
时间序列分类动态稀疏网络DNS,在宽广的接受领域内学习,无需复杂的调整。
三个要点
✔️ 在视觉任务中应用One-Shot NAS到Transformer。
✔️ 提出权重纠结,分享大部分的子网权重
✔️ 与现有基于变压器的方法相比,性能优越
Dynamic Sparse Network for Time Series Classification: Learning What to "see''
written by Qiao Xiao, Boqian Wu, Yu Zhang, Shiwei Liu, Mykola Pechenizkiy, Elena Mocanu, Decebal Constantin Mocanu
(Submitted on 19 Dec 2022)
Comments: Accepted at Neural Information Processing Systems (NeurIPS 2022)
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
在本文中,我们提出了一种用于时间序列分类(TSC)的动态稀疏网络(DSN),它可以在一定范围内接受场(RF)大小的训练,而不需要进行超参数调整。DSN模型可用于单变量和多变量TSC数据集,与基线方法相比,其计算成本更低,具有最先进的性能。
介绍
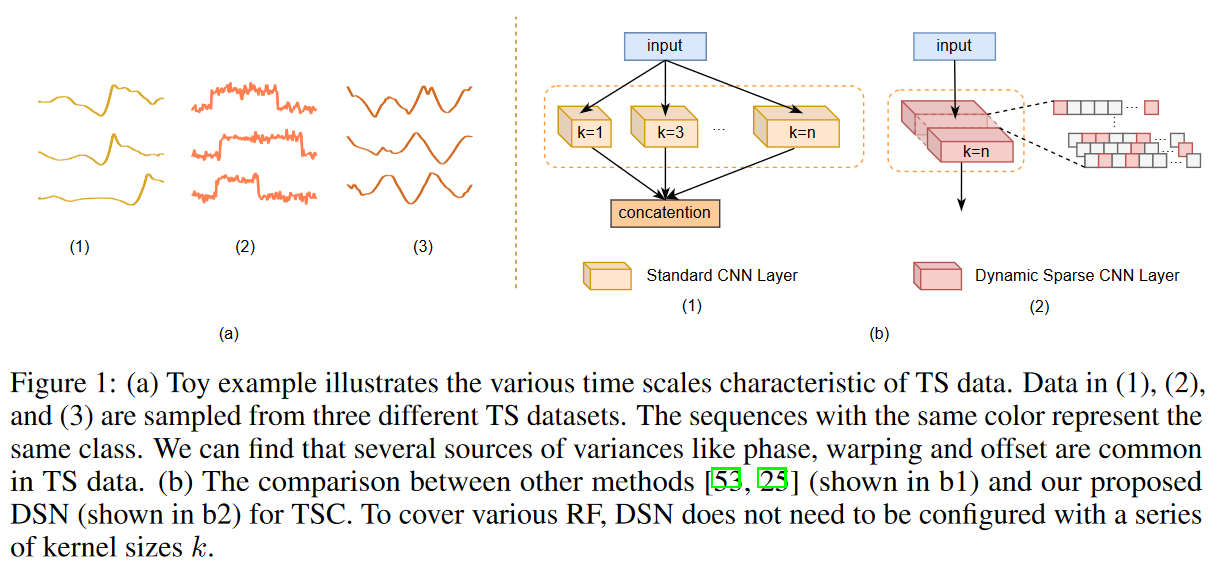
在收集时间序列数据时,面临的挑战是如何发现和利用由于采样率、记录长度等的各种变化而隐藏在时间序列中的各种标度信号。 其主要原因是收集时间序列时自然发生的几种差异,如采样率和记录长度。此外,数据点的振幅偏移、扭曲和遮挡也是不可避免的(见图1)。因此,确定特征提取的最佳尺度是很困难的,但对TSC任务很重要。主要的解决方案之一是尽可能多地覆盖感受野(RF)尺度,以避免忽略时间序列输入中的有用信号。
受稀疏神经网络模型的启发,本文提出了一种用于TSC任务的稀疏神经网络模型,该模型由一个具有较大但动态稀疏内核的CNN层组成,可以自动学习稀疏连接,在覆盖各种RF方面提出了一个动态稀疏网络(DSN)。提出的DSN是通过动态稀疏学习(DST)策略来训练的,这也降低了学习和推理的计算成本(如浮点运算(FLOPs))。传统的动态稀疏训练方法是逐层搜索连接,很难覆盖小的射频,而这里提出了一种更精细的稀疏训练方法,用于TSCs。具体来说,每层的CNN核被分为几组,在稀疏训练过程中,每组都可以在一个约束区域下进行探索。
本文的主要贡献是提出了一种用于时间序列分类(TSC)的动态稀疏网络(DSN),它可以学习覆盖不同的感受野(RF)大小,而不需要进行超参数调整,并通过动态稀疏训练来减少计算和内存成本。我们的想法是为TSC引入一个可以被训练的新的DSN模型。所提出的DSN模型在单变量和多变量TSC数据集上都达到了最先进的性能,而且计算成本比最近的基线方法低。
相关研究
按时间顺序分类
