高速公路的新MDP!可扩展的状态定义(下)
三个要点
✔️驾驶中的规划(路线规划)
✔️高速公路上的新MDP(马尔科夫决策过程)。
✔️强化学习和逆向强化学习的结合。
Advanced Planning for Autonomous Vehicles Using Reinforcement Learning and Deep Inverse Reinforcement Learning
written by C You, J Lu, D Filev, P Tsiotras
(Submitted on 2019)
Comments: Robotics and Autonomous Systems 114 (2019): 1-18.
Subjects: 分野 (Machine Learning (cs.LG); Machine Learning (stat.ML))Code介绍:
因司机失误造成的事故越来越多。为此,人们对自动驾驶的兴趣越来越大。如下图所示,自动驾驶有三个层次:感知、规划和控制。本文是对规划部分的研究。
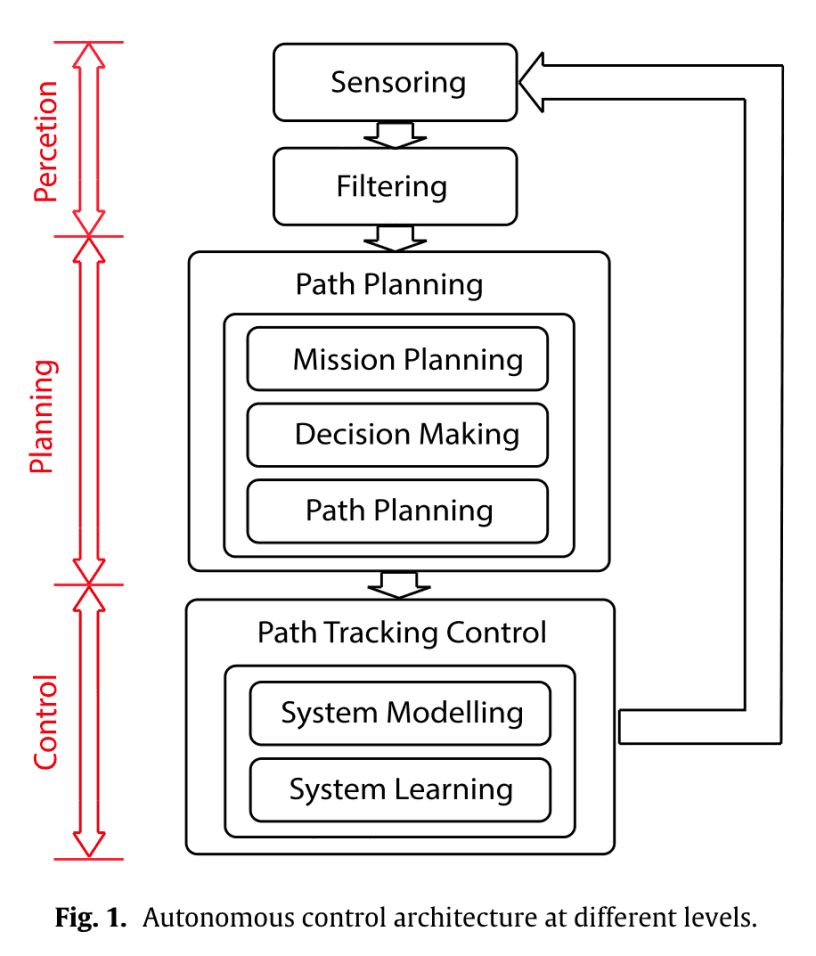
贡献
本文的三大贡献如下
- 新的公路MDP模式
- 考虑到道路的形状,可以很容易地进行扩展。
- 去掉车辆的速度,使状态空间不至于太大。
- 任意非线性奖励函数与Max Ent IRL的泛化。
- 无模型MDP的三个Max Ent深度IRL建议
MDP是一个马尔科夫决策过程。在上一篇文章(第一部分)中,解释了所提出的方法。他们为高速公路的交通模型定义了一种新的MDP(Markov Decision Process),并提出了最大熵逆强化学习的扩展。
现在,让我们来看看这个实验。
实验、结果和分析
