
BILCO用于准确和快速地调整时间序列数据之间的时间间隙。
三个要点
✔️ NeurIPS 2022年接受的论文,BILCO在序列之间存在时间偏移时对时间序列数据进行对齐
✔️ 传统的联合对齐方法准确但计算成本高,没有得到广泛使用
✔️ 巧妙的初始化和双向的推进策略,将原始问题转化为两个较小的子问题,从而使平均速度提高20倍
BILCO: An Efficient Algorithm for Joint Alignment of Time Series
written by Xuelong Mi, Mengfan Wang, Alex Bo-Yuan Chen, Jing-Xuan Lim, Yizhi Wang, Misha Ahrens, Guoqiang Yu
(Submitted on 01 Nov 2022)
Comments: NeurIPS 2022 Accept
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
这是一篇NeurIPS 2022年接受的论文。在处理时间序列数据时,多个时间序列数据之间会发生时间点偏移,而对齐是数据分析中的基本预处理步骤之一。传统的成对排列方法已经被使用,但这些时间序列数据往往是相互依赖的,不能很好地利用这些信息,给排列任务带来额外的信息。最近,联合排列被建模为一个最大流量问题,在这个问题上,排列的时间序列之间的轮廓相似性和相邻的翘曲函数之间的距离都被共同优化。然而,尽管其优雅的数学表述和出色的对齐精度,这种使用现有通用最大流算法的新模型具有显著的计算时间和内存使用量,这是对其广泛采用的主要限制。本文提出了BIdirectional pushing with Linear Component Operations(BILCO),这是一种高效、准确地解决联合排列最大流问题的新算法。在这里,开发了一种线性组件操作的策略,该策略整合了动态编程和推送标签的方法。该策略的动机是,联合排列最大流量问题是动态时间扭曲(DTW)的概括,其中嵌入了许多单独的DTW问题。此外,利用另一个事实,即良好的初始化可以很容易地计算出联合排列最大流量问题,提出了一个双向推送策略,以引入先验知识并减少不必要的计算。
对BILCO的可证明性进行了验证,使用了合成和真实世界的实验,并在各种模拟场景和三种不同的应用类别中的数千个数据集上进行了测试,结果显示,与现有最好的maxflow方法相比,BILCO始终实现了至少10倍,平均20倍的速度并且与现有的最佳maxflow方法相比,BILCO始终实现了内存使用量的1/8和平均1/10的加速。
介绍。
