特色是离线强化学习!第二部分
三个要点
✔️ 以Imporatance Sampling去的Offline Evaluation
✔️ 用Dynamic Programming的Offline RL
✔️ 用Policy constraint、Uncertainty estimation的Distributional shift的緩和
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
written by Sergey Levine, Aviral Kumar, George Tucker, Justin Fu
(Submitted on 4 May 2020)
Comments: Published by arXiv
Subjects: Machine Learning (cs.LG), Artificial Intelligence (cs.AI), Machine Learning (stat.ML)
介绍
在本文的第一部分,我介绍了Offline RL、大局、应用以及Offline RL的问题。本文是上一篇文章的延续,详细讲解了Offline RL的方法,尤其是与非政策性RL相关的方法。如果你还没有看完第一部分,请先看一下第一部分,因为这有助于你更好地理解文章的流程。
本文主要介绍两种方法:一种是利用重要性抽样估计政策收益和政策梯度,另一种是利用动态编程。
离线评估和RL与重要性取样
我们首先研究离线RL,它是基于直接估计政策收益的方法。我们将在本章讨论的方法使用Impace Sampling来评估给定政策的回报率或估计回报率的政策梯度。最直接的方法是,在由$/p/{/beta}$得到的轨迹中。重视抽样它是对$J(\pi)$(目标函数)的估计,称为非政策评价。在下一节中,我们将介绍这种非政策评估的公式,以及如何在离线RL中使用。
通过重要性抽样进行政策外评估。
您可以使用重要性抽样来获得非政策轨迹上$J(\pi)$的无偏估计器。

在上述的数式中,$w_{t}^{i}=\frac{1}{n} \prod_{t^{\prime}=0}^{t} \frac{\pi_{\theta}\left(\mathbf{a}_{t^{\prime}}^{i} \mid \mathbf{s}_{t^{\prime}}^{\mathrm{i}}\right)}{\pi_{\beta}\left(\mathbf{a}_{t^{\prime}}^{i} \mid \mathbf{s}_{t^{\prime}}^{i}\right)}$、和$\left\{\left(\mathbf{s}_{0}^{i}, \mathbf{a}_{0}^{i}, r_{0}^{i}, \mathbf{s}_{1}^{i}, \ldots\right)\right\}_{i=1}^{n}$显示了从n个$\pi_{\beta}$中采样的轨迹。这个估计器有一个问题。然而,估计器有一个大方差的问题,因为它将重要性权重$w$乘以地平线$H$。为了解决这个问题,利用$r_{t}$在未来时间$t'$不依赖于$s_{t'}$和$a_{t'}$的特点,我们可以抹去未来的重要性权重,可以用以下方式来表示

这样一来,就不需要再乘以未来的importance weights,使得方差比原公式更低。然而,即使是这样的设备,一般认为差异还是很大。唯一的目标是获得政策性能的高概率保证,这种重要性抽样在研究中被用来获得置信区间。特别是对于Offline RL的安全性很重要的应用,需要在保证策略性能不低于一定水平(如不发生事故)的前提下,改进行为策略$\pi_{\beta}$。第一步是使用为了确保满足这一安全约束,已经有研究探讨了使用重要性抽样估计器的下置信边界的政策。
非政策性政策梯度
正如本章开头所解释的那样,可以利用进口抽样直接估计政策梯度,这是一种估计所需政策参数梯度的方法,以优化$J(\pi)$。这个梯度可以用蒙特卡洛样本来估计,但它需要一个政策上的轨迹($\tau \sim \pi_{\theta}$)。那么,如何将其扩展到线下RL呢?
以往的研究表明,政策外设置,即行为政策$\pi_{\beta}(a|s)$和$\pi(a|s)$与线下不同,但与线下不同的是,政策外政策梯度在过去收除了重用数据外,我们在学习行为政策时,也会从行为政策中获得新的样本。在这一节中,我们将介绍政策外的梯度,并展示以后将其扩展到线下会面临哪些问题和挑战。
政策梯度表示为