在本章中,我们将在所述交通模型上实现强化和逆强化学习算法,并对结果进行分析。
交通模拟器
这是本次实验中使用的模拟器的内容,它是使用Pygame Python库创建的。车道数为5条。不区分车辆类型(卡车、轿车等)。每个电动车都有一个随机策略。随机策略利用周围所有的车辆(HV和EV)来定义状态$s_{EV}$,找到一组不会导致EV碰撞的动作,然后从这组动作中随机确定一个动作。
通过强化学习设定驾驶行为(专家)
在这里,你将使用强化学习来获得专家级的驾驶行为。在这种情况下,我们有两种权重:超车和跟车。设计权重$w_1$(超车)和$w_2$(跟随)见表1。
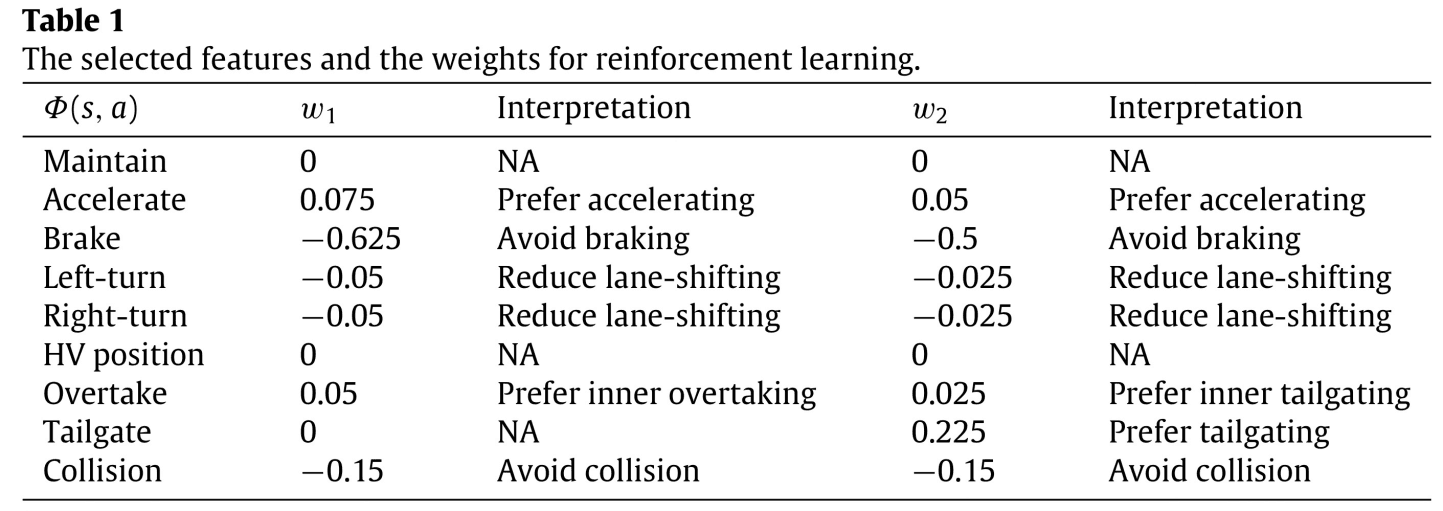
通过对$w_1$的设计,期望的驾驶行为(超车)如下。
- 如果HV前面的细胞是自由的,HV就会加速并占据前面的细胞。
- 如果HV前方有EV,无法通过,HV将保持其速度。
- 当只有一方能通过时,HV通过先变道、加速,再保持速度的方式超越前面的电动车。
- HV从弯道内侧超车,如果能从两边超车的话
- HVs不换车道,除非他们正在通过。
- 刹车时,HV不占用后排电池。
- 不允许发生冲突。
通过对$w_2$的设计,期望的操作行为(后续)如下所示
- 当EV在HV前面时,HV会保持其速度。
- 当车辆前方小区空闲,且车道变化不会导致其跟随时,HV会加速占据前方小区。
- 当HV前方没有EV时,HV会改变车道跟随EV。
- 电动车喜欢跟在弯道内的车辆后面。
- 高速公路除非遵循以下规定,否则不得变更车道。
- 刹车时,HV不占用后排电池。
- 不允许发生冲突。
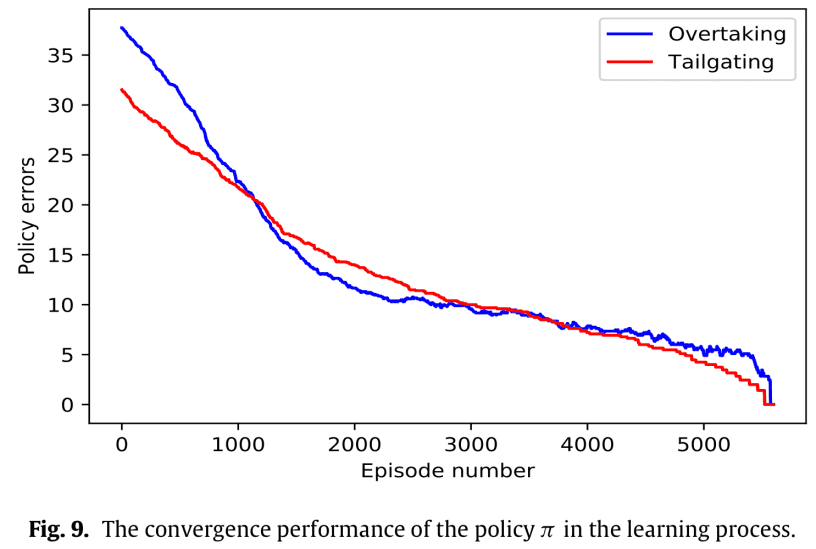
