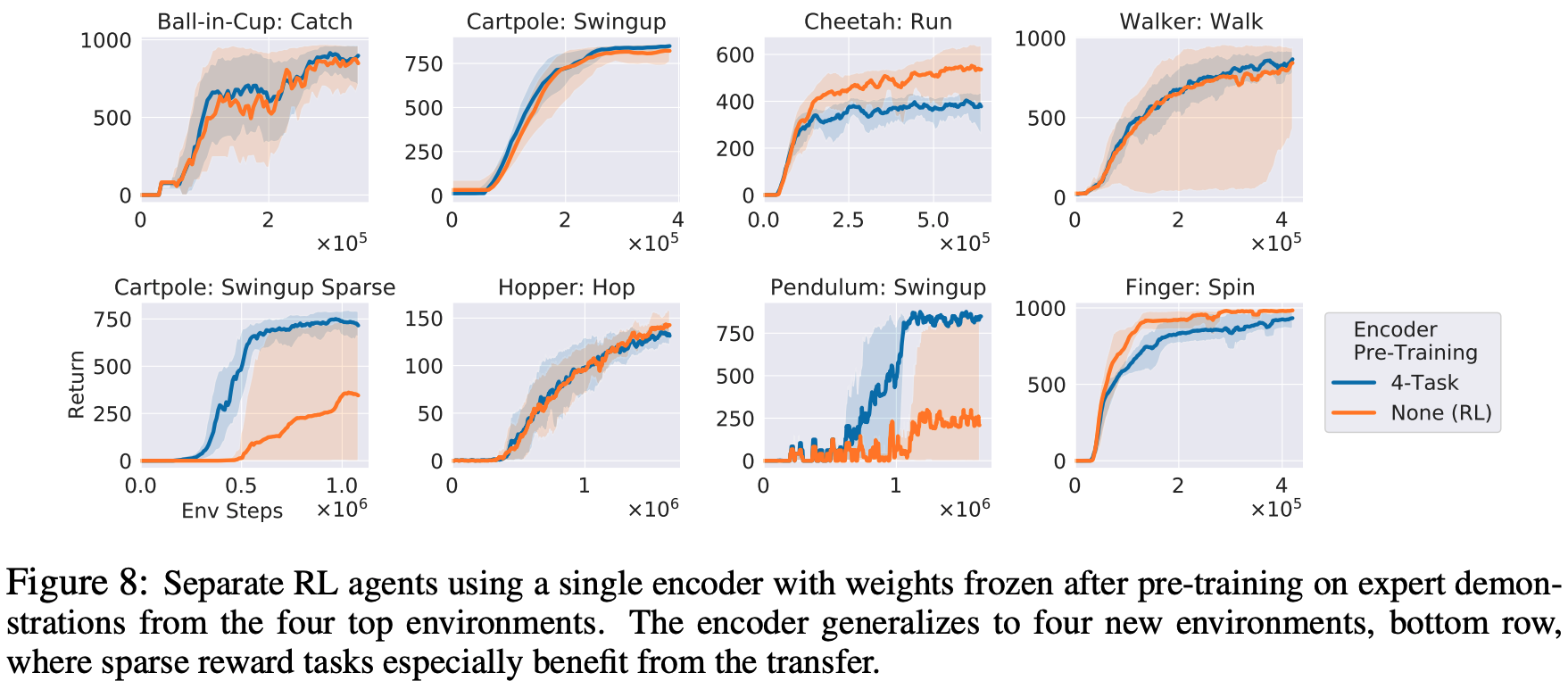
DMControl: 在这个实验中,编码器通过演示球中杯:Catch,Cartpole:Swingup,Cheetah:Run,Walker:Walk任务在下面的顶行进行预训练。下图为图中最下面一行各任务训练一个RL代理的结果,训练的编码器权重固定。最下面一行的结果显示,与没有进行预训练的RL相比,通过使用不同的任务和使用学习到的编码器进行预训练,RL代理的学习效率更高,如下图所示。
Encoder的消融研究和分析
关于Random Shift。 实验表明,随机移位图像激动基本对所有环境都有效。在DMRControl实验中,他们发现,在固定编码器后训练RL代理的过程中使用随机移位可以提高性能,而不是只在训练编码器时使用随机移位。这表明,增强不仅约束了编码器输出的表示,还约束了它的策略:在训练RL代理的过程中,编码器不是将图像存储在重放缓冲区中,而是将其如果我们能通过重放缓冲区存储50维的潜像向量,并将其用于训练,会更快、更高效。然而,对这种潜伏图像使用尽可能小的随机移位已经无效,因为移位太大。在本文中,他们提出了一种新的数据增强方法,称为子像素随机移位,它是基于相邻像素之间的线性插值。
