高速公路的新MDP!可扩展的状态定义(上)
三个要点
✔️驾驶中的规划(路线规划)
✔️高速公路上的新MDP(马尔科夫决策过程)
✔️强化学习和逆向强化学习的结合。
Advanced Planning for Autonomous Vehicles Using Reinforcement Learning and Deep Inverse Reinforcement Learning
written by C You, J Lu, D Filev, P Tsiotras
(Submitted on 2019)
Comments: Robotics and Autonomous Systems 114 (2019): 1-18.
Subjects: 分野 (Machine Learning (cs.LG); Machine Learning (stat.ML))
介绍:
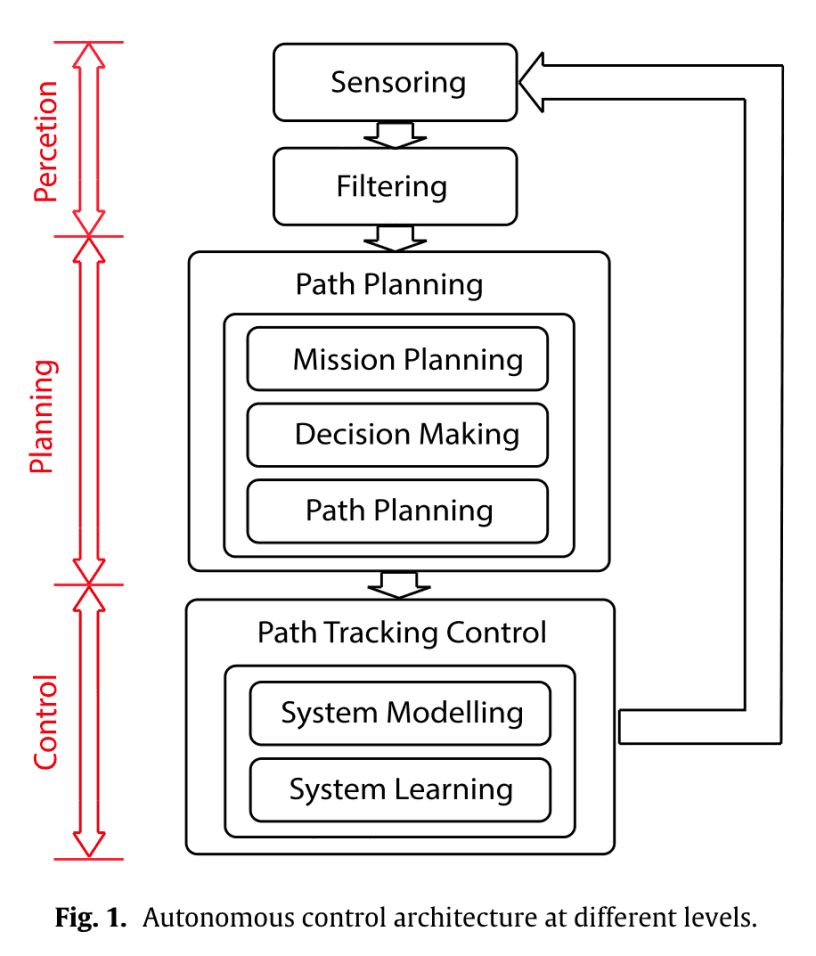
因司机失误造成的事故越来越多。为此,人们对自动驾驶的兴趣越来越大。如下图所示,自动驾驶有三个层次:感知、规划和控制。本文是对规划部分的研究。
贡献
本文的三大贡献如下
- 新的公路MDP模式
- 考虑到道路的形状,可以很容易地进行扩展。
- 去掉车辆的速度,使状态空间不至于太大。
- 任意非线性奖励函数与Max Ent IRL的泛化。
- 无模型MDP的三个Max Ent深度IRL建议
MDP是Markov Decision Process的缩写。在本文的前半部分,我们将介绍所提出的方法。本文后半部分介绍了实验和结果。现在,让我们来看看这张纸。
交通模型
马尔科夫决策过程
我们先来介绍一下马尔科夫决策过程的基本情况。马尔科夫决策过程被广泛应用于机器人、经济学、制造业和自动驾驶等领域。马尔科夫决策过程是一个数学框架,用于对代理人与其环境之间的交互作用进行概率建模。代理商在每一个时间步骤中都会收到环境状态的奖励和表征(观察),并根据它们采取行动。
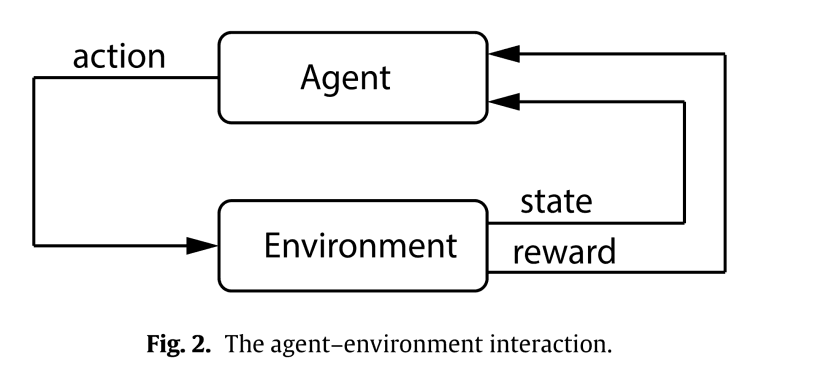
一个典型的马尔科夫决策过程由六个图元组成。
$$(S, A,{\cal T},\gamma, D, R)$$
- $S$:一组有限的可能状态。
- $A$:一组有限的可能状态。
- ${\cal T}$:状态转换概率矩阵(所有状态对)。
- $\gamma$:贴现率 $\gamma\in [0,1)$
- $D$:初始状态分布
- $R$:奖励功能
马尔科维性是指未来的概率分布只取决于现在而不取决于过去的一种属性。在方程中,如果$s$是一个状态,$a$是一个动作,则是满足下式的属性。
