![[PiCIE] 用于无监督语义分割的像素级聚类法](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2021/picie.png)
[PiCIE] 用于无监督语义分割的像素级聚类法
三个要点
✔️基于像素级聚类的无监督语义分割方法的建议
✔️使用引入两个归纳偏差的损失函数(不变性和等值性)。
✔️在COCO和Cityscapes的出色表现
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering
written by Jang Hyun Cho, Utkarsh Mall, Kavita Bala, Bharath Hariharan
(Submitted on 30 Mar 2021)
Comments: CVPR 2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
对于语义分割,像素级的注释数据集很重要。
然而,在现实中,由于注释图像的成本很高,这样的数据集并不总是可用。
在本文中,我们提出了一种从无标记数据集中进行无监督的语义分割的方法,如下图所示。

如果能够实现这种无监督的语义分割,它将具有各种优势,例如降低注释的成本和发现人类未曾发现的类别。
我们提出的方法,即利用不变性和等价性的像素级特征聚类(PiCIE),在像素级聚类的基础上解决了这个问题,并且优于现有的方法。让我们来看看下面的内容。
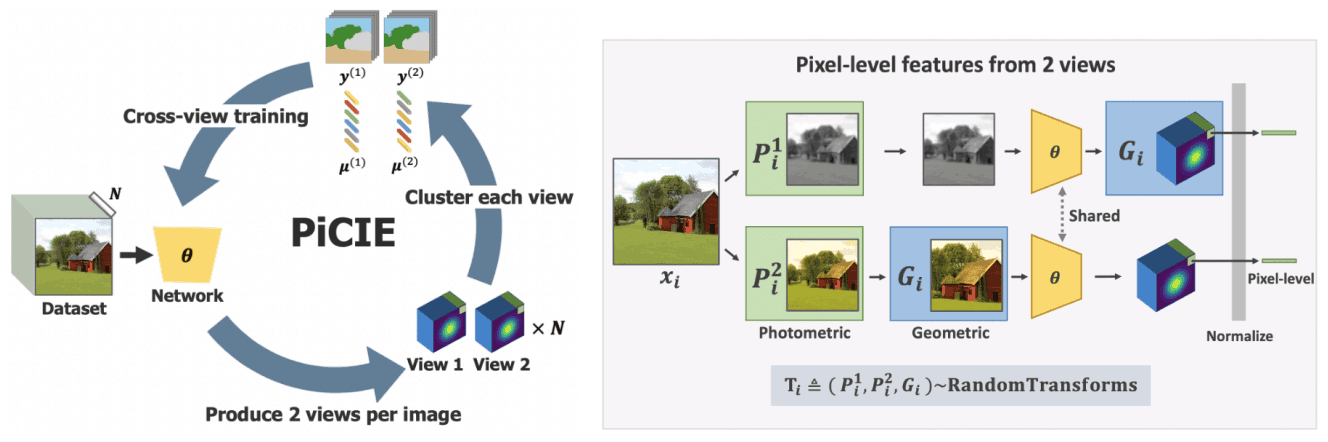
建议的方法(PiCIE
首先,我们考虑无监督语义分割任务的任务设置。
对于来自领域$D$的无标签图像数据集,该任务的目标是发现图像中的一组视觉类别$C$,并学习一个函数$f_{\theta}$,为从$D$获得的图像中的每个像素分配一个类别。
所提出的方法,PiCIE,作为像素级聚类来解决这个问题,图像中的所有像素(而不是每个图像)都被分配到一个聚类中。
然而,为了使这种聚类工作正常进行,每个像素必须被转化为一个良好的特征表示,但这样的特征空间是事先没有给定的。
为此,PiCIE进行了像素级聚类,并为此学习了特征表示。
具有像素级聚类的基线
在考虑像素级聚类之前,我们将介绍关于图像级聚类情况的现有研究。
这里的挑战是两难的,我们需要一个好的特征表示来进行聚类,但我们需要类标签来获得这个特征表示。
为了解决这个问题,DeepCluster执行聚类来寻找特征表征,然后使用产生的聚类作为伪标签来学习特征表征。这种方法可以扩展到无监督的语义分割。
换句话说,我们为每个像素找到一个特征表示,对每个像素进行聚类,并使用伪标签来学习每个像素的特征表示。
具体来说,对于一个无标签的图像$x_i (i=1,.)。,n)$,让$f_theta(x)$是由$f_\theta$得到的特征张量,$f_theta(x)[p]$是像素$p$对应的特征表示,$g_w(\cdot)$是对每个像素的分类器,然后重复以下两个过程基准线被考虑。
1.使用当前的特征表示法和K-means方法(实际上是迷你批量K-means方法)对数据集中的图像的每个像素进行聚类。
$min_{y,\mu}\sum_{i,p} ||f_\theta(x_i)[p]-\mu_{y_{ip}}||^2$
其中,$y_{ip}$表示第i$幅图像的第p$个像素的簇标签,$mu_k$表示第k$个簇的中心点。
2.基于聚类得到的伪标签,我们使用交叉熵损失训练一个逐个像素的分类器。
$min_{\theta,w}\sum_{i,p} L_{CE}(g_w(f_\theta(x_i)[p]),y_{ip})$
$L_{CE}(g_w(f_\theta(x_i)[p]),y_{ip})=-log\frac{e^s_{y_{ip}}}{\sum_ke^{s_k}}$
其中$s_k$是分类器$g_w(f_\theta(x_i,p))$的第k$类对应的分数输出。以这些为基线,建议的方法,PiCIE,做了如下的修改。
分类器的非参数化
在上述基线中,分类器$g_w(\cdot)$被用来对每个像素进行分类。
