
通过强化学习进行模型选择的时间序列异常检测。
三个要点
✔️时间序列异常有几种模式,专门研究一种模式的模型可能不擅长检测其他模式的异常。
✔️这种方法RLMSAD解决了这个问题。它汇集了检测不同特征的不同模式的模型(在这种情况下是五个),并使用强化学习来选择哪个模型适合特定时间序列的数据。
✔️这种方法证实了优于传统模型的特性。
Time Series Anomaly Detection via Reinforcement Learning-Based Model Selection
written by Jiuqi Elise Zhang, Di Wu, Benoit Boulet
(Submitted on 19 May 2022 (v1), last revised 27 Jul 2022 (this version, v4))
Comments: Accepted by IEEE Canadian Conference on Electrical and Computer Engineering (CCECE) 2022
Subjects: Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
摘要
时间序列异常检测对于现实世界系统的可靠和高效运行至关重要。基于对异常特征的不同假设,许多异常检测方法已经被开发出来。然而,由于现实世界数据的复杂性,时间序列中的不同异常现象通常有不同的方面,需要不同的异常假设。这使得单一的异常检测器很难在任何时候都胜过所有模型。为了利用不同基础模型的优势,本研究提出了一个基于强化学习的模型选择框架。具体来说,首先学习不同的异常检测模型库,然后用强化学习从这些基础模型中动态地选择候选模型。在真实世界数据上的实验结果表明,所提出的方法在整体性能上优于所有模型。
介绍。
作为网络物理系统技术的一部分,智能电网利用先进的基础设施、通信网络和计算技术来提高电网的安全和效率。本文将智能电网作为评估环境。
离群点(outlier)被定义为'一个似乎与集合中其他部分不一致的观察'。或者,它们被定义为 "偏离大多数数据序列的模式或分布的数据点 "或偏离分布的数据点"。这种异常情况的发生通常表明系统中存在潜在的风险。例如,电网中的异常电表读数可能表明故障或可能的网络攻击,而金融时间序列的异常可能表明 "欺诈、风险、身份盗窃、网络入侵、账户被接管、洗钱或其他非法活动"。因此,异常检测对于确保系统的运行安全非常重要,并在医疗保健系统、在线社交网络、物联网(IoT)和智能电网等领域找到应用。
异常检测设备通常建立在以下假设之一的基础上
(1) 变化发生的频率很低。
在这个假设下,如果数据的基本概率分布可以被描述出来,那么异常现象最有可能发生在低概率区域或分布的尾部。一项关于数据流中的异常检测的研究根据极值理论(EVT)拟合了输入数据流的极值分布,并使用PeaksOverThreshold(POT)方法来估计异常检测的正常性界限。在另一项关于电力系统计量异常检测的研究中】,作者提出使用核密度估计(KDE)对电表测量的概率分布进行近似,并进一步提出一个概率自动编码器来重建正常数据的统计区间的上界和下界。
(2) 异常实例最有可能发生在远离大多数数据的地方或低密度地区。
基于这一假设的方法常常包含最近的邻居的概念和特定数据的距离/接近/密度指标。在最近的一项研究中,k-Nearest Neighbours(kNN)算法的检测性能与几个最先进的基于深度学习的自监督框架进行了比较,作者发现,简单的基于最近的邻居的方法仍然优于它们。在一项关于物联网异常检测的研究中,作者提出了一个局部离群因子(LOF)超参数调整方案。
(3) 如果可以学习到输入数据集的良好表征,预计异常现象会有一个与正常实例明显不同的特征。另外,如果进一步的未来数据是由学习到的表征重建或预测的,那么基于异常的重建预计将与基于正常数据的重建有明显的不同。
