
时间序列分析的新趋势:使用递增邻域法进行鲁棒性时间序列 "链 "的提取 TSC22
三个要点
✔️ 一种相对较新的在时间序列数据中寻找特征 "链 "的方法得到了有力的更新
✔️ 该算法能准确地在变化的数据中找到 "链",并且对噪声具有鲁棒性
✔️ 对真实世界数据的定性评价和对合成数据的定量评价已经卓越的性能已经得到证实。
Robust Time Series Chain Discovery with Incremental Nearest Neighbors
written by Li Zhang, Yan Zhu, Yifeng Gao, Jessica Lin
(Submitted on 3 Nov 2022)
Comments: ICDM 2022
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
摘要
对时间序列数据进行分析和建模的方法很多,这里介绍的时间序列链(TSC)是其中比较新的方法。
发现时间序列主题一直是识别时间序列数据中有意义的重复模式的一个基本挑战。最近,时间序列链作为时间序列主题的延伸被引入,用于识别时间序列数据中连续演变的模式。非正式地,时间序列链(TSC)是一个时间上有序的时间序列子句的集合,其中每个子句与之前的子句相似,但最后一个和第一个子句可以任意地不相似。TSC可以揭示时间序列中潜在的连续演变趋势,并识别复杂系统中的异常现象。它已被证明能够识别复杂系统中的异常现象的前兆。然而,不幸的是,现有的TSC定义并没有准确地涵盖时间序列中不断变化的部分。发现的链很容易被噪声打破,并且可能包含非进化模式,这在现实世界的应用中已经被证明是不切实际的。受最近跟踪时间序列子序列的最近邻域如何随时间变化的工作启发,我们引入了TSC的新定义,该定义对数据中的噪声更加稳健,即在排除非演变模式的同时能更好地找到演变模式。此外,我们提出了两个新的质量指标来对所发现的链进行排名。广泛的实证评估表明,所提出的TSC定义比以前的技术对噪音更加稳健,所发现的顶级链可以在各种真实世界的数据集中揭示出有意义的规律性。
介绍。
在过去的二十年里,在时间序列数据中寻找重复模式的任务,即所谓的主题发现,由于其在许多不同领域的广泛应用,在研究界得到了很多关注。近年来,一种用于捕捉时间序列数据中不断演变的模式的新工具已经被引入,这种原始的工具被称为时间序列链(TSC)。时间序列链是一个从时间序列中提取的有序的子句集合,使得链中相邻的子句是相似的,但第一个和最后一个是任意不相似的。与其他时间序列数据挖掘技术如动机发现、不协调发现和时间序列聚类不同,时间序列链可以捕捉到随时间积累的潜在漂移,这种漂移在许多复杂系统、自然现象和社会变化中普遍存在。
为了更好地理解时间序列链的功能,考虑图1中的谷歌趋势数据,对应于美国零售连锁店Costco的12年的搜索词。在图中,发现的时间序列链被突出显示。这条链上的第一个图案显示了圣诞节前后的一个急剧高峰。这是一个正常的模式,因为网上购物的需求在假日季节前后增加。然后,该模式显示在7月左右有一个小的颠簸,因为该峰值在几年内逐渐平滑,这逐渐成长为另一个主要峰值。连锁店的这种转变模式清楚地说明了人们对好市多7月4日(独立日)的网上销售活动越来越感兴趣,并为营销提供了有益的启示。
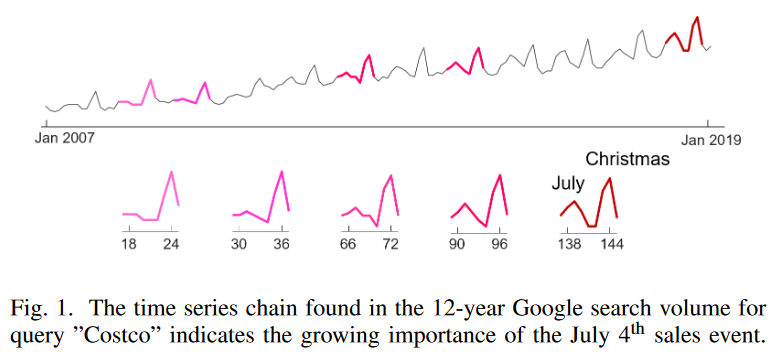
时间序列链的另一个典型应用是预言。正如先前的研究指出的那样,"大多数设备故障之前都有具体的迹象、条件或指示,表明这种故障可能会发生"。时间序列链不仅可以识别单一的前因,而且可以识别一系列的模式,揭示系统中连续和渐进的变化,帮助分析人员及早找到原因,防止灾难性的故障。目前有两种发现时间序列链的方法。链的概念最初是基于双向定义提出的,后来又提出了几何定义,以增加稳健性。最初的时间序列链定义将被称为TSC17,后来的几何链定义被称为TSC20。
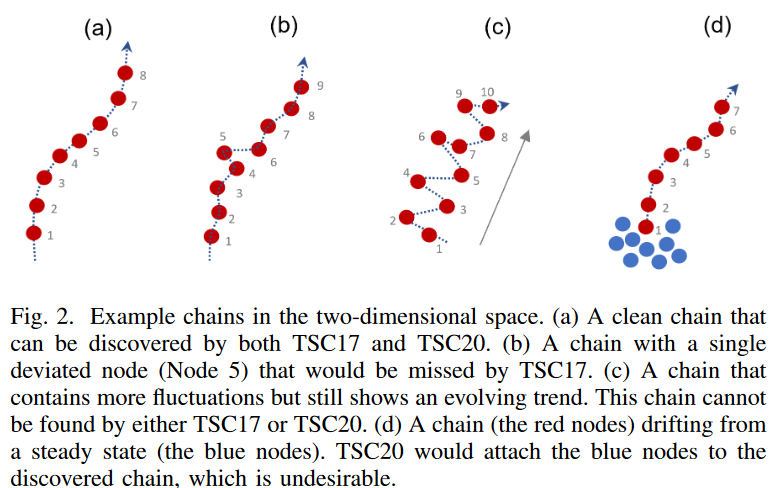
尽管时间序列链有很好的可解释性,但不幸的是,人们发现,现有的链式发现方法只在相对理想的情况下工作良好,即数据是干净的,模式以小的准线性步骤发展(如图2.a所示)。在实践中,连续的数据收集过程经常受到环境变化、人为错误和传感器信号中断的影响。 因此,数据可能包含噪音,一些模式可能偏离一般趋势(如图2.b中的节点5),连续的模式可能被颠倒,或者由于数据波动,链条可能形成之字形(图2.c)。或者,在开始漂移之前,模式可能保持相对稳定(如图2.d所示,这在预言中很典型)。现有的链式发现方法不够强大,无法处理真实世界数据中的这种情况。