时间序列数据自然地出现在许多领域,如运动捕捉、语音识别和生物信息学。通常,由于可能的延迟和失真,时间序列数据不能简单地在数据序列或时间点之间直接比较,所以数据之间的对齐是一个必不可少的预处理步骤。最常见的对齐方法,动态时间失真(DTW),使用动态编程(DP)在线性时间内找到两个序列的最佳匹配。然而,DTW及其变种只比较单一时间序列的配对,而不利用真实数据中包含的结构信息。例如,在延时显微镜数据中,像素强度被记录在一个二维网格上,相邻的像素往往具有类似的时间模式。因此,多于一对的联合排列有望通过利用结构上的依赖关系来实现更好的性能。
长期以来,人们并不清楚如何在原则上纳入结构信息,但最近开发了各种启发式的技巧。在最近的一个理论突破中,联合排列问题被优雅地建模为图形时间扭曲(GTW)图的最大流问题,通过优化时间序列的成对相似性和扭曲函数之间的距离,GTW已被用于大脑活动分析和液相色谱-质谱(LC-MS)蛋白质组学,并在许多应用中被证明有很好的排列精度,其中翘曲函数代表每个时间点的真实信号相对于参考时间序列的延迟,相邻的时间序列应该相似地传播。通过对翘曲函数的不相似性增加惩罚,GTW可以利用结构信息获得更好的对齐性能,如图1(e)和(f)所示。然而,GTW是用现有的通用最大流算法解决的,该算法计算时间长,内存占用大,限制了其广泛应用。事实上,在一个由5000个时间序列组成的典型数据集中,每个序列包含200个时间点,增量广度优先搜索(IBFS),Hochbaum的伪流(HPF),Boykov-Kolmogorov(BK)的最大流,最高标签的推重标签(HIPR)等,所有常见的方法都会消耗几个小时和超过100G的内存。
在本文中,我们确定了联合对齐最大流量问题的两个重要属性,并表明可以利用它们来设计速度和内存效率都得到改善的新算法。具体来说,首先,联合对齐是成对对齐的概括,其中嵌入了许多单独的DTW问题,如图1(a)-(d)所示。如果忽略依赖关系,该问题就会减少为几个独立的DTW问题,这些问题可以通过DP在线性时间内解决。虽然依赖关系使问题更加复杂,但可以利用DTW问题的特性。第二,对于许多应用来说,联合排列的粗略近似解可以很容易地估计出来。这样的先验知识可以被纳入,以加速最大流量算法。
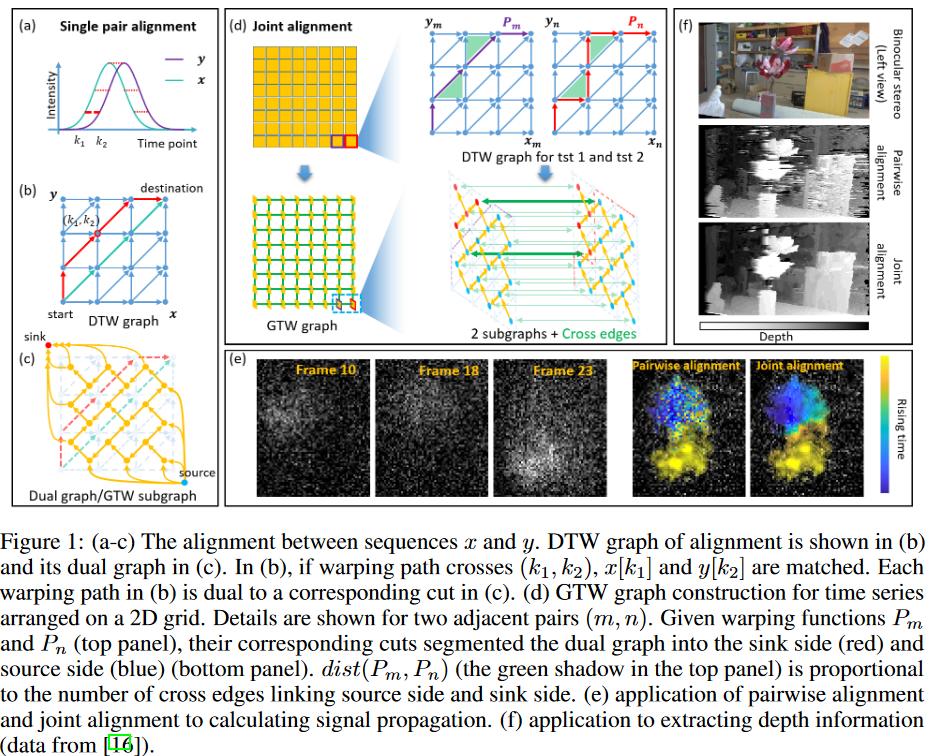
利用这两个特性,本文开发了一种新的算法--BIdirectional pushing with Linear Component Operations (BILCO),它能准确和更有效地解决联合排列最大流量问题。该算法由两个主要策略组成:
(a) 用线性分量运算的超额推演(ELCO),它利用了第一个属性,并整合了DP和推演的方法。
每个组件被定义为一个小的子图,包含连接的节点和它们相关的边。组件是自动和自适应确定的;通过结合DP和子图的特性,我们表明对每个组件的所有操作都可以在线性时间内实现。与常见的推重法相比,线性组件操作使ELCO达到更高的效率。
