用GARCH预测波动率!
三个要点
✔️使用GARCH进行波动率预测
✔️在印度国家证券交易所(NSE)上市的10只股票的波动率预测
✔️非对称GARCH模型比对称GARCH模型更准确
Volatility Modeling of Stocks from Selected Sectors of the Indian Economy Using GARCH
written by Jaydip Sen, Sidra Mehtab, Abhishek Dutta
(Submitted on 28 May 2021)
Comments: Accepted at IEEE ASIANCON'2021.
Subjects: Computational Finance (q-fin.CP); Machine Learning (cs.LG); Statistical Finance (q-fin.ST)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
波动群是一个重要的特征,对股票市场的行为有重大影响。
在本文中,我们提出了几个基于广义自回归条件异方差(GARCH)框架的波动率模型,对在印度国家证券交易所(NSE)上市的10只股票的波动率进行建模。
这些股票选自印度经济中的汽车和银行部门,对其各自部门在NSE的行业指数有重大影响。本文介绍了一系列基于广义自回归条件异方差(GARCH)方法的波动率模型。
利用2010年1月1日至2021年4月30日期间的NSE历史股票价格数据,我们在印度经济的两个最重要的部门--汽车部门和银行业--中各选择了前五只股票,并建立了一个模型。我们建立了几个GARCH模型,进行了微调,然后在样本外数据上进行了回测。
该研究有两个特点。
第一篇提出了一系列GARCH模型,这些模型的构建、微调和回测使用了印度股票市场各行业超过十年的真实股票价格数据。
其次,我们提供一个基准来比较本研究中所研究的两个部门的波动性。
通过正确了解两个行业的波动性,潜在的投资者可以了解行业的相关风险和收益。
相关研究
已经提出了相当多的基于GARCH(1,1)框架的模型,并且观察到这些模型中残差的广义分布在评估一个系列的波动性时比其他残差模型更准确。一些研究发现,非对称的GJR-GARCH模型在波动性高的时候会产生更准确的条件方差预测,但在现实世界中大多是EGARCH模型在非对称波动性的情况下产生更准确的预测。
据观察,基于GARCH的波动率模型产生了更稳定和稳健的预测,而基于熵的预测的敏感性更高。对印度经济的15个重要部门的回报分析是基于一个基于深度学习的LSTM网络模型的预测输出。
