
利用量子计算(退火机器)进行时间序列数据聚类。
三个要点
✔️ 这是一篇与日本大学和富士通公司合作撰写的关于时间序列数据聚类的论文。
✔️ 利用量子计算机(退火机器)实现了更快更准确的时间序列数据聚类。
✔️ 与现有的两种方法相比,在线分布式数据集和流量测量图像数据集的聚类特性得到了证实。
Clustering Method for Time-Series Images Using Quantum-Inspired Computing Technology
written by Tomoki Inoue, Koyo Kubota, Tsubasa Ikami, Yasuhiro Egami, Hiroki Nagai, Takahiro Kashikawa, Koichi Kimura, Yu Matsuda
[Submitted on 26 May 2023 (v1), last revised 18 Jul 2023 (this version, v3]
Comments: 13 pages, 4 figures
Subjects: Signal Processing (eess.SP); Computer Vision and Pattern Recognition (cs.CV); Fluid Dynamics (physics.flu-dyn)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述。
时间序列聚类是一种强大的数据挖掘方法,可在缺乏有关聚类的先验知识的情况下挖掘时间序列数据。大量海量时间序列数据被获取并用于各种研究领域。因此,需要计算成本较低的聚类方法。
本文的一大特色是将量子计算机(退火机)中使用的量子计算技术应用于这种聚类。退火机在高速、高精度解决组合优化问题方面优于传统计算机,有望实现现有方法难以实现的聚类。
本研究提出了一种利用退火机的新型时间序列聚类方法。所提出的方法有助于将时间序列数据平等地分类为彼此接近的聚类,同时保持对异常值的稳健性。
此外,该方法还可应用于时间序列图像。建议的方法与现有的在线分布式数据集聚类标准方法进行了比较。在现有方法中,每条数据之间的距离是根据欧几里得距离度量计算的,聚类是使用 k-means++ 方法进行的。两种方法的结果不相上下。
此外,所提出的方法还应用于一个信噪比约为 1 的流量测量图像数据集,该数据集含有大量噪声。尽管信号变异性很小(约为 2%),但所提出的方法仍能有效地对数据进行分类,且聚类之间没有任何重叠。
