能区分机器和人类吗?深入探讨文本生成模型和自动生成文本检测技术的现状!
三个要点
✔️什么是文本生成模型/自动生成文本检测器?
✔️讲解了文本生成模型的具体实例和技术。
✔️讲解了自动生成文本检测器的具体实例和技术。
Automatic Detection of Machine Generated Text: A Critical Survey
written by Ganesh Jawahar, Muhammad Abdul-Mageed, Laks V.S. Lakshmanan
(Submitted on 12 Nov 2020)
Comments: Accepted at The 28th International Conference on Computational Linguistics (COLING), 2020
Subjects: Computation and Language (cs.CL); Artificial Intelligence (cs.AI)


介绍
文本生成模型(TGM)的大幅发展也导致其被滥用的风险增加。
例如,GPT-2模型一开始并没有被披露,因为它有可能被用于制造假新闻。为了阻止这种滥用,重要的是要有一种技术,能够区分机械生成的文本和人类编写的文本。
本文对文本生成模型和自动生成句子(或文本)的检测进行了全面的描述。
目录
1.什么是文本生成模型(TGM)
1.1.学习TGM
1.2.通过TGM生成文本
1.2.1.决策。
Argumentative Decoding
- Greedy Search
- Beam Search
1.2.2.2.概率解码 xml-ph-0157@。deepl.internal - 无限采样
- Top-k采样
- 核采样
1.3.TGM的?社会影响
2.文本生成模型(TGM)的具体实例
2.1.主TGM
2.2.可控TGM(控制生成的句子)xml-ph-0050@deepl.内部2.2.1.控制令牌
2.2.2.使用属性分类器。
3.自动生成文検出器
3.1.从头开始训练的分类器
3.1.1.Bag-of-words分类器
3.1.2.检测机器配置
3.2.零射分类器
3.2.1.总对数概率
3.2.2.巨型语言模型测试室(GLTR)工具
3.3.微调 NLM
⑶.1.GROVER 探测器
⑶.2.RoBERTa 探测器
⑷.人机协作
⑶.4.1.人机探测器的差异
⑶.4.2.支持未经训练的人类
⑶.4.3.Real or Fake Text(RoFT)工具。
4. 最先进探测器的挑战
1.什么是文本生成模型(TGM)
1.1.学习TGM
一个典型的TGM是一个神经语言模型(NLM),它已经被训练成给定前一个文本的下一个token的概率模型。
例如,给定"我"、"玩"字作为输入,它就会预测它后面的字("棒球"、"足球"等)的概率。可以在$p_theta(x_t|x_1,...,x_i,...中找到。,x_i,...,x_{t_1})$。那么对于标记性词汇$V$,$x_i∈V$。让文本用$x=(x_1,...,x_{t_1}表示。,x_{|x|})$,则$p_\theta$通常用$p_\prod(x)=\prod^{|x|}_{t=1}p_\theta(x_t|x_1,...)表示。,x_{t-1})$是$p_{t-1}的形式。
在这种情况下,$p_theta$被训练成最小化以下损失函数。$L(p_\theta,D)=-\sum^{|D|}_{j=1}\sum^{|x^{(j)}|}_{t=1}logp_\theta(x^{(j)}_t|x^{(j)}_1,...,x^{(j)}_i,...,x^{(j)}_{t-1})$。在这种情况下,$D$代表来自$p_*(x)$的有限文本集,它代表参考分布。