研究显示,快速消费品行业仍然是最有利可图的行业,但电力行业的总收益最低。也有人提出了一个多变量GARCH模型来分析几个同期时间序列的波动性。
数据和方法
本研究采用的方法包括十个步骤。下面将更详细地描述这些步骤中的每一步。
数据提取
使用panadas模块的DataReader API从雅虎财经网站提取股票价格数据。
例如,如果我们想从雅虎财经网站上提取在NSE上市的Maruti Suzuki的股价记录,从开始日期到结束日期,包括最高价、最低价、开盘价、收盘价、成交量和调整后的收盘价等属性,需要的python代码如下 maruti = web.DataReader ('MARUTI.NS', 'yahoo', start, end)[['High', 'Low', 'Open', 'Close', 'Adj Close']]。 对于所有问题,开始日期是2010年1月1日,结束日期是2021年4月30日。
赫斯特指数和波动率的计算
在提取股价记录后,计算收盘价时间序列的赫斯特指数。赫斯特指数是对一个时间序列的长期行为的衡量。它测量时间序列的不同滞后值之间的自相关,并计算自相关随着滞后值的减少而减少的速度。在这些计算的基础上,Hurst指数计算出一个指标,以确定时间序列是否在向平均值强烈回归,或在向上到向下的方向聚集。在这里,Hurst指数是用一个计算最大100滞后期的自相关的函数为所有股票计算的。
在根据股价的收盘指数计算出股票的Hurst指数后,就可以计算出该系列的波动率。
每日波动率是通过计算每日回报值的标准差来确定的。月度和年度波动率的计算方法是将每日波动率分别乘以21的平方根和252的平方根的系数,假设一个月有21个工作日,一年有252个工作日。
研究回报率和回报率对数序列的统计特性
在这一步骤中,计算了回报率系列和回报率对数系列。
回报系列是用Python中的pct_change函数计算的。首先将对数函数应用于股票的收盘价,从而计算出对数回报系列:回报系列、对数回报系列、其量化-量化图、自相关函数(ACF)图和部分自相关函数(PACF)。剧情。
拟合一个具有恒定平均值和正态分布残差的GARCH(1,1)模型
在这一步,我们为股票价格的时间序列构建一个波动率模型。首先,我们构建一个具有恒定均值和正态分布残差的GARCH(1,1)模型。这种类型的GARCH模型可以用(1)来表示。
第一个项ω代表与长期平均波动率相对应的常数方差,系数α代表时间t-1的残值平方的影响,系数β代表时间t-1的方差对时间t的波动率的影响。