在过去十年中,深度学习的成功鼓励了研究人员探索并将其应用于TSC任务。在单变量TSC中,基于深度学习的模型试图通过卷积或递归网络将原始时间序列数据直接转化为低维特征表示。在多变量TSC中,LSTM或注意力层通常与CNN层堆叠在一起,从时间序列数据中提取互补特征。近年来,由于时间序列数据由不同尺度的信号组成,许多研究试图以一种更可扩展的方式提取特征。其中一个主要的解决方案是构建不同大小的合适的内核,以便增加捕获适当尺度的概率。基于火箭的方法旨在使用多个大小和扩展因子的随机核,以覆盖TSC中的各种RF。与这些工作不同,这里提出的动态稀疏CNN层可以使用可变形的扩展系数自适应地学习各种RF,在计算复杂性和性能之间进行权衡,而不需要繁琐的超参数调整。
稀疏训练
最近,彩票假说表明,有可能以较低的计算成本训练稀疏子网络,使其性能与密集子网络相匹配。最近的工作不是从密集网络中迭代修剪,而是试图在训练中根据梯度信息找到一个初始掩码进行一次性修剪。修剪后,神经网络的拓扑结构将在训练中被固定。然而,这种类型的模型很难与高密度的对应模型达到的精度相匹配。
作为彩票假说之前的一种新的学习范式,DST从稀疏网络开始,在学习过程中允许稀疏连接以固定数量的参数动态发展。DST目前正在吸引其他研究领域的关注,如强化学习和连续学习,其潜力超过了学习密集神经网络。与传统的DST方法不同,所提出的DSN采用细粒度的稀疏学习策略,而不是传统的分层方法,以捕捉TSC更多样化的RF。
适应性接收场
事实证明,在学习过程中可以自适应变化的RF在许多领域都是有效的。自适应的RF通常可以通过在学习过程中学习最佳内核大小或内核掩码来获取。然而,内核和掩码都不是稀疏的,当需要较大的射频时,这可能是计算密集的。与这些方法不同的是,DSN的动态稀疏CNN层可以用DST训练,并且可以使用可变形的扩展系数来学习捕捉可变的RFs。此外,内核在训练和推理过程中始终是稀疏的,从而降低了计算成本。
建议的方法
问题描述
定义1.(时间序列分类(TSC))。
让TS实例X ={X1,.Xn}∈Rn×m,其中m表示变量数,n表示时间步数;TSC预测类标签y∈{1, .c};如果m等于1,TSC是单变量的,否则是多变量的。
定义2:(时间序列(TS)训练集)
训练集D = { (X(1), y(1)) , ...., (X(N), y(N))},其中X(i)∈Rn×m是标签y(i)∈{1, .... , c}相应的单变量或多变量的TS实例。
请注意,在TS数据集中,所有实例都有相同的时间步数。在不丧失一般性的前提下,给定一个训练集,目的是以较低的资源成本(如内存和计算)为TSC任务训练一个具有适应性和变化的RF的CNN分类器。
具有自适应感受区的动态稀疏CNN层。
覆盖各种RF的一个简单策略是在每个CNN层应用一个多尺寸的内核,但这有几个限制。首先,来自不同TS数据集的TS实例很可能没有相同的长度和周期,这使得即使有事先的知识,也很难为所有数据集设置一个固定的内核配置。其次,为了获得一个大的感受野,通常需要堆叠更大的内核和更多的层,这就增加了存储和计算成本,因为引入了更多参数。