(b) 设计一个双向推送策略,利用第二个属性,并使用先前的知识作为初始化。
这种策略将原始问题简化为两个较小的子问题,其推送方向相反。在每个问题中,ELCO都被应用,但两个推送方向的分离大大减少了不必要的计算。
BILCO的理论时间复杂度与HIPR等最佳通用方法相同,但在联合对齐任务中,在不牺牲精度的情况下,提供了显著的经验效率提升。它的有效性已经通过合成和真实世界的实验得到了证明:与IBFS、HPF、BK和HIPR以及来自不同模拟场景和三个不同类别的真实应用的数千个数据集相比,BILCO显示出10-50倍的速度,而且内存成本平均为十分之一。
问题描述
时间序列条款对齐问题可以表述为:。
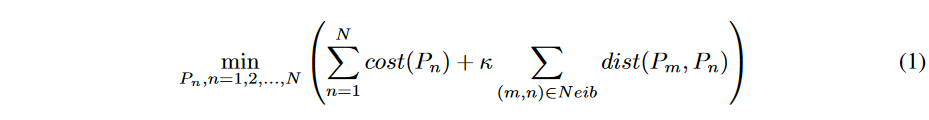
其中,Pn表示第n个时间序列对的翘曲路径,N是要共同对齐的时间序列对的总数,cost(Pn)是第n个时间序列对的对齐成本,dist(Pm,Pn)是翘曲路径距离,定义为Pm和Pn所包围的区域面积。是代表相邻时间序列的一对索引(m, n)的集合,κ是一个超参数,用于平衡对齐成本项和距离项。例如,对于二维网格时间序列数据,Neib包含相邻像素对,κ代表像素间的先验相似度。
如图1所示,方程(1)可以通过将其转化为流动网络并找到其最小切口来解决。所构建的图,即动态时间失真法GTW图,由N个GTW子图组成{Gn = (V n, En)|n = 1, 2, ., N }和一条容量为κ2的交叉边Ecross(图1(d));GTW子图中的一条边被称为Ewithin。在下面的内容中,为方便起见,"GTW子图 "将被表示为 "子图"。每个子图Gn都是DTW图的对偶,它代表一对时间序列之间的翘曲。由于子图中的切口与一对时间序列的翘曲路径相对应(图1(b)-(c)),一个DTW图中的小切口可以通过使用动态编程(DP)找到最短路径在线性时间内解决。交叉边制约着相邻子图的切割之间的差异,并对应于方程(1)中的距离项(图1(d))。为了保证翘曲路径的单调性和连续性,每个子图的逆向边的容量被设置为无穷大。
值得注意的是,GTW框架是灵活和广泛适用的,在利用结构信息的同时,可以作为一个构件来解决许多问题。假设的邻域结构和相似性强度可以是特定的应用或用户设计的。例如,对于不同的翘曲函数对,GTW可以设置不同的超参数κ。为了简单起见,本文对所有的翘曲函数对使用相同的超参数κ。
技术
BILCO包含两个主要部分,分别是ELCO和双向推送,如上所述。基于翘曲函数的初始化,双向推送策略将最大流量问题转化为两个子问题,每个子问题都用ELCO解决。这种整合导致了BILCO,然后对它的时间复杂性和内存使用情况进行分析。
线性成分操作的超额推力(ELCO)