$${\mathbb P}(s_{t+1}|s_t,a_t,s_{t-1},a_{t-1},...,s_0,a_0)={\mathbb P}(s_{t+1}|s_t,a_t) \tag{1}$$
马尔科夫决策过程的问题是找到测量$\pi:S\rightarrow A$。最佳措施可以用以下公式来定义。
$$\pi^* = \arg\max_\pi {\mathbb E}\Biggl[\sum_{t=0}^\infty\gamma^t R(s_t,\pi(s_t))\Biggr] \tag{2}$$
而如果我们把马尔科夫性质作为一个表达式,用度量
$${\mathbb P}^\pi(s_{t+1}|s_t)={\mathbb P}(s_{t+1}|s_t,\pi(s_t))\tag{3}$$
系统建模
在本节中,对高速公路场景的马尔科夫决策过程进行建模,如下图所示。
让被控制的车辆为主机车辆(HV),其他车辆均为环境车辆(EV)。动作集${\cal A}$是{"保持速度"、"加速"、"减速"、"左转"和"右转"}。
状态定义
该状态用下图表示
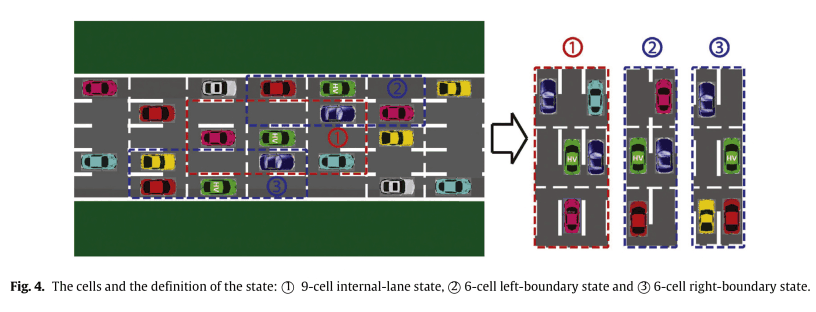
如果你在中间车道,你有9个单元格,如果你在车道的两端,你有6个单元格来代表你的状态。图中的绿车就是本案中的HV和代理商。在这种情况下,马尔科夫决策过程的数量为$2^8+2\times 2^5=320$,分别计算其周围有无EV。有了这个定义,我们可以很容易地随着车道数(2条以上)和车辆的变化而扩大。
在这种情况下,我们还可以考虑如下图所示的曲线。
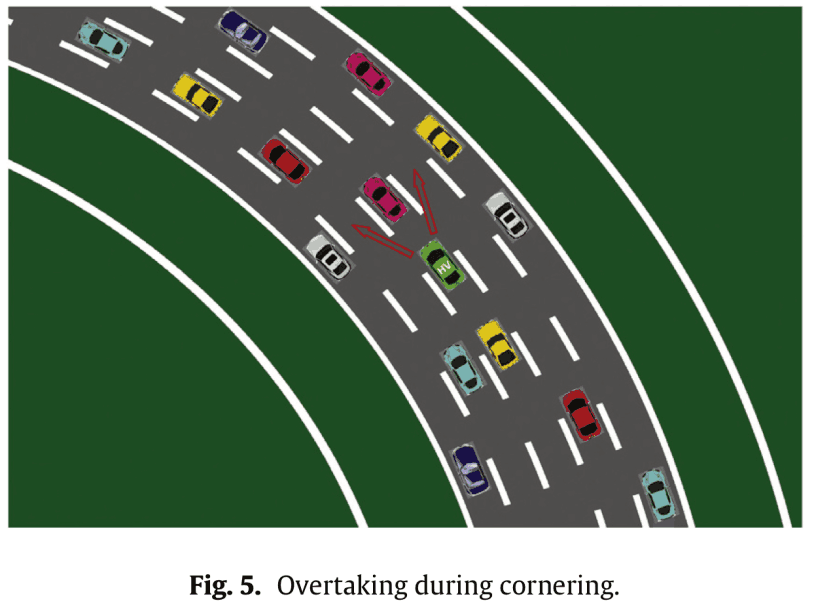
由于曲线内侧超车和曲线外侧超车是有区别的,所以我们将考虑直线、左曲线、右曲线三种曲线。换句话说,马尔科夫决策过程的数量为$320\times 3=960$。
因此,必要时可以进一步分类。比如,上坡、下坡和平地。
状态转换
下一步是状态转换。状态转换有以下假设
- 车道数$n$:$n\geq 2$。
- EVs的数量$N$:$0\leq N\leq 8$
- 电动车有自己的措施,与HV不同。
- 电动车的行动是随机的。
- 电动车不会撞上电动车的HV。
- 每辆车在每一个时间步骤都做一个动作。
根据上述假设,从状态$s_t$到$s_{t+1}$的转变包括两个步骤。
- HV观察到$s_t$,并根据当前的措施$\pi(s_t)$采取行动。
- 电动车跟随高压线的行为,表现随机
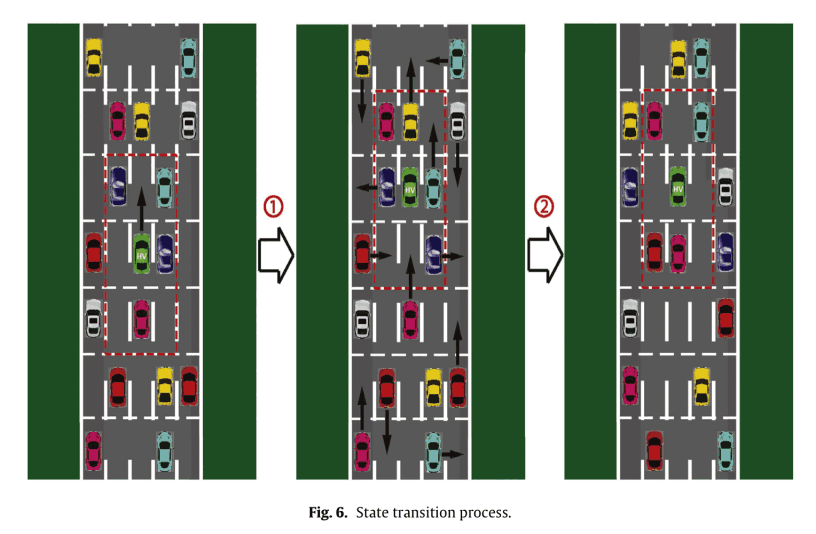