1.2.通过TGM生成文本
给定文本的第一部分$x_{1:k} ~ p*$,文本生成任务预测给定文本的延续,由$p_\theta$预测$\hat{x}_{k+1} ~ p_\theta(.|x_{1:k})$。然后将得到的文本$(x_1,...,x_k,\hat{x}_{k+1},...,\hat{x}_N)$预测为从$p_*$的目标增加样本的相似度。
例如,当给定一个标题时,可以训练新闻文章生成任务来生成文章的正文。故事生成任务也可以从头生成故事的其他部分。
在这种情况下,使用近似的确定性或随机性解码来生成文本$/{x}_{k+1}$的延续。
1.2.1.确定性解码。
贪婪的搜索
在贪婪搜索中,在每个时间步骤中选择预测概率最高的令牌。也就是说,$x_t=arg max p_\theta(x_t|x_1,...),x_{t-1})$。在这种情况下,时间复杂度为$O((N-k)|V|)$。
光束搜索
波束搜索不同于贪婪搜索,它以高概率存储前$b$的候选人。根据这些候选者,它预测下一个时间步的代币,并再次存储前$b$的候选者。这个时间复杂度为$O((N-k)b|V|)$。
确定性解码往往会重复生成相同的单词和通用的(在各种语境中都可以接受)文本。
1.2.2.概率解码
概率解码包括在每个时间步长从预测的概率分布中采样。
无限取样
非限制性抽样直接从预测的概率分布中抽取代币。虽然这是最简单的方法,但它更有可能对预测概率低的代币进行抽样(很可能不合适)。
top-k采样
为了避免无限制抽样出现的问题,将抽样的tokens数量限制在前k个。在这种情况下,k的合适值取决于上下文,例如,如果我们预测的是名词(大词汇量),它可能需要设置得更高,如果我们预测的是介词(小词汇量),则需要设置得更低。
核(top-p)取样
我们将标记限制在那些预测概率大于或等于阈值$p$的标记上进行采样。换句话说,只有$p_theta(x|x_1,...)。,x_{t-1})≥p$,这样只有那些$x$与$p$有资格进行抽样。概率解码有一种倾向,即产生不现实的(如含有大量不一致的)语句。
1.3. TGM的社会影响:
TGM可以被利用来产生假新闻、产品评论、垃圾邮件/钓鱼等。用户可能不一定能正确识别这些假新闻文章和评论/评论。因此,为了防止TGM的滥用,我们需要建立一个能够区分人类写作和自动生成的文本的模型。
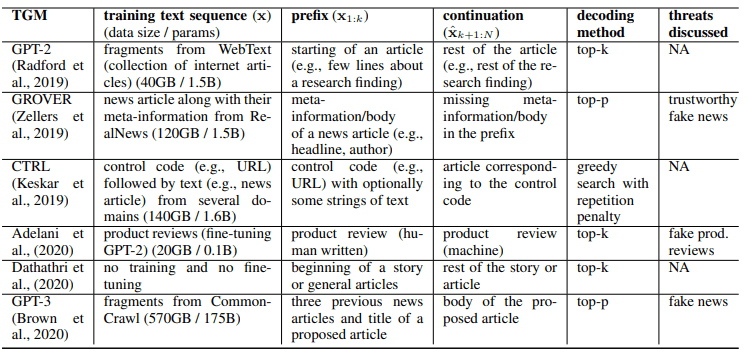
2.文本生成模型(TGM)示例
2.1.主要的专题讨论小组
主要的 TGM 如下
2.2.可控TGM
例如,一些TGM允许你控制文章的主题和情绪(正面或负面评论)。在某些情况下,这类信息可能由给定的文本控制,如GPT-2或GPT-3,但可能难以详细控制生成的文本。为此,我们设计了以下方法来明确控制生成的句子。
2.2.1.控制令牌:
在训练TGM的阶段,你把新闻文章的作者、创建日期、来源域名等元信息作为令牌输入。训练完成后,你可以控制输入这种元信息生成的文本。
例如,GROVER可以生成难以识别为人类撰写的假新闻的新闻文章。CTRL还允许明确控制控制令牌生成的文本的某些属性(例如,指定要生成的文章主题)。如:指定要生成的文章主题。
在使用控制令牌时,需要在培训时引入这样的机制。这就很难使用公开的预训练模型(如GPT-2)(由于学习成本高)。
2.2.2.使用属性分类器
相反,通过将GPT-2等TGM生成的句子与一些属性分类器(如情感分类、话题分类等)相结合,可以调整模型,生成包含特定属性的文本。在这种方法中,前期的训练模型不需要再次训练,因此可以低成本地控制生成的句子。
3.自动生成句子检测器
为了区分TGM生成的文本和人类书写的文本,已经设计了各种检测器。将介绍这种探测器的一些主要研究实例。
3.1.从头开始训练的分类器