具体来说,在现有的时间序列链的定义中发现了以下局限性
- TSC17中引入的约束条件过于严格,一个小的波动就很容易 "打破 "链条;图2.b是一个不符合约束条件的例子。
- TSC20中引入的方向性角度阈值对噪声非常敏感。如果数据包含波动,即使是50度的阈值(推荐的阈值是40度)也会错过明显的链(例如图2.c)。然而,如果进一步提高阈值,所发现的链将包含许多与演化趋势无关的噪声模式。
- 即使在方向性角度非常小的情况下,TSC20发现的链也可能包含与演化趋势无关的模式。例如,如果最初稳定的数据(非常相似的图案)开始漂移(如图2.d),TSC20会将稳定的(蓝色)图案添加到演化链中。因此,已经不可能确定数据何时开始漂移。
为了解决这些限制,我们提出了一个新的时间序列链定义,即TSC22,它利用了跟踪模式的最近邻如何随时间变化的想法来提高链发现的稳健性;与TSC17一样,TSC22是一个双向定义,但限制条件是大大放宽了,不象TSC20那样依赖角度约束。此外,还提出了一个新的质量指标来对该方法发现的链进行排序。实证评估表明,所提出的方法比以前的方法对噪音更加稳健,所发现的排名靠前的链可以在各种真实世界的数据集中揭示出有意义的规律性。
相关研究
时间序列链是一个相对较新的课题。最密切相关的工作是Zhu等人和Imamura等人。Zhu等人首先提出了时间序列链的概念。这项研究强制要求链中所有相邻的子序列对都是彼此之间最近的邻居,并将最长的链报告为顶级时间序列链。虽然这个概念简单而直观,但许多现实世界的应用表明,对双向近邻的要求过于严格,因为链很容易被数据波动和噪声破坏。Imamura等人通过只执行单向的左近邻条件来放松双向条件,并增加一个预先定义的角度约束来保证所发现的链的方向性。这个概念在某些条件下被证明是比较稳健的,但引入了一个新的角度参数,并观察到在一些实际情况下,无论如何设置这个参数,都无法找到有意义的链子。
其他关于时间序列链的研究有不同的问题设置:Wang等人探索了利用现有的时间序列链定义加快流式数据中的链发现的方法;Zhang等人提出了一种检测跨越两个时间序列的联合时间序列链的方法。Zhang et al.
这里的重点是改进单一时间序列中的连锁定义。
定义。
首先,确定了必要的时间序列符号,接着讨论了时间序列链的正式定义。
A. 按时间顺序排列的记号
与时间序列有关的基本定义。
定义1.时间序列
T = [t1, t2, ... , tn]是一个数据点的有序列表,其中ti是一个有限的实数,n是时间序列T的长度。
定义2.时间序列的划分
ST i= [ti, ti+1, ... , ti+l-1]是一个连续的点集,从时间序列T中的位置i开始,长度为l。 通常l ≫n,1≤i≤n-l+1。
通过在时间序列之间滑动一个固定长度为l的窗口,可以从时间序列T中提取出后续的内容。给定一个查询的子序列,可以计算出与时间序列T的所有子序列的距离。这就是所谓的距离曲线。
定义3.距离曲线
DQ,T是一个向量,包含查询子序列Q与时间序列T中相同长度的子序列之间的距离。形式上,DQ,T = [d(Q, S1), d(Q, S2), 。 , d(Q, Sn-l+1)] ,其中d(., .) 表示距离函数;在特殊情况下,Q是时间序列T的一个从位置i开始的子序列,距离曲线用Di表示。
遵循矩阵剖面图的原始工作,这里使用了z归一化的欧氏距离,而不是欧氏距离,以实现比例和偏移的不变性。
此外,距离剖面图可以被分成左边的距离剖面图和右边的距离剖面图。
定义4.时间序列T的左侧距离曲线
时间序列T的DLi是一个向量,包含给定子序列Si∈T和Si左边的所有子序列之间的欧几里得距离。形式上,DLi = [d(Si, S1), d(Si, S2), 。 , d(Si, Si-l/2)] 。
定义5.正确的距离曲线
DRi是向量DRi = [d(Si, Si+l/2), ... , d(Si, Sn-l+1)],其中d(Si, Sn-l+1)为向量。