在最近的一项研究中,作者提出了一个异常检测框架OmniAnomaly,由GRU-RNN、Planar Normalising Flows(Planar NF)和Variational Autoencoder(VAE)组成,用于学习和重构数据表示。然后,在一个给定的潜在变量下的重建概率被用作异常得分。在另一项关于航天器异常检测的研究中,提出了一个非参数阈值方案,利用LSTM-RNN预测序列的未来值,并解释预测误差。大的预测误差意味着时间序列中出现异常的概率很高。
然而,由于现实世界数据的复杂性,异常现象会以许多不同的方式表现出来。在测试阶段,基于对异常现象的具体假设的异常检测器往往偏向于某些方面而不是其他方面。这意味着,一个单一的模型可能对某些类型的异常现象很敏感,而倾向于忽略其他的异常现象。对于不同类型的输入数据,没有一个通用的模型能胜过所有其他模型。
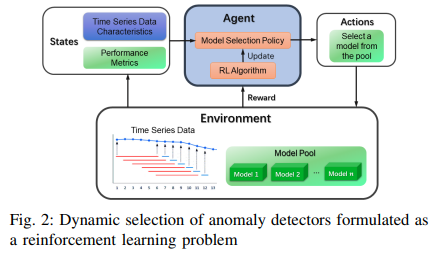
为了 在不同的时间阶段利用几个基本模型的优势,我们建议在每个时间阶段从候选模型池中动态地选择最佳检测器。 在拟议的设置中,当前的异常预测是基于当前选定的模型的输出。强化学习(RL)作为一种机器学习范式,关注 "通过最大化数字奖励信号将情况映射为行动",似乎是对这一挑战的合理解决。强化学习代理的目的是通过最大化总回报来学习最佳决策政策。强化学习已被应用于各种现实世界的问题,如电动汽车充电时间表、家庭能源管理和交通灯控制。动态模型选择的有效性也在各个领域得到了证明,如短期负荷预测的模型选择、时间序列预测的模型组合和时间序列预测的集合动态加权。
本研究提出了一个基于强化学习的异常检测的模型选择框架(RLMSAD)。拟议框架的目的是根据输入时间序列的观察值和每个基础模型的预测值,在每个时间步骤选择最佳检测器。在一个真实世界的数据集--安全水处理(SWaT)上的实验表明,所提出的框架在模型准确性方面优于每个基础检测器。
技术背景
时间序列中的无监督异常检测。
一个时间序列(X = {x1, x2, ..., xt})是一个按时间顺序索引的数据序列。时间序列可以是单变量的,其中每个xi是一个标量,或者是多变量的,其中每个xi是一个矢量。本文在无监督的情况下,解决了多变量时间序列中的异常检测问题。训练序列Xtrain是一个只包含正常实例的时间序列,而测试序列Xtest被异常实例所污染。在训练阶段,为了捕捉正常实例的特征,在Xtrain上预先训练了一个异常检测器。在测试中,检测器检查Xtest并为每个实例输出异常分数。通过将这一分数与经验阈值相比较,可以得到每个测试实例的异常标签。
马尔科夫决策过程和强化学习
强化学习(RL)是顺序决策问题的机器学习范式之一。
它的目的是训练代理人通过最大化总回报来发现环境中的最佳行为,通常被建模为马尔可夫决策过程(MDP)。一个标准的MDP被定义为一个元组,M=(S,A,P,R,γ)。在这个方程中,S是状态集,A是行动集,P(s'|s, a)是状态转换概率矩阵,R(s, a)是奖励函数。 γ是奖励计算的折扣系数 γ是奖励计算的折扣系数,通常在0到1之间。在确定性的MDP中,每个行动都会导致某个状态,即状态转换的动态是固定的,所以不需要考虑矩阵P(s'|s, a),MDP可以反过来用M = (S, A, R, γ)表示。返回Gt
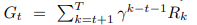
是当前时间步骤t之后的未来累积奖励。政策π(a|s)是一个概率分布,对应于当前状态和选择特定行动的可能性。强化学习代理的目的是学习一个决策政策π(a|s),使预期总收益最大化。
技术
整体工作流程。
模型的工作流程如图1所示。时间序列输入在滑动窗口中被分割。在每个分段窗口中,最后一个时间戳是要分析的实例,所有以前的时间戳都作为输入特征使用。每个候选异常检测器首先在训练集上单独进行预训练。然后针对测试数据运行所有的检测器,每个检测器为所有测试实例计算一组异常分数。为了解释异常得分,需要为每个基础检测器确定一个经验性的异常阈值。根据分数和阈值,所有基础检测器可以为测试数据生成一组预测性标签。