由于GTW图包含许多与DTW图对偶的子图,并且每个DTW图都可以通过DP线性求解,我们期望本文的方法能够利用DTW图和DP算法。虽然图之间的交叉边不允许直接使用DP,但我们发现,定义的组件是允许使用DP的最大子图。通过将新设计的图形转换策略(图3)与DP相结合,我们确定了在定义组件上的 "排水 "和 "放水 "操作确实可以线性地实现。为了保证全局最优,我们设计了一个新的标记函数,如第3.1.4节所示,它被用来指导组件上的操作。
操作的基本单位不是一个节点或子图,而是一个组件
为了利用每个子图的特性,ELCO借用了一般推标签算法的思想,其操作是本地化的;ELCO允许存在盈余,即单个节点的入流和出流之间的盈余。 有盈余的节点被认为是 "活跃 "的。根据流量交换的位置,定义了两种操作:"排水 "和 "放水"。"Drain "是一个将盈余通过Ewithin推到汇的操作,是子图内的一个操作。另一方面,"Discharge "是一个跨子图的操作,它通过Ecross将剩余部分推到邻近的子图。通过交替进行这两个操作,更多的盈余可以被送到汇中(图2)。随着盈余的扩散,许多边变得饱和,导致同一子图中出现多个切割。这些切口将子图划分为不同的组成部分(图2(e))。在这里,一个组件被定义为GTW子图的一个子集,由两个相邻的切口约束;ELCO使用组件作为操作的基本单位,而不是节点和子图。这是因为在使用DP推送流量时,组件是最大的单位。
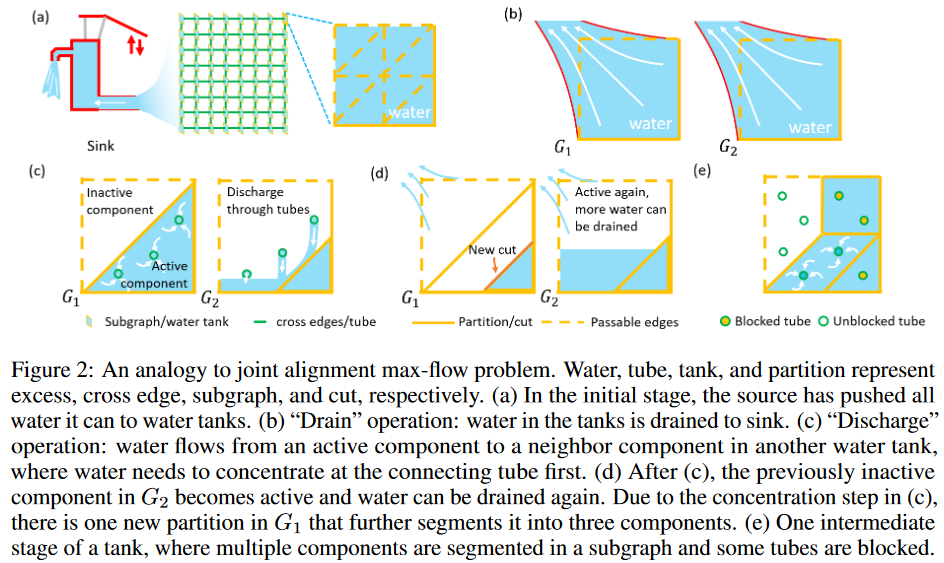
* 补充问题1。
如果两个节点在同一个组件中,至少有一条路径连接它们。
通过互补1,如果一个组件中的一个节点是活跃的,它的盈余可以扩散到同一组件的任何地方。因此,整个组件可以被看作是一个单一的单元。反之,切割会中断同一子图中各组件之间的流动,因此整个子图不能被看作是一个单一的单元。
以组件为基本操作单位,ELCO的描述如下。最初,每个子图都是一个活动组件。Drain "操作通过Ewithin将最大的剩余部分直接发送到水槽。一个新的切割产生了,靠近源的被分割的组件的盈余被阻断了。接下来轮到放电了,它寻找机会将剩余的部分从子图中移到可以执行 "排水 "的组件上。通过交替进行这两个组件的操作,可以实现全局最大流量。
-排水 "组件操作的线性时间实现。
对于 "排水 "操作,只需计算与水槽相连的一个有源元件的最小切口,所有高于新切口的剩余部分都被排掉,低于新切口的部分被确定为新的有源元件(图2(b)(c)))。如上所述,最小切割可以通过DP在其对偶图上快速解决。然而,DP不能直接应用于Ecross上的流动。该图不再是平面的(图3(a)和(b)),其对偶图也不存在。因此,我们设计了一个线性时间图转换策略(见附录中的算法),如图3所示,将Ecross上的已知流量带入Ewithin,得到一个等价的平面图,DP仍然可以应用于此。通过将线性转换策略与DP相结合,"排水 "部分的操作可以在线性时间内实现。
* 补编2。