另一方面,现有标准方法和专为流量测量数据设计的条件图像采样(CIS)方法的聚类结果显示出重叠的聚类。结果表明,建议的方法优于其他两种方法,证明了它作为一种优秀聚类方法的潜力。
介绍。
聚类是一种功能强大的数据挖掘技术,可在缺乏足够先验知识的情况下将数据归类为相关组别。特别是在处理时间序列数据时,聚类技术被称为时间序列聚类。关于时间序列聚类的研究有很多,综述论文对这些研究进行了总结。(论文引用 2,7-10)此外,网络上也有几个时间序列聚类库,并被广泛使用。根据这些文献,时间序列聚类被定义为 "在无监督的情况下将给定的时间序列数据集划分为簇,从而根据某种特定的相似性度量将同类时间序列分组的过程称为时间序列聚类"。
时间序列聚类通常采用三种主要方法:基于原始数据库/形状的方法、基于特征的方法和基于模型的方法。这些方法在初始计算步骤上有所不同。基于原始数据/形状的方法直接使用原始数据进行聚类,而基于特征的方法则将原始数据转换成低维特征向量。基于模型的方法假定时间序列数据是由随机过程模型生成的,模型参数是根据数据估算的。当聚类非常接近时,基于模型的方法的性能就会降低,因此通常使用原始数据库方法和基于特征的方法。后续步骤包括计算两组数据、特征向量和模型之间的相似度或距离。
然后使用机器学习技术,根据测得的相似性和距离将数据分组。常用的时间序列数据聚类算法包括分区、分层、基于模型和基于密度的聚类算法。在分区聚类算法中,k 均值聚类是应用最广泛的算法之一。它的主要优势在于计算成本低。不过,这种方法需要用户预先确定聚类的数量。分层聚类算法不需要预先确定聚类的数量。不过,一旦使用分割或聚合方法分割或合并了聚类,就无法对其进行调整。自组织图和隐马尔可夫模型等神经网络方法被用作基于模型的聚类方法。除了上述聚类越接近性能越差的缺点外,这些方法的计算成本也很高。基于密度的方法,如基于密度的带噪声应用空间聚类(DBSCAN),不需要预先确定聚类的数量,而且对异常值具有鲁棒性。
然而,众所周知,由于难以选择正确的参数,这些方法都会受到维度诅咒的影响。
建议方法
本研究提出了一种基于退火机的新时间序列聚类方法。与传统机器相比,量子退火和模拟退火等退火机器能更快更准确地解决组合优化问题。因此,所提出的方法有望实现现有方法难以完成的聚类任务。拟议方法的一个独特之处在于,它能将时间序列数据平等地划分为密切相关的聚类,同时保持对异常值的鲁棒性。此外,该方法专门设计用于将周期性时间序列图像平等地划分为多个相位范围。这是因为考虑到时间序列数据相对于周期的持续时间较长,每个阶段都假设有足够数量的图像。
