我们能从一种未知的生态物质--miRNA预测疾病吗?使用强化学习的疾病预测模型的建议
三个要点
✔️ 旨在开发一个模拟器,以预测未知miRNA与疾病之间的关联。
✔️ 结合三个基于Q-learning算法的子模型--CMF、NRLMF和LapRLS,并对其进行优化,以获得最佳权重。
✔️ 三种疾病的案例研究确定了所有与结直肠和乳腺肿瘤相关的前50个miRNAs
RFLMDA: A Novel Reinforcement Learning-Based Computational Model for Human MicroRNA-Disease Association Prediction
written by
(Submitted on 5 Dec 2021)
Comments: Biomolecules
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
背景介绍
是否有可能预测未知miRNAs与疾病之间的关联?
在这项研究中,我们提出了一个模拟miRNAs和疾病之间关系的系统,它作为一种新的液体活检技术--一种使用血浆和尿液等微创标本的诊断技术,一直备受关注。 miRNAs是与各种疾病(包括癌症)高度相关的生物物质。然而,由于该领域的新颖性,有许多问题没有得到解答,生物实验是主要的分析方法。实施方面的挑战--规模小、人力和物力投资大等--仍然存在。因此,需要对未知的miRNAs与疾病的关系进行定向模拟,以减少实验成本。为了应对这一挑战,我们提出了一个基于强化学习Q-learning的仿真模型,并结合三个子模型--CMF、NRLMF和LapRLS--称为RFLMDA-提出了预测未知miRNAs和疾病之间的关联,并具有很高的准确性。
什么是miRNA?
首先,将对本研究的目标--miRNAs进行简要描述。