图形转换前后对应的切割值/路径成本是相同的
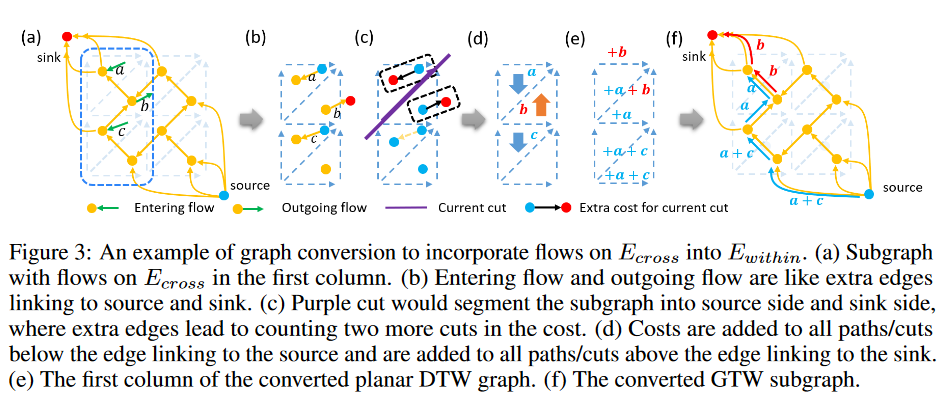
排放 "组件行为的线性时间实现。
为了排出一个组件,在每个节点上尽可能多地推出盈余,并确保该组件已发出所有盈余。这是因为盈余可以在同一组件内的任何地方流动。
* 补充问题3。
当v是汇的时候,节点v的最大可能超限是残图的最小切割值
使用修改过的DTW图,DP可以通过找到v下面的最短路径和整个图的最短路径之间的差异来计算这样的过剩。这个差值可以代表补充3中描述的min-cut的值。为了实现线性复杂度部分的 "放电 "操作,这里使用了DP的另一层,它重用了一个递归存储最短距离的保守动态矩阵。
新的标示功能,引导多余的物品接近组件之间的水槽。
本文设计了一个新的标签函数,以推导出组件之间从高标签到低标签的过度接近度t。与常见的push-relabel不同,这里的标签函数指的是组件到汇的距离,而不是节点的距离。只有Ecrosses被计算在内,因为切口切断了同一子图的组件之间的连接。从这种距离推导出的标记函数d:V→N被定义为对所有残余边有效,如果
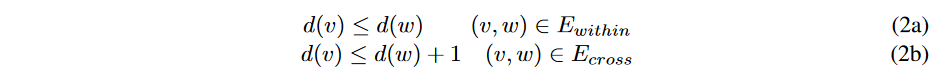
* 补充问题4。
同一组件的所有节点具有相同的标签
* 补充标题5。
如果把每个成分作为一个单一的单位,新的标记函数(2)与一般的推重标记函数是一致的
补充4表明,可以为一个组件和其中的所有节点设置相同的标签。补遗5还表明,ELCO可以被看作是另一种推式标签法,其中组件是操作单位,一般推式标签法的所有陈述在组件层面也是成立的。由于在ELCO中保留了标签函数的有效性,最优解可以通过多项式的组件操作来实现。
ELCO在Algo.1和Algo.2中概述,其中R是组件R1→R2的符号,如果(v,w)在v∈R1和w∈R2中具有正的剩余容量,则应用最佳标签选择规则,全局和间隙重标启发法都被用于加速。利用全局和间隙重标启发法进行加速。


双向推动策略
典型的推标签方案和ELCOs试图将尽可能多的多余部分推到汇中。如果由于边缘容量的限制,一些多余的部分不能到达水槽,就必须由源头吸收,这可能需要很长的时间,并有很高的计算成本。这种计算是多余的,因为这种盈余不能影响最大流速或改变最终的切割,ELCO通过线性组件算术减少每个组件内的一些冗余,但解决组件之间的问题,特别是当κ大时(Ecross容量高)这是不可能的:当κ大时,Ewithin更有可能饱和,组件更有可能被分割成更小的组件。因此,只关注每个组件是很难减少冗余的。
