
使用GAN的基于自我注意的时间序列归纳网络STING。
三个要点
✔️ 提出了一种新的多变量时间序列数据的归因方法,称为STING(使用GAN的基于自我注意的时间序列归因网络)。
✔️ 引入了一种新的注意力机制,以避免潜在的偏差
✔️ 在替换精度和使用替换值的下游任务方面优于现有最先进的方法
STING: Self-attention based Time-series Imputation Networks using GAN
written by Eunkyu Oh, Taehun Kim, Yunhu Ji, Sushil Khyalia
(Submitted on 22 Sep 2022)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
摘要
在许多现实世界的应用中,时间序列数据最常见的问题之一是,由于数据收集过程的固有性质,时间序列数据可能存在缺失值。因此,从多变量(相关)时间序列数据中代入缺失值,对于提高预测性能,同时做出准确的数据驱动的决策至关重要。传统的归因法只是删除缺失的数值,或者根据平均数或零值来填补缺失的数值。近年来,基于深度神经网络的方法引起了广泛关注,但它们在捕捉多变量时间序列的复杂生成过程方面仍有局限。在本文中,我们提出了一种新型的多变量时间序列数据的归因方法,称为STING(使用GAN的基于自我注意的时间序列归因网络)。它使用生成式对抗网络和双向递归神经网络来学习时间序列的潜在表示。此外,还引入了一种新的注意力机制,以捕捉跨时间序列的加权相关性,并避免由不相关的相关性引入的潜在偏差。 在三个真实世界的数据集上的实验结果表明,STING在替换精度和使用替换值的下游任务方面优于现有的最先进方法。结果显示,STING在以下方面的表现优于。
介绍。
多变量时间序列数据的许多实时应用领域分析这些信号并进行预测性分析。例子包括关于股票价格预测的金融营销,病人医疗诊断预测,天气预报和实时交通预报。然而,由于某种原因,时间序列数据不可避免地会包含缺失值,例如某些数据特征是后来收集的,或者由于设备损坏或通信错误导致记录丢失。例如,在医疗部门,从活检中收集的某些信息可能难以获得或有危险。这些类型的缺失数据会大大降低模型的质量,甚至通过引入相当多的偏差而导致错误的决定。因此,在时间序列中嵌入缺失值对于准确的数据驱动的决策是至关重要的。
传统的缺失值分配方法分为两类:判别性的和生成性的。前者包括链式方程多变量替代法(MICE)和MissForest,而后者包括基于深度神经网络的算法,如去噪自动编码器(DAE)和生成式算法。对抗网络(GAN))。然而,这些方法是为非时间序列数据开发的,可能很少考虑到时间序列中观测值之间的时间依赖性。特别是,DAE在训练阶段需要完整的数据,这个要求几乎不可能满足,因为缺失值是问题的内在结构的一部分。最先进的时间序列数据归因研究是基于循环神经网络(RNN)和GANs。这些捕获了观察到的(或缺失的)数据属性的各个方面和时间依赖性,如时间衰减、特征相关和时间信仰门。
在此,我们提出了一种新型的多变量时间序列数据的归因方法,STING(使用GAN的基于自我注意的时间序列归因网络)。本文的基本架构是一个生成式对抗网络,在归入不完整的时间序列数据时可以估计出真实的数据分布。具体来说,生成器学习多变量时间序列数据的基本分布,以准确计算缺失值,而判别器则学习区分观察到的和计算出的元素。GAN的生成器学习具有非固定时间滞后的观察值之间的潜在关系,使用一个新的RNN单元称为内部采用GRUI(估算用的GRU)。对过去观察的影响根据时间滞后进行加权。为了利用未来和过去的观察信息输入当前的缺失值,采用了双向RNN(B-RNN),从前向和后向两个方向估计变量。此外,我们还提出了一种新的注意机制,即有选择地关注每个时间序列中高度相关的信息。这使得在时间序列较长、两个观测值之间的时间间隔较大的情况下,可以进行有效的学习:在三个真实世界的数据集上的实验结果表明,STING在归因性能上优于最先进的方法。该模型在输入后任务上的表现也优于基线,这是衡量替换性能的一个间接指标。