然而,由于用于训练该分类器的伪标签在训练过程中不断变化,该分类器的输出很可能是有噪声的,可能无法有效工作。
由于这个原因,我们不使用像素分类器$g_w$,而是简单地使用与每个簇的中心点的距离来标记像素。
$min_\theta \sum_{i,p}L_{clust}(f_\theta(x_i)[p],y_{ip},\mu)$
$L_{clust}(f_\theta(x_i)[p],y_{ip},\mu)=-log(\frac{e^{-d(f_\theta(x_i)[p],\mu_{y_{ip}})}}{\sum_l e^{-d(f_\theta(x_i)[p],\mu_l)}})$)
其中$d(\cdot,\cdot)$是余弦距离。
引入感应式偏压
除了上述的学习程序之外,我们还为语义分割引入了两个归纳偏见。
- 对光度变换的不变性(Iinvariance to photometric transformations):即使像素的颜色略有变化,标签也是不变的。(例如,如果整个图像的亮度改变,标签就不会改变)。
- 对几何变换的等效性:如果图像在几何上发生变化,标签也会随之变化。(例如,如果图像的某一部分被放大,标签也会被放大)。)
具体来说,如果图像$x$的语义标签输出为$Y$,光度变换为$P$,几何变换为$G$,那么图像$G(P(x))$经过这些变换后的输出为$G(Y)$。
为确保预测结果符合这些特点,采用了以下过程。
关于测光变换的不变性
首先,我们考虑对测光变换的不变性。
对于数据集中的每一幅图像$x_i$,我们随机抽取两个光度变换$P^{(1)}_i$,$P^{(2)}_i$。对于有这些变换的每张图像,得到了与每个像素对应的两个特征向量。
$z^{(1)}_{ip}=f_\theta(P^{(1)}_i(x_i))[p]$
$z^{(2)}_{ip}=f_\theta(P^{(2)}_i(x_i))[p]$
基于这些特征向量,可以得到两个伪标签和一个中心点。
$y^{(1)},\mu^{(1)}=arg min_{y,\mu}_sum_{i,p}||z^{(1)}_{ip}-\mu_{y_{ip}}||2$
$y^{(2)},\mu^{(2)}=arg min_{y,\mu}_sum_{i,p}||z^{(2)}_{ip}-\mu_{y_{ip}}||2$
在这些伪标签和中心点的基础上,我们引入两个损失函数,如下所示。
$L_{within}=\sum_{i,p}L_{clust}(z^{(1)}_{ip},y^{(1)}_{ip},\mu^{(1)})+L_{clust}(z^{(2)}_{ip},y^{(2)}_{ip},\mu^{(2)})$
$L_{cross}=\sum_{i,p}L_{clust}(z^{(1)}_{ip},y^{(2)}_{ip},\mu^{(2)})+L_{clust}(z^{(2)}_{ip},y^{(1)}_{ip},\mu^{(1)})$
通过$L_{within}$,特征向量的聚类被训练成有效的工作(接近与伪标签相对应的中心点),即使受到光度转换的影响。
另一方面,$L_{cross}$通过学习特征向量的聚类来实现对光度变换的不变性,从而有效地对经历不同光度变换的图像所对应的伪标签/中心点起作用。
关于几何变换的等效退化问题
此外,我们为几何变换引入了一个等价物。具体来说,我们将几何变换$G_i$纳入上述的两个特征向量。
$z^{(1)}_{ip} = f_\theta(Gi(P^{(1)}_i (xi))[p]$
$z^{(2)}_{ip} = G_i(f_\theta(P^{(2)}_i (xi))[p]$
在这种情况下,$Z^{(1)}_{ip}$被应用于光度转换后的图像$P^{(1)}_i (xi)$,$Z^{(2)}_{ip}$被应用于光度转换后图像的特征向量$f_\theta(P^{(2)}_i (xi))$,分别由几何学的进行转换。
基于这些特征向量,我们可以通过使用损失函数$L_{total}=L_{within}+L_{cross}$,结合上述的损失函数,基于不变性和等值性进行学习。
最后,PiCIE管道的伪代码看起来是这样的