作为一个极端的例子,考虑所有的节点根据切割被分割成源端VT的情况。在这种情况下,所有的盈余都可以到达汇合点,所有的推送操作都不是多余的。在另一种极端情况下,所有节点都属于源侧VS。大多数多余的东西不能到达水槽,但仍然被推送,导致冗余的计算。相反,从汇入地推送赤字比从源头推送多余部分是一个更好的策略。赤字意味着输入流量小于输出流量。推出赤字无非是在图形中用计算推出多余部分。如果你有先验的知识来找到翘曲路径的初始化,你可以简单地在汇的一侧推出多余的部分,在源的一侧推出赤字。在这之后,计算上的浪费就非常少了。考虑到这一点,我们决定设计一个双向推送策略(图4),其中源和汇被交换。由于所有的节点都被分割成VS,所有向相反方向推送赤字的操作都不是多余的。总之,在水槽边的VT上推送多余的部分,在源边的VS上推送不足的部分,不会使图失效。
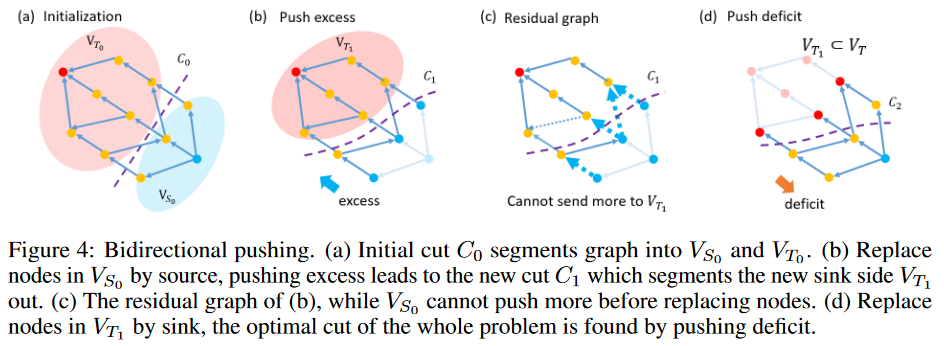
初始化:估计GTW图的初始切口C0。让相应的源侧和汇侧分别为VS0和VT0。
挤出多余部分:通过将VS0中的所有节点替换为源,并挤出多余部分来解决最大流量问题。让VT1成为新的水槽边除以新的小切口C1。
红色推动:用汇替换VT1中的所有节点,用红色推动解决最大流量问题。由此产生的微型切面C2是原始GTW图的一个微型切面。
该策略通过以下语句保证实现最优解
* 补编6。
假设minicut将节点V分割成源端VS和汇端VT,用源端或汇端替换VS或VT节点不会影响minicut。
* 补充标题7。
如果VT代表原GTW图的真正minicut被分割成的汇边节点,那么VT1⊆VT。
定理1。
在双向策略中得到的小切口就是原图中的小切口。
在联合排列问题中,更容易找到好的初始化,因为κ越大,相似性惩罚越大,所以最后的切割往往是相似的。
双向推送与线性分量算术
在小的κ下,组件通常很大,ELCO可以有效地工作。另一方面,当κ大时,不同子图的切割是相似的,初始解很容易被估计。因此,双向推送策略效果很好。通过将每个子图初始化为平均子图的最优翘曲路径(这也是无限κ的联合排列的解),BILCO能够同时兼顾这两个优点,在任何κ下都有良好的性能。该方法在实验中使用了这样的初始化并获得了良好的性能。因此,我们推荐将其作为BILCO的初始化,至少在类似的应用中。
复杂性
双向推动策略可以将原始问题转化为两个较小的子问题,这可能有助于加速任何最大流量方法。例如,在最好的情况下,初始化是准确的,问题可以被分割成两个一半大小的子问题。在这种情况下,O(|V|2p|E|)方法的速度几乎加快了三倍,因为V和E都减半。即使初始化不佳,这种策略也只是增加了操作的数量而不影响复杂度的限制。
ELCO就像是DTW(复杂度Θ(|V |))和HIPR(复杂度O(|V |2p|E|))的整合。一方面,Ecross有一个下限ω(|V|),使ELCO比DTW更复杂。另一方面,通过使用线性组件操作来进行过度推送,ELCO的操作单元比HIPR少,降低了复杂性。即使在最坏的情况下,每个组件只包含一个节点,ELCO也等同于HIPR,具有相同的上边界。因此,BILCO的最坏情况下的复杂度是O(|V|2p|E|)。