相关研究
Che等人提出了带衰减的门控递归单元(GRU-D),它在不完整的时间序列中学习缺失模式,并在填补医疗数据集中的缺失值时预测目标标签。该模型使用RNNs,并考虑其最后一次观察和经验平均值的加权组合。他们引入了一个输入衰减率和一个隐藏状态衰减率来控制衰减系数。然而,该模型的基本假设是,缺失的数据模式往往与目标标签相关(即信息性缺失)。鉴于这一事实,我们采取了一种统一的方法,将估算和预测任务(即目标标签)整合为一个单一的过程。这使得该模型的通用性降低,因为它依赖于目标标签被完全观察到。这使得它很难在无标签、无监督的情况下或标签不明确的情况下使用。它还强加了一个统计假设,即推断出的数值是最后一个观察值与经验平均值的比率。
在一项类似的工作中,Cao等人提出了一种基于RNN的方法,称为BRITS(Bidirectional Recurrent Imputation for Time Series),它直接学习缺失值,这些缺失值被认为是双向RNN图中的潜变量。它结合了基于历史和基于特征的估计,用于特征相关,并应用了一种学习策略,允许缺失值采取延迟的梯度。然而,它的目的是根据给定的时间序列来预测目标标签,同时学习归因。因此,在学习阶段需要知道目标标签。然而,这是一个相当强的约束,因为目标标签可能是未知的或包含缺失的值。因此,Imutation的性能对目标标签的完整性非常敏感。与他们不同,本文的模型在任何过程中都不依赖于目标标签。
Luo等人提出了一个基于GAN的归因模型,称为GAN-2-stages。为了对具有时间不规则性的分布进行建模,他们提出了一个门控递归单元(GRUI),该单元根据不规则时间间隔的时间长度来学习减弱过去观测的影响。他们进一步学习发生器的输入 "噪声",并从潜在的输入空间中找到最佳的噪声,从而使生成的样本与原始样本最为相似。然而,原始样本根据缺失程度有不同的时间衰减,而生成的样本则根据完整性有相同的时间衰减。这种明显的时间衰减差异使鉴别器能够更好地区分虚假和真实数据,并防止生成器的稳定训练,因为鉴别器的收敛速度更快。此外,该系统有一个自我喂养的学习方法,在训练过程中不正确的输出会继续反映在随后的训练中,直到训练过程结束。
Luo等人提出了一个端到端生成对抗网络(E2GAN)。他们利用了一种压缩和重建策略,通过去噪自动编码器避免了 "噪音 "优化阶段。在发生器中,随机噪声被添加到原始时间序列中作为输入,编码器试图将输入映射到一个低维矢量。然后解码器从低维向量中重建并生成样本。通过这个过程,E2GAN能够在学习原始时间序列的分布的同时,强制对输入进行压缩表示。然而,E2GAN仍然受到GAN-2阶段的限制,如与发生器相比,判别器的快速收敛和RNN的自学习。本文采用双向延迟梯度的方法,利用观测数据快速有效地训练发电机中的RNN模型。此外,拟议的判别器试图通过识别输入矩阵的每个元素是真(观察到的值)还是假(生成的值),而不是整个输入矩阵来解决更具体的问题,从而实现稳定的对抗性学习。
问题描述
让多变量时间序列数据X ={x1,x2, ...。,xT }是一个由T个观测变量组成的序列,其中第t个观测变量xt∈RD 由D个特征{xt1,xt2, ...,xtD},其中xtD由D个特征{xt1, xt2, ...,xtD}组成。也就是说,xtd被表示为xt中第d个变量的值。 X是一个带有缺失值的不完整矩阵。我们还引入了一个掩码向量mtd来表示xt中缺失变量的位置。因此,MTD的定义如下。