通过分别检查左边和右边距离曲线的最小值,可以很容易地找到一个子阵列的左近邻(LNN)和右近邻(RNN)。两个向量,即左矩阵剖面和右矩阵剖面,用于存储所有子序列与其相应的左/右近邻之间的距离,以及其近邻的位置。
定义6.左矩阵轮廓
MPL是一个大小为2×(n-l+1)的二维向量,其中MPL(1,i)=min(DLi),MPL(2,i)= arg min(DLi)。
其中MPL(1, i)存储Si与i之前最相似的子序列(即其LNN)之间的距离,M PL(2, i)存储LN N的位置。
定义7.右矩阵轮廓
MPR是一个大小为2×(n-l+1)的二维向量,其中MPR(1,i)= min(DRi),MPR(2,i)= arg min(DRi)。
B. 现有时间序列链的定义
所有现有的时间序列链的定义都是从后向时间序列链发展而来的,并且可以很容易地得到给定的左侧矩阵轮廓。
定义8.时间序列T的后向链
时间序列T的TSCBWD 是时间序列子序列的有限有序集合TSCBWD = [SC1 , SC2 , SC3 , ... , SCm],其中C1>C2>......。 C1 > C2 > ... > Cm是时间序列T的索引,使LNN(SCi )=SCi+1,1≤i<m。
为了清楚起见,我们将把时间序列链的一部分称为节点。我们将把后向链的第一个节点称为起始节点,把最后一个节点称为结束节点。这里,在TSCBWD 中,SC1 是起始节点,SCm 是结束节点。
同样,从右边的矩阵剖面可以得到一个向前的时间序列链。
定义9.正向链
TSCFWD 是一个时间序列T的有限有序的子序列集。 , SCm ] 其中C1 < C2 < ... < Cm是时间序列T的指数。对于任何1≤i<m,RN N(SCi)=SCi+1。
现有的研究通过对后向链施加不同的约束来定义链;在TSC17中,时间序列链是根据后向链和前向链的交叉点来定义的。这被称为双向的时间序列链。
定义10.双向时间序列链
双向时间序列链(TSC17)是一个时间序列T的有限有序的子集。 TSC = [SC1 , SC2 , SC3 , ... , SCm ] 其中C1 > C2 > .... C1 > C2 > ... > Cm,对于任何1≤i<m,我们有LNN(SCi )=SCi+1和RN N(SCi+1)=SCi。其中,该集合的大小m表示为链的长度。
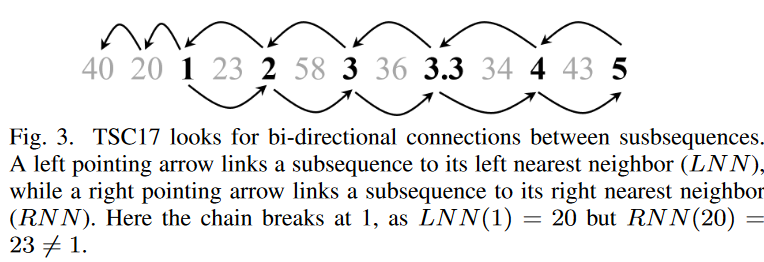
为了理解TSC17是如何工作的,考虑图3中的时间序列。
40, 20, 1, 23, 2, 58, 3, 36, 3.3, 34, 4, 43, 5
子序列的长度被设定为1,距离由数字之间的差值的绝对值来衡量。按照后向链5→4→3.3→2→1→20→40,看每个节点的LNN和RNN是否能形成一个循环。
LNN(5)=4,RNN(4)=5。
LNN(4)=3.3,RNN(3.3)=4。
LNN(3.3)=3,RNN(3)=3.3。
LNN(3)=2,RNN(2)=3。
lnn(2)=1,rnn(1)=2。
LNN (1)=20,但RN N (20)=23 6=1,所以链在1处断裂。 如图3所示,提取的链(逆行)是
5 ↔ 4 ↔ 3.3 ↔ 3 ↔ 2 ↔ 1
仔细观察图3可以发现这个问题的一个很好的答案。如果简单地按照5→4→3.3→3→2→1→20→40的链条,没有任何约束,链条就会失去其 "方向性"。大的噪声数字(20,40)根本不符合缓慢下降的趋势;TSC17中的双向约束将这些噪声信号从链中移除。
在TSC20中,时间序列链是通过对后向链施加角度约束来定义的。这被称为几何时间序列链。
定义11.时间序列T的几何时间序列链
一个时间序列T的几何时间序列链(TSC20)是一个时间序列T的有限有序的子序列集合。 , SCm ] (C1 > C2 > .... > Cm ),这样对于任何1≤i<m,我们有LNN(SCi )=SCi+1,对于任何2≤i<m,我们有第i个角度θi ≤ θ。其中。
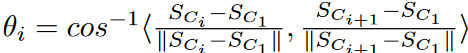
θ是一个预定的阈值。
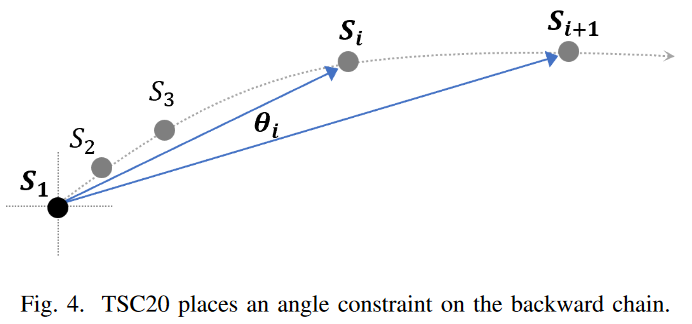
图4显示了TSC20定义在二维空间的工作情况。方向角θi测量从Si到Si+1的方向变化,参考锚节点S1。链上两个连续的子序列之间的小角度阈值确保了子序列的演化方向相似。