在这里,我们来看看一个从头开始训练的分类器(≈从头开始)。
3.1.1.词袋式分类器
一个使用逻辑回归模型和tf-idf的简单模型可以区分WebText中的文本和GPT-2生成的文本。这是检测器中最简单的方法之一。本研究测试了不同数量的参数(117M、345M、762M和1542M)和采样技术(纯采样、top-k采样和top-p采样)的检测精度的变化。
结果我们发现,参数数量越多,检测难度越大,核采样比顶k采样更难检测。(这可能是由于top-k抽样产生的词比较常见,词频的分布与人类有很大的不同)。还发现,GPT-2的微调使其更难检测。
3.2.2.检测机器配置。
本研究不是将人类书写的文本和自动生成的句子划分为二进制,而是确定是什么模型生成的文本(如解码方法、模型中的参数数量等)。
结果表明,模型构成是可预测的(与随机情况相比),概率很高。(这项任务也被证明不像分辨人类句子和自动生成的句子那样困难)。这表明,自动生成的句子对模型构成有很强的依赖性。
此外,单词的顺序在分类中并没有发挥太大的作用,使用bag-of-words(表示一个单词在句子中的出现次数)的检测器和复杂的检测器(如Transformer)一样表现良好。
另一项研究表明,经典的机器学习模型和简单的神经网络在以下三种环境下有一定的作用。
(1)对两篇文章是否由同一TGM产生进行分类。
(2)该条产生于哪种TGM分类。
(3)人写和自动生成的文本分类(目标任务)
但是,对于(3),我们根据几个TGM(CTRL、GPT-1、GPT-2、GROVER、XLLM、XLNet、PPLM和FAIR)进行验证,发现GPT-2的原始文本很难被检测出来。
3.2.零点分级器
在本节中,我们将讨论使用预训练模型(GPT-2、GLOVER等)的零射分类案例。在这种情况下,用于文本生成的模型和用于自动生成句子检测的模型可能相同或不同。在这种设置下,自动句子检测不需要监督数据。
3.2.1.总对数概率
作为一个简单的例子,我们使用TGM来评估对数似然。它将给定文本的对数可能性与人类编写的文本和TGM生成的文本的对数可能性的平均值进行比较,并根据哪个更接近进行预测。与上述简单的逻辑回归模型相比,这种分类器的性能很差。
3.2.2.巨型语言模型测试室(GLTR)工具
一种被称为GLTR工具的技术利用GPT-2生成的文本和人类编写的文本的分布差异来进行分类。在使用TGM生成文本时,根据top-k采样、核采样等方式依次生成下一时间步的令牌。现在,给定一个文本,使用一些TGM根据文本的前k个token来预测下一个token的概率分布。如果文本是一个TGM生成的句子,我们希望预测的下一个标记的分布与给定文本的实际下一个标记更相关。此外,由顶k和核抽样生成的文本往往具有较低的异常词频率。
基于这些思想,根据词的出现率、词在预测分布中的等级和熵进行分类。
画面如下图所示。

在此图中,实际下一个令牌相对于预测下一个令牌的概率分布的顺序以颜色显示。上图为人文本,下图为GPT-2大(温度=0.7)生成的文本。可以看出,分布中很多等级高的token出现在自动生成的文本中,凸显了两种文本的差异。
3.3.微调NLM;
在这里,我们正在对一个预先训练好的模型进行微调,以进行自动句子检测。与零射一样,用于文本生成的模型和用于自动生成句子检测的模型可能相同或不同。
3.3.1.GROVER检测器
在本研究中,我们在GROVER模型的基础上增加了一个线性分类器,即TGM,并对其进行了微调,以进行自动句子检测。
我们在实验中发现,当用于生成文本的模型和用于检测自动生成句子的模型相同时,检测精度较好。不过,有可能实验验证的模型刚好呈现出这样的趋势。
3.3.2.RoBERTa探测器
在这项研究中,我们对RoBERTa进行了微调,并成功识别了由GPT-2生成的网页,参数数量最多,准确率约为95%,展示了最先进的性能。
