
用于准确预测混合季节性变化和趋势的时间序列模型LaST。
三个要点
✔️ NeurIPS 2022年接受的论文。提出了LaST,一个包含多种波动趋势的时间序列数据的预测模型,包括季节性(周期性)波动和趋势
✔️ 将多种波动趋势分开,并使用变异推理逻辑识别每一种趋势
✔️ 在真实世界的数据上测试了性能,发现与之前的七个模型相比,结果更优
Learning Latent Seasonal-Trend Representations for Time Series Forecasting
written by Zhiyuan Wang, Xovee Xu, Weifeng Zhang, Goce Trajcevski, Ting Zhong, Fan Zhou
(Submitted on 30 Dec 2022)
Comments: NeurIPS 2022
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
这是一篇NeurIPS 2022年接受的论文。最近,人们试图通过将各种深度学习技术(如RNN和Transformer)纳入序列模型来提高时间序列的预测能力。然而,由于时间序列通常由多个相互交织的元素组成,因此仍然难以提取清晰的模式。受计算机视觉和经典时间序列分解中独立的变异自动编码器的成功启发,本文旨在推断一些描绘时间序列的季节性(周期性变化)和趋势成分的表征。为了实现这一目标,在变异推理(变异贝叶斯方法)的基础上,我们提出了LaST,其目的是在潜在空间中分离季节性和趋势的表示。此外,LaST监督和分离潜空间中的季节性和趋势表征,无论是就其本身还是就输入重构而言,并引入了一组辅助目标。广泛的实验证明,LaST在时间序列预测任务上取得了最先进的性能,与最先进的表征学习模型和端到端预测模型相比,LaST取得了最先进的性能。
注:关于变异贝叶斯方法的更多信息,请参见PRML(模式识别和机器学习)第十章。
介绍
由于时间序列数据的普遍性和重要性,最近开发了无数的深度学习预测模型来改善时间序列预测,吸引了研究人员的努力:这些方法基于RNN和变形金刚等先进技术,通常学习信号的每个时刻的潜在表示,然后预测器来得出预测结果,在预测任务中取得了重大进展。
然而,这些模型很难提取与时间模式(如季节性、趋势、水平)相关的准确和明确的信息,特别是在没有表示约束的监督的端到端架构中。因此,人们努力将变异推理应用于时间序列建模,事实证明,对具有概率形式的潜在表征的改进指导有利于下游的时间序列任务。然而,当时间序列数据中存在复杂的各种成分的共同演化时,由于神经网络中的高度纠缠,用单一的表征进行分析会导致表面的变量和缺乏模型的可重复使用性和可解释性。因此,虽然现有的高维表示方法提供了效率和效果,但它们牺牲了信息的利用率和可解释性,甚至可能导致过度拟合和性能下降。