为了解决这些挑战,提议的动态稀疏CNN层有一个大而稀疏的内核,可以通过训练获得自适应RF。具体来说,给定第l层的输入特征图xl∈Rcl-1×h×w(单变量TSC时h为1,cl-1为输入通道数)和内核权重Θl∈Rcl-1×cl×1×k(k为内核大小,cl为输出通道数),提出的动态稀疏CNN层带有stride 1和padding的卷积公式为
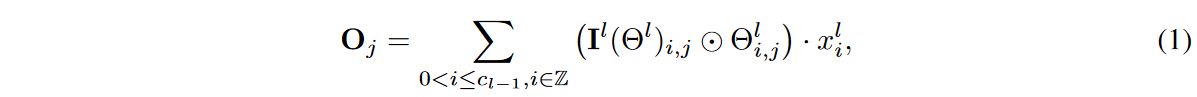
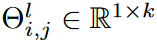
 其中Oj∈Rh×w表示第j个输出通道中的输出特征表示,Z表示整数集,Il(-).Rcl-1×cl×1×k →{0,1}cl-1×cl×1×k是指标函数,Il(Θl)i,j表示 ,第(i,j)个通道的内核的激活权重、元素和积,-表示卷积算子。
其中Oj∈Rh×w表示第j个输出通道中的输出特征表示,Z表示整数集,Il(-).Rcl-1×cl×1×k →{0,1}cl-1×cl×1×k是指标函数,Il(Θl)i,j表示 ,第(i,j)个通道的内核的激活权重、元素和积,-表示卷积算子。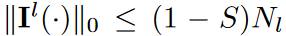 指标函数Il(-)是在拟议的DSN训练中学习的,它满足以下条件其中0≤S<1为稀疏密度比。
指标函数Il(-)是在拟议的DSN训练中学习的,它满足以下条件其中0≤S<1为稀疏密度比。 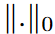 表示L0准则, Nl=cl-1×cl×1×k。当S>0时,内核是稀疏的,在动态稀疏CNN层中可以使用大的k来获得大的RF,并降低计算复杂度。
表示L0准则, Nl=cl-1×cl×1×k。当S>0时,内核是稀疏的,在动态稀疏CNN层中可以使用大的k来获得大的RF,并降低计算复杂度。
有效邻里接收场的大小
感受野被定义为CNN模型中的特征所看到的输入区域。每个连续层中的每个特征所看到的区域被定义为邻居感受区(NRF)。具体来说,NRF的大小对应于标准CNN层的内核大小(考虑到扩张等于1的情况)。然而,如果内核中的第一个或最后一个权重没有被激活,那么提议的动态稀疏CNN层的NRF大小就会小于内核大小。例如,∃i ∈{1, ....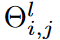
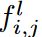 cl-1},j∈{1,.cl},Il(Θl)i,j,1,1=0或Il(Θl)i,j,1,k=0。如图2所示,内核的eNRF大小为第l个CNN层中第一个和最后一个激活权重的距离、
cl-1},j∈{1,.cl},Il(Θl)i,j,1,1=0或Il(Θl)i,j,1,k=0。如图2所示,内核的eNRF大小为第l个CNN层中第一个和最后一个激活权重的距离、
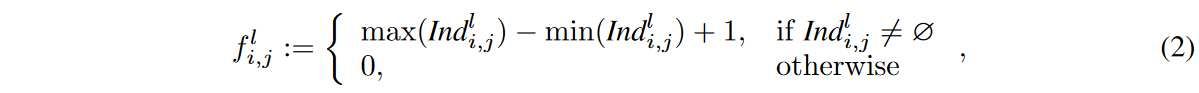
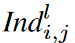 这里代表与内核的非零权重相对应的指数集。
这里代表与内核的非零权重相对应的指数集。 显然,这就是.
显然,这就是.