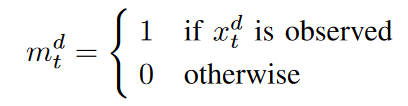
如果xtd 是一个缺失的值,那么X帽子被定义为与X大致相同,只是它是0。由于时间戳之间的时间间隔并不总是相同,我们将δd t 定义为最后一次观察和当前时间戳st 之间的时间间隔。
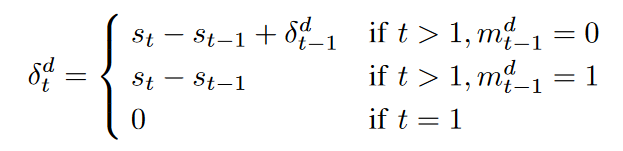
图1中显示了一个带有输入矩阵的例子。在这个例子中,S被定义为S = {0, 2, 3, 7, .,sT },并被定义为。
其目的是通过GAN的对抗性学习机制,准确地补足不完整矩阵X的缺失值。生成器试图学习X的基本分布,以产生一个完整的时间序列矩阵ˆ X,鉴别器试图通过识别完整矩阵的每个元素是来自X的真实值还是来自ˆ X的假值,来使估计的掩码矩阵ˆ M与掩码矩阵M相匹配。ˆM的每个元素都代表ˆX的每个元素是一个实值的概率。这个概率被表示为pdt∈[0,1]。
技术
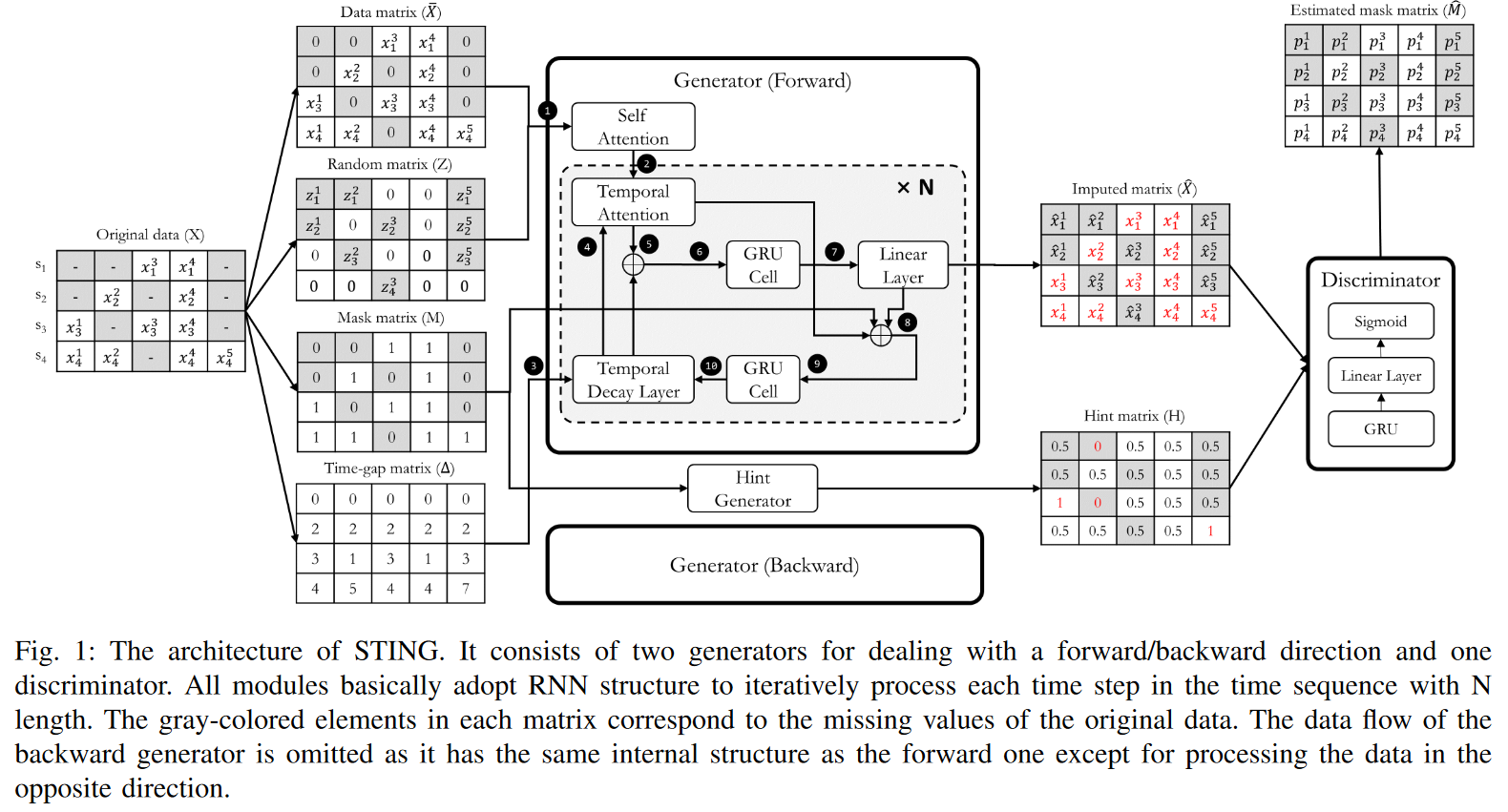
本节描述了如何为多变量时间序列数据建立一个归因模型,重点是图1所示的架构和整体工作流程。
受现有深度生成神经网络的启发,STING由两个生成器(Gs)和一个判别器(D)组成:两个Gs将正向和反向时间序列作为输入,各自按照指定的方向生成一个时间序列矩阵ˆX。两个方向的生成补充了单向GRU结构中的信息缺失问题,该结构受到时间序列数据中大量缺失值的影响。G的内部由两个注意力模块和两个改良的GRU单元组成。注意力模块计算整个序列的相关权重,这可以为后续的GRU模块提供更多线索。然后,两个GRU单元被设计用来处理具有不规则时间间隔的时间序列输入。另一方面,与G相比,D的结构相对简单,包括一个用于时间序列处理的GRU模块,一个用于降维的线性层,最后是一个产生每个元素的概率作为输出的sigmoidal激活。
从工作流程的角度来看,我们的方法首先是为每个缺失值用零来填充̄ X,然后用zd t来替换这些元素。这允许G在重复生成ˆxt时确定前一个时间戳的哪些值是可靠的,哪些是不可靠的。∆ 此外,∆还具有重要的信息,即当有任意缺失的数值时,先前的隐藏状态G应该参考多少。基于这四个输入矩阵,G生成一个归因矩阵ˆ X,并通过填入X的观察值来完善它,因为它不需要生成xtd,它已经知道了。换句话说,ˆxtd被xtd取代,如果它的元素是观察。这是估算的结果,并被转移到判别器。
另一方面,D将ˆX作为输入,并学习区分每个元素是否是观察。在这样做的时候,一个提示矩阵H也被作为一个额外的输入,告知D关于M的某些部分,并将其注意力引向特定的成分:HTD =0(作为缺失值)或HTD =1(作为观察值),其中H揭示了M的某些部分。此外,htd=0.5并不意味着任何关于D的学习可以集中在哪一个mtd上。这是因为D要在0.5的样本点中选择0和1,这是一个相对困难的学习点,D会专注于获得一个更好的拟合。换句话说,如果没有提示机制,G就不能保证学到由原始数据唯一定义的期望分布。在实践中,关于M的提示信息量可以通过改变提示发生器中的H来控制。提示越多,D就越容易学习。最后,D的输出是ˆM,其中每个元素都代表ˆX的每个元素是一个观察值的概率pdt。
通过最小-最大博弈联合训练G和D,G学会了原始数据X的基本分布,并能正确地归入缺失值,使D无法区分它们;G的理想结果是,ˆM的每个ptd对应生成的假值ˆxtd被设置为1。因此,D的理想结果是,每个对应于假值ˆxtd的ptd被设置为0,否则被设置为1。这意味着D准确地预测了一个等于掩码矩阵M的结果。STING的一个特点是,D试图区分矩阵中的哪些元素是真实的(观察到的值)或虚假的(归属的值),而不是整个输入矩阵。这种策略使D公司能够集中精力解决更具体的分类问题,从而提高性能。