为了解决上述局限性并探索一个新的分离式时间序列学习框架,本文利用了分解策略的思想,将时间序列数据分割成几个组成部分,每个组成部分都捕捉到一个潜在的模式类别。分解有助于分析过程,并揭示出更符合人类直觉的基本洞察力。基于这种洞察力,采取了与不同时间序列特征(这里是季节性和趋势)相对应的几个潜在表征,通过将序列制定为这些特征的总和,从中预测出结果。这些潜表征应尽可能独立,以避免模型对输入序列有足够的信息,但容易出现特征纠缠。
因此,在本文中,我们提出了一个新的框架LaST,用于学习时间序列预测的潜在季节性-趋势表征。LaST利用一个编码器-解码器架构,并遵循变异推理理论,学习时间序列的季节性和趋势的两个离散的潜在表征。该系统学习。(1) 从输入重建中分离出独特的季节性和趋势模式,这些模式可以很容易地从原始时间序列和商业措施中获得,并相应地设计一组辅助目标;和(2) 从表征本身出发,在保证输入数据和各自表征的一致性的前提下,最小化季节/趋势表征之间的相互信息(MI)。
本文的三个主要贡献是
- 基于变异推理和信息理论,设计了一种学习和分离季节性-趋势表征的机制,并在一个时间序列预测任务中实际证明了其有效性和对现有基线的优越性。
- 提出了一个潜在的季节性-趋势表示学习框架,即LaST。它将输入编码为一个分离的季节性-趋势表示,并提供了一个实用的方法来分别重建季节和趋势,避免了混乱。
- MI项被引入作为一种惩罚,并为其优化提出了新的可操作的下限和上限。下限改善了传统MINE方法中的偏向梯度问题,并保证了信息丰富的表示。上界提供了进一步减少季节-趋势表示的重叠的可行性。
表示潜在季节性趋势的学习框架
LaST使用季节性和趋势特征来学习解离,但该框架可以很容易地扩展,以适应有两个以上的成分需要解离的情况。
问题描述
考虑一个时间序列数据集D,由N个独立的序列组成,表示为X(i ) 1:T = {x(i ) 1, x(i) 2, - - , x(i) t, - - , x(i ) T },其中i∈{1, 2, ... ... }为单变量或多变量值,代表时间瞬间t的当前观测值(如价格或降雨量),其中每个x(i) t为单变量或多变量值,代表时间瞬间t的当前观测值(如价格或降雨量)。目的是推导出一个模型,输出适合预测未来序列Y = ˆ XT+1:T + τ的表示方法Z1: T。在下文中,当没有歧义时,上标和下标1:T被省略了。一个用于推断观察X和未来Y之间的可能性的模型,有一个潜在的表征Z,可以表述如下。