第l个动态稀疏CNN层的eNRF大小集合表示为F(l),并满足0≤min(F(l)),max(F(l))≤k。以图2中第l层的情况为例,F(l)={0, 1, 2, 3, 4, 5, 6}。每个动态视角的CNN层被认为对应于从1到k的各种eNRF大小。如果期望获得全局信息,Il(-)可以通过分配权重来激活,以获得更大的eNRFs,并选择性地利用输入特征。另一方面,当捕捉局部环境时,随着eNRF的变小,激活的权重趋于集中:以k=5为例,Il(Θl)i,j在全局环境中可以是[1, 0, 1, 0, 1],在局部环境中可以是[0, 0, 1, 1, 0]。.通过这种方式,eNRF可以被自适应地调整。
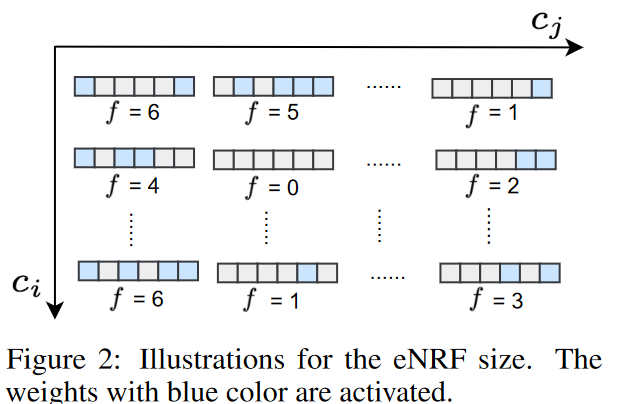
DSN架构
拟议的DSN模型由三个稀疏CNN模块组成,每个模块包括一个动态稀疏CNN层和一个1×1 CNN层。在堆叠的稀疏CNN模块之后,还有一个动态稀疏CNN层、两个自适应均值池层和一个1×1卷积层,作为DSN模型的分类器。整体架构如图3所示。
由于1×1卷积的eNRF大小总是等于1,所以第l个稀疏CNN模块的eNRF大小集S(l)等于动态稀疏CNN层的eNRF大小集,S(l)满足0≤min(S(l)),max(S(l))≤k。那么,三个稀疏CNN模块连续堆叠的eNRF大小集可以用RF描述如下。
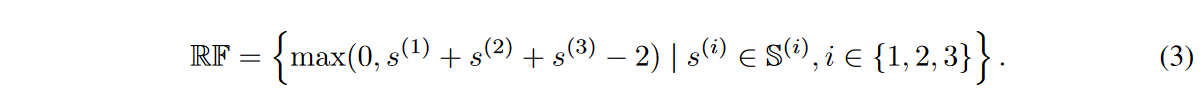
公式(3)表明,通过堆叠多个稀疏CNN模块,RF的大小可以线性增加,第l个动态稀疏CNN层的大小为S(l)增加。为简单起见,本研究中每个动态稀疏CNN层的核大小一致设置为k。然后,RF满足max(RF)≤3k - 2和0≤min(RF)。因此,通过增加稀疏CNN模块的k,可以增加堆叠的稀疏CNN模块的eNRF大小范围。
DSN模型的动态稀疏训练。
在这一节中,我们提出了一个学习策略,以发现需要激活的权重,以确保一个性能良好的RF。这意味着有必要考虑如何在拟议的DSN的训练过程中更新指标函数Il(-)。
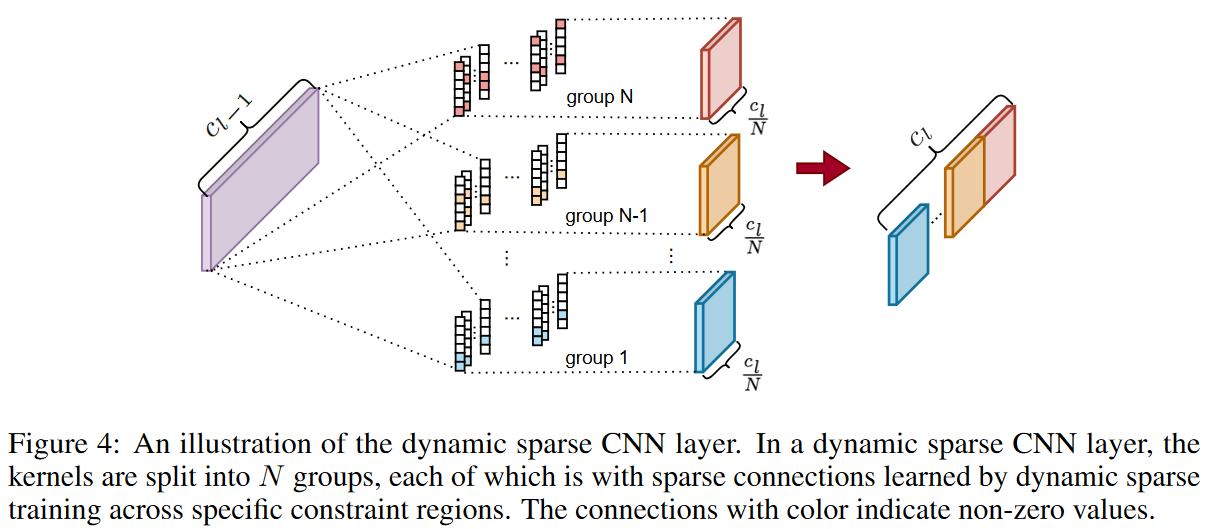