当对核心采样产生的例子进行训练时,其他解码方法(top-k和无限制采样)也是有效的。研究还表明,在大型GPT-2上训练的检测器能够充分检测小型GPT-2生成的句子。(但是,在相反的情况下,大GPT-2生成的句子的检测精度会降低)。
此外,与上述GROVER研究不同的是,RoBERTa模型微调时比GPT-2模型微调时更准确。(这可归因于RoBERTa的双向性)。
另一项研究显示,在对人类撰写的和自动生成的推文进行分类时,表现出最先进的性能,远远超过经典的机器学习模型、神经网络(RNNs和CNNs)等。虽然RoBERTa的预训练并不包括Twitter数据,但它展示了RoBERTa在这种预训练中没有看到的数据上表现良好的潜力。
3.4.人机协作
与其使用全自动检测器,不如考虑采用人工和机械相结合的决策方式。下面介绍基于这些尝试的一些研究。
3.4.1.人机检测器的区别
研究表明,人类的判断能力和机械探测器的以下能力存在差异。
(1)人类评价者更善于发现自动生成的句子中的不一致和意义错误(如不连贯)。自动检测器不善于做出这些判断,因为它们理解意义的能力不如人类。
(2)如果自动生成的句子中存在词偏(在top-k采样中看到的趋势),自动检测器可以做出正确的决定,但人工评价很难发现这些问题。
如果我们要把人和机器结合起来进行自动句子检测,了解这些能力上的差异将是非常重要的。
3.4.2.支持未经训练的人类。
我们前面讨论过的GLTR工具,可以通过将文本的特征可视化,帮助人类做出决策。这种协助可以提高人类在没有经过特殊训练的情况下做出决策的准确性。(54%至72%)但是,GLTR往往偏向于判断一个句子是自动生成的,很难确定它不是自动生成的句子。
这种偏见导致人类和机器需要"合作",因为人类评价者有可能被机械的决策所吸引。
3.4.2.真假文本(RoFT)工具(论文、网站)。
RoFT工具是一种评估人类对自动生成句子检测决策能力的方法。人工评价器需要检测人写的句子和自动生成的句子之间的界限。
具体来说,就是依次给出一系列的句子,最初是由人写的,然后中途由自动生成的句子组成。如果用户确定该句子还没有切换到自动生成,则给出下一句话。如果用户决定改用自动生成的句子,用户必须提供理由。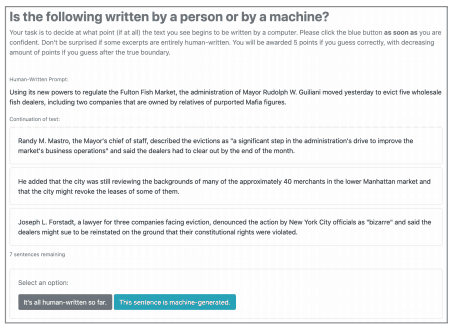
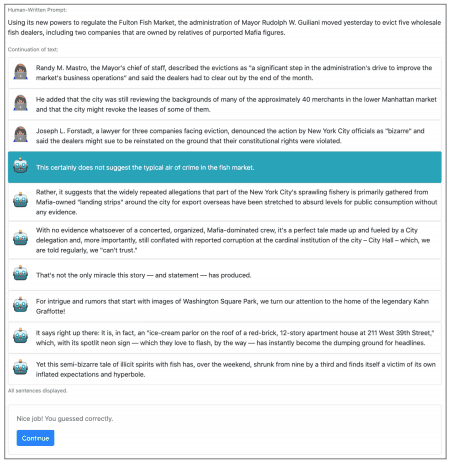
重复这个过程,并对其进行评估,看评估者是否能区分人写的句子和自动生成的句子之间的界限。RoFT工具其实在这个页面上就可以找到。
提醒一下,可能会有偏差,比如呈现给用户的人工编写的文字比自动生成的文字多。
4. 最先进探测器的挑战
在这里,我们描述了使用RoBERTa模型的最先进探测器的挑战。本研究研究了由GPT-2生成的人类撰写的亚马逊产品评论和文本的检测任务。我们随机调查了100个检测器未能正确判断的假阳性案例(即当自动生成的文本被确定为人类所写时),其中包括以下几种。
- 流利(包括人类难以辨别的罕见的流利事例)。
- 短暂
- 不属实(如影评中演员的名字不同)。
- 不相关的内容(如乐评中出现与音乐无关的字眼)
- 包含矛盾(A喜欢B但不喜欢B等)。
- 包括重复(A是伟大的,A也是伟大的等)。
- 包括一些不符合常理的事件。
- 错别字和语法错误。
- 内容不一致。
因此,我们了解到,即使是最先进的探测器,仍然有一些问题需要解决,比如无法确定人类在一定程度上可以确定的事项。
摘要
本文介绍了文本生成模型(TGM)和自动文本检测技术的现状。随着GPT-2和GPT-3等文本生成技术的发展,滥用TGM的危险性越来越大。因此,防止这种高级TGM滥用的检测技术在未来将变得越来越重要。
希望本文能为对这一研究领域感兴趣的朋友提供有益的知识。



与本文相关的类别