如果我们用重要性抽样来估计

当我们估计政策梯度时,我们可以用与上一节介绍的收益相同的方式排除未来重要性权重。

近似的非政策性政策梯度
在前文所述的进口加权政策目标中,我们还要乘以进口权重,这就造成了很大的方差。所以,我们可以用$\pi_{\beta}$的状态分布代替当前策略$\pi$中的状态分布$d^{\pi}$,得到$\pi$的近似策略梯度。由于状态分布$d^{pi}$和$d^{\pi_{\beta}}$之间的不匹配,这种近似的政策梯度也是有偏差的,但研究表明,它在实践中经常起作用。这个新的目标函数可以表示如下
$$J_{\beta}\left(\pi_{\theta}\right)=\mathbb{E}_{\mathbf{s} \sim d^{\pi} \beta(\mathbf{s})}\left[V^{\pi}(\mathbf{s})\right]$$
$J_{\beta}(\pi_{\theta})$和$J(\pi_{\theta})$处于不同的状态分布,$J_{\beta}(\pi_{\theta})$是$J(\pi_{\theta})$的偏估计器。由于偏估计器的存在,有时需要一个次优解,但在$d^{\pi_{\beta}}$的目标函数中,不需要使用导入抽样,所以我们可以用其优点是可以对数据进行采样,方便计算。
未来的挑战
在本章中,我们介绍了一种使用导入抽样的方法,即使用导入抽样来估计当前政策$\pi_{\theta}$的最终收益率或收益斜率。但是,上面介绍的政策改进基本上是针对非政策学习的,即在设计时既要使用过去收集的样本,又要使用与训练同时收集的新样本。这也是为什么离线RL的作用不大的原因。那么,要想使用线下RL,需要解决哪些问题呢?其一,如果用于收集线下数据的行为策略$\pi_{\beta}$与当前的策略$\pi_{\beta}$相差太远,由于导入抽样本身的高方差,则这就导致重要性抽样估计效果不佳,方差过大,特别是在高维状态和行动空间或长边疆问题中。因此,$\pi_{\theta}$不能离$\pi_{\beta}$太远。因此,重要性抽样目前仅限于低维的状态/动作空间和相对较短的地平线任务,利用$\pi_{\beta}$的次优。
离线RL与动态编程
使用动态编程的算法,如Q-learnng,基本上比使用策略梯度的算法更适合离线RL。在行为者-批评者的情况下,政策梯度是通过使用价值函数来估计的。目前已经有一些使用动态编程的离线RL研究,如QT-Opt,这是一种基于50万个离线抓取数据的Q学习方法。然而,这种方法也被证明,当在新的训练中同时使用额外的数据时,其准确性更高。然而,一些研究表明,使用离线RL可以更好地训练一些数据集。
然而,我们知道,如果不进行在线数据收集,分布转移并不能产生良好的效果,正如我们在第一个离线RL功能中所显示的那样。解决这个问题的方法主要有两种,一种叫做政策constrant,就是让学到的政策$$接近收集数据时所用的政策$\pi_{\beta}$。另一种方法称为基于不确定度的方法,估计Q值的不确定度,并用它来发现分布偏移。在这一节中,我们首先会对分布转移进行详细的解释,介绍这两种方法,然后说明最后需要解决什么样的问题。
Distribution Shift
在Offline RL中,有两种类型的分布偏移会导致问题:状态分布偏移(访问频率)和行动分布偏移。当离线RL中训练的政策$\pi$在测试时间进行评估时,其分布转移是状态访问频率$d^{\pi}(s)$和行为政策$\pi_{\beta}$在学习的政策$d^{\pi_{\beta}}(s)$上的分布转移。如果访问频率$d^{\pi}(s)$不一样,行为者-批评者训练的策略可能会在未知状态下产生意外的行动。这种关于状态的分布转移在测试中是个问题,但在训练中却恰恰相反,关于行动的分布转移是个问题。这意味着,为了计算下面的目标Q值,我们需要计算$Q(s_{t+1}, a_{t+1})$ 这取决于$a_{t+1} \sim \pi(a_{t+1}|s_{t+1})$,所以如果$\pi(a|s)$离$\pi_{\beta}$太远,输出的目标Q值就会有较大误差。