A. 发电机。
STING利用两种类型的生成器(即前向G和后向G)来说明时间上两个方向的依赖关系,如图1所示。两者的作用是相同的,除了其中的一些,将在下面的 "一致性损失 "部分解释。因此,在本节的大部分内容中,将只描述前向G的细节,而后向G由于篇幅原因将被省略。每个G由一个复杂的GRU结构组成,有两种类型的注意层(自我注意和时间注意),一个时间衰减层和一个双GRU细胞。详细的结构和学习目标如下。
注意力的目的是通过找到给定查询值的输入中最相关的部分,并生成一个查询响应的表示,来学习输入数据不同坐标之间的结构依赖。通过学习基础数据分布的结构属性,注意力机制已被证明在各个领域是有效的。例如,在机器翻译任务中,这种机制可以用来衡量在解码过程中应该对编码器序列中的每个单词给予多少关注。在各种注意算法中,标度点积注意被定义为。
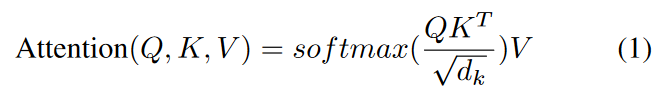
其中Q是查询,K是键,V是值。比例系数√dk是为了确保内积的值不会变得太大,特别是当维度很高时。因此,关注功能是通过计算作为关键和价值的整个编码器序列与作为查询的解码器的特定时间步骤之间的相关性的权重来实现的,称为关注分数。特别是,自我注意模块计算自我序列的不同位置之间的注意分数(即Q=K=V),以计算同一序列的表示。
为了使模型能够共同注意到来自不同位置的不同表征子空间的信息,我们进一步采用多头注意,其定义如下。
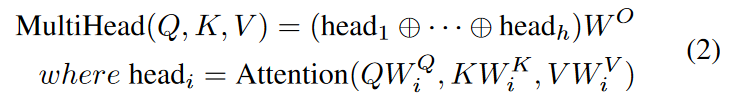
其中,W Q i ∈Rdmodel×dq ,W K i ∈Rdmodel×dk ,W V i ∈Rdmodel×dv ,W O ∈Rhdv×dmodel 是可学习参数矩阵。 ⊕表示串联操作。在这个模型中,dmodel 对应于数据的输入维度,四个平行的注意力头在减少的维度中计算,并串联到原始维度。
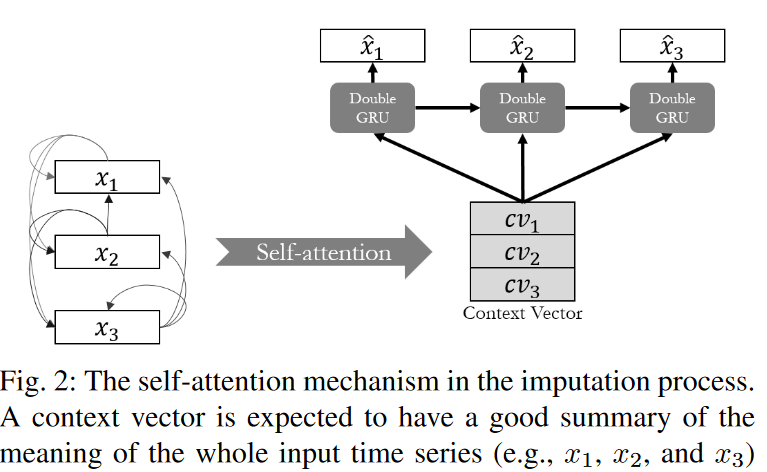
在本文中,由于两个原因,采用了注意力机制来为归纳问题提供更有针对性的线索。首先,它允许模型关注那些具有相对相似模式以及时间顺序的时间步骤。这特别适用于具有周期性的时间序列。许多时间序列在其序列中可能具有周期性属性(如天气预报、交通预报等)。第二,可以从整个序列中获得足够的信息,而不仅仅是来回的几个时间步骤。如果序列中有许多缺失的值,那么从整个序列中提供的信息质量要比只从某些时间步骤中提供的好。这一特性是传统方法(RNN方法)难以捕捉的,它依赖于时间序列。因此,在我们的模型中,我们将输入序列转化为一个上下文向量(即Q和K是从同一个输入序列中得到的),并考虑整个序列的定量相关性,如图2所示,使用自我观察模块。然后设计了一个时间注意模块,以反映GRU的隐藏状态和背景向量之间的相关性(Q是隐藏状态,K是背景向量)。
时间衰减层控制了GRU中不规则时间间隔的过去观测的影响。衰减率需要从数据中学习,因为它根据与变量相关的基本属性在不同的变量之间变化,因为缺失模式是未知的,而且可能是复杂的。换句话说,t时的衰减率矢量γt定义如下。
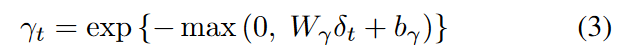
这里,Wγ和bγ是可学习的参数,并使用指数型负整流器来确保每个衰减率在0到1的范围内单调下降。 只要满足这些条件,这些功能就可以被其他功能取代。直观地说,其效果是削弱了从隐藏状态而不是直接从原始输入变量中提取的特征。通过学习以前隐藏状态的信息被衰减和利用的程度,衰减率在进入GRU-单元之前,通过逐个元素的乘法将以前的隐藏状态(ht-1)调整为h′t-1。
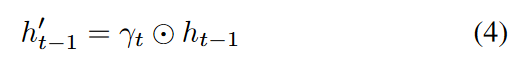