在聚类计算中,我们使用了富士通公司的第三代数字退火器(DA3),它是量子启发计算技术之一,DA3能够解决二次无约束二元优化(QUBO)问题,聚类问题可以表述为一个伊辛模型,等同于QUBO问题。DA3 可在多达 100 kbits 的大型问题空间中提供解决方案,其中一个解决方案来自 "UEA & UCR 时间序列分类存储库",另一个解决方案来自作者以前关于卡尔曼涡旋的数据。这包括捕捉 STREET 的流量测量图像数据。之所以特别选择流量测量数据,是因为这些数据一般都是高维数据(约 106),并且含有测量噪声。在聚类过程中,采用了原始数据库和基于特征的方法。此外,还将结果与现有的标准方法进行了比较,特别是在线 "tslearn "和条件图像采样(CIS)方法(仅流量测量数据)。
结果和讨论
对在线提供的时间序列数据集进行聚类。
图 1 展示了所提方法在 UEA 和 UCR 时间序列分类库中 "作物 "数据集分类中的应用。 "tslearn "的 "TimeSeriesKMeans "函数和使用建议方法的聚类结果如图 1 所示。农作物 "数据集包含 24 个聚类。不过,这里显示的是两个代表性聚类的结果。在该数据集中,正确的分类结果已知,并显示在图 1 中。此外,还计算了每种方法的集合平均数据。如图 1(a)所示,提议的方法成功地对数据进行了分类,而使用现有标准方法(tslearn)得到的结果显示分类效果不佳。因此,计算了拟议方法和 tslearn 分类结果的均方误差(RMSE)。如图 1(a)所示,拟议方法和现有方法的均方误差分别为 0.013 和 0.015。这进一步证实了拟议方法优于标准的现有方法。另一方面,如图 1(b)所示,拟议方法和现有方法的均方根误差分别为 0.013 和 0.009。在这些条件下,拟议方法不如现有方法。然而,如图 1(b) 所示,由于正确数据的方差较大,分类本身就很困难。因此,可以得出结论,拟议方法提供的结果与现有方法相当。
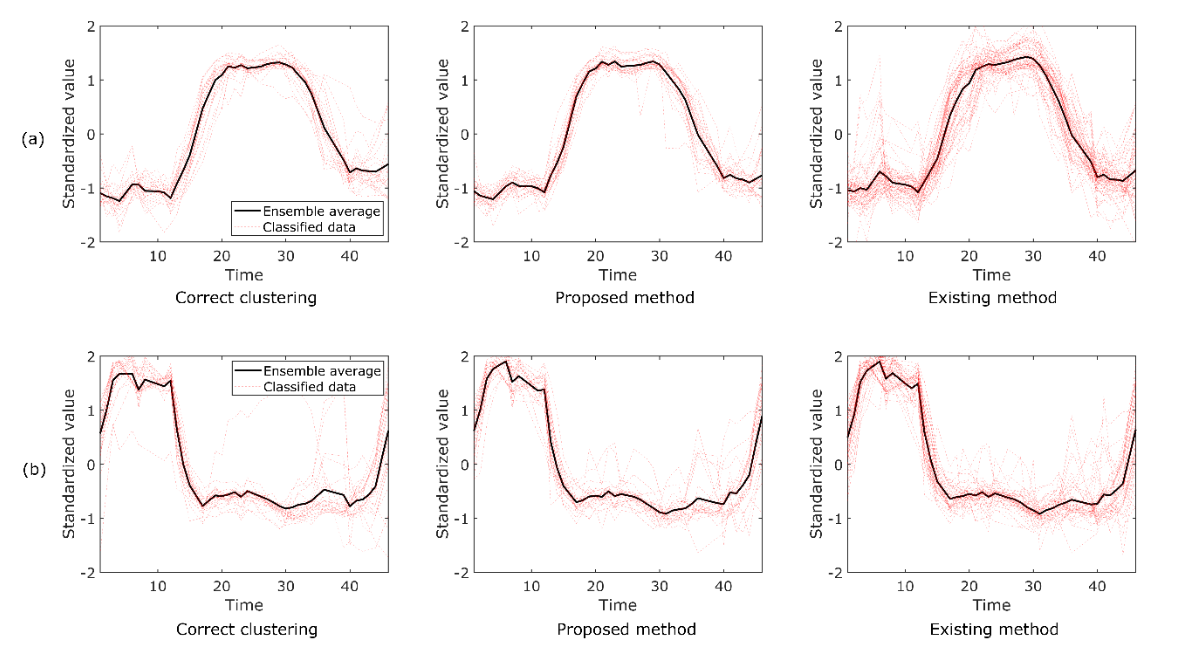
| 图 1:在 UEA 和 UCR 时间序列分类库中的 "作物 "数据集上,建议方法和现有方法的典型聚类结果。图中(a)和(b)分别显示了存储库中标记为第 1 类和第 17 类的数据。 |
流量测量时间序列数据集的聚类。
在本研究中,该方法被应用于一个流量测量数据集,以证明其对噪声数据的有效性。典型的数据快照如图 2 所示,图像显示其中包含大量噪声,信噪比约为 1。
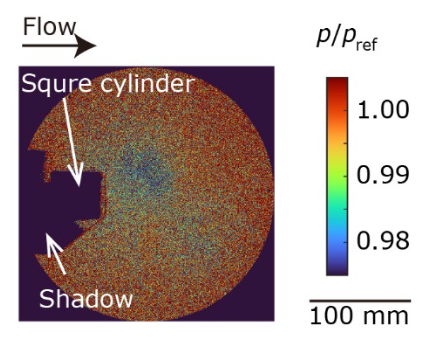
| 图 2:按大气压力𝑝归一化的压力𝑝 Inoue et al. |