![]()
在GARCH模型中,残差被用作波动性冲击(突然的变化)。在这一步的GARCH(1,1)模型中,我们假设残差遵循均值为零的正态分布。时间t的残差由(2)给出。
(2),它代表了时间瞬间t的回报,是回报系列的平均值。
![]()
我们拟合了一个GARCH(1,1)模型,其均值为常数,残差为正态分布。我们确定GARCH模型的参数ω、α和β的值以及它们各自的p值。我们还确定了模型的Akaike信息准则(AIC)。
Akaike信息准则(AIC)...使用观察值和理论值(残差)之间的差异来评估统计模型的预测能力的一种统计方法。数值越小,拟合度越高。
拟合一个GARCH(1,1)模型,其均值为常数,残差为倾斜的t分布。
由于股票收益率和对数收益率的值通常不遵循正态分布,我们通过假设残差遵循倾斜的t分布而不是正态分布来微调步骤4中构建的GARCH模型。
我们还通过将skew-t误差分布的波动率与GARCH(1,1)模型的日收益率作对比,测试了GARCH(1,1)模型的准确性。
对数回报系列的最佳ARMA模型的识别
在这一步,我们找到最适合股票价格对数回报系列的自回归移动平均线(ARMA)模型。
创建一个ARMA残差与GARCH(1,1)的拟合模型
一个最佳的ARMA模型被拟合到对数回报系列中,一个GARCH(1,1)模型被拟合到该系列中,并且均值为零(因为假设残差的均值为零)被拟合到ARMA模型的残差中。
利用GARCH模型的总结函数,我们得到了参数ω、α和β以及它们相应的p值。P值的显著性水平表明模型的拟合度。
将非对称波动率模型拟合到收益率序列中,并评估模型的拟合度
上一步构建的 GARCH 模型假定正面和负面新闻对波动率有类似的影响。这个假设在现实世界中并不成立,负面新闻对收益率波动的影响要大于正面新闻的影响。
为了有效地模拟收益率序列的波动性,GARCH模型必须具有处理不对称效应的能力。
为此,我们构建了两个不对称模型,(i)GJR-GARCH和(ii)EGARCH。
GJR-GARCH(1,1,1)模型由(3)给出。在(3)中,γ是一个不对称的参数,d_(t-1)是一个虚拟变量。如果前一次的残差为负数,虚拟变量的值为1,如果前一次的残差为正数,虚拟变量的值为0。
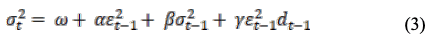
EGARCH(1,1,1)模型为(4)。
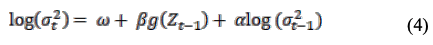