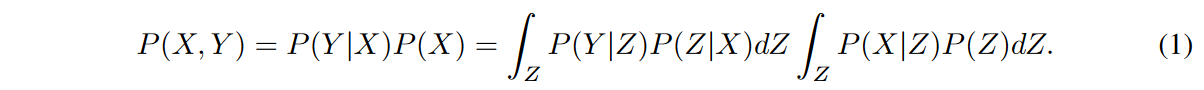
就变异推理而言,可能性P(X|Z)是由后验分布Qφ(Z|X)计算出来的,并通过以下证据下限(ELBO : 证据下限) 实现最大化。
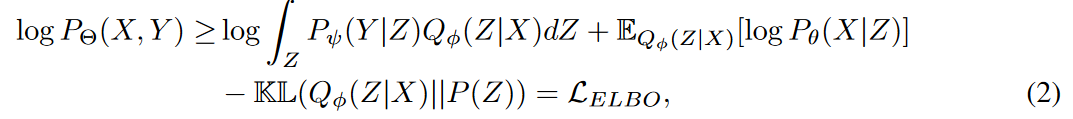
其中Θ由ψ 、φ和θ 组成,表示学到的参数。
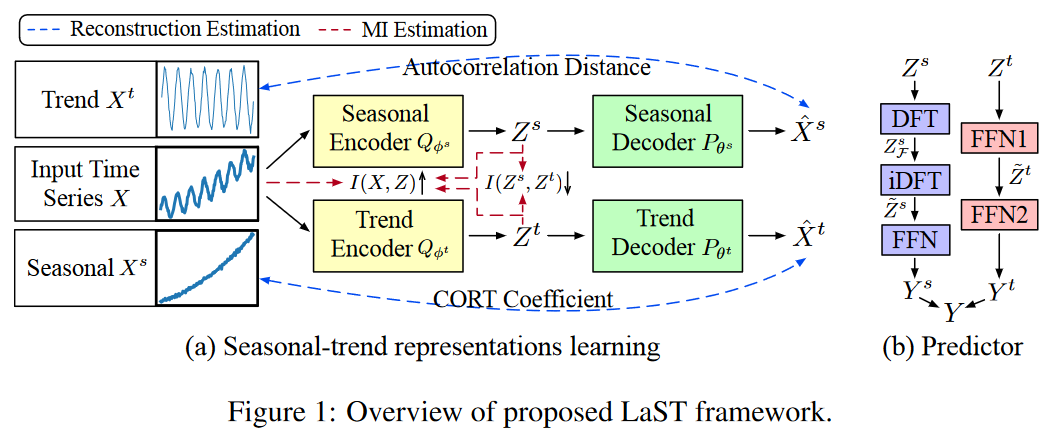
然而,这面临着纠缠的问题,不能明确地提取复杂的时间模式。因此,为了弥补这一局限性,在LaST中加入了分解策略,以学习季节性和趋势性的两个独立的表示。具体来说,时间信号X和Y被表述为季节性和趋势成分之和,即X=Xs+Xt。因此,潜伏表征Z被分解为Zs和Zt,假设它们是相互独立的,即P(Z)=P(Zs)P(Zt) 图1显示了LaST框架的两个部分:(a)表征学习以分离季节性-趋势表征(单独重建和MI约束)和(b)基于所学表征的预测。
定理1
有了这种分解策略,方程(2)(即ELBO)自然就有了以下的分解形式
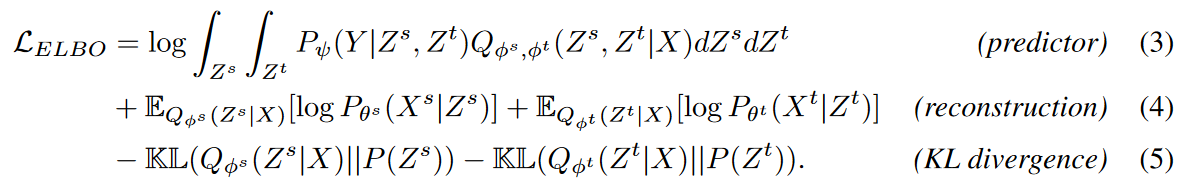
ELBO分为三个主要单元,即公式(3)、(4)和(5)。预测器进行预测并测量准确性(如L1或L2损失),而重建和KL发散则作为正则化条款提供,旨在改善所学的表示。这三个单元描述如下。
预测器
这个预测变量可以 被看作是两个独立部分的总和:![]() 和
和 ![]() 。在此,我们提出两种专门的方法来利用季节性-趋势表示,结合它们各自的特点。给定一个季节性的潜在表示Zs∈RT×d,季节性预测器首先使用离散傅里叶变换(DFT)算法来检测季节性频率。也就是说,Zs F = DFT(Zs) ∈ CF ×d,其中F = ⌊T +1 2⌋是由于奈奎斯特定理。 接下来,我们在频域向后延伸表示到未来部分,即~Zs = iDFT(Zs F ) ∈ Rτ ×d。给定Zt,趋势预测器提供一个前馈网络(FFN)f : T → τ,生成一个可预测的表示~Zt∈Rτ×d 将Zs和~Zt分别映射到Y s和Y t,用两个FFN终止预测器,以便通过它们的总和获得预测结果Y。
。在此,我们提出两种专门的方法来利用季节性-趋势表示,结合它们各自的特点。给定一个季节性的潜在表示Zs∈RT×d,季节性预测器首先使用离散傅里叶变换(DFT)算法来检测季节性频率。也就是说,Zs F = DFT(Zs) ∈ CF ×d,其中F = ⌊T +1 2⌋是由于奈奎斯特定理。 接下来,我们在频域向后延伸表示到未来部分,即~Zs = iDFT(Zs F ) ∈ Rτ ×d。给定Zt,趋势预测器提供一个前馈网络(FFN)f : T → τ,生成一个可预测的表示~Zt∈Rτ×d 将Zs和~Zt分别映射到Y s和Y t,用两个FFN终止预测器,以便通过它们的总和获得预测结果Y。