在本研究中,使用了所提出的 "tslearn "方法和 CIS 方法,将这些时间序列数据分为九个聚类。聚类结果如图 3 所示,图中数据采用多维缩放比例构造(MDS)方法以二维散点图表示;在 MDS 计算中,数据 𝐱𝑖和 𝐱j 之间的距离表示为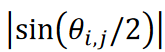 ,其中 |a| 表示 a 的绝对值,
,其中 |a| 表示 a 的绝对值,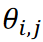 是对应于数据向量𝐱𝑖 和 𝐱j 之间的夹角。由于这里使用的卡尔曼涡街数据集是一个具有单一最大距离的周期现象,因此数据沿半径为 1/2 的圆分布。如图 3 所示,所提出的方法成功地对数据进行了分类,没有出现重复。
是对应于数据向量𝐱𝑖 和 𝐱j 之间的夹角。由于这里使用的卡尔曼涡街数据集是一个具有单一最大距离的周期现象,因此数据沿半径为 1/2 的圆分布。如图 3 所示,所提出的方法成功地对数据进行了分类,没有出现重复。
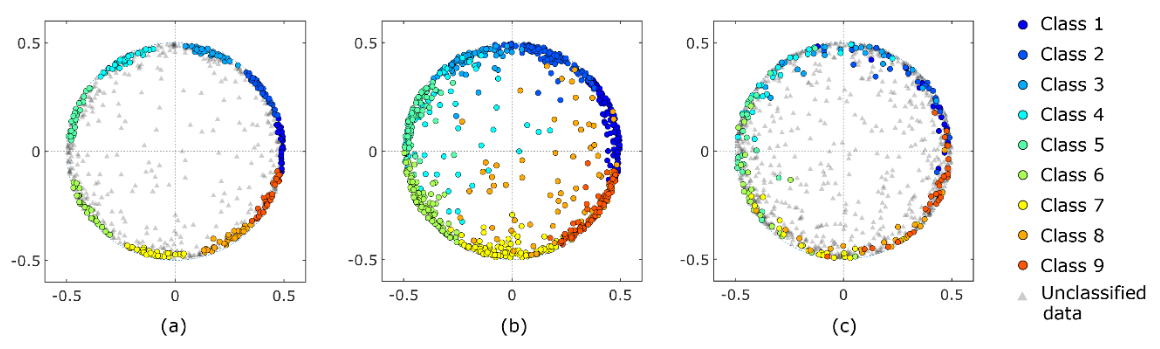
| 图 3:MDS 的二维散点图。(a) 拟议方法的结果,(b) 现有标准方法(tslearn)的结果,(c) CIS 方法的结果。 |
数据点被平均分为若干组,组与组之间的大小相近。偏离半径为 1/2 的圆的数据点被视为异常值,因为这些数据被视为偏离周期现象的干扰。然而,现有的标准方法将异常值归入其中一个群组。这在计算数据的集合平均值时是不合适的;在 CIS 方法中,只对圆圈上的数据进行分类。然而,一些聚类显示出重叠区域,没有形成单独的聚类。基于密度的方法,如基于密度的噪声应用空间聚类(DBSCAN),是众所周知的强大聚类方法。然而,DBSCAN 将圆圈上的数据点划分为一个单独的聚类。
图 4 显示了集合平均压力分布。拟议方法(图 4a)和 CIS 方法(图 4c)能很好地提取周期性涡旋的发展,尽管压力波动只有 2%。另一方面,用标准方法获得的压力曲线无法准确提取周期性运动。例如,在第 2 阶段和第 3 阶段之间,位于上侧的漩涡突然消失,而在第 5 阶段和第 6 阶段之间,位于上侧的漩涡则逆转了流向(图 4b)。这种差异是由于图 3b 中观察到的涡团重叠造成的。对拟议方法和 CIS 方法在涡旋中心的最小压力进行了比较,因为压力会随着涡旋的出现而减小。建议方法的集合平均压力为 p/pref = 0.982 ± 0.001,CIS 方法的集合平均压力为 p/pref = 0.984 ± 0.002,其中误差为标准偏差,pref 为大气压力。这一差异表明,在 CIS 方法中,由于在集合平均过程中也包含了不同阶段的数据,上述重叠簇削弱了漩涡。这些结果进一步证明,所提出的方法是分析周期现象的一种强有力的聚类技术。