miRNAs是21-25个核苷酸(nt)长的单链RNA分子,它是参与调节真核生物中基因转录后表达的生物物质。人类基因组中被认为有1000多个miRNA编码,它们破坏目标mRNA--信使RNA--的稳定性,并通过翻译抑制蛋白质的生产。构成人体的蛋白质一般通过中心教条从DNA转化为蛋白质--转录,将DNA转化为mRNA的过程,以及翻译,将mRNA转化为蛋白质的过程。miRNA被认为是这后一过程的最重要的调节器,并与一些生物现象有关,包括疾病的发展。特别是,据报道,它在某些癌症类型和阶段有特异性表达,并与一些疾病和病毒感染的鉴定高度相关。因此,miRNAs可以作为新型生物标志物用于疾病诊断和预后,也有望用于基因治疗。
另一方面,由于miRNA是一个相对新发现的领域,有很多东西还没有被探索,而生物实验是最主要的分析方法;因此,这种分析的挑战--规模小、人力物力投入大、实验周期长、局限性大-是存在的。在此背景下,有必要开发模拟器,为miRNA和疾病之间的关联指出一定的方向,并减少生物实验的挑战和成本。
研究目标
为了应对这些挑战--并降低实验成本--我们提出了RFLMDA,这是一种使用三个模型和强化学习来模拟miRNA和疾病之间关联的方法。具体来说,我们将三个子模型--CMF、NRLMF和LapRLS结合在一起,并根据强化学习的Q-learning算法分配最佳权重S。对所提出的模型--RFLMDA--的评估结果表明,它达到了较高的预测精度:与其他方法相比,很明显RFLMDA具有更好的预测精度--AUC、AUPR-);八种疾病的模拟结果显示,与这些疾病相关的前50个miRNA中,有许多已经被得出。
方法
数据集
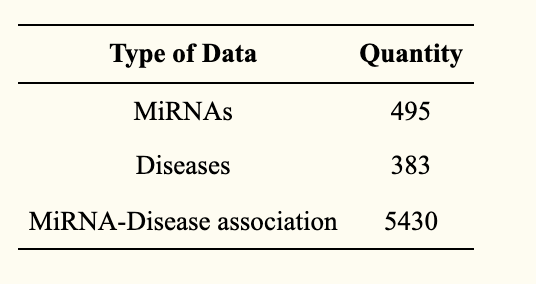
该数据集包括来自人类miRNA-疾病关联数据库-HMDD v2.0(http://www.cuilab.cn/hmdd,2021年10月15日访问)的数据。(见下表)。
还假设miRNA之间存在相互作用,这些相互作用影响生物过程。因此,我们构建了一个495行、495列的miRNA功能相似性邻接矩阵(如下)来训练这些效应:在矩阵中,矩阵的每个元素都是指两个miRNA之间的功能相似性得分。
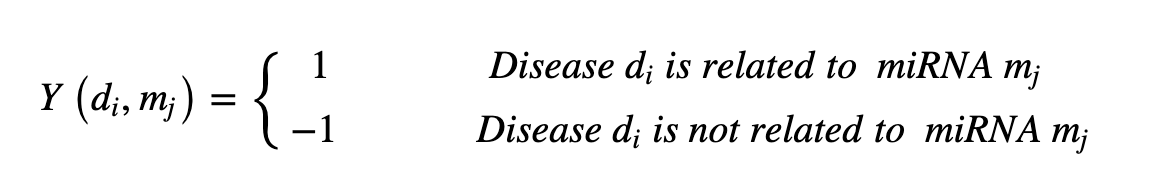