内存用量
BILCO还利用GTW图的结构来提高内存效率。在典型的最大流方法中,很大一部分内存被用来记录节点和边的关系;在BILCO中,图的结构是已知的,所以节点和边可以按坐标顺序存储,关系可以从它们的位置推导出来。在实际应用中,存储组件的成本并不高,因为与大的|V|和|E|相比,组件的数量可以忽略不计。 表1根据BILCO和对等方法的实现,比较了它们的内存使用情况。

实验
这里,BILCO的效率与四种同行的方法,即IBFS、HPF、BK和HIPR,在合成模拟和实际应用下进行了比较。所有实验均在MATLAB中进行,使用英特尔(R)至强(R)黄金6140@2.30Hz,128GB内存,Windows 10 64位和微软VC++编译器;没有使用GPU;所有实验均在MATLAB中进行。所有的方法都是使用MATLAB包装器在C/C++中实现的。
综合数据
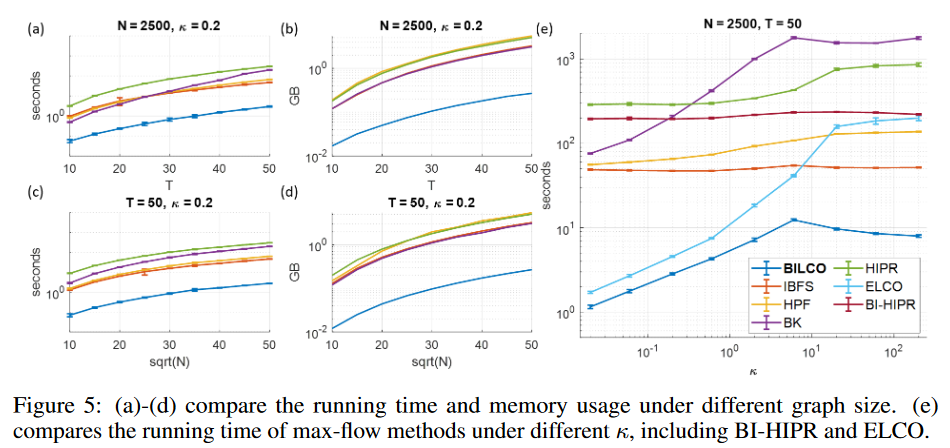
模拟的图像信号传播数据集,有不同的像素(N)和帧(T),使用4个连接的邻居,GTW图大约是 |V | = 2N T 2个节点和 |E | = 7N T 2条边。一个钟形信号从图像的中心向边界传播。加入高斯噪声,使信噪比达到10分贝,模仿现实生活中的场景。为了使超参数κ具有可比性,合成数据通过除以噪声的标准偏差而被归一化。
图5(a-d)比较了不同图形大小的BILCO和peer方法,显示BILCO方法比任何peer方法都快10倍以上,并且只花费1/10的内存成本。图5(e)显示了超参数κ的影响,比较了HIPR与双向推进策略(BI-HIPR)和ELCO方法。可以看出,随着Ecross容量的增加,大多数方法的执行时间随着κ的增加而增加,这是由于交换流的自由度增加和图的复杂性增加。在所有方法中,BILCO在任何κ下都显示出最高的效率。比较ELCO和BILCO或HIPR和BI-HIPR,可以看出双向推送策略加速了这两种方法,特别是在大κ下。这是因为随着κ的增加,默认的初始化越来越接近于最优解,有效地消除了不必要的计算。图5(e)还显示,ELCO和双向推动这两种策略是互补和协同的:当κ小的时候,ELCO在加速方面占主导地位;当κ大的时候,双向推动的影响更大;而当κ小的时候,ELCO的影响更大。有趣的是,当κ大时,这两种策略会协同提高速度。例如,在最大的κ下,BI-HIPR和ELCO都比HIPR快近4倍,意味着独立效应的16倍提速,而BILCO比HIPR快约100倍。
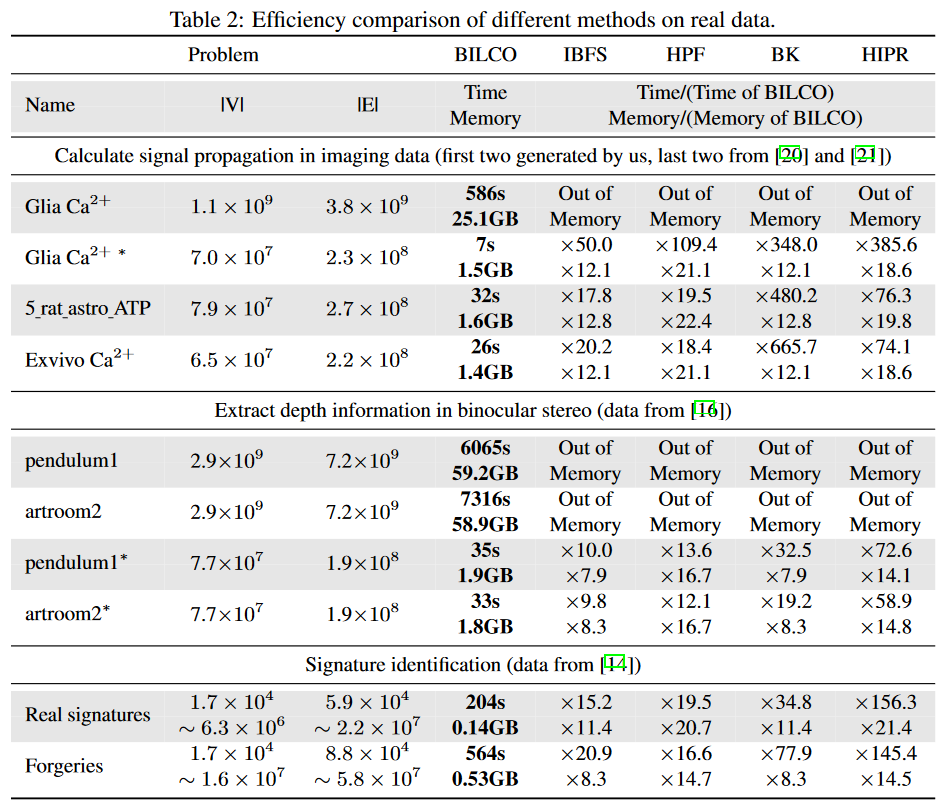
实时数据