这里,它代表了一个逐个元素的乘法。
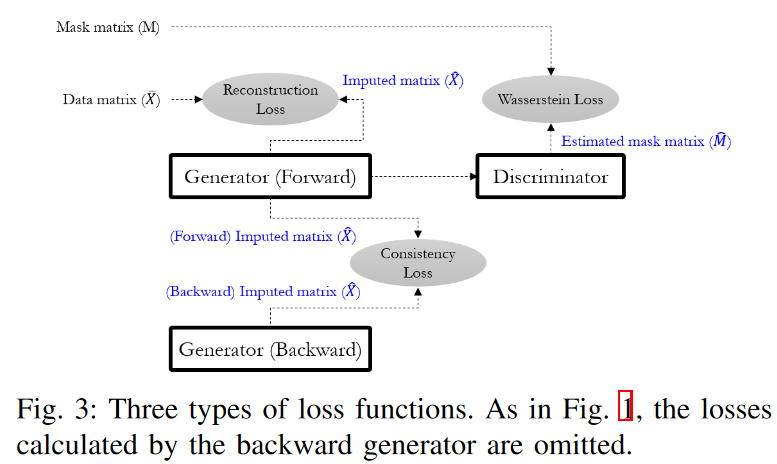
B. 识别器。
与GAN框架类似,引入一个判别器(D)作为训练G的对手。 D包括一个用于时间序列处理的GRU模块,一个用于降维的全连接层,最后是一个产生每个元素的概率作为输出的sigmoidal激活。 实验发现,D相对容易收敛因此,对于稳定的对抗性学习来说,它的结构比G更简单。学习D的损失函数也相对简单:由于与G相同的原因,传统的Wasserstein GAN损失不能直接应用:D的输入是由G归纳的矩阵ˆX,它是作为元素归纳的值和观察值的组合。也就是说,每个人都对应着一个假值或一个真值。这意味着损失函数必须同时考虑矩阵中的两类输入。出于这个原因,D的损失函数(LD)定义如下。
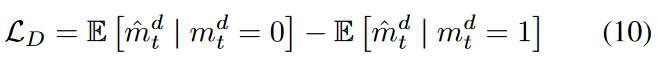
这里,第一项和第二项分别表示当D采取虚假和真实输入值时的损失:当D采取虚假值时,它应该输出0,而当它采取真实值时,它应该输出1。前向G和后向G各产生一个矩阵作为输出,所以D也有两个损失对应于两者。然而,为方便起见,只显示了一个。
C. 寻找最佳噪音
大多数使用GANs的研究旨在通过改变随机矢量Z(称为 "噪声")来产生真实的多个样本。然而,这种方法可能不适用于Imutation问题。换句话说,它需要成功地完成两项任务,即不仅要填补缺失的数值,而且要与观察值完全匹配。由于这种特殊性,"Z "型搜索发挥了重要作用。具体来说,随机噪声向量z是从高斯分布等潜在空间中随机采样的。这意味着,随着输入随机噪声z的变化,生成的样本G(z)也会发生明显变化。即使生成的样本遵循原始数据的真实分布,x和G(z)之间的相似度也可能不够大。换句话说,尽管它们的分布在广义上是相似的,但个别样本在某些观点上可能有很大的不同。为了解决这个问题并进一步提高相似度,引入了寻找最佳匹配的最佳噪声z′。由于一些条件(样本中的观测值)已经知道,它们可以被用来反复寻找更合适的Z。该方法已被广泛应用于图像数据的纹理转换、画像和表格数据的归纳等领域。
受这些研究的启发,该模型通过在推理阶段的学习来寻找最佳的噪声z′,它产生的缺失值更适合于原始数据分布上的样本。推理阶段的学习并不学习模型的参数,而是对输入zt进行反向传播,在每次迭代中更新。zt的学习使用与(9)中的学习G(LG)相同的损失。也就是说,梯度--∂lg/∂t 被迭代更新以寻找更合适的梯度。在寻找最佳噪声z′t作为输入之一后,通过前向和后向G分别产生两个归因矩阵。最后,两个矩阵的平均值被用来确定最终的估算结果。
实验
在本节中,我们进行了实验,目的是通过回答以下研究问题来证明所提出的STING模型的有效性
- RQ1 STING是否优于其他最先进的推断方法?
- RQ2 STING是如何对下游任务进行后输入的?
- RQ3 哪些模块对STING的绩效改进影响最大?
在下文中,首先描述了实验中使用的数据集和基线方法。接下来,提出的STING与其他比较方法进行了比较,并对STING在两个不同的实验设置下进行了详细分析。最后,进行了一项孤立的研究,分析STING主要模块的影响。
对于所有的数据集,在实验过程中采用最小-最大归一化,以了解基本实验设置的细节。所有的实验都重复了10次,考虑到实验过程中的任何种类的随机性,报告了准确性的平均值。用(6)和(7)中的LR和LC对生成器进行了10个历时的预训练。我们在实验中发现,当生成器稍加预训练后,其收敛速度更快,性能更好。然后,我们在每次迭代时交替更新生成器和判别器,逐一进行。模型是用Adam优化器训练的。发生器和判别器的学习率分别为0.001和0.0001。给予判别者的提示比例被固定为0.1。批量大小被设定为128。λr和λc分别被设定为10和1,作为(9)中损失的超参数。该模型是在PyTorch中实现的,所有的训练都是在一个拥有11GB内存的2080Ti GPU上进行。