在(4)中,我们对函数值的评估如下
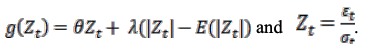
对于θ=0,冲击越大,条件方差就越大。如果(Z_t - E[Z_t]>0),条件方差就会减少。
另外,如果冲击小于平均值,那么对方差的冲击就是正数。将 GJR-GARCH 和 EGARCH 模型的预测波动率值与收益率序列作对比,看看预测波动率值与收益率序列的实际波动率值有多接近。
验证EGARCH波动率预测的准确性
这一步使用两种不同的预测方法,即扩大窗口法和固定窗口法,来计算预测值。本步骤使用两种不同的预测方法:扩大窗口法和固定窗口法,通过 EGARCH 模型计算 2021 年 1 月 1 日至 2021 年 4 月 30 日的样本外数据的预测波动率。结果如下
在固定窗口法中,未来5天的波动率值是根据前5天的波动率来预测的。在扩大窗口法中,训练窗口的大小随着预测轮次的增加而增加。最后,我们绘制了预测的波动率值以及预测的和实际的波动率值。
用样本外的数据回测EGARCH模型
在最后一步,我们针对回报率系列对EGARCH模型进行回测。我们对收益系列进行EGARCH模型的回测,并计算平均绝对误差(MAE)。
实验结果
我们对各种基于GARCH的波动率模型的性能进行了广泛的实验结果。
汽车行业
在NSE上市的五大汽车行业股票 在NSE上市的五大汽车行业股票是Maruti Suzuki India (MSZ), Mahindra and Mahindra (MAH), Tata Motors (TAM), Mahindra and Mahindra(MAH),(iii)塔塔汽车(TAM),(iv)Bajaj Auto(BAJ)和Hero Motocorp(HMC)。用于计算这五家公司各自的汽车行业指数的权重百分比如下:MSU-18.72, mmh-15.72, tmo-11.50, baj-10.89, hmc-7.99 。
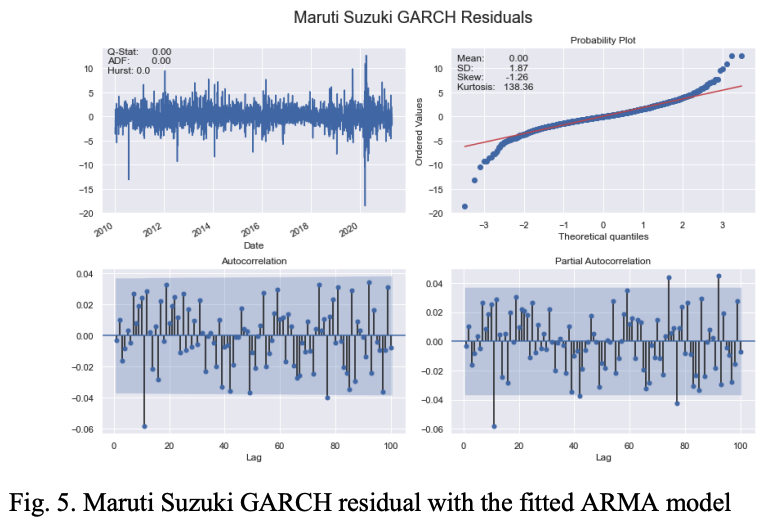
表一中只显示了每个行业中表现最好的股票的视觉效果。图1也说明了马鲁蒂铃木股票的对数回报系列的主要特征。
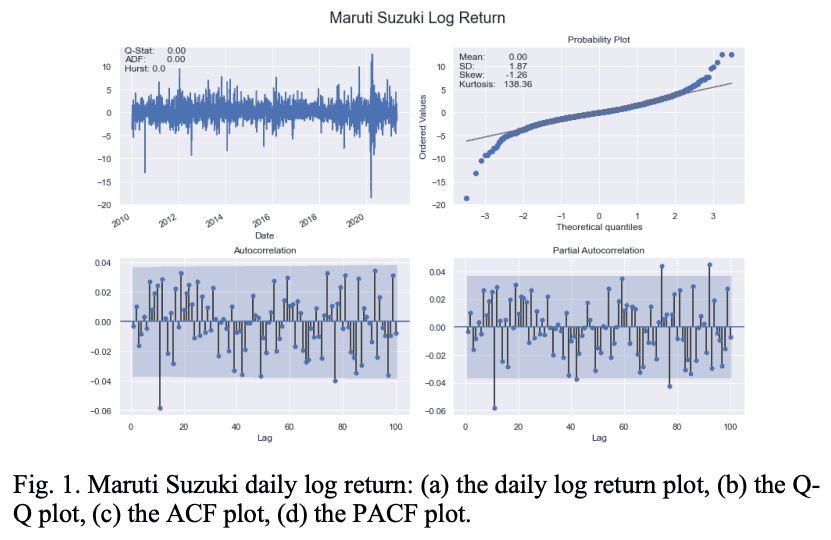
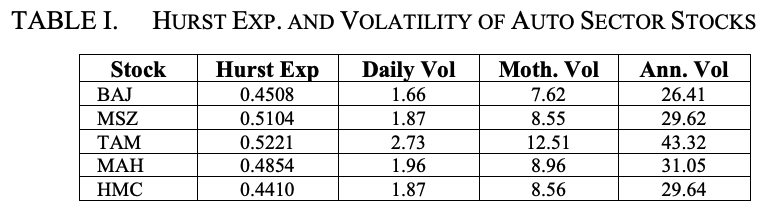
图2说明了Maruti Suzuki日波动率系列的特点。
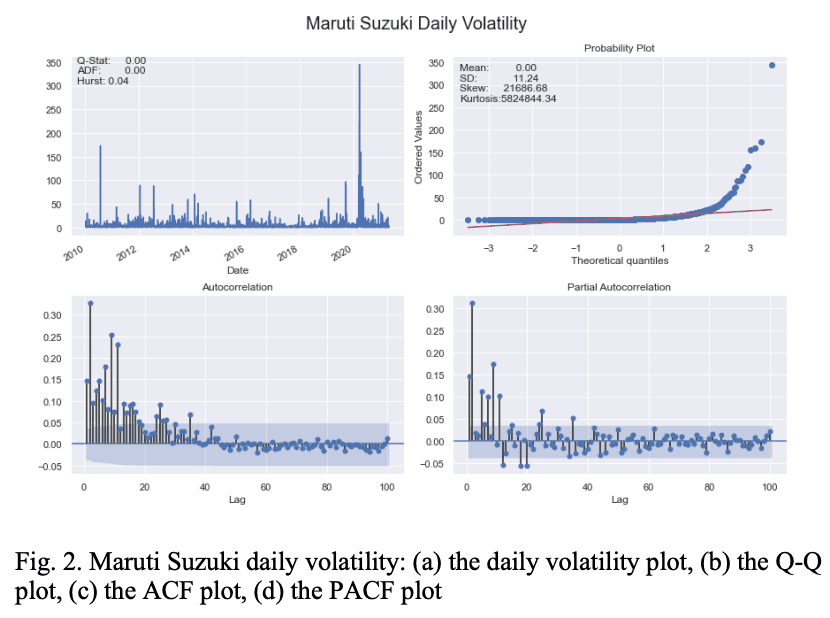