在下图所示的例子中,HV的安全动作是加速或向左变道。在这种情况下,选择加速,周围的电动车就会采取相应的安全随机动作。
强化学习
选择强化学习算法
强化学习算法主要是表法或函数逼近法。表格形式适合于在有限和小状态动作空间中求解马尔科夫决策过程。例如,动态编程、蒙特卡洛方法和TD学习方法。
传统的动态编程使用价值函数来寻找最优的措施。例如,价值迭代法和政策迭代法。但是,它需要对环境有充分的了解,不能用于连续状态的动作空间。蒙特卡洛方法不需要完全了解环境。相反,它要求代理人与环境交互的状态、行为和奖励的样本序列。每集的样本收益是平均的,即在每集结束时进行数值和相应措施的学习。TD学习法是动态编程法和蒙特卡洛法的结合,其优点是不需要充分了解环境,可以在线学习。例如,Sarsa和Q-learning。
Sarsa和Q-learning的区别在于更新当前状态的动作值时参考的是未来状态的动作值,Sarsa代表的是"状态-动作-回报-动作",也就是说要更新当前状态的动作值,就要更新下一步的动作值。剂的动作值进行使用。而Q-learning则是搜索代理在下一步可能采取的最大行动值,并使用该值更新当前状态下的行动值。因此,Sarsa是一种政策内算法,Q-learning是一种政策外算法。
Q-learning使用的是epsilone-greedy方法,可以轻松地触发每集的'死亡',有可能提供更好的策略。所谓"死亡",就是当剧情达到一定状态(目标状态)时,剧情结束。
函数近似用于大型或连续的状态空间问题,可以用一组(非线性)函数来表示数值、度量和奖赏。理论上,所有在监督学习领域使用的方法都可以作为函数近似用于强化学习。例如,神经网络、幼稚贝叶斯、高斯过程和支持向量机。
由于上一章所描述的马尔科夫决策过程的模型具有有限的状态和动作数,而代理并不能预测电动车的行为,因此我们采用无模型的方法,以表格的形式进行。
奖励函数
接下来,我们来谈谈奖励函数,它在强化学习中很重要。在驾驶任务中,设计奖励功能是一项困难的任务,因为很难描述驾驶员的行为特征,实际的奖励功能是未知的。此外,不同司机的奖励功能也可能不同。设计奖励函数的一种广泛使用的方法是将其表示为人工选择的特征的函数。这些特征取决于代理的行为和环境的状态。在本文中,我们使用线性组合的特征来表示奖励函数。
$$R(s,a)=w^T\phi(s,a)\tag{4}$$。
然而,$w$是一个权重向量,$w$是一个特征向量。
这一次,$\phi$由以下五个要素组成。
- 行为特征
- 高压位置
- 超车战术
- 共同所有权
- 碰撞
在1中,驾驶员可能会更喜欢某些回报较高的行为;2、HV是否靠近道路边界行驶;3、在拐弯处通过时,他可能会有从内侧或外侧通过的偏好;4、HV是否在电动车后面;5、HV和电动车是否在同一个广场。5是HV和EV是否在同一个方块。