TSC17和TSC20的局限性。
TSC17和TSC20使用起来都很直观,但发现它们很容易受到数据中的噪音和波动的影响。
A. TSC的弱点 17.
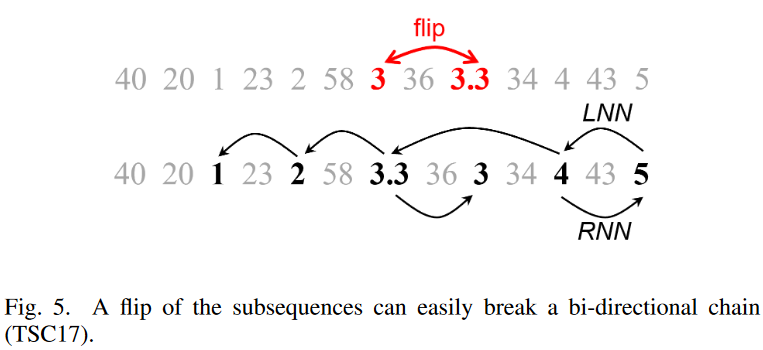
让我们再看看图3中的例子:图5。 假设我们把数字3和3.3倒过来,如上所示。现在的时间序列将看起来像这样。
40, 20, 1, 23, 2, 58, 3.3, 36, 3, 34, 4, 43, 5
图5.考虑从节点5向后延伸链条,如下图所示:我们看到LNN(5)=4,LNN(4)=5,所以我们可以在链条上增加4。继续下去,LNN(4)=3.3,但RNN(3.3)=3 6=4,所以我们不能加3.3,链子就断了。然而,从下面的图5.可以看出,当反过来时,可以建立一个合理的链,以5→4→3.3→2→1的顺序逐渐减少。这个链条就是因为双向约束太紧而没有建立起来。
B. TSC20的弱点。
TSC20中使用的几何链定义取消了TSC17的双向l约束,只使用后向链。虽然这导致了更长的链,如图3所示,但不相关的噪声模式可以包含在链中。为了解决这个问题,TSC20在后向链上增加了一个角度约束。然而,我们发现,这种角度限制引起了新的问题,TSC20在某些情况下会遗漏明显的链,而在其他情况下则会在找到的链上添加不需要的图案。
1) 忽略了一个明显的事件链
图6.考虑上面的二维例子。假设这些子序列在时间上以下列顺序出现
S9, S8, S7, S6, S5, S4, S3, S2, S1
部分序列以 "之 "字形方式演变,但明显显示出从左到右缓慢移动的趋势。然而,TSC20不能检测这种联系。
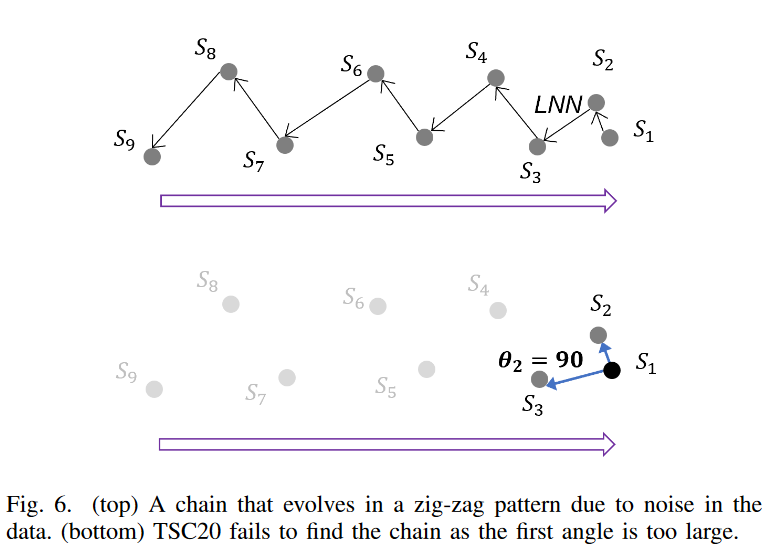
按照TSC20的定义,上图6中,我们首先找到从S1开始的后向链(箭头指向二维空间中LNN的所有子序列),然后根据锚定子序列S1检查连续子序列之间的角度 如图6所示,第一个角度θ1=90度,这是远远大于TSC20中提出的40度的阈值,链就会立即断裂。通过重新设置锚点到下一个部分链,可以对所有的部分反向链进行检查,但不幸的是,没有一个部分链满足约束条件。
请注意,图6只显示了波动会导致TSC20在二维空间中崩溃。事实上,这种演化模式在高维空间中非常常见,因为噪声和波动导致子序列向不同方向漂移。
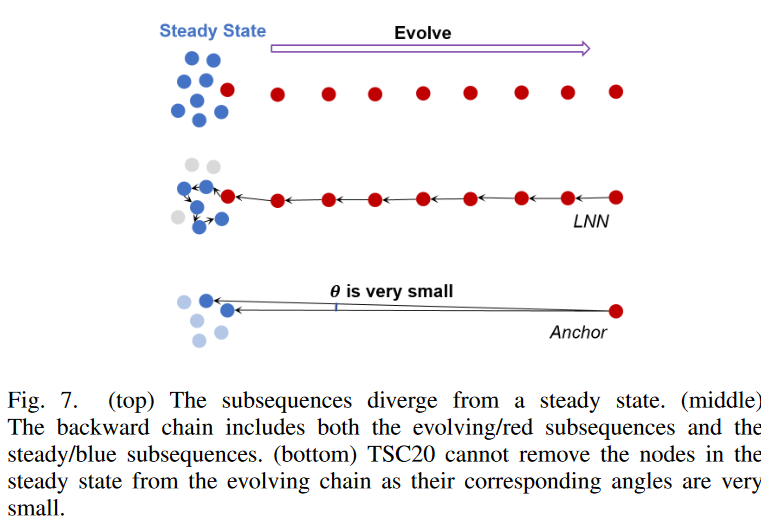
2) 在链条上增加了不受欢迎的图案
TSC20的另一个问题是,不相关的图案会被附在链上,降低了链的质量,上面的图7就是一个例子。这里,子序列最初是静止的(以蓝色显示),然后开始一路向右漂移(以红色显示)。理想情况下,链式发现算法应该找到所有演化的(红色)子序列,而不是稳态的(蓝色)子序列,这样,链式的末端节点(左边的第一个红色节点)就能准确地告诉我们系统何时开始漂移(即变化点)。这种时间信息对预测应用非常重要,因为它有助于确定漂移的根本原因。然而,如果我们沿着图7所示的后向链,我们可以看到沿此链的所有连续节点都满足TSC20角度约束。红色节点是以准线性方式演化的,所以方向角接近零。与连续的蓝色节点对应的角度(图7.底部)也非常小,因为这些节点离锚点很远,但非常接近它。因此,TSC20角度约束不能将蓝色节点从链中排除,因此不能检测到变化点。
建议的方法
为了解决上述现有时间序列链定义的局限性,本文提出了一种新的时间序列链发现方法,命名为TSC22 如TSC20所述,链发现方法应包括两个部分。一个发现数据中所有链的算法和一个用于对发现的链进行排名的质量指标。
A. 递增的邻里关系
我们的链式发现方法利用了Y. Zhu等人的想法,跟踪时间序列子序列的近邻是如何随时间变化的;图8显示了这一方法的工作原理,使用的是上一节的一维运行例子。从右边扫描到子序列2,以前的近邻子序列(或增量近邻序列)根据其绝对值的差异被存储。我们把{3,4,5}这个集合称为增量邻域集(IN N S),因为这个集合显示了从时间序列的末端遍历时,子阵列的最近邻域的位置如何变化。