而如果策略能够输出一个未知的动作,比如在由于错误导致Q函数非常大的情况下,那么策略就会学习执行这个动作。在在线RL中,Q函数即使属于这种情况,也可以通过获取新的数据进行修正,但在离线RL中是不可能的,所以这是一个问题。
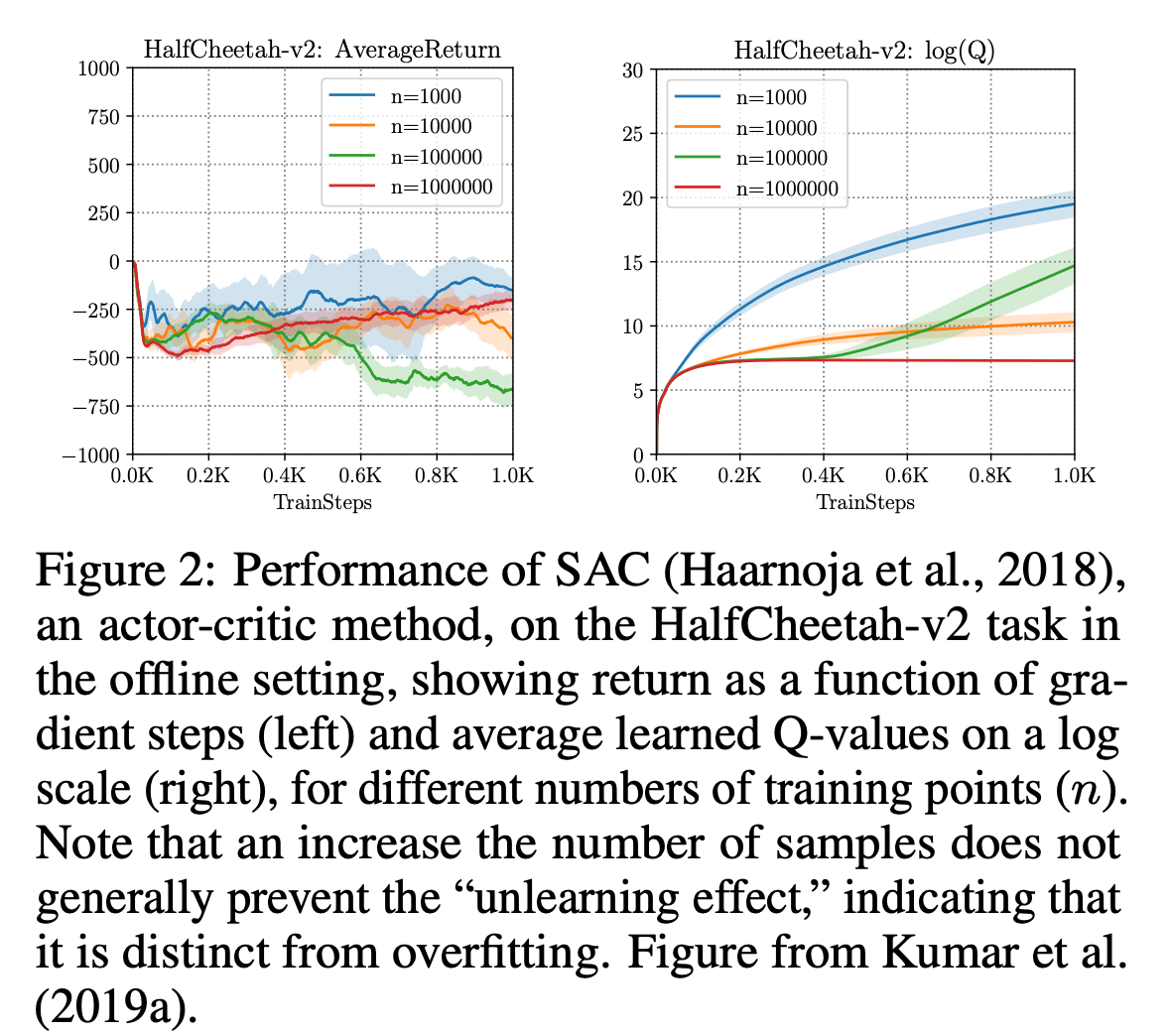
这不是一个简单的增加数据的问题。下图中,横轴是梯度更新,纵轴左边是最终的平均收益,右边是对数刻度的Q值。如果你看下图左边的绿线,看起来像是过拟合,因为一旦性能上升,随着我们的不断学习,性能就会下降,但与橙色的较少数据相比就不是这样了,过拟合是通过增加更多数据来解决的。这使得问题变得更加复杂。此外,随着训练的进行,目标Q值越来越大,整体Q功能越来越差。这样一来,可以说行动上的分布误差对于学习代理有效使用offliine RL很重要。接下来,我们介绍政策约束是解决这个问题的方法之一。
政策限制
防止行动上的分布偏移的一个有效方法是使用策略约束,使$\pi(a|s)$接近$\pi_{\beta}(a|s)$,防止未知行动被执行。如果执行了一个未知的动作,由于意外的动作被执行了一次,错误会继续积累,但如果未知的动作没有被执行,则会防止错误的积累。那么,我们该如何做政策性违章呢?在这篇文章中,我们讨论了显式f分化约束、隐式f分化约束(主要是KL分化)以及一种称为积分概率度量(IPM)的技术。我们将介绍他们。约束也有两种基本类型:一是政策约束,直接约束行动者的更新;二是政策惩罚,约束奖励函数和目标Q值。
首先,我们来看看政策约束,可以用定点迭代法来表示,其目标如下