他们使用这些特征取值器设计一个权重向量$w$来鼓励或惩罚一个特定的特征,并使用强化学习来学习最佳策略,以最大化总奖励。
另一种想法是使用参数化的函数逼近器来设计奖励函数,如高斯过程或深度神经网络(DNN)。函数近似器的参数可能与明确的物理意义没有直接的关系,所以很难人工设计,也很难从数据中学习。
最大熵原理与奖赏函数
当事先对奖励函数的认识不足时,上一章的方法就不方便了。因此,我们采用逆向强化学习,避免人工设计奖励函数,让用户直接从专家司机的示范中学习最佳驾驶策略。
最大熵原理
最大熵原理已被用于计算机科学和统计学的许多领域。在基本公式中,给定一组目标分布的样本和一组目标分布的约束条件,利用最大熵分布估计目标分布,使约束条件得到满足。在逆强化学习问题中,给定由过去的状态和行为组成的代理人的时间历史(demo)来估计奖励函数。以前的逆强化学习的问题是奖励函数不能唯一确定,但通过利用最大熵原理,现在可以唯一确定解。在反强化学习的第一个最大熵原理(Max Ent IRL)中,奖励函数只取决于当前状态,由特征函数的线性组合表示。
$$R(s)=\sum_i w_i \phi_i(s)=w^T\phi(s)\tag{5}$$
$\zeta \triangleq \{s_0,a_0,...,s_T,a_T\}$为以下概率
$${\mathbb P}(\zeta|w)=\frac{1}{Z(w)}e^{\sum_{s\in \zeta}w^T\phi(s)}\tag{6a}$$
$${\mathbb P}(\zeta|w)=\frac{1}{Z(w)}e^{\sum_{s\in \zeta}w^T\phi(s)}\prod_{(s,as')\in\zeta}{\mathbb P}(s'|s,a)\tag{6b}$$
方程(6a)表示确定性马尔科夫决策过程,方程(6b)表示随机马尔科夫决策过程。方程(6)中的两个方程都显示了路径(demo)上的分布,路径的概率与其报酬的指数成正比。这意味着对代理人来说,回报较高的路径更可取(可能性更大)。反强化学习的目标是找到最优权重$w^*$,使观察到的demo的似然在式(6)的分布下最大化。
下面,我们将采用新的奖励结构来制定逆强化学习问题。
- 将$R(s)$改为$R(s,a)$ ($R(s,a)$)
- 处理概率马尔科夫决策过程。
- 该演示必须从相同的状态$s_0$开始,并在$t=0$到$t=T$的相同长度的时间内进行观察。
记法
- $D$:一组演示文稿。
- $N$:$D$中的演示数。
- $\Omega \supseteq$:完整的路径空间