表一显示,BAJ、MAH和HMC股票 从表一来看,BAJ、MAH和HMC股票表现出均值回归的特征,而MSZ和TAM系列在Hurst指数方面表现出温和的均值回归特征。
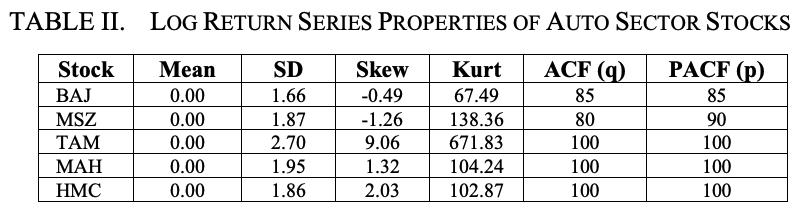
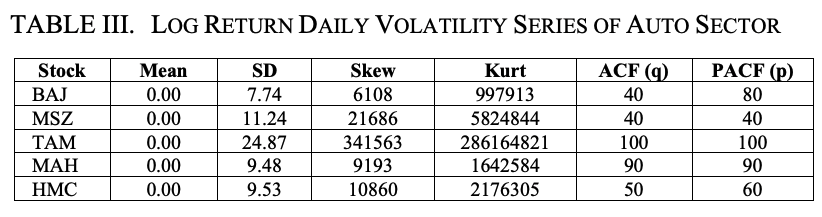
表二和表三显示了汽车行业股票的对数回报序列的重要统计属性和对数回报序列的每日波动性。从表二可以看出,所有股票的对数回报序列的平均值为零,但TAM的标准差、偏度和峰度是最高的。
表三中也有同样的观察。
因此,我们可以得出结论,TAM是汽车行业中最容易波动的股票。另一方面,BAJ被发现在该部门表现出最低的波动性。
每日对数收益率系列和每日波动率系列的ACF和PACF图在大滞后值时都是显著的;当ACF和PACF图与最大滞后值100作对比时,发现这些图在大滞后值时是显著的。这些图被发现在大滞后期是显著的。
接下来,我们用GARCH(1,1)模型拟合收益率序列,均值为常数,波动率模型为GARCH,误差分布为正态。表四显示了将GARCH(1,1)模型拟合到汽车行业五个股票的收益率序列的结果。表四中的各栏分别显示了股票的名称(Stock),将模型拟合到收益率序列数据所需的迭代次数(#Iterations),函数(即对数似然函数)的评估次数(Func Eval),梯度的更新次数(Grad Eval),以及对数似然函数的值(Log-like)。Likelihood)的对数似然函数。
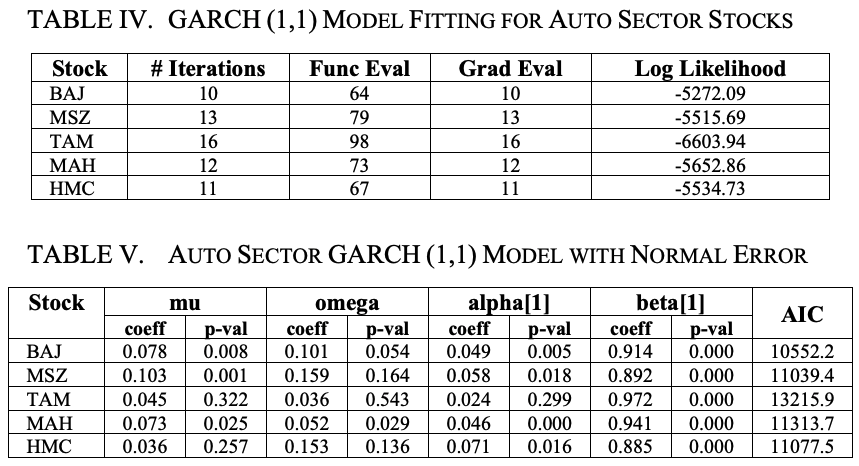
表五给出了具有恒定均值和正态分布误差的GARCH(1,1)模型的概况。
参数mu代表恒定的均值,omega代表与长期平均波动率相对应的恒定方差,alpha代表本轮中没有的新信息,beta代表上期的预测波动率。
α值越高,冲击的影响越大。另一方面,β值越高,冲击的持续时间就越长。
从表五中可以看出,MSZ的α值最高,TAM的α值最低。因此,冲击的影响在MSZ最大,在TAM股最小。另一方面,根据β值,发现TAM的冲击时间最长,HMC的冲击时间最短。
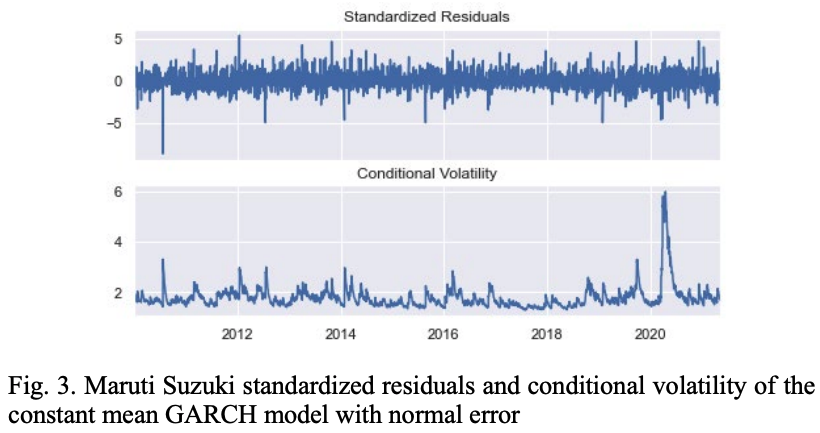
图3显示了用GARCH(1,1)模型计算的MSZ股票的标准化残差和条件波动率的模式,假设平均值不变,残差呈正态分布。
下一步是将误差模型从正态改为偏态。在金融时间序列中,残差几乎都不是正态分布,因此,假设残差遵循偏态t分布比假设残差遵循偏态t分布更符合实际。