重构和KL发散
在这两个项中,KL发散可以通过使用先验假设的蒙特卡洛抽样来轻松估计。在这里,为了提高效率,我们使用广泛使用的设置,即两个先验分布都遵循N(0,I)。重建项不能直接测量,因为Xs和Xt是未知的。另外, 将这两个项 整合到![]() ,使得解码器更容易从任何表示中重建复杂的时间序列,从而导致混乱。
,使得解码器更容易从任何表示中重建复杂的时间序列,从而导致混乱。
定理2。
由于高斯分布的假设,重建损失Lrec可以在不利用Xs和Xt的情况下进行估计,方程(4)可以被以下方程所取代
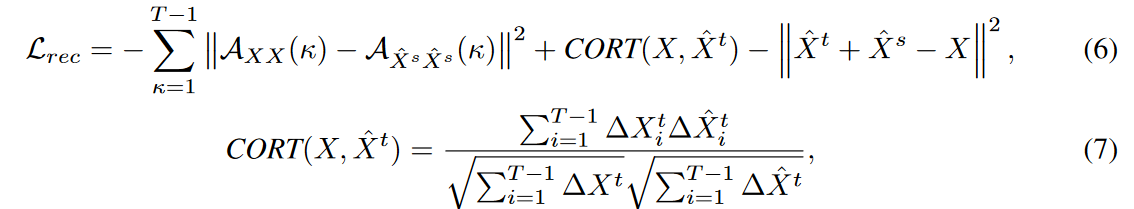
其中![]() 是滞后值κ 的自相关系数,CORT(X, ˆ Xt)是时间相关系数, ΔXi = Xi - Xi-1 是一阶差分。
是滞后值κ 的自相关系数,CORT(X, ˆ Xt)是时间相关系数, ΔXi = Xi - Xi-1 是一阶差分。
根据方程(6),重建损失可以被估计,反之,可以用来监督离散化表征学习。然而,我们发现这个框架仍然有一些不足之处。
(1) KL发散倾向于减少后验和先验之间的距离。如果建模能力不足,它往往会牺牲变异推理和数据拟合。此外,后验估计将很少有关于输入的信息,并可能导致与观察结果无关的预测。
(2) 季节性--趋势表达的非关联性被隔离重建间接推动,在这种情况下有必要对表达本身施加直接约束。
通过引入一个额外的相互信息正则化项,这些约束被放松了。具体来说,它增加了Zs、Zt和X之间的相互信息,缓解了分歧缩小的问题,并减少了Zs和Zt之间的相互信息,进一步分离了它们的表示。
LaST的最大化目标如下。
![]()
这里,I(-,-)代表两个表征之间的相互信息项。 然而,这两个相互信息项是不可追踪的。
优化的相互信息界限
现在我们 解决方程(8)中最大化I(X,Zs)和I(X,Zt)以及最小化I(Zs,Zt)的可追踪的相互信息量,并显示模型优化的下限和上限。
I(X,Zs)或I(X,Zt)的下边界
在以前探索MI下限的方法中,例如MINE,使用联合分布和边际之间的KL发散来定义一个基于能量的变异族,以实现一个灵活和可扩展的下限。这可以表述为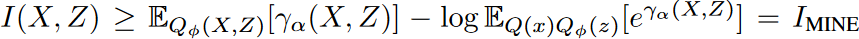 ,其中γα 可以是参数α的学习归一化准则,但由于参数化的对数项,梯度是有偏差的。 对数函数被其正切族所取代,这就改善了上述的偏向约束。
