
用不精确的伪标签进行半监督性分割
三个要点
✔️ 开发了一种新型的半监督式分割方法,$U^2PL$,该方法使用不精确的伪标签进行训练。
✔️ 根据熵值将假标签分为准确或不准确,不准确的标签被用作每个类别的负面样本的线索。
✔️ 在各种基准实验中,论文方法记录了SOTA。
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
written by Yuchao Wang, Haochen Wang, Yujun Shen, Jingjing Fei, Wei Li, Guoqiang Jin, Liwei Wu, Rui Zhao, Xinyi Le
(Submitted on 8 Mar 2022 (v1), last revised 14 Mar 2022 (this version, v2))
Comments: Accepted to CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
在半监督性分割中,为无标签的数据提供足够数量的假标签是很重要的。传统的方法将对预测有信心的像素作为 "地面实况",但存在一个问题,即大多数像素没有信心,因此不能用于训练。直观地说,一个置信度低的像素应该有很高的置信度,它不确定自己在某些类别之间的预测,不属于任何其他类别。因此,它们可以作为这些类别的负面样本。在本文中,我们开发了一种充分使用无标签数据的方法。首先,根据标签的熵值将其分为准确或不准确,不准确的标签被用作训练中每个类别的负面样本的线索。随着模型预测变得更加准确,准确-不准确的分类阈值被适应性地调整。
技术
让${cal D}_l={{(x_i^l, y_i^l)}_{i=1}^{N_l}$用于标记数据,${cal D}_u={{(x_i^u)}_{i=1}^{N_u}$用于大量未标记数据。${{Cal D}_u=\{(x_i^u)\}_{i=1}^{N_u}$.下图是$U^2PL$的示意图,由一个学生模型和一个教师模型组成,两者之间唯一的区别是权重的更新方式:学生模型的权重$theta_s$以通常的方式更新,而教师模型的权重$theta_t$则以$_更新。theta_s$是用$theta_s$的指数移动平均数更新的。两个模型都包括一个基于CNN的编码器$h$和一个带有分割头$f$和表示头$g$的解码器。在每个训练阶段,提取有标签和无标签的数据{{cal B}_l, {{cal B}_u$,每个样本为$B$。对于有标签的数据,我们最小化了通常的交叉熵,而对于无标签的数据,我们把它们放入教师模型,并从熵值中最小化了确切标签的伪交叉熵。最后,对比性损失被用来采用不确切的标签。最后的损失函数如下。
$${cal L}={cal L}_s+lambda_u{cal L}_u+lambda_c{cal L}_c$$$