- $\phi_\zeta$:沿途特征的数量($\phi_\zeta = \sum_{(s,a)\in\zeta}$)
非参数化特征
我们先来考虑没有参数化的特征,即没有被神经网络等逼近的特征。非参数化的特征$\phi(s,a)$只是状态和行为的函数。利用这一点,奖励函数可以被看作是以下形式的特征的线性组合。
$$R(w;s,a)=w^T\phi(s,a) \tag{7}$$。
在这里表示$R(w;s,a)$,以明确奖励函数取决于一个未知的权重向量$w$。从相关研究[2]来看,受观测到的$D$的特征约束影响,最大化$\Omega$上的分布熵,与最大化公式(6b)中最大熵分布下$D$的似然相同。换句话说,公式中的表达式。
$$w^*=\arg \max_w {\cal L}_D(w)=\arg\max_w \frac{1}{N}\sum_{\zeta\in {\cal D}}\log{\cal P}(\zeta|w)\\ =\arg \max_w \frac{1}{N}(\sum_{\zeta\in{\cal D}}(w^T\phi_\zeta + \sum_{(s,a,s')\in\zeta}{\mathbb P}(s'|s,a)))-\log Z(w) \tag{8}$$
参数化特征
使用非参数化的功能需要手动设计功能,但不一定能成功设计出形式复杂的未知奖励函数。一般来说,这是一项艰巨的任务。因此,使用参数化的特征。通过使用参数化的特征,避免了通过优化参数来手动设计特征。"为了制定Max Ent IRL问题,我们考虑用特征的线性组合来表示奖励函数,但特征明确依赖于参数$\theta$。
$$R(w,\theta;s,a)=w^T\phi(\theta;s,a) \tag{9}$$。
在式(8)中,不是只调整权重$w$,而是同时调整$\w$,并使可能性${\cal L}_D$最大化,如下所示
$$w^*,\theta^*=\arg\max_{w,\theta} {\cal L}_D(w,\theta)=\arg\max_{w,\theta}\frac{1}{N} \sum_{\zeta\in {\cal D}}\log {\mathbb P}(\zeta | w,\theta)\\ =\arg\max_{w,\theta} \frac{1}{N} (\sum_{\zeta\in {\cal D}}(w^T\phi_\zeta(\theta)+\sum_{(s,a,s')\in\zeta}{\mathbb P}(s'|s,a)))-\log Z(w,\theta)\tag{10}$$
下图为参数化过程。