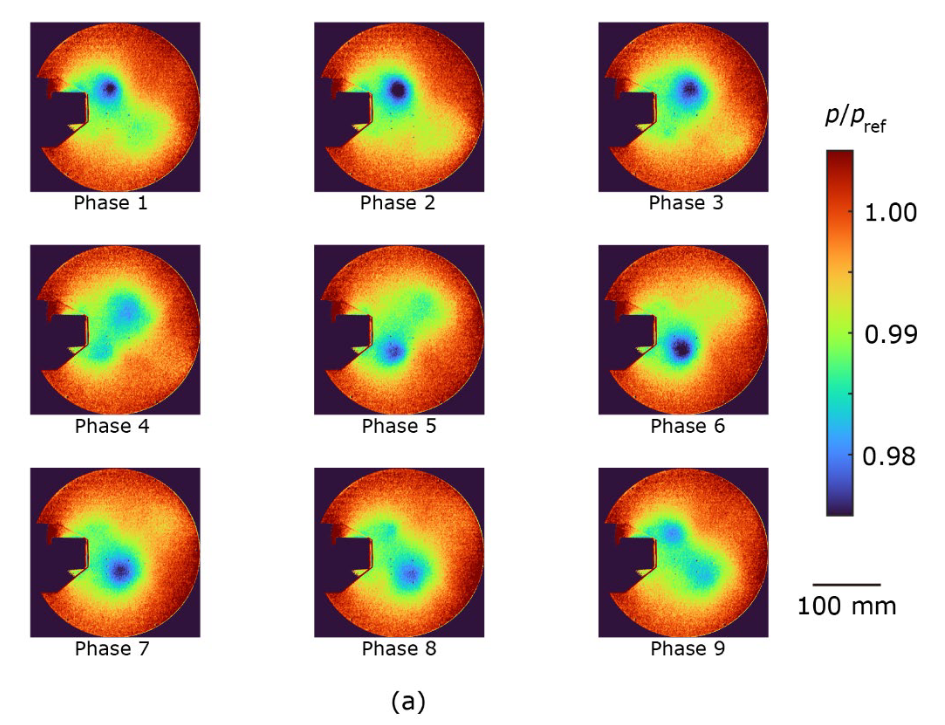
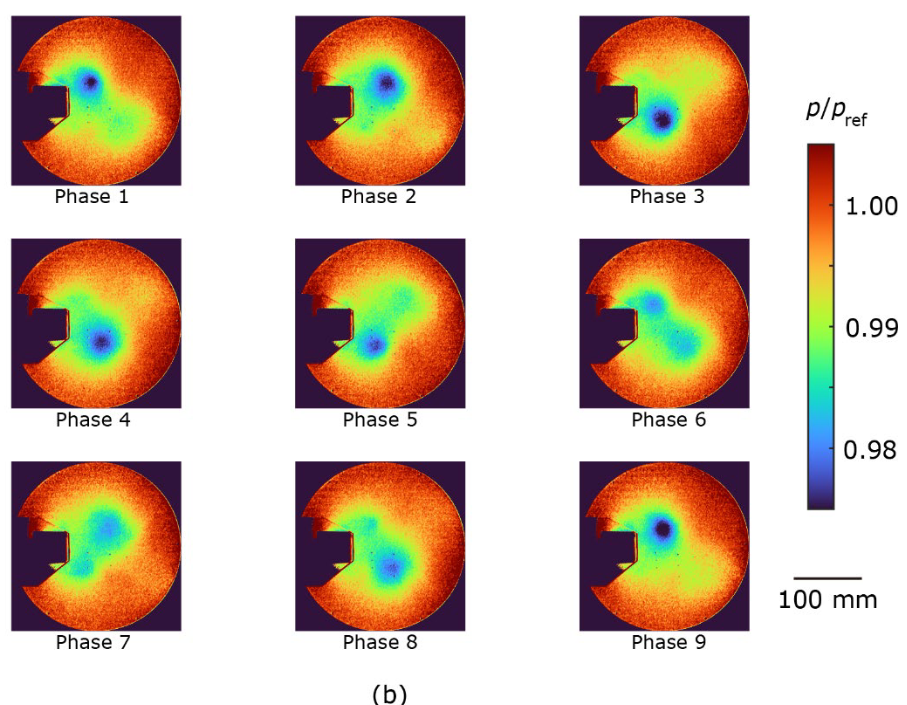
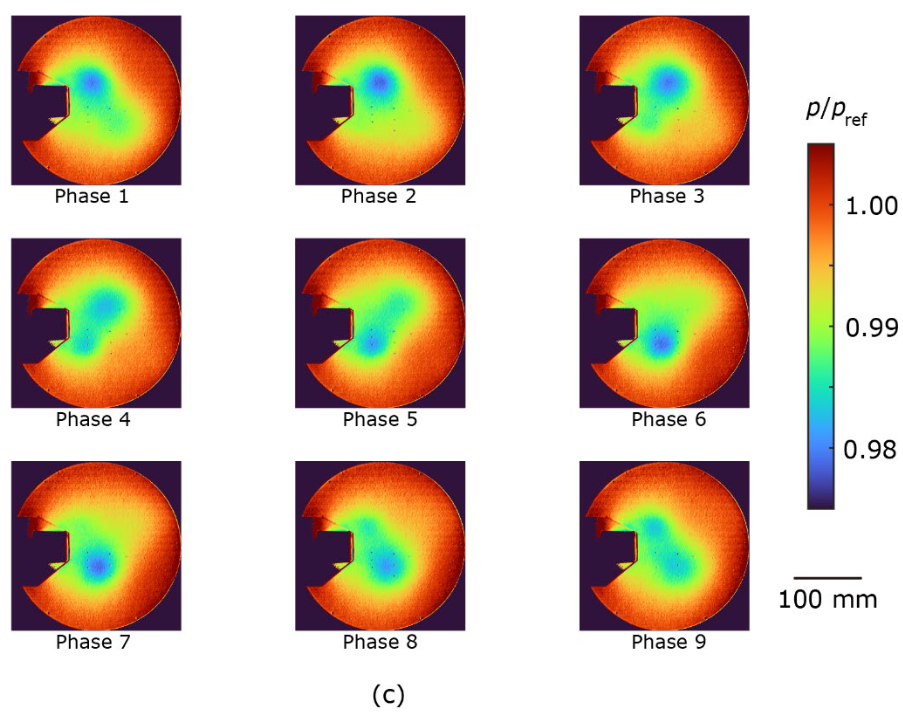
| 图 4:(a) 拟议方法、(b) 现有标准方法 (tslearn) 和 (c) CIS 方法的集合平均压力分布。压力 p 按大气压力前值归一化。 |
材料和方法
拟议的时间序列聚类方法。
我们提出了一种基于退火机的新聚类方法。我们重点关注时间序列数据分析中的原始数据库和基于特征的方法。 聚类问题的哈密顿描述如下:
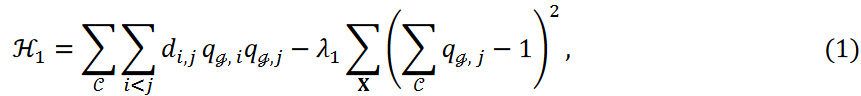
在哪里?

𝐱i与𝐱𝑗之间的相似度或距离的倒数记为𝑑𝑖,𝑗,λ1为超参数。和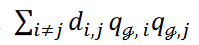 表示属于一个聚类的两个数据点之间的相似度或距离的倒数之和。总和 ∑𝒞 表示等式 1 中第一项在所有聚类中的总和。通过
表示属于一个聚类的两个数据点之间的相似度或距离的倒数之和。总和 ∑𝒞 表示等式 1 中第一项在所有聚类中的总和。通过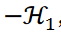 可将聚类最小化、
可将聚类最小化、
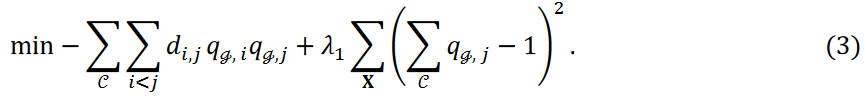
等式 3 中的第二项表示保证数据点只属于一个聚类的约束项。 𝜆1的值决定了这一约束的严重程度,该值越小,一些数据点就越有可能被视为异常值而不归入任何聚类。本研究考虑了以下最小化问题:
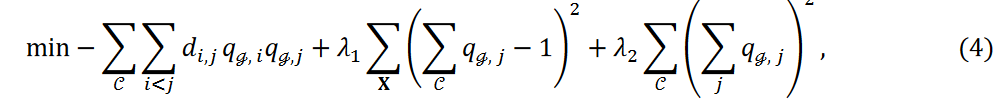 这里,等式 4 中新的第三项(新项)调整了归入每个群组的数据点数量。为便于记述,将其记为
这里,等式 4 中新的第三项(新项)调整了归入每个群组的数据点数量。为便于记述,将其记为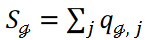 ,表示属于 Cℊ 聚类的数据点数量。等式 4 中的第三项可写成:
,表示属于 Cℊ 聚类的数据点数量。等式 4 中的第三项可写成:
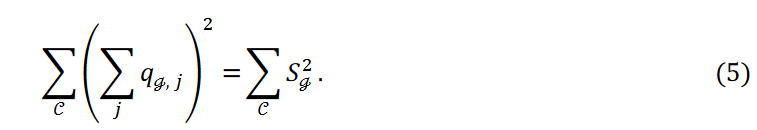
每个聚类所属数据点的平均数和方差分别用 𝜇 和 𝜎2表示。公式 5 的写法如下
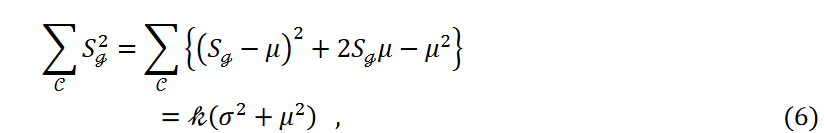