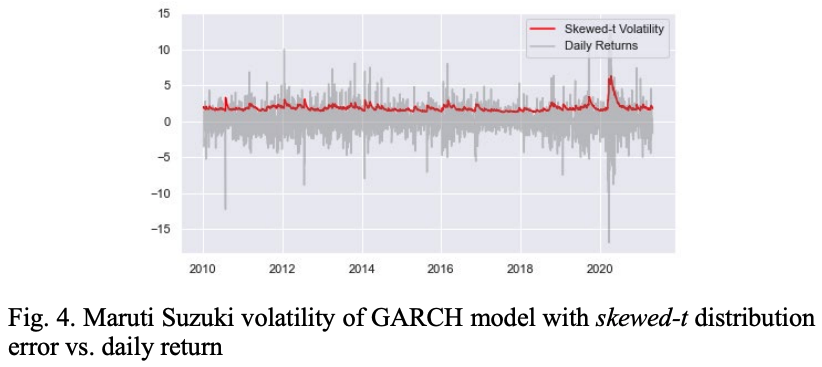
图4将GARCH模型的波动率与倾斜-t分布的残差与MSZ股票的每日回报值进行了比较。
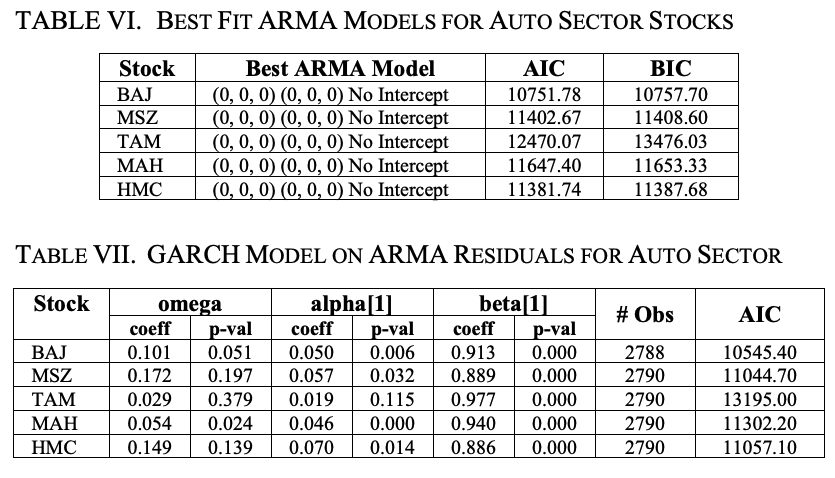
为了进一步完善GARCH(1,1)模型,我们用ARMA模型对股票收盘价的对数回报进行建模,拟合ARMA模型的残差,并用新的GARCH模型估计对数回报序列的波动率。
表六显示了结果:我们可以看到,对于所有五只股票,没有截距的ARMA(0,0,0)(0,0,0)是最佳拟合模型。这个ARMA的残差被拟合到一个零均值的GARCH(1,1)模型。
表七显示了五种股票的结果。
为了进一步提高GARCH模型的准确性,利用GJR-GARCH和EGARCH的概念构建了两个不对称的模型。首先,我们将GJR-GARCH模型适用于汽车行业的股票回报序列。均值是常数,残差是t分布的,波动率是不对称的GARCH模式。
这个模型中考虑的非对称冲击是一个滞后的冲击。表八给出了汽车行业中五只股票的模型概况。可以看出,几乎所有的伽马系数和贝塔系数都是显著的。
在汽车行业的GJR-GARCH波动率模型中,它被发现是最重要的预测因素。
最后,我们用EGARCH(1,1,1)构建另一个非对称波动率模型。与其他GARCH模型不同,EGARCH不要求α和β参数为非负值。因此,构建EGARCH模型需要的时间更少。表九给出了汽车行业股票的EGARCH模型的概况。可以看出,该模型非常符合股票的回报值,因为α、γ和β系数几乎都很显著。
表十显示了汽车行业股票的GJR-GARCH和EGARCH模型的BIC值;除了MAH,我们发现EGARCH模型的BIC低于相应的GJR-GARCH模型的BIC。图6显示了MSZ收益率序列,GJR-GARCH波动率和EGARCH波动率。我们可以看到,两个GARCH模型的表现几乎相同,两个模型都准确地捕捉了MSZ收益率序列的波动性。
使用扩大的和固定的滚动窗口方法,我们预测了从2021年1月1日开始的80个数据点的MSZ回报系列的波动性。结果显示在图7中。可以看出,这两种预测方法给出了相同的预测结果。
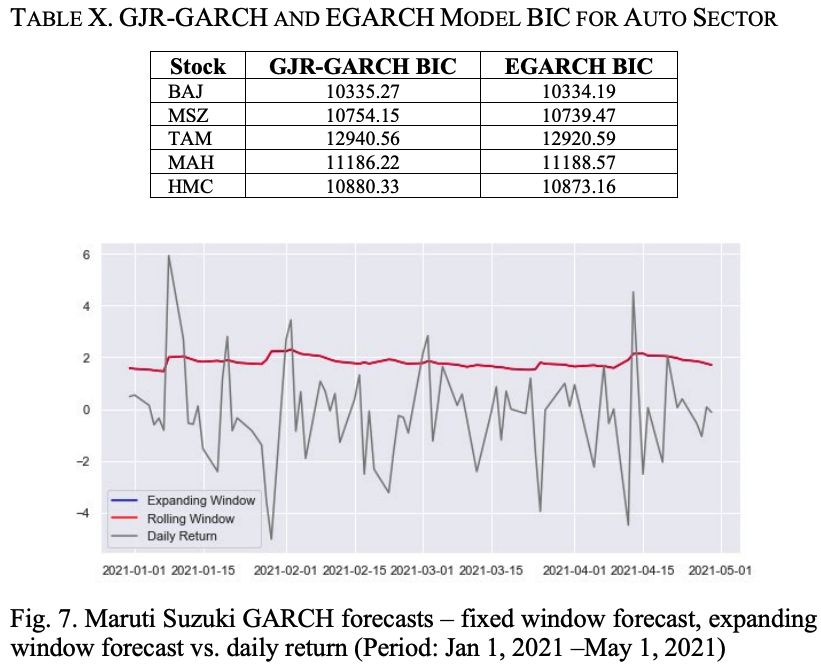
为了评估EGARCH模型对汽车行业股票回报系列的表现,我们对该模型进行了回测。
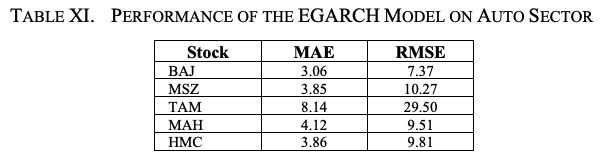
表十一显示了五只股票模型的平均绝对误差(MAE)和均方根误差(RMSE)。.TAM的MAE和RMSE的高值是由于股票的高波动性。