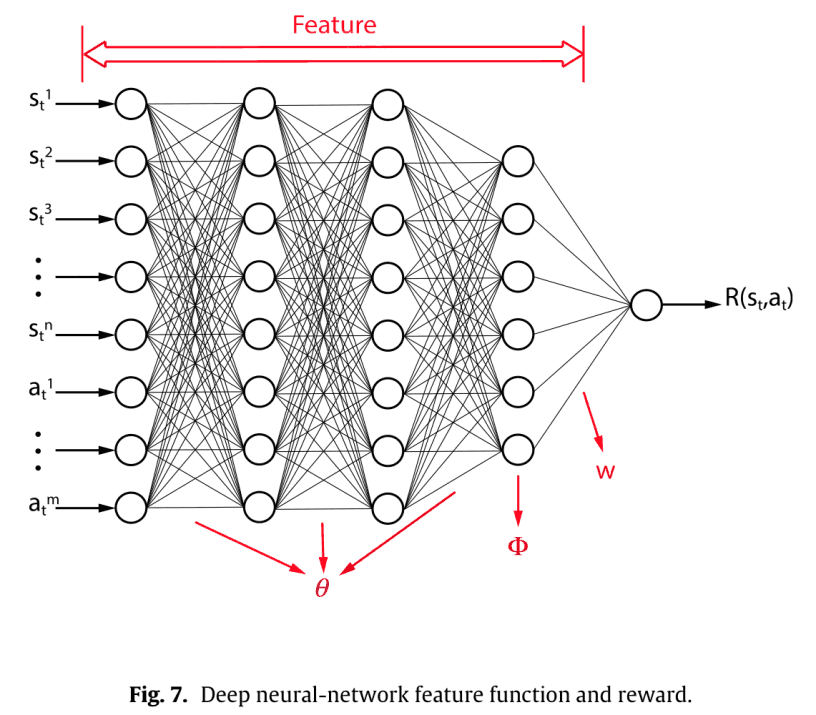
在这里,设置$w=1$可以让我们直接用单个DNN来表示奖励函数,只调整$\theta$就可以得到整个路径空间$\Omega$的最大熵分布。
逆向强化学习
补偿近似器
他们使用DNN作为函数逼近器来恢复未知的奖励。他们还考虑了相关研究中对奖励函数的三种定义。
- $R$: $S\rightarrow R$, $R(s)$
- $R$: $S\times A\rightarrow R$, $R(s,a)$
- $R$: $S\times A\times S\rightarrow R$, $R(s,a,s')$
第一种定义是在你想在没有行动的情况下达到目标状态,或避免危险情况时使用。这个定义表明,代理人对该动作没有特殊行为。
第二个定义考虑了行为,因此我们可以表达代理人对某一行为的偏好。
第三个定义还考虑了在状态$s$中执行动作$a$后的下一个状态$s'$。然而,$s'$取决于环境的反应,代理人可以在不知道未来状态的情况下,根据执行行动$a$的预期报酬决定行动。因此,$R(s,a)$和$R(s,a,s')$可以说是等价的。
由于这些原因,我们将在这种情况下使用$R(s,a)$。
DNNs有两种可能的结构来表示$R(s,a)$,如下图所示。
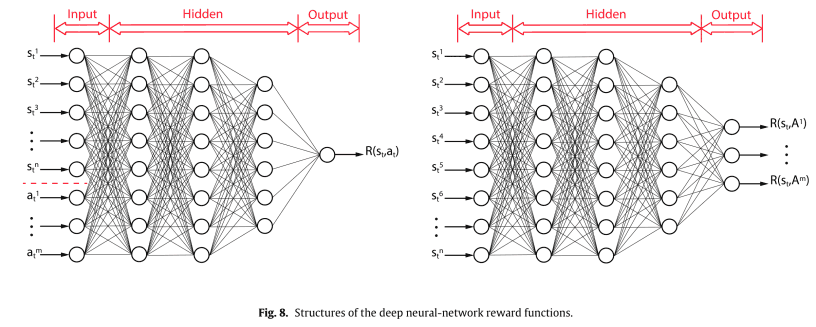
最大熵反强化学习(Maximum Entropy Inverse Reinforcement Learning)
图8.中用于学习参数的IRL算法用上一节的最大熵原理进行解释。
模型学习
考虑一个完全无模型的情况,不知道状态转换模型${\mathbb P}(s'|s,a)$。模型训练的思路是分析每个状态-行为-状态的访问次数,计算状态转换的概率。
$${\mathbb P}(s'|s,a) = \frac{\nu(s,a,s')}{\sum_{s'\in S}\nu(s,a,s')} \tag{11}$$
然而,$\nu(s,a,s')$是在状态$s$中执行动作$a$时,从$s$到$s'$的状态转换的总次数。当$nu(s,a,s')$接近无穷大时,概率${\mathbb P}(s'|s,a)$接近实际值。
该模式通过Q-Learning进行教学。
逆强化学习算法
首先,通过模型训练的结果${\mathbb P}(s'|s,a)$来计算预期状态--行动访问次数${\mathbb E}[\mu(s,a)]$。据此,计算$\frac{\partial{\cal L}_D}{\partial R}$。利用这个公式,计算$\frac{\partial{\cal L}_D}{\partial \theta}$,并根据下面的公式更新参数。