$$\pi_{k+1} \leftarrow \arg \max _{\pi} \mathbb{E}_{\mathbf{s} \sim \mathcal{D}}\left[\mathbb{E}_{\mathbf{a} \sim \pi(\mathbf{a} \mid \mathbf{s})}\left[\hat{Q}_{k+1}^{\pi}(\mathbf{s}, \mathbf{a})\right]\right]$ s.t. $D\left(\pi, \pi_{\beta}\right) \leq \epsilon$$
这基本上是一般行为者-批评法,但在一般行为者-批评法的基础上增加了约束条件$D\left(\pi, \pi_{\beta}\right) \leq \epsilon$。过去曾对$D$进行过实验,包括一些不同选择的研究。这就是所谓的政策约束,对行动者的更新增加了一个约束。
现在我们再来看看政策惩罚:在行动者-批判者中,为了保证政策$\pi$不会偏离$\pi_{\beta}$太远,防止其在未来选择偏离$\pi_{\beta}$的行动,在Q值上加了一个约束条件。 这可以通过在奖励函数中加入惩罚$\alpha \mathcal{D}(\pi(\cdot|s), \pi_{\beta}(\cdot|s))$,即$\bar{r}(\mathbf{s}, \mathbf{a})=r(\mathbf{s}, \mathbf{a})-\alpha D\left(\pi(\cdot \mid \mathbf{s}), \pi_{\beta}(\cdot \mid \mathbf{s})\right)$来实现,同时在Q值中加入约束条件,以防止政策$\pi$离$\pi_{\beta}$太远,而选择未来的行动会远离$\pi_{\beta}$。 另一种拟采用的方法是将约束条件$\alpha D\left(\pi(\cdot \mid \mathbf{s}), \pi_{\beta}(\cdot \mid \mathbf{s})\right)$直接加到目标Q值中,可表示为:1.

现在让我们来看看不同类型的约束。第一个是明确的f分化约束。对于所有的$f$凸函数,$f$-分歧定义如下。

KL-divergence,$\chi^{2}$-divergence,总变量距离等是常常被用的$f$-divergence的一种。接下来我们介绍隐式$f$-divergence
隐性的$f$离间约束条件是AWR表示......。ABM和其他模型,我们将通过以下步骤来训练政策。

上面的第一个表达式
是导入抽样权重Importance sampling weight $\exp \left(\frac{1}{\alpha} Q_{k}^{\pi}(\mathbf{s}, \mathbf{a})\right)$上对样本进行加权,通过用KL-divergence解决回归问题,我们确定了以下策略。其中$$为拉格朗日乘数。这个方法的推导可以在这里找到。
最后,我们将介绍积分概率度量(IPMs)。这些是分歧是可以测量的。用下面的表达式表示,它是$D_{\Phi}$为取决于函数类$\Phi$。