我们还为疾病定义了语义上的相似性,因为预计它们之间是相似的(见下文):每种疾病都基于一个有向无环图(DAG)--一个有向图,点代表疾病,边代表疾病之间的关系。每种疾病都是基于一个有向无环图(DAG)--其中点代表疾病,边代表疾病之间的关系。
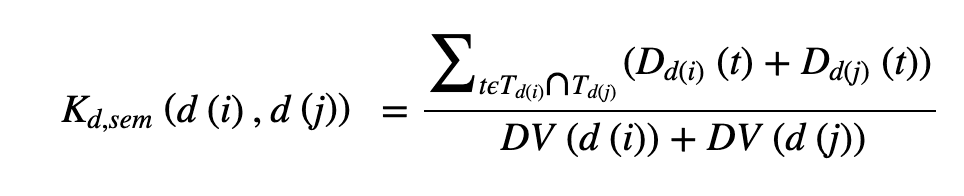
子模型
现在我们将讨论构成拟议方法基础的三个子模型--CMF、NRLMF和LapRLS。协作矩阵分解(CMF)是推荐系统背景下使用的经典模型之一--例如评级预测、冷启动推荐等:它通过最小化目标函数来工作。A:miRNA特征矩阵,B:疾病特征矩阵,F:预测的miRNA-疾病相互作用矩阵。
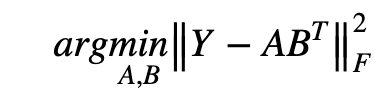
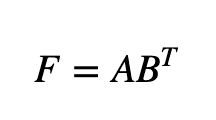
接下来,我们讨论邻域正则化逻辑矩阵分解(NRLMF)。这个模型结合了逻辑矩阵分解(LMF)方法和正则化来预测关联。为了最小化目标函数(如下),我们计算与某些变量有关的导数--下式中的U和V--并根据极端值进行优化。
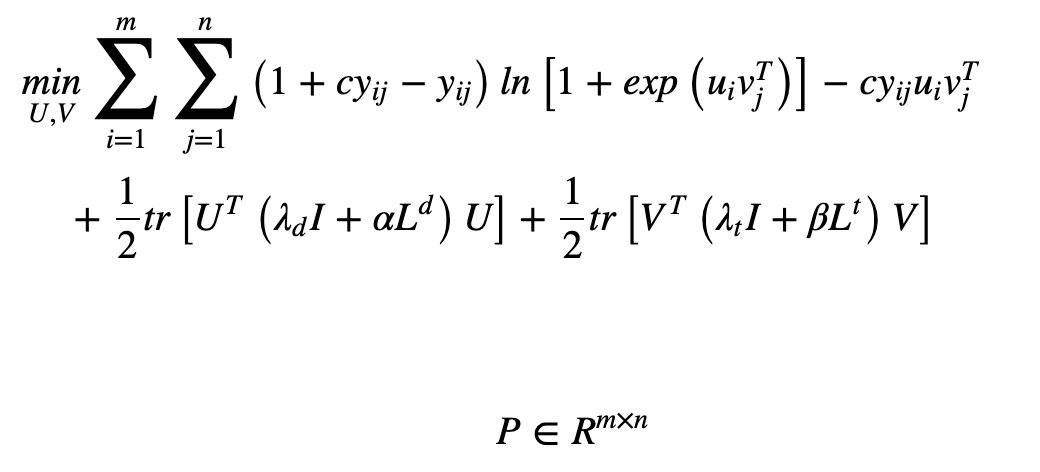
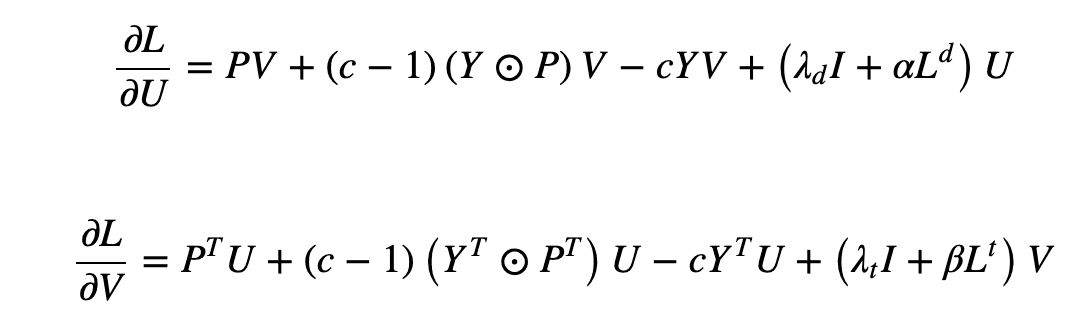
最后一个是Laplacian Regularized Least Squares(LapRLS),这是一种半监督学习方法。这个模型构建了一个近邻图,并利用了正则化--为最小二乘损失函数的系数引入拉普拉斯图(见下文)。它还有两个主要特点:模型的简单性;性能与拉普拉斯正则化支持向量机相当。
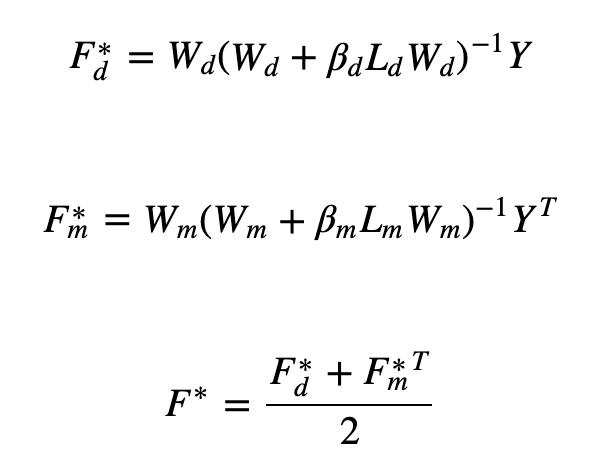
建议的模式
所提出的模型是基于Q-learning(一种强化学习算法),包括为上述三个模型--CMF、NRLMF和LapRLS分配最佳权重。强化学习基于四个主要部分:代理、奖励、环境状态和行动:代理通过执行行动来操纵环境,从一个状态转到下一个状态;在完成任务后,代理被给予积极或消极的奖励。当任务完成后,代理人会得到一个积极或消极的奖励。强化学习的特点是对行动的选择,目的是使累积奖励最大化,从而得出适合该情况的最佳解决方案。