银行部门
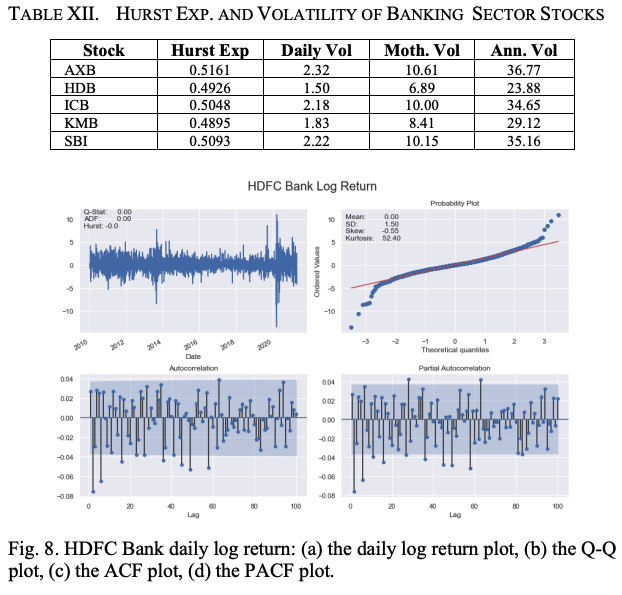
对计算新交所银行业指数贡献最大的五只股票及其各自的权重(%)如下。(i) HDFC银行(HDB)-27.41, (ii) ICICI银行(ICB)-21.09, Axis银行(AXB)-14.30, Kotak Mahindra银行(KMB)-13.02和印度国家银行(SBI)-11.74。表十二显示了银行部门五只股票的赫斯特指数、日、月和年波动率。可以看出,AXB、ICB和SBI表现出非常温和的趋势性,而HDB和KMB则是均值回归;AXB是波动性最大的股票,而HDB是五只股票中波动性最小的。
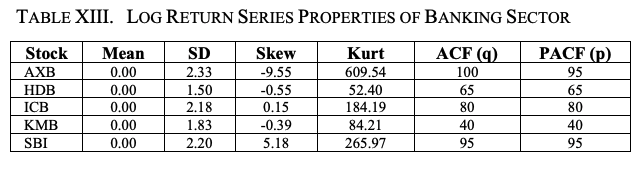
表十三和图八显示了银行业股票的对数回报系列的主要统计特性。虽然所有回报系列的平均值都是零,但我们发现AXB的SD是最大的。AXB的偏度和峰度的大小也是五个银行部门股票中最高的,表明它是银行部门股票中最不稳定的。
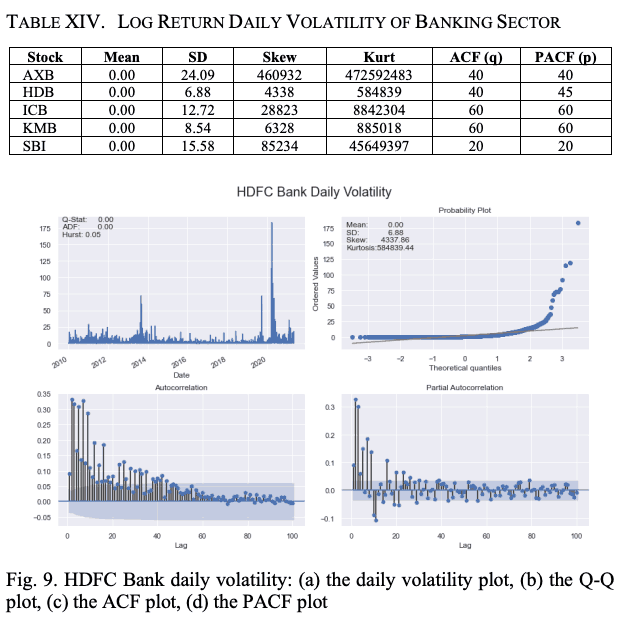
ACF和PACF图的最大滞后值为100。表十四和图九显示了每只股票的对数回报系列的波动特征。我们再次看到,每日对数回报波动率的平均值都是零;AXB的对数回报系列波动率的SD、偏度和峰度值都是最高的。
与汽车行业股票的情况一样,我们将常数GARCH(1,1)模型适用于回报率序列,并对残差进行正常分布。
表十五列出了银行部门五只股票的模型拟合结果。表十五中列名的含义与前面介绍的表四中列名的含义相同。
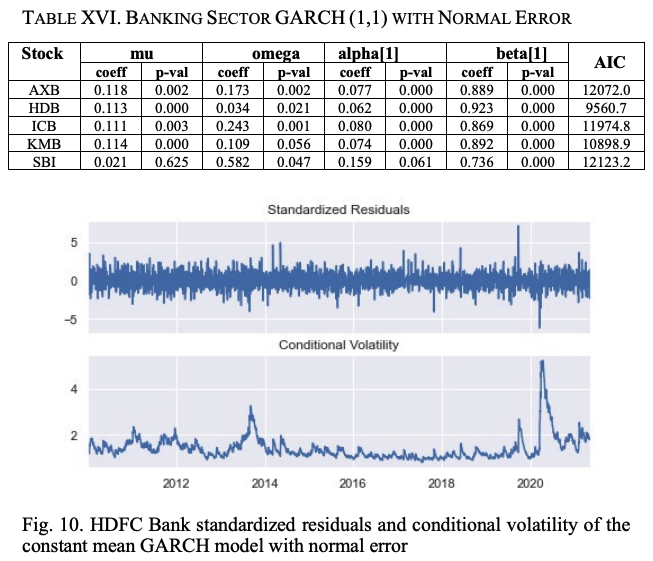
表十六显示了银行业股票的常数均值GARCH(1,1)模型与正态分布残差的汇总情况。如前所述,参数mu、omega、alpha和beta分别代表恒定平均值、长期恒定方差、上一轮残值的平方系数和上一轮波动率预测的方差系数。
α值越高,冲击对波动的影响越大,β值越高,影响的有效期越长。我们发现,SBI的α值最高,HDB的参数值最低。这是最低的组屋。因此,冲击的影响对SBI是最大的,对HDB是最小的。就β值而言,建屋局受冲击影响的时间最长,而SBI受冲击的时间最短。
用GARCH(1,1)模型计算的建屋局股票收益率序列的标准化残差和条件波动率见图10。这个GARCH模型是在两个假设的基础上构建的。
(i)回报系列的平均值是恒定的。
(残差为正态分布。
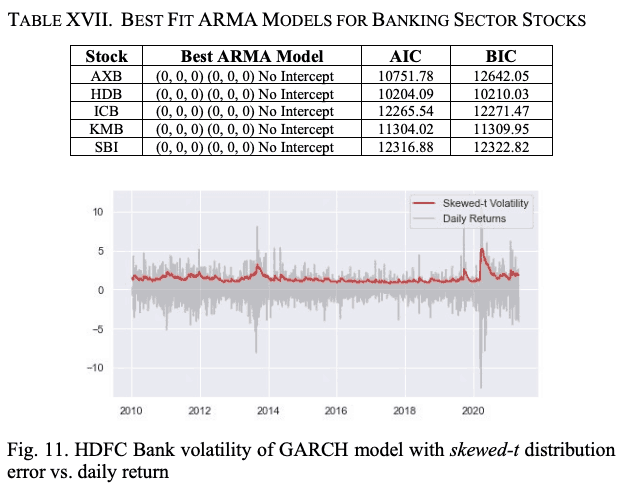