他们使用Q-learning来学习这些最优策略。$w_1$:$w_1^*$和$w_2$:$w_2^*$对应$w_1$:$/pi_1^*$。下图是收敛的情况。
下面是一个使用政策$1^*$进行模拟的结果的例子。
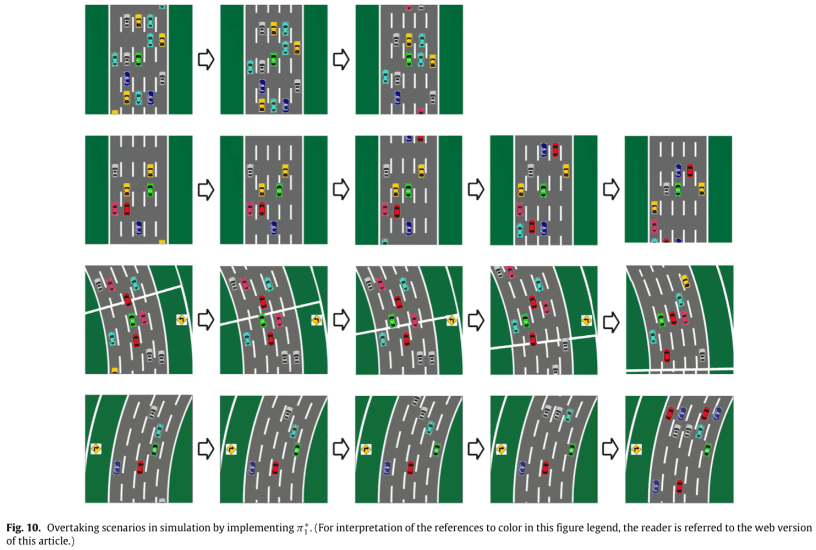
第一条线是指HV前方有空间的情况;HV加速,在黄车后面。
第二条线是指HV前面有一辆车,左右车道都可以超车的情况。由于道路是一条直线,所以可以从任何一边超车。在这种情况下,汽车从左侧超车,并加速直到追上蓝车。
第三条线是车辆在HV前方和右侧的情况,HV只能使用左侧车道通行。
4号线是指HV前面有一辆车,左右车道都可以超车的情况。车子向右变道,在弯道内,加速行驶,但没有完成通行,因为青色的车也在加速。
这些行为与我们在设计权重$w_1$时瞄准的行为是一致的,并且已经成功地学会了。
通过逆向强化学习获得驾驶行为。
首先,我们选择图8.中DNN的结构来表示奖励函数。在这种情况下,在这用的是第二种,比较方便。状态向量$s_t$是9辆汽车(1辆HV和8辆EV)的位置和道路类型的10个维度。在$A$中有五个动作。分别是车速保持、加速、减速、右侧变道和左侧变道。模拟初始状态$s_0$如图11所示,在5车道的中间车道上,HV周围有3辆电动车。仿真持续时间$T$为1500,演示次数为500。
接下来,实现了三种类型的最大熵逆强化学习,算法4是传统的最大熵逆强化学习,算法5和6是提出的最大熵逆强化学习的方法。不同的是分割$$Delta T$的持续时间。结果如表2所示。
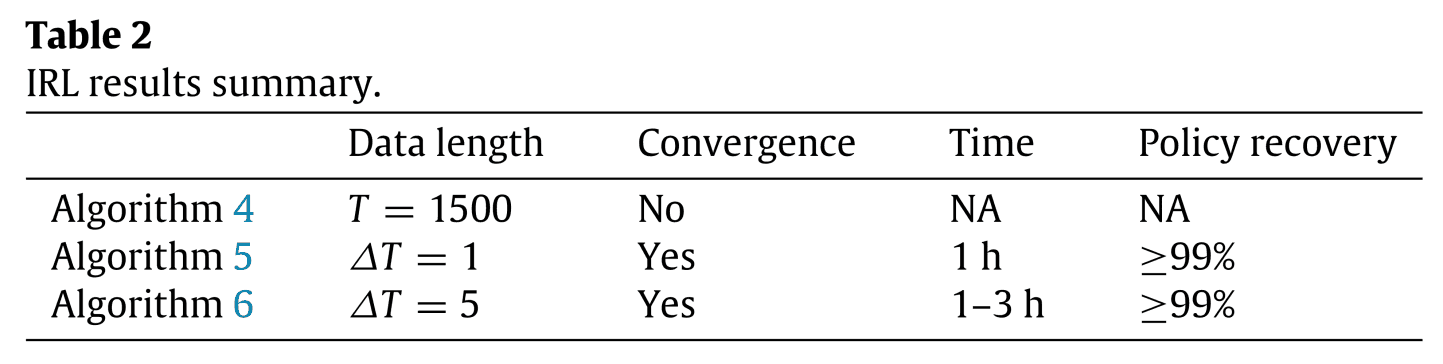