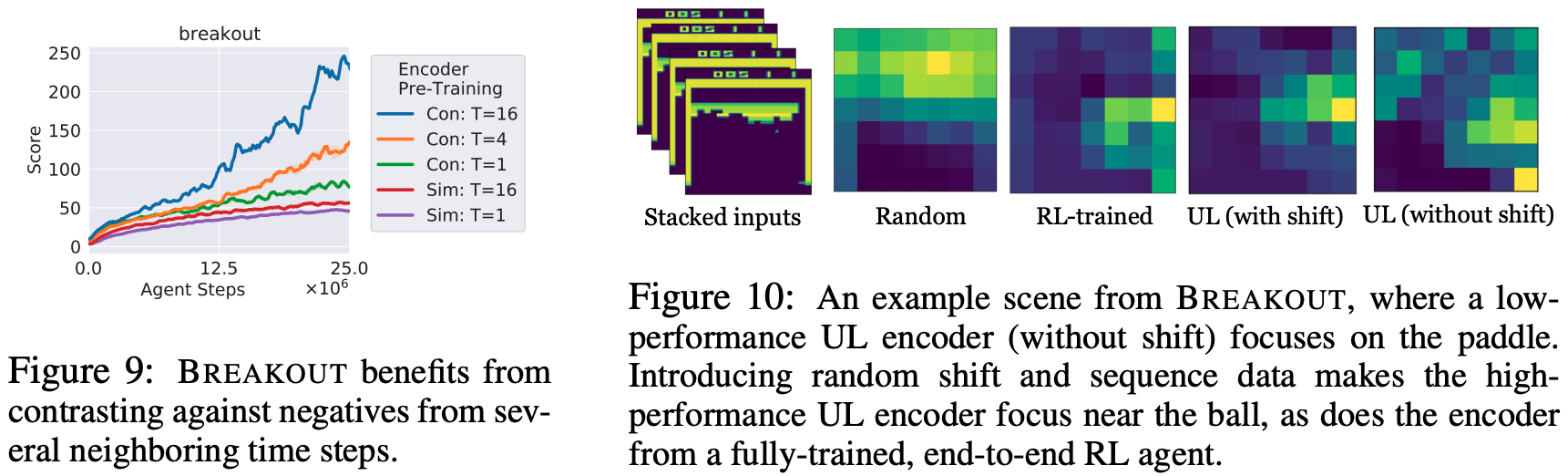
相邻转折的运用分析。 雅达利仅就突围任务而言,我们发现,使用一段轨迹来创建和学习匹配,而不是基于单个转场来创建匹配,是更为有效的。下图显示了使用对比性损失和相似性损失的情况,其中$T$代表负样本的时间步长。从下图可以看出,在$T=16$的情况下,性能最好。然而,对于其他任务,他们发现即使在使用单个转场时,它也表现良好。
训练有素的编码器: 下图右侧显示的是无监督学习中带随机移位和不带随机移位的RL之间的比较。从这些结果可以看出,有RL agnet和随机移位的无监督学习主要集中在球的附近,而没有随机移位的无监督学习主要集中在球拍上。你可以看到,他们正在关注它。
摘要
在本文中,他们引入了一个名为ATC的无监督学习任务,即使编码器与RL代理解耦并进行预训练,它也显示出与端到端RL性能相似或改进的性能。本文提出,在各种环境下进行实验后,有必要进一步分析,因为有些环境下,虽然在某些环境下效果不错,但效果并不明显。但是,我们相信,如果能够将编码器与RL代理分离,并事先学习,将能够更灵活、更高效地学习RL代理,所以我们期待未来的研究。



与本文相关的类别