A. 数据集。
2012年PhysioNet挑战赛数据集(PhysioNet)--源于2012年PhysioNet挑战赛1,该数据集旨在开发针对患者的院内死亡率预测方法。它包括12000条来自重症监护室(ICU)住院的多变量临床时间序列记录。我们使用整个数据集的训练集A(4,000个ICU住院时间)。实验性的预处理数据集共有192,000个样本。每个样本包含37个变量,包括48小时的DiasABP、HR、Na和乳酸。有554名患者(13.85%)的死亡标签为阳性。这个数据集的缺失率很高(80.53%),而且非常稀疏,使得它很难简单地执行下游任务,如死亡率预测。由于这个原因,以前的许多研究都用这个数据集进行了实验,以评估归因和归因后任务的性能。
KDD CUPChallenge 2018数据集(空气质量)-- 可从UCI机器学习资源库获取,KDD CUP Challenge 2018数据集(空气质量)是一个公共的空气质量数据库。数据集,用于2018年KDD CUP挑战赛,以准确预测未来48小时内的空气质量指数(AQI)。这些记录包括总共12个变量,包括来自北京12个监测站的PM2.5、PM10和SO2。期间涵盖了2013年3月1日至2017年2月28日,变量是按小时测量的。总样本量为420,768,有一些缺失值(1.43%)。
气体传感器阵列温度调制数据集(气体传感器)-- 可从UCI机器学习资料库中获取 一氧化碳(CO)和潮湿的合成空气在气室中的动态变化,为期3周。包括14个温度调制的金属氧化物(MOX)气体传感器,在气室中暴露于一氧化碳(CO)和潮湿的合成空气的混合物中三周。整个数据集的一天被用于实验。样本数量为295,704个。每个样本由20个变量组成,包括气室中的CO浓度。与其他数据集不同,所有的样本都是完全观察到的。
B. 基线。
为了评估我们的模型的性能,我们将它们与以下有代表性的基线进行比较。基于统计的(Stats-based),基于机器学习的(ML-based)和基于神经网络的(NN-based);基于ML的模型是基于python软件包sklearn和f ancyimpute实现的;基于NN的实验设置,如模型的超参数,分别根据相应的论文进行设置。
- 平均值只是用相应变量的全局平均值来填补缺失值。
- Prev Fill (Prev)用以前的观察值来填补缺失的数值。由于其时间序列的性质,这种方法是非常简单和计算效率高的推算方法。
- KNN[35]使用K-Nearest Neighbours来寻找10个相似的样本,并用这些样本的平均值来填补缺失值。
- 矩阵分解(MF)[36]是一种将不完整的矩阵直接分解为两个低秩矩阵的方法,通过梯度下降法解决,并通过矩阵补全法补足缺失值。
- 连环方程多重替代法(MICE)[10], [37]将每个缺失值的特征迭代为其他特征的函数,并使用其估计值进行替代。
- Generative Adversarial Imputation Nets (GAIN) [18]使用GANs对实际观察到的情况进行缺失值的估算。
- 带衰减的门控递归单元(GRU-D)[2]是以GRU为基础,使用不规则时间间隔的衰减机制来计算缺失值。
- E2GAN(端到端生成对抗网络)[16]是基于GAN的,其特点是生成器的自动编码器结构。这意味着在学习原始时间序列分布的同时,可以对低维向量进行优化。
- Bidirectional Recurrent Imputation for Time Series (BRITS) [15]适应双向RNN来嵌入缺失值,对数据集没有任何特定的假设。