例如,如果函数类$\Phi$是重现核希尔伯特空间(RKHS),那么$D_{\Phi}$就代表最大均值差异(MMD)。这种基于MMD的方法用在一个叫BEAR的方法中。
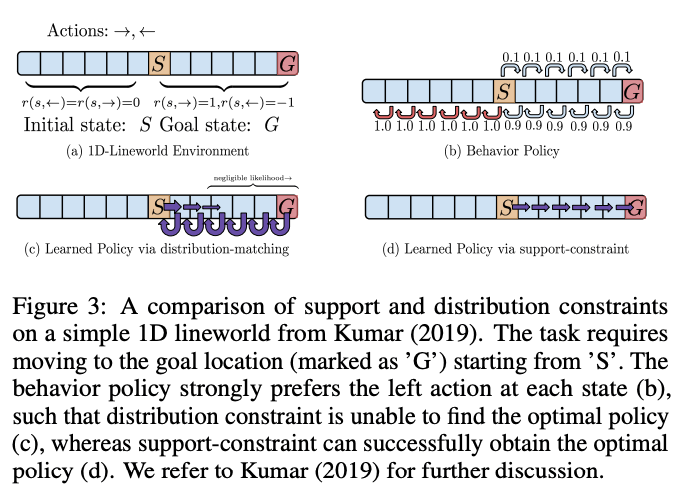
那么如何选择约束条件呢?基本上,KL-divergence和其他$f$-divergences都不太适合离线RL。例如,如果行为政策是均匀随机的,KL-divergence使政策更接近行为政策,这就导致了一个非常随机的次优政策。下面我们来看看1-D Lineworld环境的例子。在本例中,我们从Start $S$开始,到Goal $G$,行为策略假设向左过渡的概率很大,如(b)所示。在这种情况下,当使用分布匹配(如KL-divergence)时,无法找到最佳策略,因为它匹配的行为策略具有向左过渡的高概率。另一方面,据说支持约束可以帮助你找到最佳政策。支撑约束是利用上面介绍的最大均值差异进行约束的,过去的经验表明,约束的作用类似于对分配以及支撑的约束。研究通过实验证明了这一点。
不确定性估计
接下来,我将介绍一种不同于政策约束的分配转移的不确定性估计方法。该方法的主要思想是利用未知动作的不确定性输出一个保守的目标Q值,因为当可以估计Q函数的不确定性时,未知动作的不确定性会增加。该方法必须学习由$\mathcal{P}_{\mathcal{D}}\left(Q^{\pi}\right)$表示的Q函数中不确定性的集合或分布。而如果我们能了解到这组不确定性,我们就可以通过估计保守的Q函数来改进政策。这个方程表示如下,其中$Unc$代表不确定性,我们从实际Q值的估计值中减去。

计算这个$Unc$的主要方法是做一个Q函数的合集,或者最大化最坏情况下的Q值。
未来的挑战
正如本章所解释的那样,近似动态编程算法在离线环境中的表现很差,主要是由于行动中的分布转移,以及策略我介绍了两种类型的解决方案:约束和不确定性估计。然而,虽然不确定性估计不能提供比策略约束更好的性能,但当需要保守地执行行动时(例如,防止事故),特别是在离线RL中,使用不确定性估计仍然是一个好主意。这种对不确定性估计的使用尤为重要,今后需要改进。另一方面,政策约束的表现要好一些,但使用政策约束的算法的性能不如这取决于行为政策估计的准确性。换句话说,如果行为政策表现出多模态的行为运动,就很难准确估计行为政策,目前也很难将行为政策应用于实际问题。此外,即使行为策略被完美估计,由于函数逼近的影响,学习也可能无法进行。例如,如果数据集很小,可能会对小数据集进行过拟合,如果动作状态分布很窄,学习的策略就会很通用。而最重要的是,在线RL通过收集新的数据来解决高估误差,而离线RL则存在误差堆积的问题。而另一个问题是,一旦培训政策离开了行为政策,就会越走越远。由于学习的策略频繁地访问未知状态,所以会出现性能下降。因此:你需要运用强有力的政策约束,但这将限制政策的改进。因此,我们需要考虑的一个问题是找到一个约束条件,能够有效地在错误积累问题和被学习的次优策略问题之间做出权衡。
摘要
本文介绍了无模型RL中离线RL的方法和问题。不过,我们希望通过这篇文章能让大家对方法有一个整体的认识,对大家以后的阅卷有所帮助。我想密切关注离线RL的问题和它的性能,但我不确定仅从离线数据集是否真的能解决动作分布转移问题。



与本文相关的类别