,其中γα 可以是参数α的学习归一化准则,但由于参数化的对数项,梯度是有偏差的。 对数函数被其正切族所取代,这就改善了上述的偏向约束。
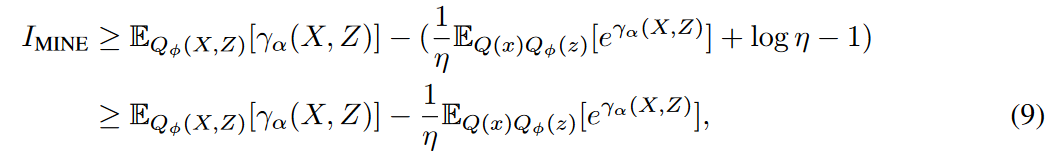
这里,η表示不同的切线。第一个不等式依靠的是一个凹陷的负对数函数。曲线上的值是切线上的值的上界, 当接触点 与自变量 的真实值重合时,即![]() ,是紧的。切线与自变量之间的距离越近,下限越大。因此,让 η成为 估计自变量的变异项
,是紧的。切线与自变量之间的距离越近,下限越大。因此,让 η成为 估计自变量的变异项![]() , 以获得尽可能大的下限。这个不等式 只有在
, 以获得尽可能大的下限。这个不等式 只有在![]() ,也就是说,γα 可以确定一对变量(X,Z)是从联合分布中取样还是从边际取样。与MINE一样,这个一致性问题可以通过神经网络的普遍近似定理来解决它可以通过神经网络的普遍近似定理来解决。因此,方程(9)为I(X,Z)提供了一个具有无偏梯度的灵活和可扩展的下限。
,也就是说,γα 可以确定一对变量(X,Z)是从联合分布中取样还是从边际取样。与MINE一样,这个一致性问题可以通过神经网络的普遍近似定理来解决它可以通过神经网络的普遍近似定理来解决。因此,方程(9)为I(X,Z)提供了一个具有无偏梯度的灵活和可扩展的下限。
I(Zs,Zt)的上边界
过去,在寻找相互信息含量的可追踪上界方面的努力很少。现有的上界可以通过具有已知概率密度的联合分布或条件分布(这里是Q(Zs | Zt), Q(Zt | Zs)或Q(Zs, Zt))来追踪。然而,这些分布缺乏可解释性,难以直接建模,导致上述上限的估计无法追踪。
为了避免直接估计未知的随机密度,我们为Q(Zs, Zt)引入了一个基于能量的变异族,并使用方程(9)中的归一化符号γβ(Zs, Zt)设定了一个可追踪的上界。具体来说,将γβ纳入上界ICLUB 中,得到I(Zs, Zt)的可追踪季节性趋势上界(STUB),其定义如下。
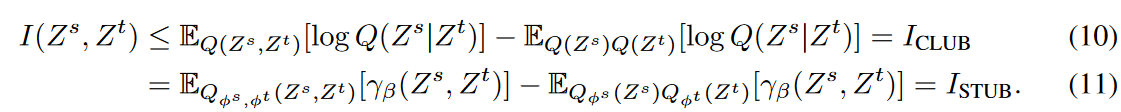
只有当Zs和Zt是一对独立变量时,方程(10)中的不等式才是严格的。这恰恰是ISTUB的充分条件,因为在独立情况下,MI和方程(11)都是零,这是季节性趋势纠缠的最优目标。批判γβ和γα一样,具有判别作用,但提供了一个反分,并将MI约束到最小。然而,方程(11)在学习参数β的过程中会出现负值,导致MI的上限不正确。 为了缓解这个问题 , 引入了一个 额外的惩罚项 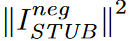 ,以帮助模型优化,并对ISTUB的负数部分进行L2损失 。