改进的逆强化学习算法
在每个状态行为对的大量访问面前,训练模型可能不会有好的结果。这是由于${\mathbb P}(s'|s,a)$的状态转换概率${{s'|s,a}}$的误差→$\frac{\partial{\cal L}_D}{\partial R}$的误差→$\frac{\partial{\cal L}_D}{\partial \theta}$更新$\theta$时造成的误差。出现了错误的积累,如错误的情况。以下是两个对策
- 在逆向强化学习之前,对模型进行预训练,直到收敛为止。
- 将演示分成小块,避免因长期预测而产生较大误差。
第一,虽然有可能改进,但如果系统很复杂,或者整个demo代表了随机系统的长期行为,那么demo ${\cal D}$可能仍然不足以代表环境的随机行为。
这次我们将采用第二种策略。将演示demo ${\cal D}$划分为:$$\cal D_\tau = \zeta_\tau^i\,i=1,...,N_\tau$$
除法规则有三种。
- $\zeta_\tau^i$从$\tau\in S$开始
- $\zeta_\tau^i$的长度对$\tau\in S$一定,就是$\Delta T$
- $\zeta_\tau^i\subseteq \zeta$的途径$\zeta\in {\cal D}$
与$zeta_\tau$相对应的路径空间表示为$\Omega_\tau$,并在所有$\Omega_\tau$的同时分布的熵最大化,受demo ${\cal D}_\tau$的约束。
结论
在本文的前半部分,我们介绍所提出的方法了。所提出的MDP(Markov Decision Process,马尔科夫决策过程)交通模型具有吸引力,因为它易于扩展。我们将奖励函数$R(s)$扩展为$R(s,a)$,因为它只考虑逆强化学习中的状态,所以不适合复杂任务。这是本文首次提出这一概括。在本文的后半部分,我们将介绍他们的实验和结果。请参考本文的后半部分。
参考文献
1]尤长喜,陆剑波,Dimitar Filev,Panagiotis Tsiotras."Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning."Robotics and Autonomous Systems 114(2019):1-18.
[2]E.T.Jaynes,"Information theory and statistical mechanics",Phys.Rev.106(4)(1957)620-630.



与本文相关的类别