这里,数据点数 𝑛 和聚类数 k 是固定的,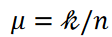 是一个常数。然后,随着方差的减小,即等式 4 中第三项的减小,数据点会被平均分到每个聚类中。
是一个常数。然后,随着方差的减小,即等式 4 中第三项的减小,数据点会被平均分到每个聚类中。
示范性时间序列数据集
建议的聚类方法应用于两个时间序列数据集。其中一个数据集名为 "农作物",是从 UEA 和 UCR 时间序列分类库中获取的。
这些时间序列数据来自 FORMOSAT-2 卫星拍摄的图像。数据集由 24 个农业用地覆盖图类别组成,每个类别对应其时间演变。本研究使用了 "tslearn "中的 "TimeSeriesKMeans "函数。该函数的参数为:簇数 24,度量(各数据之间的距离)为欧几里得,初始化方法为 k-means++,其他参数为默认值。这是一种标准的时间序列聚类方法。在提议的方法中,欧氏距离也被用作度量,度量的倒数被用来最小化方程 4 中的第一项。参数𝜆1 被设定为𝜆2 的约 100 倍,因为所有数据点都必须属于该数据集中的一个聚类。这一条件的结果是所有数据点都属于其中一个聚类(等式 4 中的第二项为零)。
本研究中使用的第二组数据是使用压敏涂层(PSP)方法测量获得的流动图像数据;PSP 是一种基于氧淬灭 PSP 涂层中染料发出的磷光的压力分布测量技术。测量的数据是方形圆柱体后面的卡尔曼涡街造成的压力分布。数据大小为 780 x 780 空间网格。流速为 50 米/秒,雷诺数为 1.1 x105。由于磷光强度波动较小,压力差过小,无法用 PSP 方法进行检测。而且测得的压力包含很大的噪声,需要从数据中减少噪声。众所周知,卡曼涡旋是一种周期性现象。时间序列聚类的目的之一是减少噪声并提取重要模式,因此我们将数据分为多个相位组,并在这些组内求取平均值。由于侧重于涡旋相位信息,因此采用余弦相似度量来评估数据之间的相似性;由于 PSP 数据是具有两个空间维度和一个时间维度的时间序列图像数据,因此将压力分布数据重新格式化为列向量。由此得到的时间序列 PSP 数据被写成 𝑛 时间序列数据 𝐱 = {𝐱1, 𝐱2 ⋯ , 𝐱𝑛} ,其中 𝐱𝑖 是对应于重塑压力分布的向量。由于测得的 PSP 数据含有大量噪声,因此在计算相似性时使用了去噪数据。根据文献,可以通过截断奇异值分解(SVD)来获得噪声较小的数据集。其中,数据矩阵 Y 是将时间序列中的𝐱𝑖向量排列后得到的,用 SVD 表示:

其中矩阵 𝐔 和 𝐕 是单元矩阵,上标 ⊤ 表示转置。矩阵 Σ 是奇异值降序排列的对角矩阵。众所周知,数据可以通过截断 SVD 近似如下:

其中 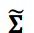 是第一对角矩阵,𝑟 × 𝑟 是截断秩。矩阵
是第一对角矩阵,𝑟 × 𝑟 是截断秩。矩阵 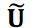 和
和 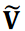 是与 相对应的还原矩阵。这样就得到了降噪后的时间序列数据矩阵
是与 相对应的还原矩阵。这样就得到了降噪后的时间序列数据矩阵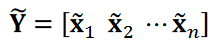 或时间序列数据
或时间序列数据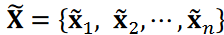 。这里,我们假设 r = 5,这是一个常用的截断值。余弦相似度 cos 𝜃𝑖,𝑗 的计算公式如下:
。这里,我们假设 r = 5,这是一个常用的截断值。余弦相似度 cos 𝜃𝑖,𝑗 的计算公式如下:

其中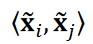 是
是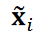 和
和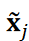 的内积,
的内积,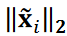 是
是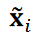 的 ℓ2 值。在本研究中,为了降低计算成本,只考虑了棱镜后面的压力分布。将
的 ℓ2 值。在本研究中,为了降低计算成本,只考虑了棱镜后面的压力分布。将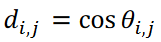 代入公式 4 并使用 DA3 计算聚类。参数 λ1设置为 λ2的几十倍,这样等式 4 中的每个项的大小都相近。在这些条件下,一些数据被归类为异常值。对同一群组中的图像进行集合平均,以提取重要模式。请注意,这里是对原始图像数据 X 进行平均以提取模式,而没有使用
代入公式 4 并使用 DA3 计算聚类。参数 λ1设置为 λ2的几十倍,这样等式 4 中的每个项的大小都相近。在这些条件下,一些数据被归类为异常值。对同一群组中的图像进行集合平均,以提取重要模式。请注意,这里是对原始图像数据 X 进行平均以提取模式,而没有使用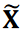 上的数据集。
上的数据集。
考虑到 cos 𝜃𝑖,j的范围在 -1 到 1 之间,我们引入了以下关系式 𝑟𝑖,𝑗,其范围在 0 到 1 之间:

其中,当 i = i(相同数据)时,1 -ri,j = 0。数据之间的距离度量定义为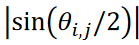 ,其中 |𝑗| 表示 𝑗 的绝对值,θi,j 是数据向量之间的角度。在这个距离度量中,最大距离为一。计算数据表时使用了这一距离度量。
,其中 |𝑗| 表示 𝑗 的绝对值,θi,j 是数据向量之间的角度。在这个距离度量中,最大距离为一。计算数据表时使用了这一距离度量。
时间序列数据也通过上述 "tslearn "的 "TimeSeriesKMeans "功能进行了分类。此外,还使用了专门针对 PSP 测量的 CIS 方法,根据压力传感器(一种采样率高于 PSP 的点式传感器)测量的压力数据,将时间序列数据分为几个相位组。换句话说,CIS 方法需要额外的传感器来进行聚类。对额外传感器的依赖可以说是 CIS 方法的局限性之一。
结论
提出了一种使用退火机的新聚类方法。在 QUBO 模型中添加了一个新术语,用于调整归入每个聚类的数据数量。QUBO 模型中添加了两个新数据集,一个是 UEA 和 UCR 时间序列分类库中的 "作物 "数据集,另一个是我们之前研究中的流量测量图像数据集。在对 "农作物 "数据集进行聚类时,我们采用了一种名为 "tslearn "的现有标准方法。在这种方法中,每个数据集之间的距离是根据欧氏距离计算的,聚类则是通过 k-means++ 算法计算的。比较拟议方法和现有方法的结果发现,拟议方法比现有方法显示的数据点变化更少。该数据集获得了正确的聚类结果。然后计算集合平均数据,并比较正确数据与集合平均数据之间的均方误差(RMSE)。结果表明,两种方法对该数据集的结果相似。
然后,将所提出的聚类方法应用于一个流量测量图像数据集,该数据集由卡尔曼漩涡造成的压力分布时间序列组成。在该数据集中观察到了周期性。该数据集的另一个特点是包含大量噪声,信噪比约为 1。为了进行比较,我们还使用现有的标准方法和专门为流量测量数据设计的条件图像采样 (CIS) 方法对该数据集进行了分类。尽管压力变化较小,约为 2%,但所提出的方法成功地对数据进行了分类,且聚类之间没有重叠。另一方面,现有方法和 CIS 方法都出现了簇间重叠,无法形成离散的簇。现有方法的数据集群之间存在大量重叠,在集合平均压力分布中,有些数据集群中的涡旋突然消失,有些数据集群中的涡旋则出现回流。在 CIS 方法获得的集合平均压力分布中,涡流减弱了。这些结果凸显了拟议方法在聚类周期现象方面的卓越性能。



与本文相关的类别