定义12 .一个子序列Si的增量邻域集(INNS)是子序列Sj的集合(i < j ≤ n - l + 1)。
{Sj|d(Si, Sj) < d(Si, Sk) ∀k : j < k ≤ n - l + 1}
请注意,一个子序列的右邻总是包括在子序列的IN N S中。
B. 寻找增量邻域中的所有链子
在增量邻域的基础上,我们引入了一个关键节点,它是我们定义链的一个关键要素。
定义13. 如果Si∈IN N S(LNN(Si)),那么时间序列T的一个时间序列子序列Si是一个关键节点(CN)。
请注意,与定义10(TSC17)相比,关键节点可以基于更宽松的约束:由于RNN总是属于一个递增的近邻集,TSC17链的节点也是这个定义中的关键节点。可以找到一个时间序列T的所有关键节点。这被称为关键节点集,表示为CN T。这使我们能够正式定义TSC22(宽松的双向时间序列链)。
定义14. 时间序列T的松弛双向时间序列链(TSC22)是时间序列子序列的有限有序集合。
t sc = [sc1 , sc2 , sc3 , ... , SCm ] (C1 > C2 > ... >Cm),这样,。
1) 对于任何1 6 i < m,LN N (SCi ) = SCi+1,其中
2)sc1∈cn t,。
3) 对于任何1<i 6 m,我们有SCj∈IN N S(i),j = arg min i<j≤m SCj∈CN T
从条件(1)中,我们可以看到,与TSC17和TSC20一样,我们的新链定义TSC22是建立在后向链之上的,我们称之为 "宽松的 "双向链,因为前向链的约束没有TSC17那么严格。
图9显示了一个一维的时间序列,作为一个例子。
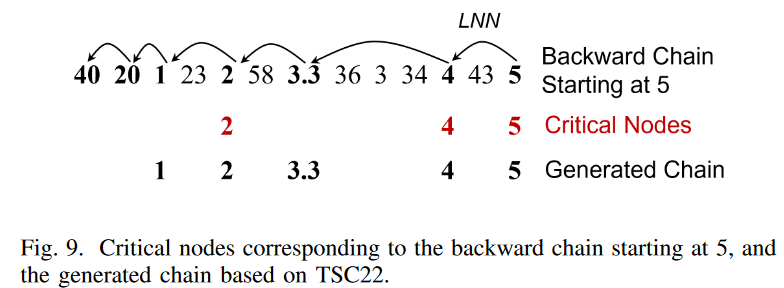
从(1)和(2)中,我们看到TSC22是一个从关键节点开始的后向链。现在让我们从节点 "5 "开始扩展链:如图9所示,我们发现LNN(5)=4,5∈IN N S(4)={5}。这意味着5是一个关键节点,也是TSC22的有效起始节点。接下来,我们继续检查后向链中的下一个节点:4是一个关键节点,因为LN N(4)=3.3,4∈IN N S(3.3)={3,4,5},3.3 6∈IN N S(2)={3,4,5},3.3不是一个关键节点,因为LN N(3.3)=2,等等。继续下去,我们看到这个后向链上的关键节点是5、4和2。条件(3)要求对于链上的每个节点SCi(除了起始节点),链上出现在SCi之后的最近的关键节点必须是IN N S(SCi)的一个元素。对后向链5→4→3.3→2→1→20→40中的每个节点进行检查,我们看到部分链5、4、3.3、2和1满足这个条件,但部分链20有1个6∈IN N C(20)={23, 34, 5},链不能在这个位置断开。因此,产生的链是5→4→3.3→2→1。基本上,条件(3)保证了生成链的 "方向性":如图9所示,在原始时间序列和生成链中,与2右边的所有子列相比,子列2更接近子列1;在原始时间序列和生成链中,子列4更接近子列2右边的所有子列。与2右边的子序列相比,4更接近于2和3.3。
对比图9和图5,我们可以看到TSC22可以提取有意义的链,即使有些链的模式由于噪声而被颠倒了。我们还看到,图6中的人字形链也可以通过我们的定义找到。这表明TSC22比TSC17和TSC20对噪声的适应性更强。
C. 排名。
现在我们有了在TSC22中发现的所有链,我们需要一种机制来衡量它们的质量并对它们进行有效的排名;TSC17对发现的链按其长度进行排名,但这并不总是有效的,特别是当时间序列中有大量的噪声时;在TSC20中提到,TSC17即使在不显示进化趋势的静止数据中也可能发现长链,仅靠顶级链的长度不能确定数据中是否存在有意义的链。理想情况下,一个高质量的链条应该具有以下特性。