C. 归因性能的直接评价(RQ1)
本实验的目的是直接评估基线和STING之间的归因性能。在这个实验中,一定比例的观察值被随机剔除,并作为基础事实使用。然后,剩余的观测数据被用作归因模型的训练数据。每个模型的替换训练完成后,通过每个模型替换缺失的数值,推断出完整的数据。然后将推断出的数值与地面实况进行比较,用RMSE(均方根误差)衡量每个模型的性能,数值越小说明性能越好。在第一个实验中,与真值的比率被设定为20%,并对三个数据集的所有模型的性能进行了比较;在第二个实验中,真值比率从10%到90%不等,并对表现最好的基线性能进行评估。
表一总结了第一次实验的结果,显示STING在所有数据集上都取得了最好的性能。与性能最好的基线(即BRITS)相比,结果的误差改进分别为4.0%、21.0%和59.1%。有一种统计方法,Prev,具有相当高的性能。这表明具有历史价值的简单赋值可能比其他模型表现得更好,而其他模型则耗时且复杂。这是合理的,因为时间序列数据收集的性质,它在很大程度上依赖于历史样本。特别是,对于时间变化不大的数据集,用过去的数值进行填充可以以很小的代价提供很大的好处。Prev也显示出与GRU-D类似的性能趋势。这有很大的意义,因为GRU-D学习了平均值与历史值的比率,并填补了缺失值;在基于ML的模型中,KNN在气体传感器数据集上显示出与BRITS相似的最佳性能,但在其他数据集上其性能并不稳定。另一方面,MICE在所有的数据集上都表现出相对良好和稳定的性能,而基于GAN的GAIN在时间序列数据集上表现不佳,原因是缺乏适合时间序列的学习策略。
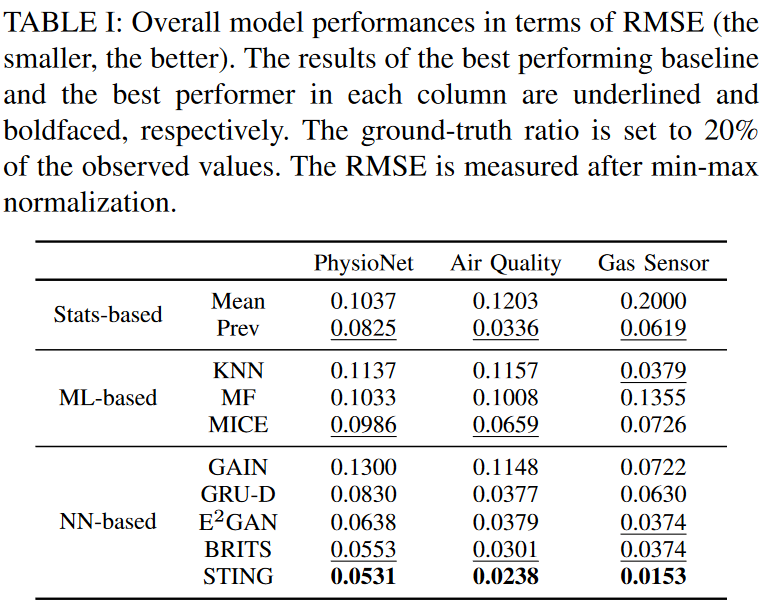
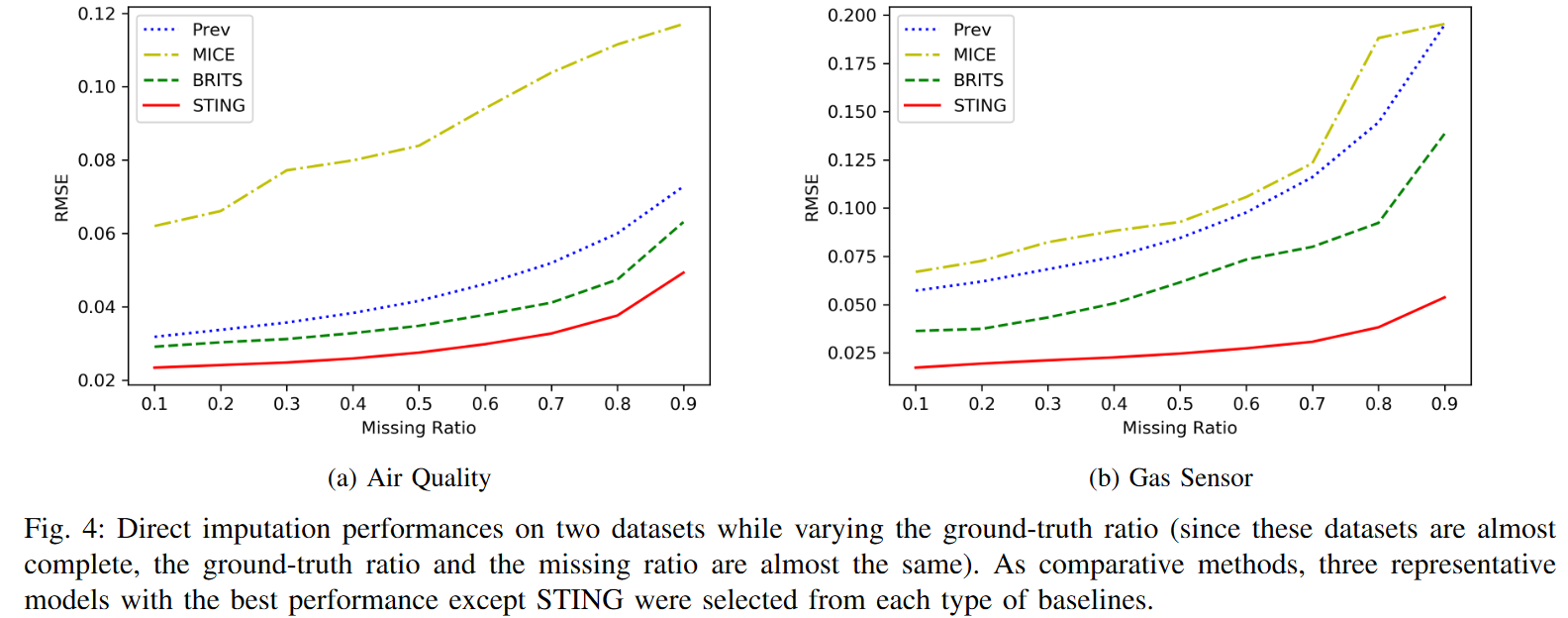
图4显示了两个数据集在不同缺失率下的第二次实验的性能结果。请注意,PhysioNet的缺失率非常高(80.53%),因此在本实验中被排除。相反,较高的缺失率会减少用于估算训练的训练数据,从而降低所有模型的性能。尽管如此,可以看出,STING在所有条件下都取得了最好的性能,性能逐渐下降。换句话说,数据集中包含的缺失值越多,STING对缺失值的归纳就越不敏感,与其他的相比。这一结果证实了STING利用了注意力机制,因为参考整个序列可以获得相对更多的信息。
D. 归因性能的间接评价(RQ2)
本实验的目的是通过下游任务解决方案的结果来间接评估归因的性能。如果源数据和归类数据的分布相似,下游任务的结果也应该相似。因此,通过预测结果,可以间接看到不完整数据的推算程度。为了稳定地训练预测模型,只使用了气体传感器数据集,它原本是完整的数据。这个数据也允许我们假设一个理想的替换模型,即所有的缺失值都由地面真实数据替换,从而获得一个上限的预测性能。在这个实验中,这个理想的替换模型也被列为基线。请注意,由于本实验的目的是测量归纳性能,而不是提高预测性能,所以归纳和预测的任务没有同时训练。在对非标签的测试数据进行归纳后,再由在完整的训练数据上学习的预测模型来推断,该模型已经被训练过了。这样做的目的是为了在标签不明确或标签缺失的典型设置中提供公平的模型比较。
这个实验的程序如下。为了独立建立归因和回归模型,首先将数据集分为80%的训练数据和20%的测试数据。利用这些完整的训练数据,首先训练一个回归模型来预测目标CO浓度。对于回归模型,我们构建了一个简单的GRU,有两层,落差为0.3,最后是一个全连接层。然后,训练数据被设定为具有一定比例的完全随机缺失值。在对训练数据进行方法和基线训练后,除测试数据的目标值外的缺失值可以通过所获得的模型进行归置,以获得与每个模型相对应的不同的归置测试数据集。然后使用基于推算出的测试数据的回归模型对目标进行预测。最后,对预测值和实际目标值之间的RMSE结果进行测量。这种评估方法使用户能够确定估算的数据是否遵循原始数据的分布,前提是类似的分布产生类似的性能。换句话说,通过比较原始测试数据与回归结果(由理想模型推算)的接近程度,我们可以确定哪些推算数据更接近真实分布。这里应该指出的是,我们的目标不是要达到最先进的预测性能。