实验结果
在我们的实验中,我们使用COCO-Cityscapes数据集进行验证(我们省略了实验设置)。下面是一个针对COCO-Cityscapes数据集的拟议方法的预测实例。
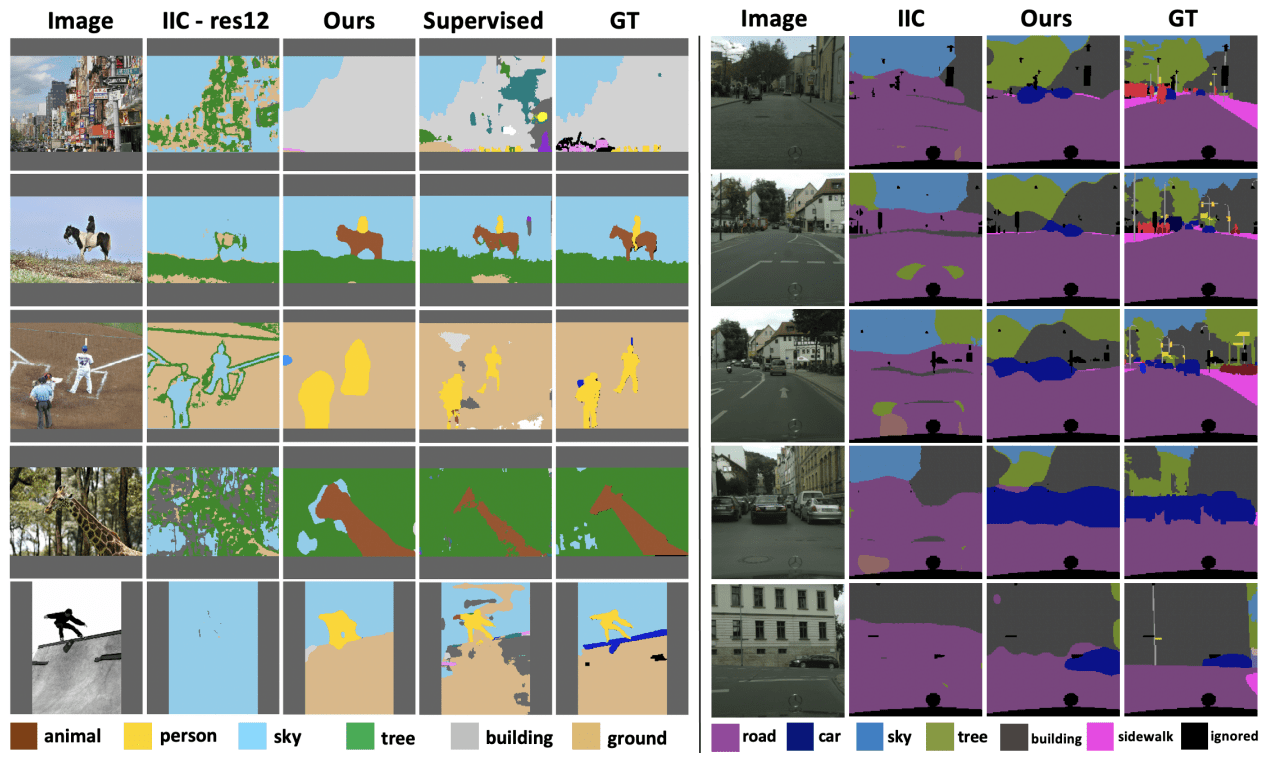
如图所示,与现有的基线方法IIC相比,所提出的方法显示出优越的预测结果。它与监督和地面实况相比也很出色。
整个COCO数据集的表现、两个类别(东西/事物)的表现以及城市景观数据集的表现如下。
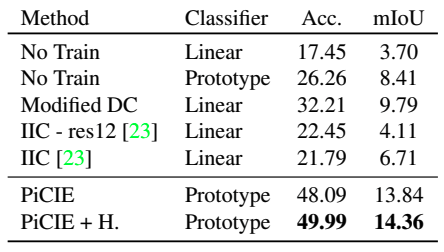
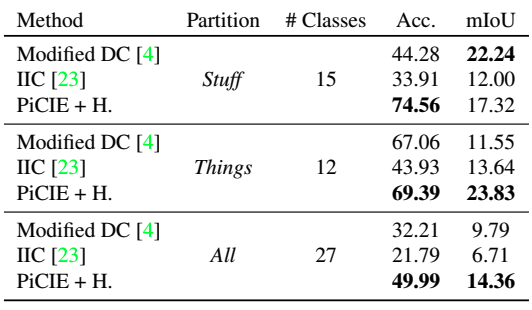

修改的DC表示为语义分割而修改的DeepCluster。此外,+H表示过度集群(针对大量集群的联合优化)。一般来说,所提出的方法优于现有的无监督方法。
摘要
本文介绍的论文通过引入像素级聚类和两个归纳偏向,解决了无监督语义分割的挑战性问题,并显示了出色的效果。
它们非常简单,不需要任何特定的任务处理或精细的超参数调整,但它们在COCO数据集的东西和事物类别上都表现良好,为无监督的语义分割开辟了一条新途径。我们认为,这为无监督的语义分割开辟了一条新的途径。



与本文相关的类别

![[任何分割] 零镜头分割模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/segment_anything-520x300.png)