- 高分化 链上的第一个和最后一个节点必须有足够的差异。
- 渐变 一个链条上的连续节点,彼此之间非常相似。
- 纯度链不能包含不相关的模式。
- 长度 较长的链子更好,以确保充分覆盖漂移模式。
请注意,这些质量观点不一定是一致的。一条链可能进化得非常快,显示出高分化但低渐变性,而且长度很短。另一方面,另一条长链可能由相互之间几乎相同的图案组成,但没有显示出进化的趋势。为了解决这个问题,我们开发了两个考虑到所有属性的质量指标,并根据这些质量指标设计了一个两阶段的排名算法,以确保高质量的连锁店脱颖而出。
有效长度
受TSC20的启发,它计算了 "有效长度 "指标Leff,同时衡量了分歧和渐变。
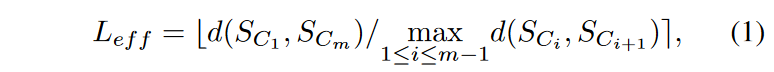
其中b.e代表四舍五入到最近的整数。分子是链中第一个和最后一个节点之间的距离,分母是链中所有连续的节点对之间的最大距离。如果链条以均匀的速度线性演化,我们可以想象Laff是链条的长度。这一措施基本上表明,如果以线性轨迹运动,从起始节点到达终点节点所需的大致步数,每步的距离等于链上节点之间的最大连续距离。具有高发散性和高渐变性的链应该具有较高的Laff,而含有噪声的链应该具有Laff≈1。 由于Laff是一个整数,所以有等值的。首先按照Leff得分对链条进行排名,然后根据Leff得分最高的链条的相关度的平方之和进行精细排名。
相关长度
本文中的指标被称为相关长度,计算方法如下。
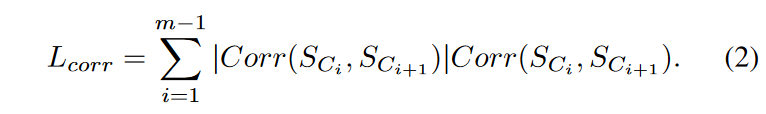
其中Corr(.)是z归一化子序列的皮尔逊相关系数,数值范围为[-1, 1];如果两个子序列非常相似,它们的皮尔逊相关系数就接近于1;如果它们含有噪声,它通常小于0.5。在这里,皮尔逊相关系数乘以其绝对值,以放大相似和不相似的配对之间的差异。这个衡量标准被称为相关 "长度",因为如果一条链上的连续节点彼此非常相似,Lcorr将非常接近于链的实际长度。因此,具有高度相似子序列的长链将在细粒度排名阶段被优先考虑。与只考虑链长的TSC17排名方法和只考虑分歧和渐变的TSC20排名方法相比,这种排名方法对链的所有质量方面都有更好的覆盖。有了新的排名方法和更强大的链的定义,TSC22可以有效地从各种真实世界和合成数据集中发现有意义的链,即使在数据中存在大量的噪音。
实验评价
我们证明,在真实世界和合成数据上,所提出的方法比目前最先进的时间序列链发现方法TSC17(ICDM'17)和TSC20(KDD'20)更稳健。为了确保公平的比较,我们对TSC17和TSC20都使用了原始的Matlab源代码,而TSC20则使用了默认的方向角。
首先,通过对真实世界数据的几个案例研究,对三种链式发现方法的性能进行定性分析,然后在一个大型合成数据集上进行定量比较,在这个数据集上可以计算出基于地面真实的绝对性能指标。
A. 案例研究:企鹅活动数据的稳健分析
1) 清洁数据
这里,Y. Zhu等人的企鹅活动时间序列。这显示了小鸟移动时的X轴加速度。子序列的长度为25;图10显示了企鹅跳入水中时22.5s的数据(以40Hz的频率记录)。鸟儿大约2秒后到达水面(第80个数据点),之后深度值开始增加,如图10所示,TSC 22显示了一个明显的我们发现一个高质量的链条,显示出不断发展的趋势。这条链显示了企鹅如何调整它们的拍打来平衡浮力和水压的增加:用TSC22得到的链覆盖了整个潜水范围,而用TSC20得到的链在末端缺少几个节点,用TSC17得到的链在两边缺少几个节点。20和TSC17链能够显示图案的进化趋势,但不能显示进化过程的开始/结束时间。