,以帮助模型优化,并对ISTUB的负数部分进行L2损失 。
实验
下面介绍了广泛的实验评估结果,将LaST与最新的基线进行了比较,同时还介绍了隔离研究和季节性趋势表现可视化的一系列经验结果。
设置
数据集和基线
在七个真实世界的基准数据集上进行了实验,包括以下四类主流时间序列的预测应用
(1) ETT .电力变压器温度包括一个目标 "油温 "和六个 "电力负荷 "特征,每小时(即ETTh1和ETTh2)和每15分钟(即ETTm1和ETTm2)记录一次,为期两年。
(2) 电力来自UCI机器学习资源库,经过预处理,包含2012年至2014年321个客户的每小时用电量,单位为千瓦时。
(3) 交易所包含1990年至2016年八个国家的每日汇率。
(4) 天气包括21个天气指标(如温度和湿度),在2020年每10分钟记录一次。
对两类时间序列建模和预测任务的最先进方法和LaST进行了比较:
(1) 表征学习技术,包括COST、TS2Vec和TNC、
(2) 端对端预测模型,如VAE-GRU、Autoformer、Informer、TCN等。
评级设置
根据以前的研究,该模型在单变量和多变量的预测设置中都被运行。在多变量预测中,LaST接受并预测了数据集中的所有变量。在单变量预测中,LaST只考虑每个数据集的某些特征。对于所有的数据集,都采用标准归一化,输入长度T=201。对于数据集的划分,LaST遵循标准协议,对所有数据集按照6:2:2的比例将数据集划分为训练集、验证集和测试集的时间序列。
实施细节
在LaST的网络结构方面,采用了单层全连接网络作为前馈网络(FFN),用于后验、重建和预测器的建模。此外,两层MLP用于MI边界估计中的批评者γ。季节性和趋势表示的尺寸是匹配的。我们对单变量预测设定为32,对其他数据集的多变量预测设定为128。MAE损失被用来衡量从预测器得到的预测结果。学习策略使用亚当优化器,学习过程在10个epochs内提前停止。学习率初始化为10-3,并以每历时0.95的权重衰减。
性能比较和模型分析
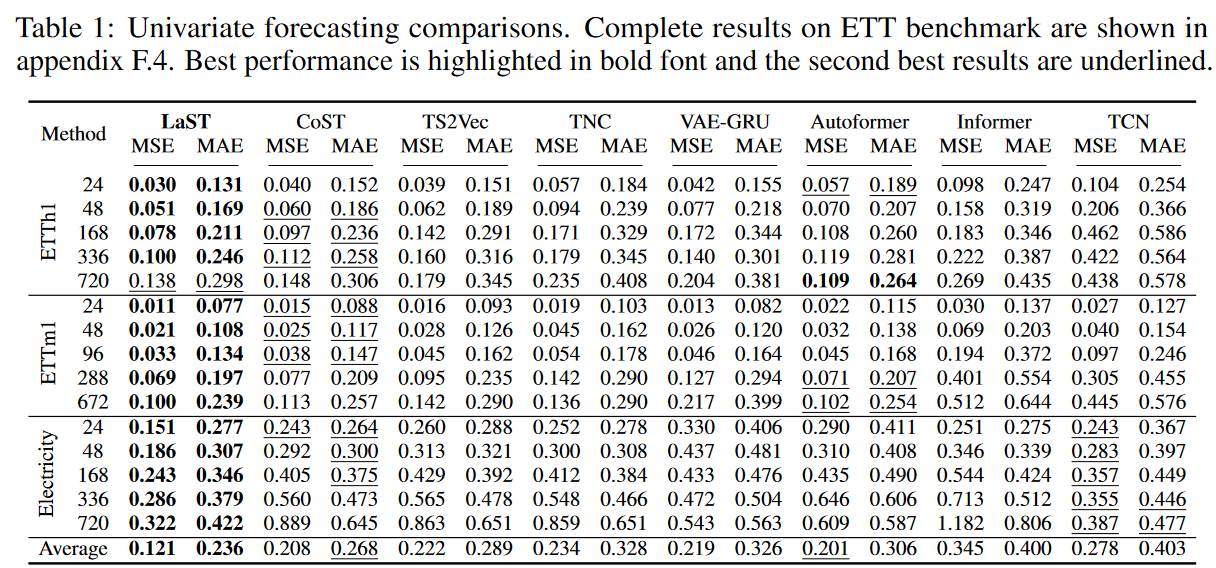
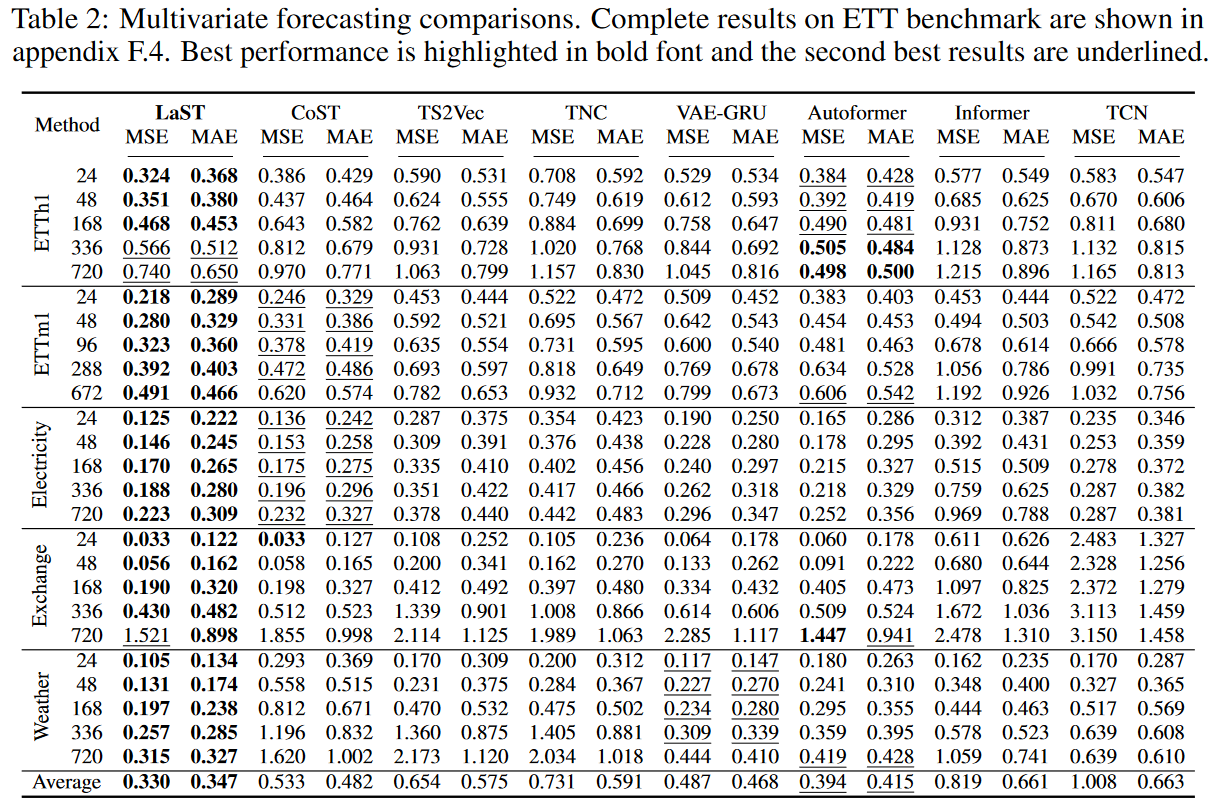
影响
表1和表2分别总结了单变量和多变量预测的结果;在五个真实世界的数据集上,LaST相对于高级表征基线取得了最先进的性能;相对于最好的表征学习方法CoST,MSE和MAE的相对收益分别为25.6%和22.1%,相对于最好的端到端模型Autoformer为22.0%和18.9%。我们注意到,Autoformer在每小时ETT数据集的长期预测中取得了更好的性能,我们认为这有两个原因:
(1) 基于变压器的模型本质上建立了长距离的依赖性,这在长期序列预测中发挥了重要作用
(2) 它采用了一个简单的分解方法,即用固定的核大小进行均值汇集,这对每小时ETT的高度周期性数据集来说是比较合适的。
虽然这种现象有利于长期预测,但它对当地环境的敏感性是有限的,奖金对其他数据集的影响不大。与基线相比,LaST自适应地提取了季节性和趋势的模式,以分离的方式表示,使其适用于复杂的时间序列。
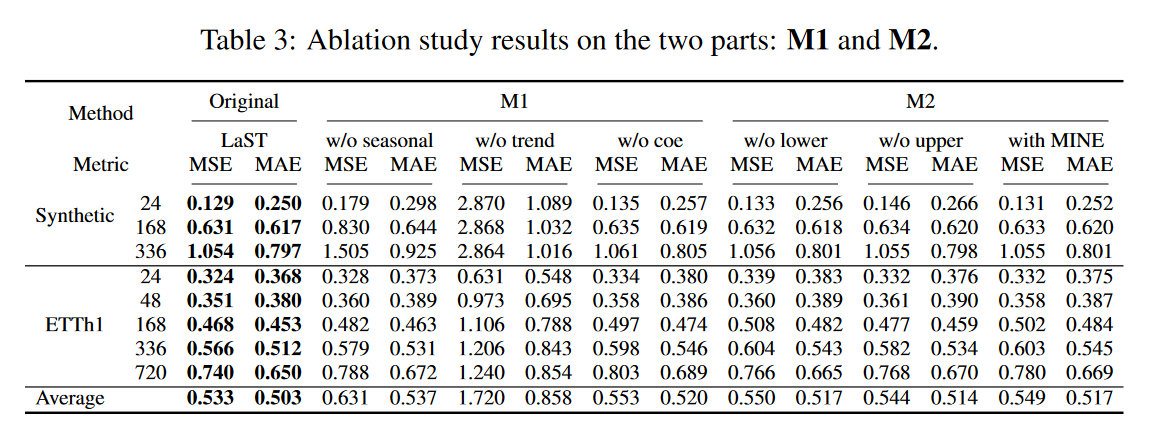
零敲碎打
在合成数据集和ETTh1上研究了每个LaST机制的性能优势。结果见表3,包括两组:M1考察了季节性-趋势表示学习框架的机制。其中,"w/o seasonal "和 "w/o trend "分别表示没有季节性和趋势成分的LaST,"w/o coe "表示估计重建损失时没有自相关和CORT系数的LaST;M2确定了MI的引入和估计,其中 "w/o lower"和 "w/o upper "分别表示在正则化项中去除MI的下限和上限,而 "with MINE "表示用MINE替换下限。结果显示,所有机制都提高了预测任务的性能。当趋势成分被移除时,我们发现质量明显下降。其原因是,季节性预测来自iDFT算法,该算法基本上是对过去观测结果的周期性重复。然而,捕捉季节性模式和用完整的LaST协助趋势成分可以提供一个优势,特别是在长期设置和强烈的周期性合成数据集。此外,据观察,当使用有偏正则项MINE时,性能变得不稳定,有时比没有MI下限的LaST更差,但无偏下限(见方程(9))持续优于LaST。
表达方式的解构
图2是使用tSNE方法对季节性趋势进行的可视化表示。作为比较,也直观地显示了自动形成器解码器最后一层的嵌入情况。可以看出,在没有分解机制的情况下,同样的彩色点是混合的("w/o dec "表示去掉了两个分解机制(自相关和CORT系数,以及MI上限),而对于LaST则有更清晰和紧密的聚类。
同样值得注意的是,带有简单移动平均块的Autofomer在时间序列方面实现了令人满意的分解,但其表征仍然是纠结的。这些结果表明:(1)学会分离季节性-趋势表征并不容易;(2)所提出的分解机制能够成功地在潜伏空间中分离季节性-趋势表征,专注于特定的时间模式。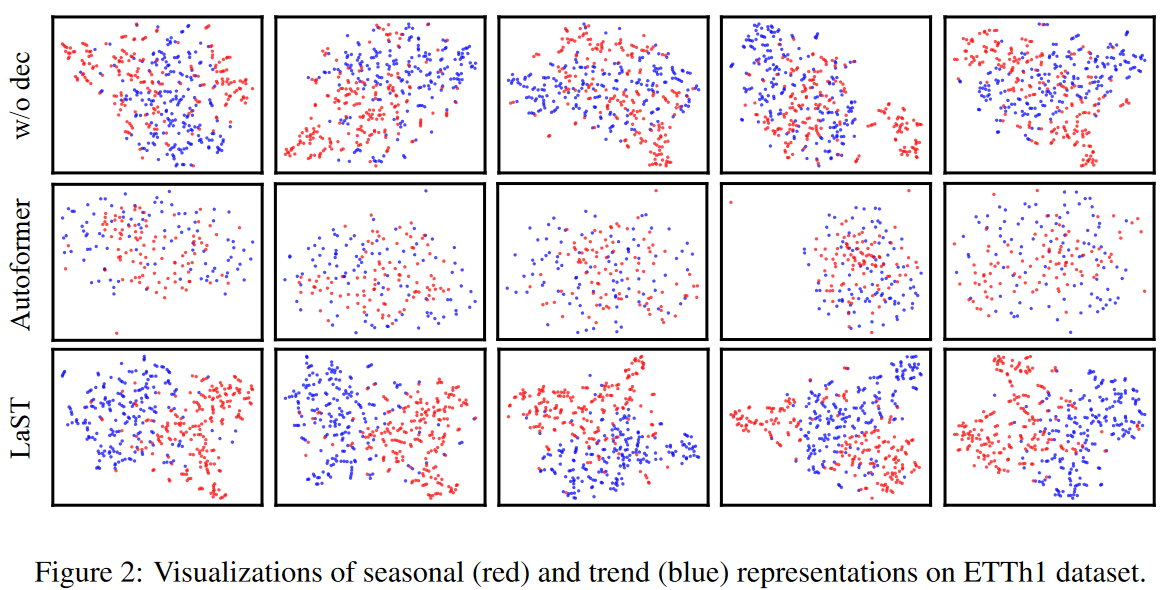
输入设置
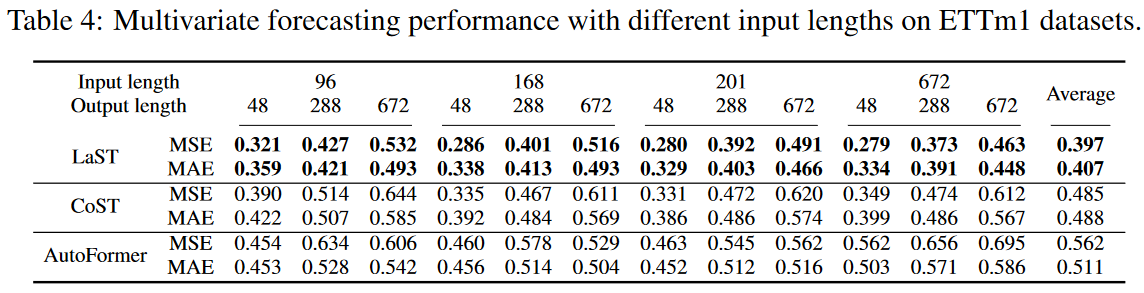
为了进一步验证敏感性,研究了超参数的输入长度的影响,结果列于表4。长的回视窗口提高了性能,特别是对长期预测而言,而其他窗口甚至降低了性能。这验证了LaST可以有效地利用历史信息来理解模式并进行预测。