表2显示,传统的方法,即算法4,并没有收敛。这是由于系统的数据长度较长和概率行为。所提出的算法5和6收敛,但计算时间比算法6短,因为算法5没有计算状态动作对的访问次数的期望值,因为$/Delta T =1$。
还在模拟中实现了学习措施${\hat\pi}_1^*$(超车)和${\hat\pi}_2^*$(跟随)。由于${\hat\pi}_1^*$与$\pi_1^*$相同,所以与图10相同。图12.显示了${\hat\pi}_2^*$,如图12所示。
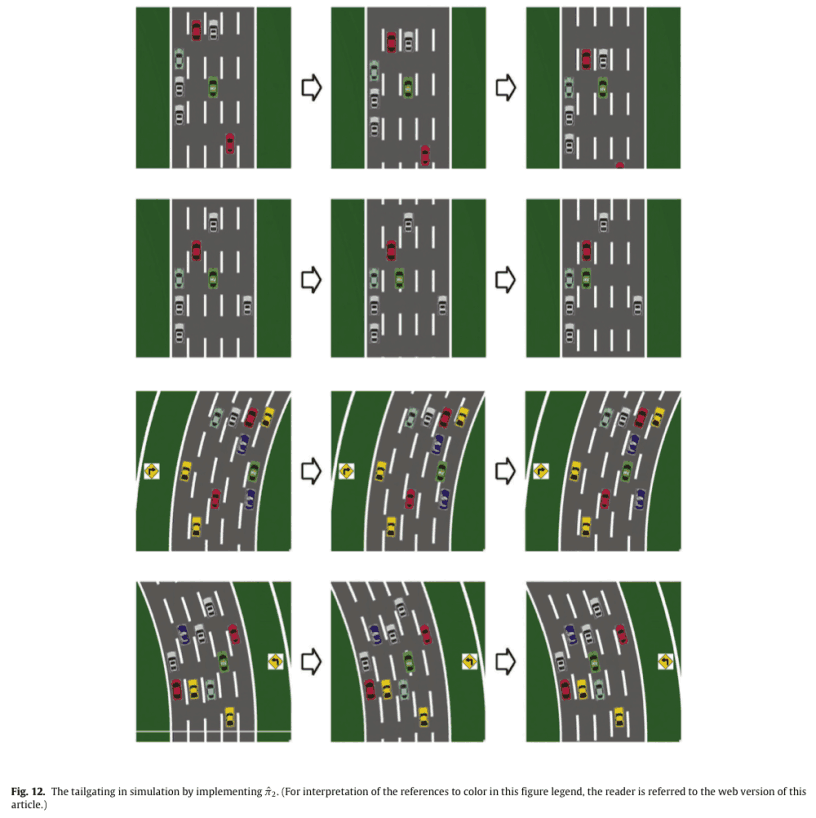
第一条线是在HV前面有空间的情况下,HV通过变道无法跟上电动车,所以它加速填补前面的空间。
第二条线是HV向左变道跟随的情况。
第三条线与第二条线类似,但却是拐弯抹角的情况。
在4号线中,HV可以通过两侧变道的方式沿道路左侧行驶,但它更喜欢沿曲线左侧行驶。
这些动作与设计权重$w_2$时所针对的动作是一致的,可以说,他们已经成功地从度量$w_2$中得到了度量。
结论:
采用随机马尔科夫决策过程对交通进行建模和强化,并采用逆强化学习来实现预期的驾驶行为。状态和MDP交通模型定义灵活,可以为任意数量的车道和任意数量的电动汽车建立交通模型。考虑到驾驶策略可能会随着道路上的弯道而改变。虽然状态定义很容易扩展,并有效地解决了MDP问题,但该模型并没有区分不同的车速或车辆类型,而是将每辆车作为一个质量点。要将本文的结果用于现实世界的场景中,还需要做更多的工作。例如,根据交通中的(相对)速度动态改变MDP状态的大小。通过对驾驶员奖励函数的设计,我们可以利用Q-learning学习相应的最优策略,并展示典型的驾驶行为,如超车和跟车。
为了从数据中恢复措施和奖励函数,我们提出了一种新的基于最大熵原理的无模型逆强化学习方法。现有的方法大多是$R(s)$,但我们使用了$R(s,a)$,它可以设计出更多样化的运气行为。它是最大熵逆强化学习的第一个泛化,具有任意参数化的连续可微分函数近似(DNNs)。