其中$lambda_u, \lambda_c$是平衡参数,${cal L}_s, {cal L}_u$是标记的和未标记的损失函数,表示为
$${cal/L}_s=frac{1}{|{cal/B}_l|}\sum_{(x_i^l,y_i^l)\in {\cal B}_l}l_{ce}(fcirc h(x_i^l;\theta), y_i^l) $$
$${cal/L}_u=frac{1}{|{cal/B}_u|}\sum_{x_i^u\in {\cal B}_u}l_{ce}(f\circ h(x_i^u;\theta), {\hat y}_i^u)$$
然而,$y_i^l$是第i$个标记数据的注释标签,${hat y}_i^u$是第i$个未标记数据的伪标签,$f/circ h$是$f$和$h$的组成函数。${cal/L}_c$是以下的。
$${\cal L}_c=-\frac{1}{C\times M}\sum_{c=0}^{C-1}\sum_{i=1}^{M}\log\left[\frac{e^{<{\bf z}_{ci},{\bfz}_{ci}^+>/tau}}{e^{<{bf z}_{ci},{bf z}_{ci}^+>/tau}+{sum_{j=1}^Ne^{<{bf z}_{ci},{bf z}_{cij}^->/tau}}}}right]$$
其中$M$是锚点像素的数量,${bf z}_{ci}$是$c$类的第i$锚点像素的复制量。每个锚有$N$阳性和$N$阴性样本,每个复制是。${bf z}_{ci}^+,{bf z}_{cij}^-$是。$<\cdot,\cdot>$是余弦相似度,$tau$是超参数。
伪标示法
第i$幅图像的第j$个像素的教师模型分割头的概率分布为${\bf p}_{ij}\in {\mathbb R}^C$。其中$C$为类的数量。熵是。
${cal H}({bf p}_{ij})=-\sum_{c=0}^{C-1}p_{ij}(c)\log p_{ij}(c)$
和学习时点$t$的伪标签定义如下。
$${hat y}_{ij}^u=\left\{begin{array}{ll} argmax_{c}p_{ij}(c)&{\rm if}\ {cal H}({\bf p}_{ij})<\gamma_t\ ignore & {\rmotherwise} `end{array} `right.$
其中$gamma_t$是一个阈值,决定了要截断总体熵的多少个百分点。
使用不准确的标签
U^2PL$由锚点像素、正样本和负样本组成。
锚点像素
让${\cal A}_c^l, {cal A}_c^u$分别为迷你批次中每一类有标签和无标签数据的锚点像素。
$${\cal A}_c^l=\{{\bf z}_{ij}|y_{ij}=c,p_{ij}(c)>\delta_p\}$$