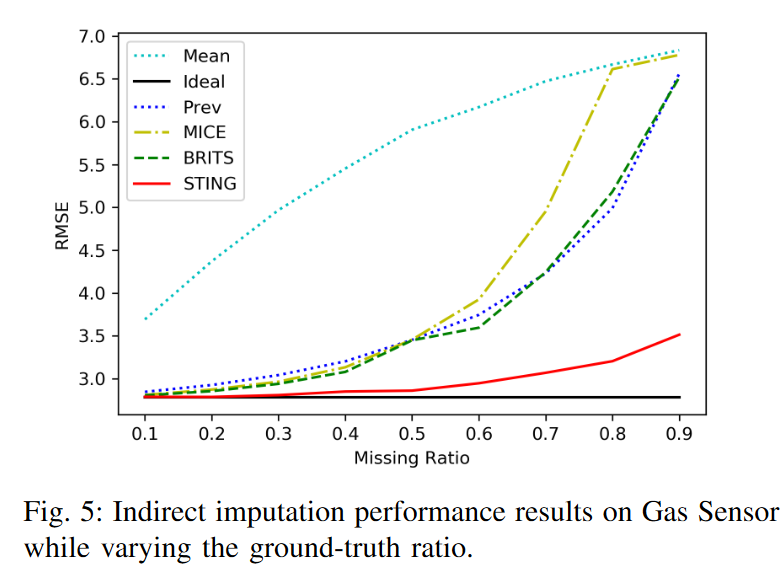
图5显示了在改变地面真实比率的情况下,每个归入的数据的回归模型的RMSE结果。可以看出,理想模型具有最低和恒定的RMSE,因为它能够在任何缺失率下对原始测试数据进行归纳。在所比较的估算模型中,STING在任何比率下都能达到最佳性能。另一方面,平均数取得了最差的性能,显示出用平均数来估算时间序列的效率是多么低。有趣的是,失踪率之间有一个明显的差异,大约为0.5。此前,大多数模型在3.5以下保持类似的良好性能,但随后RMSE急剧增加。在0.9的基础上,尽管条件很差,STING显示出相对较小的误差增加;使用GANs生成新的时间序列并通过注意机制利用整个序列的信息似乎有优势。
E. 消融研究(RQ3)
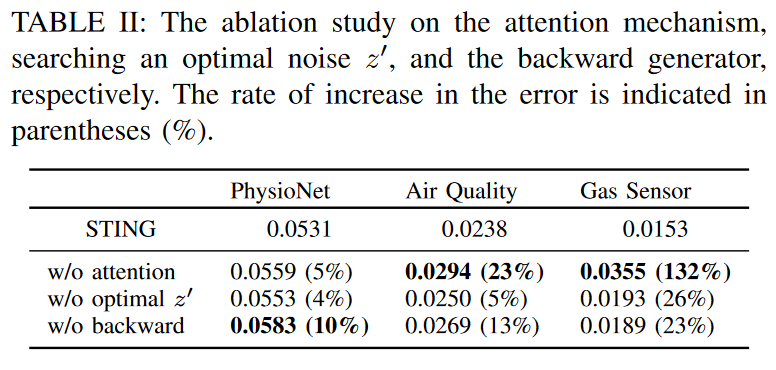
STING的有效性的潜在来源是两个注意力模块,即最优噪声z′搜索方法和后向发生器,分别。为了了解每个关键特征如何影响STING的性能改进,进行了消融实验,并将所得架构的性能与整个STING架构进行了比较。为此,在三个数据集上实验了三个模型,每个模型只排除了STING的一个特征。我们测量了估算值的RMSE,地面真相的比例设定为观察值的20%。
表二显示了消融结果,所有情况下的RMSE都有增加。去掉后向发生器的结果显示,PhysioNet的错误率增加得最多。另一方面,去掉注意力模块后的结果显示,气体传感器和空气质量的错误率增幅最大。这表明,所提出的注意模块在STING中发挥着相对重要的功能。也就是说,在学习跨序列的相关性的过程中,它产生了显著的重要信息,用于任何数据集的归因。另一方面,搜索最佳噪声z′的模块的影响相对较小。这表明,即使z是随机生成的,仍有可能产生与原始数据的实际分布相匹配的样本,因为X的观察值是以STING中的G为条件的。换句话说,即使有非最佳的噪声,STING也有可能有效地学习原始时间序列的分布,这一过程起到了补充作用。
上述与其他模型的比较实验已经证明了STING的有效性。有两个主要因素促成了即使在恶劣条件下的显著表现。首先,我们能够确认GAN机制运作良好,产生的样本遵循原始时间序列的真实分布,说明STING如果设置好,如何收敛到所需的分布。特别是,我们解释说,鉴别器问题在Wasserstein距离上设置得更微妙,以最大限度地提高对抗性学习效果,与以前使用GANs的工作进行了比较。作为第二个关键因素,我们发现所提出的注意力机制在归纳任务中是有效的:STING能够通过关注某些周期性模式和某些时间步骤获得更多的信息。随着缺失率的增加,这种效果变得更加明显,这清楚地表明了在归类过程中保留大量信息的好处。
摘要
本文提出了STING,一种基于生成对抗网络和双向递归神经网络来学习时间序列潜在表征的多变量时间序列数据的新型归因方法。它还提出了新的自我和时间输入机制,以捕捉跨时间序列的加权相关性,并防止不相关的时间步骤带来的潜在偏差。在真实世界的数据集上进行的各种实验表明,STING在归因准确性和归因值的下游性能方面都优于以前的最先进方法。在未来,他们计划研究更普遍的数据的归因,包括分类类型;对于GANs来说,分类数据的生成是一个特别具有挑战性的问题;测试GANs生成和归因分类数据的潜力是未来研究的一个主题。



与本文相关的类别