遵循DST方法的主要思想,提议的DSN模型从头开始训练,以保持内核的稀疏性。根据设计,在训练阶段,激活的权重总数不得超过Nl(1-S)。然而,我们在这里观察到,用DST方法很难捕捉到小的eNRFs,DST是一种逐层寻找激活权重的方法,特别是当稀疏比S较小时。基于这一观察,每个动力学解析的CNN层的核被分为不同的组,其相应的搜索区域也有不同的大小,如图4所示。 与DST方法相反,在DSN中,对激活权重的搜索是在不同的核组中分别进行的,这是一个更细粒度的策略。具体来说,第l层的内核权重Θl∈Rcl-1×cl×1×k沿输出通道被分为N组。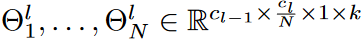
 也就是说,和相应的搜索区域 。
也就是说,和相应的搜索区域 。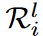
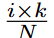
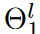 第l层中第i组的搜索区域被定义为该组中每个核的第一个位置。以k=6和N=3为例,第一组中的激活权重只在每个核的前两个位置,而在最后一组中,它们是在整个核中(如图4所示)。这样一来,各种eNRFs都可以被覆盖,减少了搜索空间,提高了搜索效率。
第l层中第i组的搜索区域被定义为该组中每个核的第一个位置。以k=6和N=3为例,第一组中的激活权重只在每个核的前两个位置,而在最后一组中,它们是在整个核中(如图4所示)。这样一来,各种eNRFs都可以被覆盖,减少了搜索空间,提高了搜索效率。
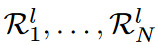 给定一个权重搜索区域和稀疏率S,所提出的DSN模型被训练,如算法1所示(见原始论文)。激活的权重在搜索区域内被探索,并在每个∆t迭代中被更新。根据余弦退火法的函数fdecay (t;α,T),更新的权重比例随时间衰减,如下所示。
给定一个权重搜索区域和稀疏率S,所提出的DSN模型被训练,如算法1所示(见原始论文)。激活的权重在搜索区域内被探索,并在每个∆t迭代中被更新。根据余弦退火法的函数fdecay (t;α,T),更新的权重比例随时间衰减,如下所示。
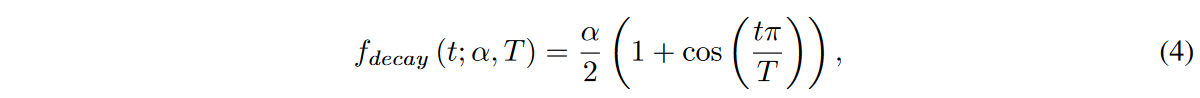
其中,α是更新的激活权重的初始百分比,t是当前的训练迭代,T是训练迭代的次数。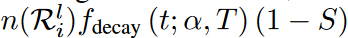
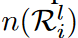