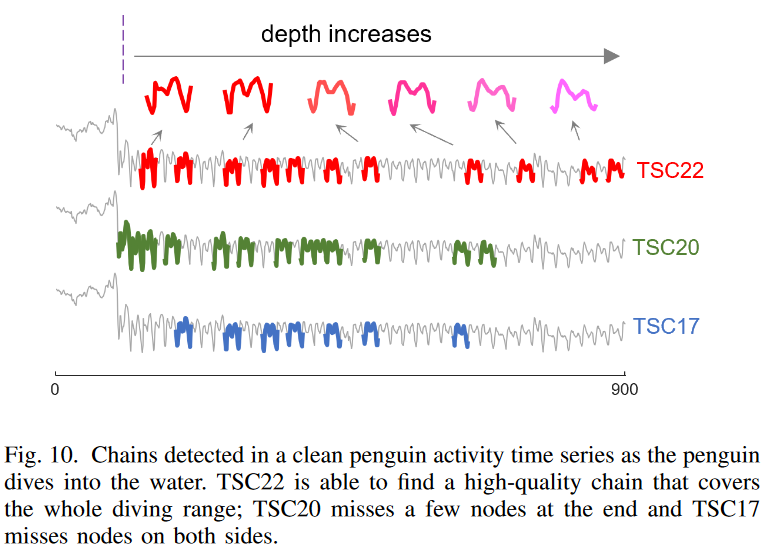
人们可能会想,图10中TSC17和TSC20无法找到TSC22链,是由于TSC17和TSC20受到限制,还是由于一种有利于其他链而不是TSC22链的排名机制。仔细观察发现,TSC22链不符合TSC17或TSC20的定义;如图5,由于数据的自然波动(如企鹅为避开其他动物而改变运动方向的可能性),该链中的大多数连续节点在TSC中没有发现17不满足双向近邻约束。然后,按照TSC 22链反向操作,我们看到该链的前三个节点形成的方向角(见图6)为114°,远高于TSC 20的角度阈值(40°),所以该链瞬间被断开。这个例子验证了TSC17和TSC20在具有自然波动的高维真实世界数据中的弱点,并证明了TSC22在此类数据中的稳健性。
2)带有Lydam背景噪音的数据。
在图11中,为了进一步测试三种方法的稳健性,在企鹅数据中加入了少量(±0.08量级)的随机噪声,以模拟传感器的额外背景噪声。在这种情况下,可以看出TSC22在整个潜水过程中仍能找到高质量的链,即使在有额外噪声的情况下,所发现的模式也显示出非常明显的进化趋势。然而,TSC20和TSC17未能捕捉到这一链条,它们的顶级链条现在只覆盖了演化范围的一半。此外,TSC20在其顶部链上添加了一个随机的噪音模式。这代表了随着后向链的变长,过滤方向性角度约束的能力被削弱了。
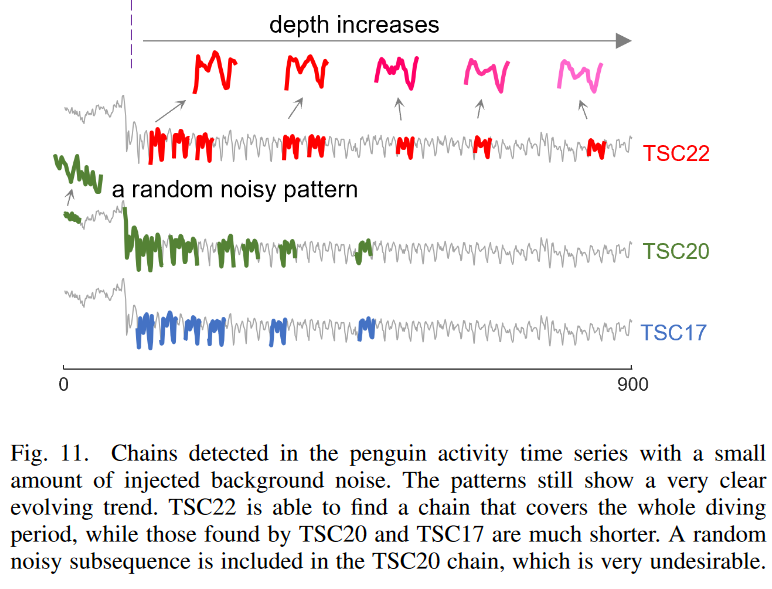
B. 案例研究:检测散点和表格数据中的变化点
这里我们用Y. Zhu等人的倾斜台数据来比较所考虑的三种方法在系统从稳定状态过渡到漂移状态时的表现。 图12显示了躺在倾斜台上的病人的动脉血压(ABP)信号。这里,部分阵列的长度被设定为180,大约相当于一个心脏周期。这样的数据在许多其他领域是很典型的,特别是在预言方面,系统最初运行在稳定状态,然后开始恶化。因此,正确识别变化点(漂移的开始)是很重要的,这样就可以利用这些信息来确定造成漂移的隐性机制,并在早期阶段防止系统失败。
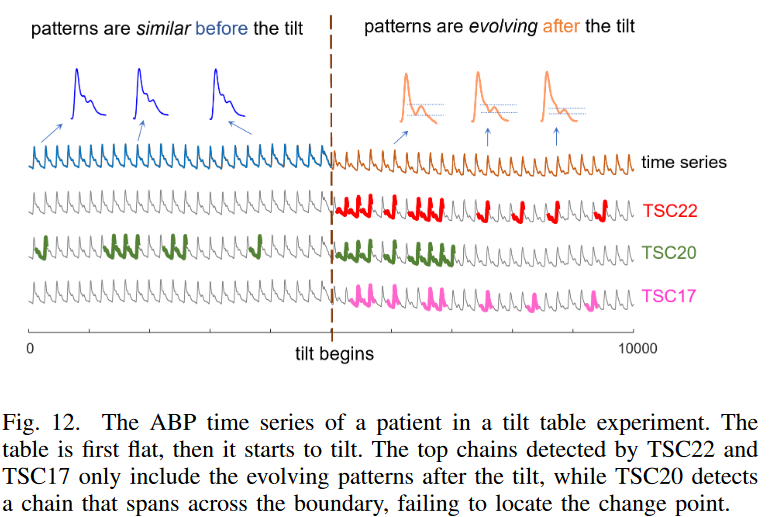
图12显示,TSC22和TSC17只成功地找到了斜率后数据的右侧部分的链,而TSC20检测到了跨越斜率和静止部分的链。在这种情况下,不难理解为什么TSC20不能生成纯链(见图7)。由于任何一对相对于锚点的预倾斜子序列几乎都是相同的,它们之间形成的方向性角度接近于零:当达到一个稳定的数据区间时,TSC20的单向性根本无法阻止后向链的增长。另一方面,TSC22和TSC17中的双向限制有效地阻止了这些链生长到固定部分。这个例子进一步说明了TSC22的用处:TSC22可以准确地指出系统开始漂移的时间,使分析人员更容易通过检查漂移前后发生的事件找到漂移的隐含原因。
C. 案例研究:在人类步态力数据的多个训练阶段寻找联系。
如图13所示,使用人类行走力的时间序列对寻链方法进行了评估,该时间序列表示传感器在四种不同跑步速度下运行的分带式跑步机上检测到的前后力。从图13中可以看出,在TSC22上检测到的链都是在TSC22的不同速度区间内。链条的急剧缩进模式表明,随着速度的增加,力的变化更快,受试者的脚在磨线机地板上的时间更短。较短的倾角到峰值时间也表明运行速度较快。然而,TSC20和TSC17只能检测到部分数据中的链,不能覆盖全部范围,即使该模式在整个时间序列中演变。
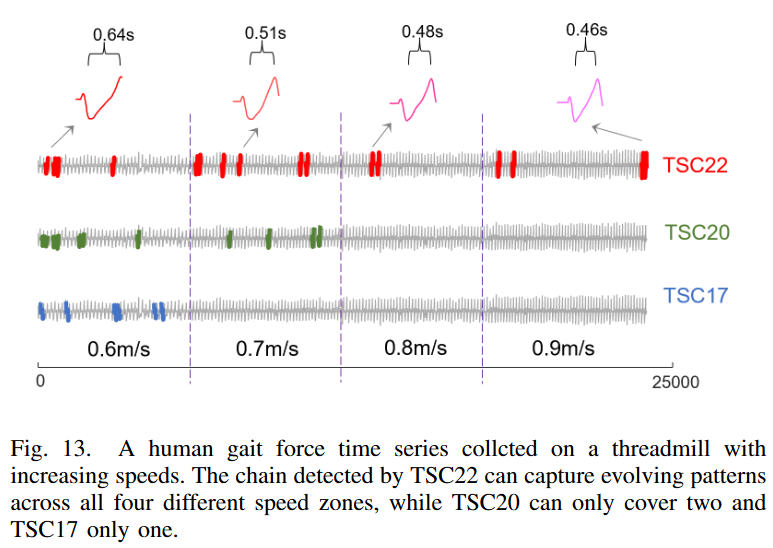