利用上一步得到的预测分数、经验阈值和预测标签,再定义两个信心分数。这两个置信度分数,连同预测分数、阈值和预测标签,作为状态变量被整合到马尔科夫决策过程(MDP)中;一旦构建了MDP,就可以使用适当的强化学习算法学习模型选择策略(这里的实现中使用了DQN)。

基准检测器的性能评估。
提出了两个分数来描述模型库中的候选探测器的性能。每个异常检测器为测试数据生成一组异常分数。通常情况下,较高的异常得分表明存在异常的可能性较大。因此,预测分数超过模型阈值越高,在当前模型预测下,相应的实例就越可能是异常的。因此,人们可以根据给定分数超过阈值的程度来评估一个模型预测的有效性。这里,提出了距离-阈值信心(Distance-Threshold Confidence)。
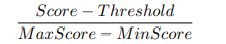
是通过当前得分超过最大和最小得分之差的阈值(按最小-最大比例缩小到[0,1]的范围)来计算的。我们还提出了 "预测-共识信心",其灵感来自于集合学习中的多数投票思想。

它被计算为相对于候选模型的总数而言,做出相同预测的模型数量。池中产生相同预测的候选模型越多,当前的预测就越可能是真的。
马尔科夫决策过程(MDP)的制定
模型选择问题被形式化为一个马尔可夫决策过程,如下(见图2)。在这种设置下,状态转换是确定的,因为它们自然地遵循一个时间序列,作为序列中的时间步骤。也就是说,对于从st 到st+1 的每一对最近的连续状态,状态转换概率P(s'|s)为1,否则为0。贴现系数γ被设定为1(未贴现)。
- 国家
状态空间的大小与模型池相同。我们将每个状态视为一个选定的异常检测器,状态变量包括按比例的异常得分、按比例的异常阈值、二进制预测标签(0代表正常,1代表异常)、距离-阈值信心和预测-协议信心。请注意,对于每个基础检测器,其异常得分和阈值使用minmax尺度归一化为[0, 1]。
- 行动
行动空间是离散的,与模型池的大小相同。在这里,每个从池中选择一个候选检测器的行动都由池中所选模型的索引来描述。
- 奖励
奖励函数是根据预测和实际标签的比较来确定的。这由(r1, r2, r3, r4 > 0)表示。

奖励是为了鼓励代理人在动态环境中做出适当的模型选择。我们将异常情况视为 "正面",将正常实例视为 "负面";真正面(TP)代表一种状态,即预测标签和地面真实标签都是 "异常",并且模型正确识别了异常情况;真负面(TN)代表一种状态,即预测标签和地面真实标签都是 "负面"。地面真实标签都是 "正常 "的,换句话说,模型正确地识别了正常的实例 假阳性(FP)代表预测标签是 "异常 "而地面真实标签是 "正常 "的情况。假阴性(FN)表示预测标签为 "正常",而地面真实标签为 "异常 "的情况,意味着模型忽略了异常情况,并将其错误地识别为正常。意义。
考虑到上述四种情况对现实世界的影响,在奖励设置方面提出以下假设正常的例子占大多数,异常的情况相对罕见。因此,正确识别正常实例被认为是一个比较琐碎的情况。从这个角度看,TN的奖励应该相对较小,TP的奖励相对较大,即r1>r2。
忽视实际的异常情况一般也比发出错误警报更有害。有时,它可能会鼓励模型对积极的预测过于敏感和 "大胆"。通过这种方式,该模型可能会产生更多的FP,但也会减少忽视实际异常情况的风险。在这方面,当模型未能检测到实际的异常情况时(在FN的情况下),即r4>r3,比它产生错误警报时(在FP的情况下)受到更严重的惩罚。
实验
数据集
用于评估的数据集是由新加坡科技大学的网络安全研究中心iTrust收集的安全水处理(SWaT)数据集。这个数据集收集了来自工业水处理测试平台的51个传感器和执行器的操作数据。这里的实验是在2015年12月版进行的,包括7天的正常运行数据和4天的被攻击污染的数据(离群值)。这是一个具有51个特征的多变量时间序列数据集:7天的正常数据包含496,800个时间戳,被选为预训练集。被攻击的四天的数据包含449,919个时间戳,被选为测试集。测试集中的异常数据比例为11.98%。
基本模式