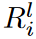 因此,在第t次迭代期间,第l层第i组的更新激活权重的数量为n,其中是该区域内可探索的权重数量。
因此,在第t次迭代期间,第l层第i组的更新激活权重的数量为n,其中是该区域内可探索的权重数量。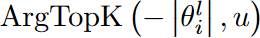
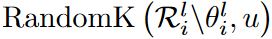 在更新激活权重的过程中,首先修剪了在确定的激活权重,然后在随机生成新的激活权重。
在更新激活权重的过程中,首先修剪了在确定的激活权重,然后在随机生成新的激活权重。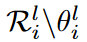
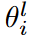
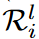 这里ArgTopK(v,u)给出了向量v中数值最高的u元素的索引,RandomK(v,u)输出向量v中随机u元素的索引,并表示除此之外的权值。
这里ArgTopK(v,u)给出了向量v中数值最高的u元素的索引,RandomK(v,u)输出向量v中随机u元素的索引,并表示除此之外的权值。
搜索激活的权重是直截了当的。首先,修剪小幅度的权重是很直观的。这是因为幅度小的权重的贡献是微不足道的或可以忽略不计的。另外,考虑到修剪的弹性,通过随机再生与修剪后的权重相同数量的新权重,可以更好地搜索激活权重。因此,与在学习前后修剪权重的方法相比,权重搜索是动态的、可塑的。
实验
数据集
每个数据集的细节如下。
- UCR 85档案中的单变量TS数据集:该档案由85个单变量TS数据集组成,这些数据集从不同领域(如健康监测和遥感)收集而来,具有特征性和不同的复杂程度。训练集的实例数量从16到8926,时间步长分辨率从24到2709。
- 来自UCI的三个多变量TS数据集:EEG2数据集包含1200个实例,由两个类别和64个变体组成;人类活动识别(HAR)数据集包含6个类别,10299个实例和9个变体。和9个变体;每日运动数据集包含19个类别,9120个实例和45个变体。
实验设置和实施细节
使用Adam优化器进行优化,初始学习率为3×10-4,余弦衰减为10-4,训练了1000个历时,迷你批次大小为16。核组的数量,N,被设置为三个,以帮助覆盖小、中和大的eNRFs。每个设置重复五次,并报告平均结果。