为了使模型更加真实,就像我们对汽车行业股票所做的那样,我们在构建GARCH模型时,假设残差遵循倾斜的t分布,而不是正常分布。图11显示了带有倾斜t分布残差的GARCH模型的波动率和建屋局股票的每日回报值。
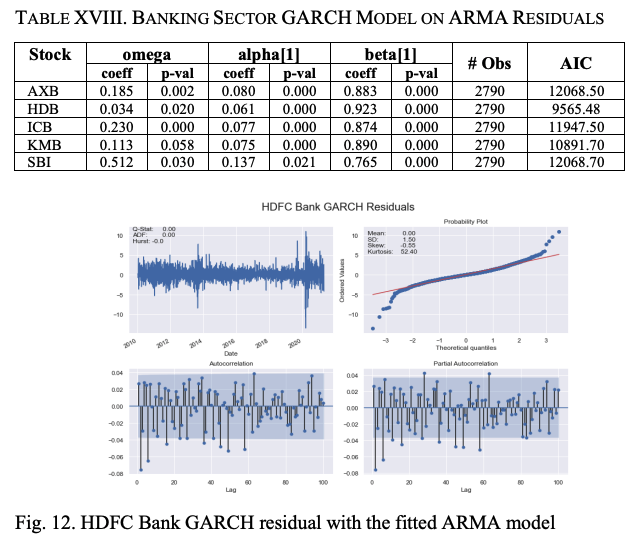
下一步是对GARCH(1,1)模型进行微调。
我们使用股票收盘价的对数回报构建了一个ARMA模型,将ARMA模型的残差与GARCH模型进行拟合,并估计对数回报序列的长期波动性。我们对股票的对数回报系列拟合ARMA模型。表十七显示了这些结果。我们发现,对于银行业的所有五只股票,以及汽车行业的股票,最好的拟合模型是无截距的ARMA(0,0,0)(0,0,0)。
GARCH模型的摘要见表十八,其中ω、α和β的大部分系数都显示出显著的P值,表明模型的拟合度非常好。与汽车行业股票的情况一样,我们构建了两个不对称模型,即EJR-GARCH和EGARCH,以使波动率模型更加准确。
首先,构建一个GJR-GARCH模型。建立了一个恒定均值的GJR-GARCH模型,残差遵循t分布,一个滞后的不对称冲击是显著的。
表XIX给出了这个模型的概述。
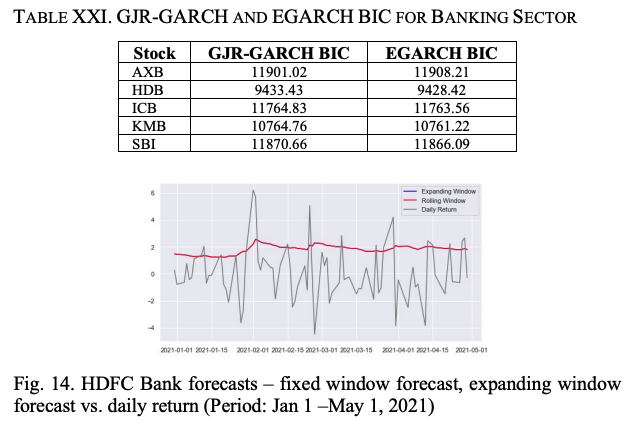
由于所有的gamma和beta系数都是显著的,很明显,一旗不对称冲击和一旗方差是模型的主要组成部分。表XX中EGARCH(1,1)模型的结果显示,该模型比GJR-GARCH(1,1)模型更适合,因为所有系数都是显著的。从表二十一可以看出,对于除AXB以外的所有股票,EGARCH模型的BIC都小于GJR-GARCH,对股价数据的拟合效果更好。
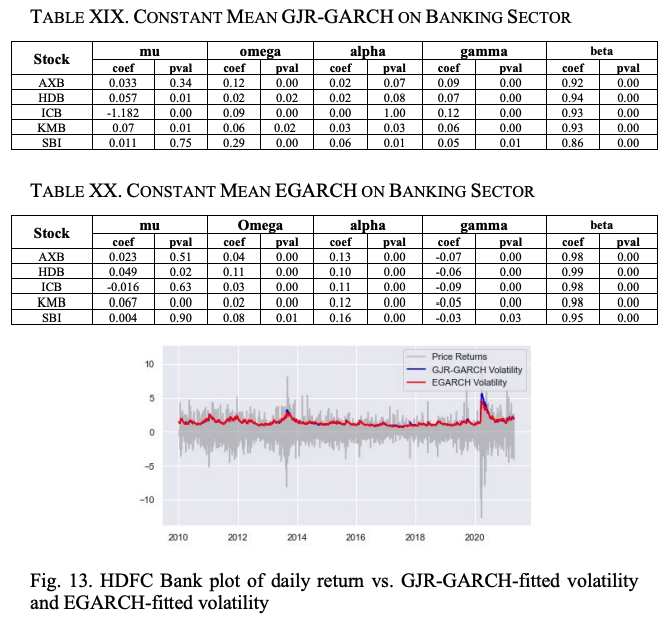
图14显示了HDB的回报系列和GJR-GARCH和EGARCH的波动率。
表二十二显示了EGARH模型对银行业所有五个股票的平均绝对误差(MAE)和均方根误差(RMSE)。可以看出,该模型对样本外的数据表现得非常好。
 最后
最后
在本文中,我们提出了几个基于GARCH的不同变体的波动率模型。这些模型是根据2010年1月1日至2021年4月30日的历史股票价格数据构建的。
2021年,从印度国家证券交易所的汽车和银行业中选择股票。在对模型进行微调后,对样本外数据进行了回测,以评估其预测股票未来波动的准确性。非对称GARCH模型被发现优于对称模型,但EGARCH被发现给出了最准确的结果。



与本文相关的类别
.JPG)