在这种强化学习中经常使用的还有Q-leaning--一种基于马尔科夫模型的价值学习算法,用贝尔曼方程解决,以及使用时间差法的非政策学习(见下图)。
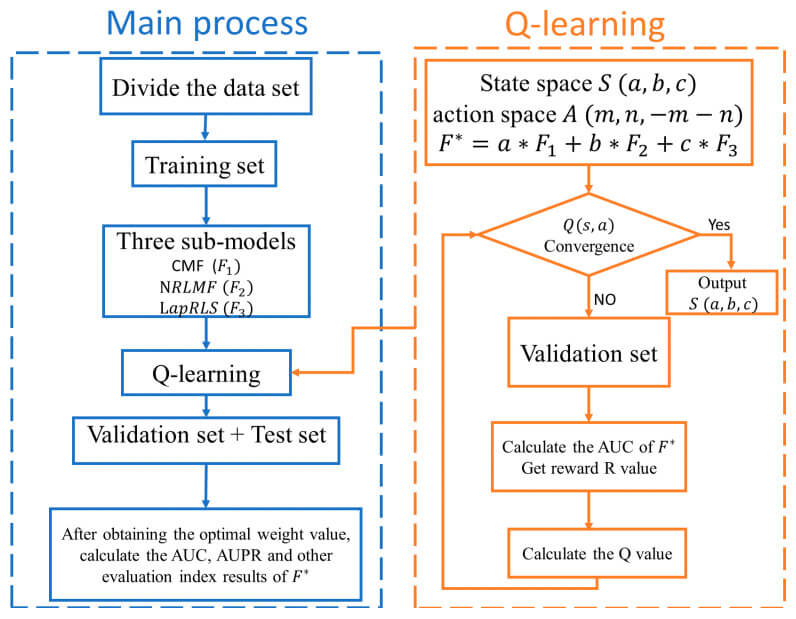
基于这种方法,提议的模型得出了最佳权重,并将其分配给每个模型:5倍交叉验证--将数据集按8:1:1的比例分为训练、验证和测试集--和最佳权重的得出和组合。
我们使用AUC的差异作为强化学习中行动选择的衡量标准--每一轮验证都会产生一个新的AUC,AUC的差异被用作奖励的衡量标准:如果下一个状态和当前状态的AUC的差异大于0,我们给予正1的奖励;否则我们给予负1的奖励。如果下一个状态和当前状态的AUC之差大于零,则给予加一的奖励;否则,给予减一的奖励。这些连续的迭代学习使奖励相继收敛,使我们更接近最优解。建议模型的具体算法如下
结果
这一评估的目的是得出所提出的模型的最佳权重和miRNA与疾病之间关联的预测准确性。
评价指标
评价指标是AUC(曲线下面积)--以ROC曲线和标线为界的平面图的面积,数值范围为0至1;AUPR(PR曲线下面积)--以PR曲线为界的面积(精度召回曲线):X轴上的召回率和Y轴上的精度所限定的区域。
与现有模型的比较
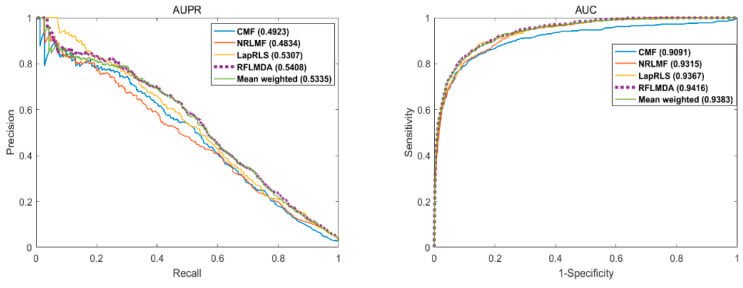
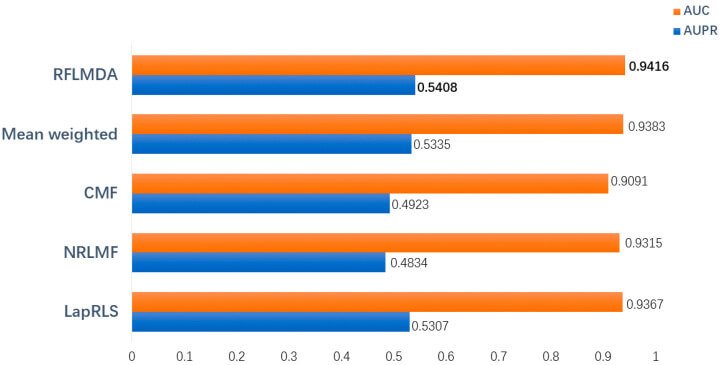
本评价的目的是得出所提出的模型RFLMDA的预测性能。具体来说,所提出的模型与其他五个模型--RFLMDA、平均加权:具有1/3权重的三个子模型、CMF、NRLMF和LapRLS--以及上述指标--AUC、AUPR和AUPR--------是衍生出来的。评估结果(见下文)表明,所提出的模型具有最佳性能。
案例研究
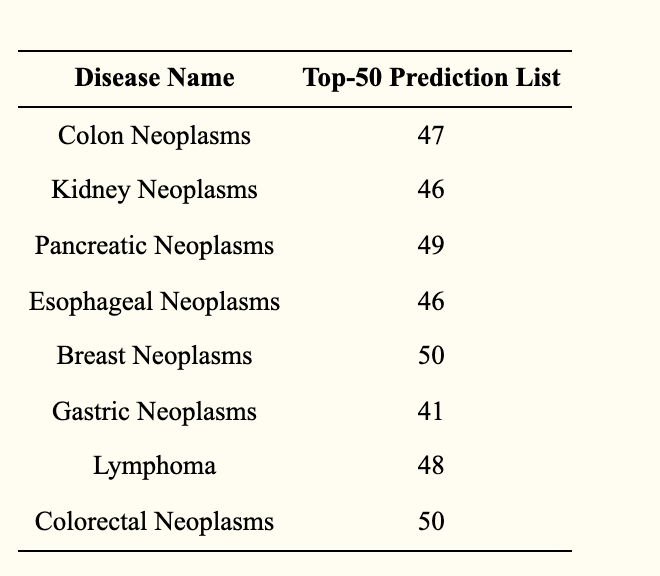