结果和分析
表1-2显示了在单变量和多变量TSC基准上的表现。对于单变量TSC,可以看出,在UCR 85档案数据集上,在参数数量较少(如Params 3)和计算成本较低(如FLOPs)的情况下,所提出的方法在大多数情况下优于基线方法。对于多变量TSC,提议的DSN方法在EEG2和HAR数据集上取得了更好的性能,其中MLSTM-FCN在Daily Sport上的准确度高出0.46%。拟议的DSN的资源成本(Params和FLOPs)比基线方法的资源成本要小很多。

敏感性分析(例如在模拟中)
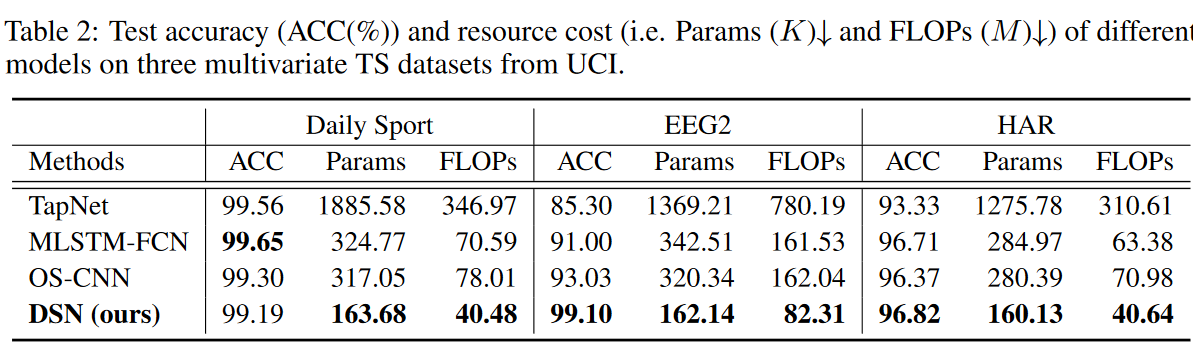
稀疏率的影响
从表3中,我们可以看到动态稀疏CNN层的稀疏率如何影响多变量TS数据集的最终测试精度和资源成本。在这里,我们分析了在不同的稀疏率(S∈[50%,80%,90%])和密集的DSN模型下测试精度和资源成本之间的权衡。请注意,密集模型的定义与DSN模型完全一样,整个内核是密集连接的。可以看出,模型中更多的参数并不一定意味着更好的性能。这主要是因为增加参数的数量会导致过度拟合,而在合适的稀疏比下,所需的感受野很容易被覆盖;以EEG2数据集为例,其性能随着稀疏比的降低而迅速下降。这个数据集被认为是对小的接受区的特征有很高的期望。实验表明,80%的稀疏度反映了准确性和资源成本之间的良好权衡,这也是这里DSN模型的动态稀疏CNN层的默认设置。
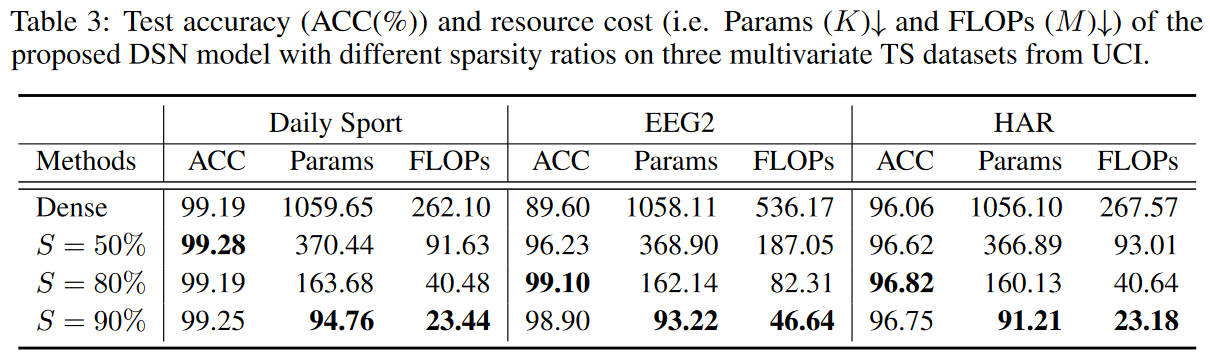
架构的有效性。
为了说明DSN结构对最终性能的影响,通过采用通常用于评估TSC的临界差分图进行了详细的比较;从图5来看,具有四个动态稀疏CNN层、每层有177个输出通道的DSN模型始终比其他结构好可以看出,它的表现比其他结构更好。提出的具有更多输出通道的模型似乎对保持网络的容量很重要,但与其他模型相比需要更多的参数和FLOPs。这突出了准确性和计算效率之间有趣的权衡。实验表明,具有四个动态稀疏CNN层和每层141个输出通道的DSN模型是性能和资源成本之间的权衡,这也是这里DSN模型的默认设置。
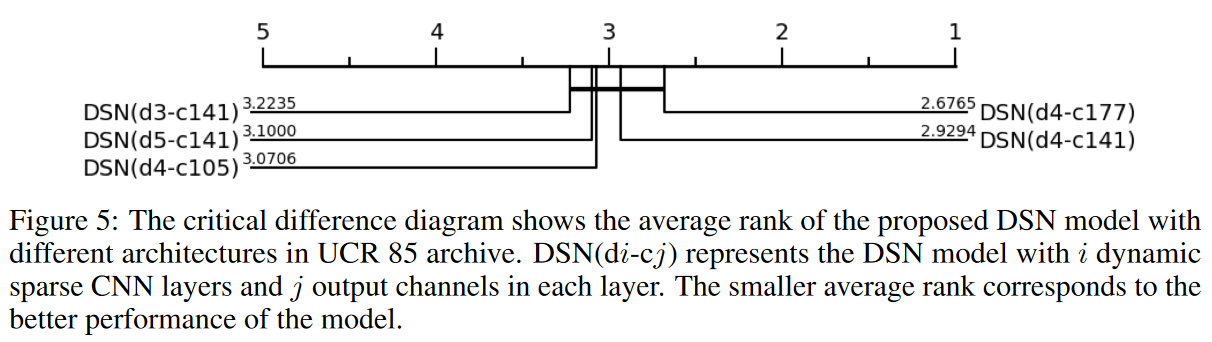
核心小组的有效性。