我们已经表明,当概率系统的知识有限时,很难使用长演示进行IRL。
错误的产生主要有两个因素。
- 如果数据量不足以代表系统的随机行为
- 如果在无模型问题中,一个随机系统的预测误差随着时间的推移而积累并变得很大。
相比之下,他们对IRL算法进行了改进,将demo分成较短的数据片,并最大化数据片上的同期分布熵。
通过模拟验证了所提出的方法。
摘要
未来的发展方向包括在高保真模拟或真实世界任务中引入部分观测MDP设计控制器,在不完全感知决策中引入部分观测MDP,以及利用CARLA等模拟应用本方法,引入多代理更好地控制交通流。如果能用上它,那就有意思了。在驾驶中也需要处理不完美的感知,因为据说它是存在的。虽然本文不是端到端的驾驶方法,但新的MDP是非常有吸引力的,因为它可以扩展。如果它能作为其他端到端方法的规划辅助,可能有助于防止事故和缓解交通拥堵。虽然在现实世界的任务中使用这种方法可能会很困难,但如果能像导航命令一样使用它,并将其与控制结合起来,那就很有意思了。
参考文献
1]尤长喜,陆剑波,Dimitar Filev,Panagiotis Tsiotras."Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning."Robotics and Autonomous Systems 114(2019):1-18.
[2]E.T.Jaynes,"Information theory and statistical mechanics",Phys.Rev.106(4)(1957)620-630.



与本文相关的类别