为什么TSC20和TSC17在这种情况下会失败?请注意,同一速度区域内的模式相互之间比较相似,并且以相当小的速度演变,因为速度是零散的、恒定的增加。由于参与者的运动自然存在波动,同一速度区内的许多模式都是相反的(见图5),整体的演变更接近于图2.c或图6中的人字形链,而不是图2.a中的模式。作为合理性检查,可以看到图13中的TSC22链上没有一个节点满足TSC20的双向近邻约束,链上最后三个节点(即后向链的前三个节点)形成的方向角为86度,远远超过TSC20的角度限制40度。这个例子进一步证明了TSC22对于现实世界中的时间序列数据的出色鲁棒性,这些数据自然会受到许多波动和噪声的影响。
D. 定量稳健性分析
在上述评估中,没有绝对的地面真理标签(即每个图案在时间序列中的确切位置),而这些标签的潜在模糊性使得我们很难根据真实世界的数据进行合理的定量分析。因此,为了计算准确度和重现性等定量性能指标,我们创建了一个大型的合成数据集,并将链状图案手动嵌入其中,以测试有关的三种方法是否能准确定位这些图案。
图14显示了创建的时间序列的一个例子。在这里,地面真实链的第一个节点(图14.顶部)是从UCR时间序列分类档案1中的数据集中随机抽取的,而最后一个节点是一个随机行走模式。该链由10个节点组成,从第一个节点到最后一个节点呈线性演化。这个链条的节点被嵌入到随机位置,同时保持它们在随机噪声时间序列中的顺序。为了增加任务的难度,我们在数据上面添加了随机噪声来扭曲模式,还在时间序列中嵌入了10个模式(如下图14.所示),这些模式与第一个节点(从同一数据集取样)相似,但与演变趋势无关。在生成的时间序列的开头和结尾添加了两个随机噪声部分,以模拟现实世界中链条不延伸到整个时间序列的情况。为了构建合成时间序列,使用了UCR时间序列档案中的17个数据集,涵盖了所有传感器、心电图和模拟形状的数据,实例长度从50到500,省略了包含高频模式的数据集,这些数据集会使生成的链的视觉解释变得困难。使用了以下数据集。对于每个数据集,产生五个不同的时间序列,并测量每个链式发现方法在这些时间序列上的平均性能。

如果检测到的链上的节点(即子序列)与地面事实的重叠率超过50%,则定义为命中。
由于所有的TSC方法都包括两个步骤--链式检测和排序--我们进行了实验来比较有无排序步骤的性能�
1) 使用排名时的整体表现
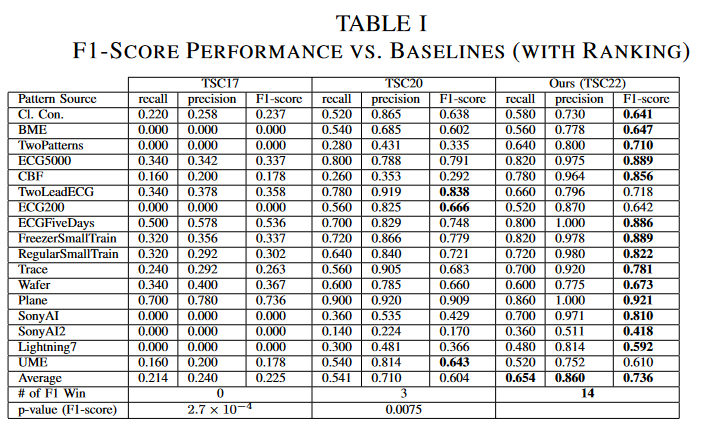
表一显示了三种方法检测到的前1条链的性能:TSC22在17个数据集中的14个数据集的F1得分高于两个基线,其平均值(0.736)远远好于TSC17(0.225)和TSC20(0.604)。TSC22和TSC17之间的Wilcoxon签名秩检验的P值为2.7×10-4,TSC22和TSC20之间的P值为0.0075。两个P值都小于0.05,表明TSC22在统计上明显优于基线。
2) 没有排名的表现
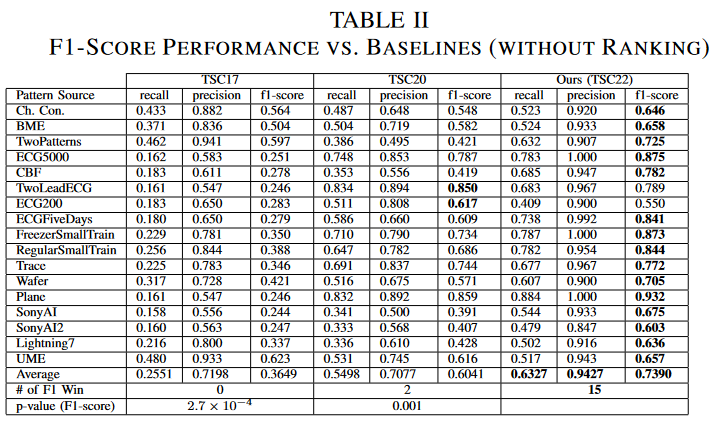
为了使用消除排名影响的定义公平地比较三种TSC方法,固定了链的起始节点,并对发现的链的性能进行了评估。在每个时间序列中,我们从大实话链的最后五个节点独立地 "增长 "链条,并报告在这五个不同的链条中获得的最大F1得分 从表二来看,TSC22在17个数据集中有15个的F1得分超过了两个基线Wilcoxon检验P值也被用来确定最大的F1得分。同时,由于Wilcoxon检验的P值小于0.05,可以得出结论,TSC22的定义明显优于现有的TSC的定义。
摘要
本研究提出了一个新的时间序列链定义,即TSC22,它利用了跟踪模式的最近邻如何随时间变化的想法,并提高了链对噪声的鲁棒性。此外,还提出了两个新的质量指标来对检测到的链进行有效的排名。在真实世界和合成数据上进行的广泛实验表明,新的定义比最先进的TSC定义要稳健得多。对真实世界的时间序列进行的案例研究也表明,在不同的噪声条件下,该方法发现的排名靠前的链可以在各种应用中揭示出有意义的规律性。
(文章作者)一个强大的新工具被提出来用于时间序列数据分析,它有广泛的应用。请读者根据自己的数据进行评估。



与本文相关的类别