如图6所示,在没有内核组的情况下训练DSN会阻碍对小eNRF的捕捉,不能保证在预期有局部信息的数据集上有满意的表现,如EEG2。此外,随着稀疏率S的降低,大RFs被大部分占去的现象变得更加严重,有组和无组训练之间的性能差异增加,如表4所示。通过分组内核,可以在所有数据集上实现不同的RF覆盖率和广告精度。

零散的研究
动态稀疏训练的有效性。
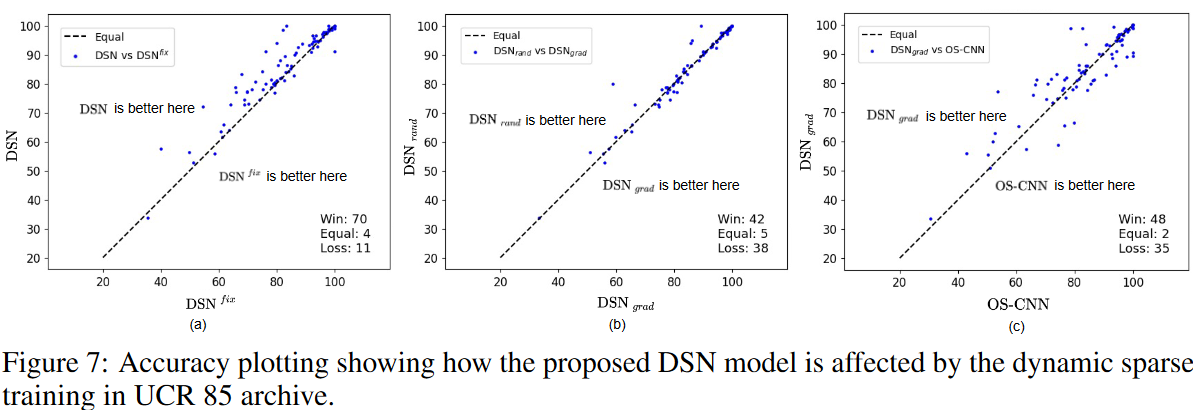
此外,还研究了动态稀疏训练对DSN方法的影响:进行了一项消融研究,将DSN与静态变体进行比较,该变体在初始化激活权重后的训练过程中固定拓扑结构(即DSNfix)。换句话说,公式(1)中的指标函数Il(-)在训练过程中不被更新,图7(a)所示的结果显示,DSN模型在UCR 85档案中几乎优于DSNfix,表明是通过动态稀疏学习学习了适当的激活权重及其值结果显示,DSN模型几乎总是优于DSNfix。
与其他DST方法的案例研究。
同样,我们分析了所提出的DSN方法在其他DST方法中的有效性,如RigL,它以最大的梯度而不是随机地增长权重;从图7(c),我们可以看到,根据梯度增长权重(即DSNgrad)在UCR 85档案的大多数情况下都能胜过OS-CNN方法。此外,如图7(b)所示,DSNgrad的表现与随机增长权重的方法(即DSNrand)一样好。请注意,DSNrand是本文提出的方法的主要设置,这是因为它不需要在任何时候计算全部梯度。综上所述,所提出的DSN及其细粒度的稀疏性策略可以很容易地与现有的DST方法相结合,并显示出在未来通过与其他先进的DST方法相结合而进一步改进的潜力。
激活权重的可视化。
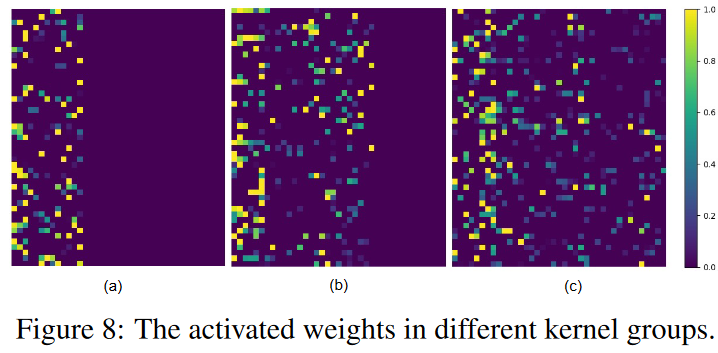
图8显示了在HAR数据集上进行稀疏训练后DSN模型的归一化激活权重。(a), (b)和(c)对应于第一个动态稀疏CNN层的三个核组的激活权重,图中每一行代表一个核。可以看出,每个内核的权重都是稀疏的,可以在之前定义的约束区域内激活。
摘要
本文提出了一种用于时间序列分类(TSC)的动态稀疏网络(DSN),可以通过训练来适应不同的感受野(RF)大小,而不需要进行超参数调整、与最近的基线方法相比,DSN模型以较低的计算成本实现了最先进的性能。所提出的DSN模型提供了一个可行的解决方案,弥补了各种TSC的资源意识和有效的相邻接收场覆盖之间的差距,并有可能激励各领域的其他研究人员。



与本文相关的类别