$${cal A}_c^u={{bf z}_{ij}|{hat y}_{ij}=c,p_{ij}(c)>\delta_p\}$$
以下是结果。其中,$y_{ij}$是第i$幅图像中第j$个像素的地面真实,${hat y}_{ij}$是伪标签,${bf z}_{ij}$是代表,$delta_p$是阈值。因此,最终类别$c$的锚点像素${cal A}_c$是
$${cal A}_c={cal A}_c^l\cup {cal A}_c^u$$
阳性样本阳性样本。
阳性样本是与锚点像素相同类别的重心。
$${bf z}_c^+=\frac{1}{|{\cal A}_c|}\sum_{{bf z}_c\in {cal A}_c}{bf z}_c$$
负面的样本
让二元变量$n_{ij}(c)$对于有标签的数据为$n_{ij}^l(c)$,对于无标签的数据为$n_{ij}^u(c)$。由于${cal/O}_{ij}=argsort({bf p}_{ij})$。
$$n_{ij}^l(c)={\bf 1}[y\neq c]\cdot{bf 1}[0\leq {cal O}_{ij}(c)<r_l]$$
$$n_{ij}^u(c)={\bf 1}[{cal H}({bf p}_{ij})>\gamma_t]\cdot{\bf 1}[r_l\leq {cal O}_{ij}(c)<r_h]$$
定义为:。其中$r_l,r_h$为阈值。最后,$c$类的负样本被定义为
$${cal N}_c={{bf z}_{ij}|n_{ij}(c)=1}$$
分类记忆库
每个类别都使用了一个内存库${\cal Q}_c$,以确保小型批次内的样本数量为负数。
结果。
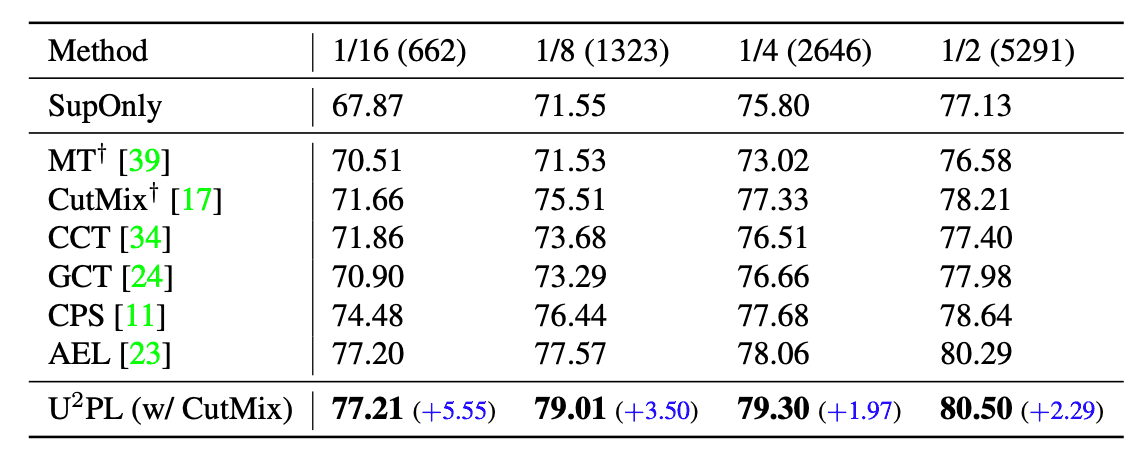
在分割PASCAL VOC数据集时,各半监督学习方法与我们的方法的比较结果如下表所示。表中显示,该方法在所有分割方法中的准确度最高。
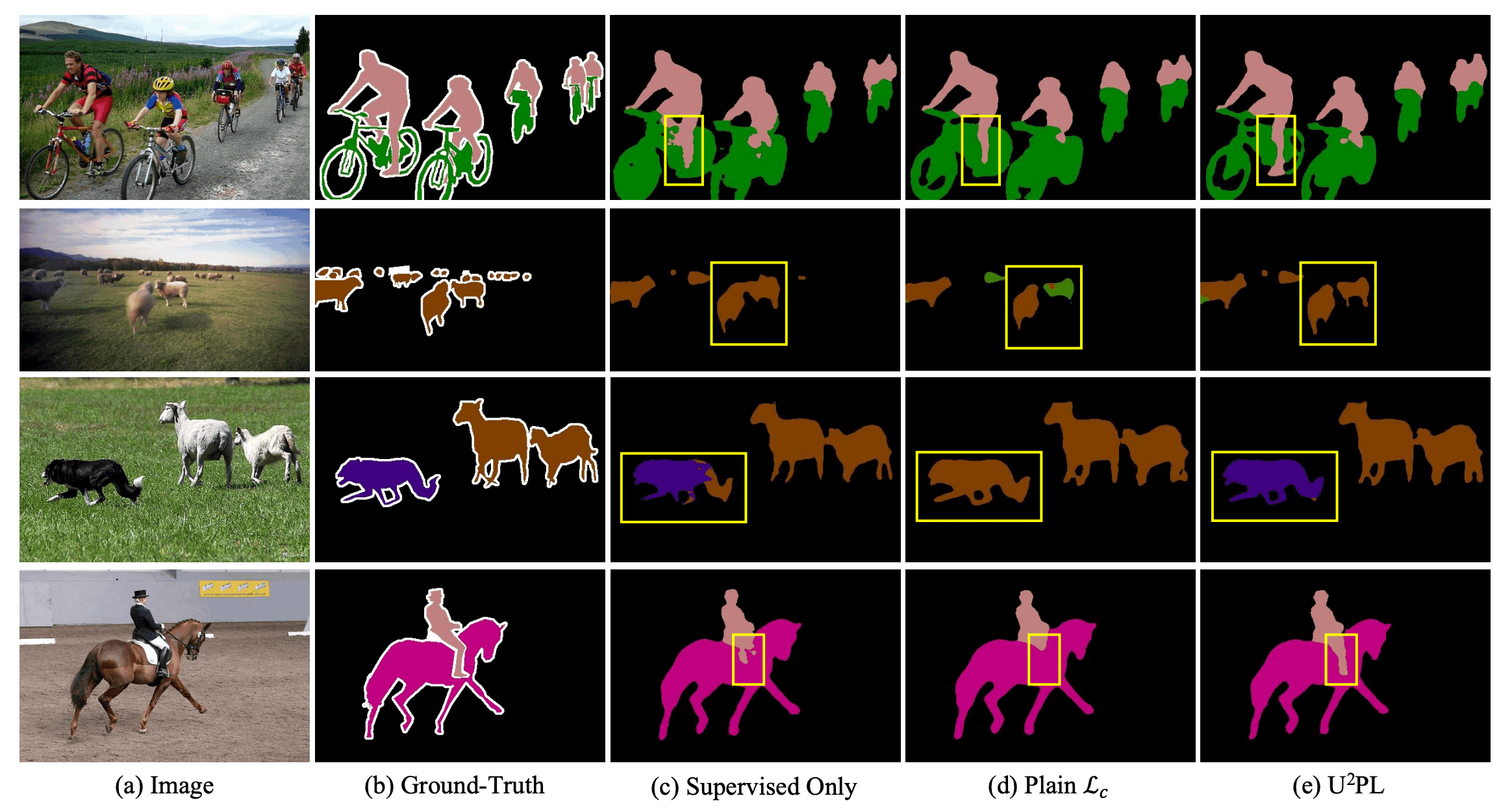
下图中还显示了一个定性比较结果的例子。从图中可以看出,该方法正确预测了只用标记数据训练的模型不完整的区域。
摘要
本文提出了一种新的半监督性分割方法,即$U^2PL$,它利用了不精确的数据。提出的方法显示出比以前的半监督方法更好的性能。与监督学习相比,半监督学习的缺点是需要更多的训练时间,但似乎必须对时间进行补偿,以便在没有大量标记数据的情况下达到高精确度。



与本文相关的类别

![[任何分割] 零镜头分割模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/segment_anything-520x300.png)


![[PiCIE] 用于无监督语义分割的像素](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2021/picie-520x300.png)