从案例研究来看。
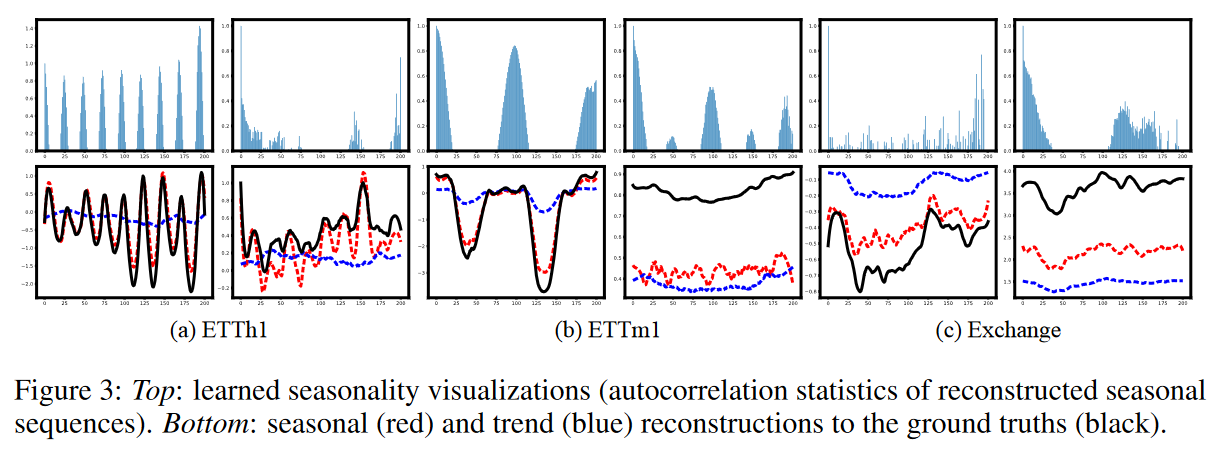
我们通过在具体例子中可视化提取的季节性和趋势来进一步验证LaST:如图3所示,LaST能够捕捉现实世界数据集的季节性模式。例如,每小时和15分钟的ETT数据集显示出强烈的日内周期;尽管交易所数据集缺乏明显的周期,但LaST在每日数据中提供了几个长期周期。此外,趋势和季节性成分分别准确地重建了原始序列,证实了LaST能够为复杂的时间序列生成可行的、分离的表示。
以前的工作
大多数用于时间序列预测的深度学习方法被设计为端到端的架构。各种基本技术(如残差结构、自回归网络、卷积)被用来生成富有表现力的非线性隐藏状态和反映时间依赖性和模式的嵌入。还有一组研究将转化器结构应用于时间序列预测任务,旨在发现跨序列的关系并关注关键时间点。与ARIMA和VAR等经典算法相比,深度学习方法已经取得了卓越的性能,并在多个领域得到了广泛的应用。
许多研究表明,学习灵活的表征对下游任务是有益的。在时间序列表征领域,早期使用变异推理的方法通过学习编码器来重建原始信号和相应的解码器来共同学习一个近似的潜在表征。最近的努力通过使用共轭和归一化流等技术来建立更复杂和灵活的分布,对这些变异方法进行了改进。另一个研究小组利用蓬勃发展的对比学习,从扩展的时间序列中获得不变的表征,这避免了重建过程,并在没有额外监督的情况下改进了表征。
时间序列分解是一种经典的方法,将复杂的时间序列分割成几个组成部分,以获得时间模式和可解释性。最近的工作是应用机器学习和深度学习方法来实现大数据集的稳健和高效分解。还有一些研究成果借助分解来解决预测问题。例如,Autoformer通过均值池将时间序列分解为季节性和趋势部分,并引入自相关机制来增强Transformer,以更好地发现关系;CoST在频域和时域中分别将信号编码为季节性和趋势表征并引入了对比学习来监督它们的学习。这些方法与本文的不同之处在于,它们利用了简单的均值池分解机制,可以提供不相容的周期性假设,并通过在不同领域的处理,直观地解耦表示。另一方面,LaST通过自适应地提取潜在空间中分离的表征的季节性和趋势,从概率的角度促进分离。
摘要
该论文描述了LaST,这是一个独立的变异推理框架,具有相互信息约束,用于分离潜在空间中的混合季节性-趋势表征,以有效预测时间序列。大量的实验表明,LaST成功地分离了季节性-趋势表征,并取得了最先进的性能。在未来,LaST将专注于解决时间序列下游的其他挑战性任务,如时间序列的生成和分配插值。此外,他们表示,他们计划在其分解策略中明确建立随机因素模型,以更好地理解现实世界的时间序列。



与本文相关的类别