本评价利用案例研究来进一步阐明RFLMDA模型的预测性能--这种评价可以对预测性能进行更客观和有效的评估。在此,我们调查了HMDD中报告的八种疾病的miRNA和疾病之间的关联:乳腺肿瘤、胃肿瘤、结直肠肿瘤、胰腺肿瘤、食道肿瘤、肾脏肿瘤、淋巴瘤和结直肠肿瘤。评估结果(下表)显示,在这些疾病中,前50个最相关的miRNA中的许多都被估计到了。
考虑因素
我们提出了一个模型--RFLMDA,它基于强化学习的Q-learning算法,并结合了三个模型--CMF、NRLMF和LapRLS。该模型是基于Q-learning算法。该模型通过多次迭代学习权重:S,使三个模型达到最优。 5倍交叉验证的结果显示,最佳权重为S(0.1735,0.2913,0.5352),该模型具有较高的预测精度--AUC:0.9416。模型具有更高的性能。
作为对RFLMDA预测性能的进一步验证,对8种疾病进行了额外的评估,作为案例研究。因此,我们已经确定了与结直肠和乳腺肿瘤相关的所有前50个miRNA,以及与胃癌、结直肠癌、胰腺癌、食管癌、肾癌和淋巴瘤相关的前50个miRNA中的41、47、49、46、46和48。这些评价表明,RFLMDA能够得出可靠的候选miRNAs。
由于miRNA的概念本身是新的,因此非常需要能够模拟未知miRNA和疾病之间关联的工具。因此,所提出的模型将为未知miRNA与疾病之间的关联程度提供方向,并将使人类疾病治疗和基因药物的开发取得更有效的进展。
另一方面,挑战在于所使用的模型的性能限制,以及模型对其他疾病的性能的不确定性,而不是正在评估的疾病。在前一种情况下,所提出的模型的预测准确性可能会因本研究中采用的三种模型--CMF、NRLMF和LapRLS的性能而不同;为了解决这个问题,结合其他学习和分类的方法模型。后者需要对非案例研究的疾病进行额外的评估--特别是对解决方案有高要求的生活方式相关疾病:糖尿病、心血管疾病等。由于每种疾病的具体特点,如果有必要,将需要采用除Q-learning以外的其他算法--基于模型的学习:动态编程(DP),其他无模型的学习:SARSA,蒙特卡洛--以及重新定义这里定义的相似性矩阵。除了Q-learning之外,可能还需要其他算法,例如



与本文相关的类别