在这里,我们将我们的方法BILCO与四个同行的方法在三个不同的应用类别中进行比较:信号传播计算、深度信息提取和签名识别。由于所有这些最大流量方法都给出了相同的结果,这里只比较执行时间和内存使用量,如表2所示。名称中的*代表空间降样数据,以BILCO为基线,其他的成本是多少倍 第二个应用实例允许从两幅图像之间同一行的错位中提取深度,但假设相邻行的深度分布相似.在这个实验中,窗口大小被设定为数组长度的1/5,以避免不必要的计算,同时允许相对较大的差异。第三个应用是识别20个签名,并将500个真实的签名和500个伪造的签名与参考签名进行比较。表中显示了两类签名的总执行时间和最大内存用量。可以看出,BILCO在所有这些联合对准的应用中始终表现最好:与最好的同行方法相比,BILCO显示出大约10-50倍的速度,需要几乎1/10的内存成本。特别是在需要估计信号传播的应用中,BILCO的表现比其他方法平均快29倍(范围在18-50)。考虑到这些应用是多样化的,而且依赖结构从深度方向的两个邻居、传播方向的四个邻居和签名方向的所有邻居都不相同,这有力地证明了BILCO的优越性和广泛的适用性。
结论。
与DTW相比,联合对齐利用了数据的依赖性,因此产生了更好的性能,但要牺牲速度和内存。在本文中,我们利用这个问题的特殊性,开发了BILCO算法,使这些牺牲最小化。该算法可以有效地解决联合排列的最大流量问题,并在不牺牲精度的情况下获得一个精确的全局最优解。除了理论分析外,通过综合实验和实际应用证明了BILCO的效率,表明与IBFS、HPF、BK和HIPR方法中最好的方法相比,BILCO大约快10-50倍,平均只需要1/10的内存成本。此外,在各种情况下的验证表明了BILCO的广泛适用性。预计这项研究将促进联合对准的应用,并在各个领域有更好的表现。
双向推送策略不仅可以被看作是一种通用的推送标记加速方法,而且被发现与BILCO的线性成分操作协同工作。通过双向推送策略,图形被分离,从而减少了不需要的过度和不足,减少了饱和的边缘和切口,以及更大的组件。由于组件较大时,操作的数量可以大大减少,与前述的HIPR相比,BILCO甚至比BI-HIPR(4×)和ELCO(4×)的乘法速度快(100×)。
BILCO算法是解决某些最大流量问题的特殊方法。最大流量算法的发明由来已久,但现有的方法,无论是基于路径扩展、局部操作如pushrelabel、两者的组合,还是图分解的整合但都不能有效地解决这个问题。据我们所知,本文是第一个整合DP和一般的push-relabel方法来解决最大流量问题的。在这个领域有一种普遍的感觉,即初始化对最大流量算法不是很有用,但在这里我们表明,双向推是利用初始化的一个很好的策略,当与线性分量操作相结合时,它特别强大。我们希望我们在这里的努力不仅有助于联合排列的应用,而且还能为特定网络流问题的方法学的发展提供刺激。虽然很难为经典问题发明更好的通用算法,但对于更多的专业问题,有很多机会,他们觉得由于最近问题的超大规模,确实有很大的需求。



与本文相关的类别