在形成模型库时,要选择基于不同异常点假设的模型,以确保选择的多样性。以下五个无监督的异常检测算法被选为候选模型
- 一类SVM ( 一类SVM )
一种基于支持向量的新颖性检测方法。其目的是学习一个超平面,将高数据密度的区域与低数据密度的区域分开。
- 隔离森林(iForest)。
隔离森林算法是基于异常现象容易被隔离的假设。如果多个数据集/数据集信息/决策树被拟合到一个数据集上,异常的数据点应该更容易从大多数数据中分离出来。因此,预计异常情况会在相对靠近决策树根部的叶子中发现,也就是在决策树的较浅深度。
- 异常点检测的经验累积分布(ECOD)。
ECOD是一种多变量数据的统计离群点检测方法;ECOD首先计算沿每个数据维度的经验累积分布,然后使用该经验分布来估计尾部概率。估计的终端概率在所有维度上汇总,并计算出异常得分。
- 基于Copula的异常值检测(COPOD)。
COPOD是另一种用于多变量数据的统计离群点检测方法。它假设了一个经验协同学来预测所有数据点的尾部概率,这进一步充当了异常得分。
- 多变量的无监督 异常检测(USAD) 。
这是一种基于表征学习的异常检测方法。它使用对抗性训练的编码器-解码器对来学习原始时间序列输入的稳健表示。在测试阶段,重建误差被用作异常得分。分数越是偏离预期的正常嵌入,就越有可能发现异常情况。
对于单类SVM和iForest,Scikit-Learn库的默认超参数使用SGDOneClassSVM和IsolationForest;对于ECOD和COPOD,PyOD工具箱的默认函数为ECOD和COPOD的默认函数来自PyOD工具箱;对于USAD,我们使用了作者的原始GitHub仓库的实现。
估值指数
该研究使用精确度、召回率和F-1得分(F1)来评估异常检测性能。
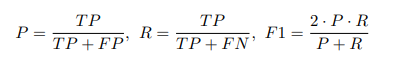
异常数据被认为是 "正数",正常数据点是 "负数"。根据定义,真阳性(TP)是正确预测的异常数据,真阴性(TN)是正确预测的正常数据,假阳性(FP)是一个正常的数据点被错误地预测为异常,假阴性(FN)是一个异常的数据点被错误地预测为正常。
实验装置。
下采样可以通过减少时间戳的数量来提高学习率,也可以去除整个数据集的噪音。在数据预处理阶段,采用了平均每5个时间戳5步的下采样率。
由于我们已经知道SWaT数据集中的异常百分比(11.98%,约为12%),阈值标准被固定为12%。这意味着,对于每个基础检测器来说,如果一个数据实例的得分在该序列的所有输出得分中排名前12%,则当前检测器将该数据实例标记为异常。并使用StableBaselines3中DQN的默认设置进行训练。为了报告RL模型在不同超参数设置下的性能,我们在随机初始化的情况下,每个实验运行10次,并报告评价指标的平均值和标准偏差。
结果和讨论
1)整体表现
首先,比较了单独的五个基础模型和强化学习模型选择(RLMSAD)方法的性能。这里,RLMSAD的奖励设置为:TP为1,TN为0.1,FP为-0.4,FN为-1.5。
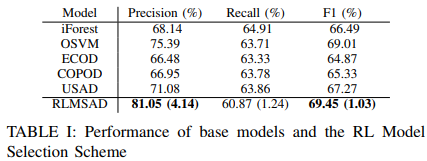
基本模型的准确度(Precision)得分在66%到75%之间。所有基本型号显示召回率约为63%。基本模型的F-1得分约为65%至69%。
在所提出的框架中,总体准确率和F-1得分都有明显提高,RLMSAD准确率达到81.05%,F-1达到69.45%,显示了异常检测性能的明显改善。
2) 不同的薪酬安排
调查惩罚对MDP公式中假阳性(FP)和假阴性(FN)的影响。
对错误识别的惩罚的影响。
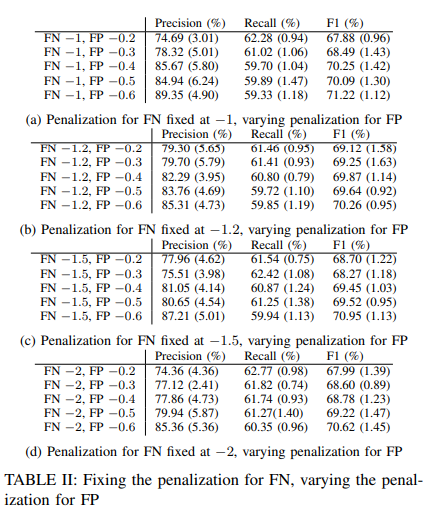
对假阴性的惩罚是固定的,对假阳性的惩罚是不同的。结果列于表二。增加对假阳性的惩罚是为了指示模型在预测中更加谨慎。因此,该模型报告的错误警报较少,只有在对其预测相当有信心时才会报告异常情况。换句话说,该模型对序列中相对较小的偏差不太敏感,这可能会提高准确性。它也只将那些与大多数人有显著差异的数据实例报告为异常情况,因此涵盖的实际异常情况较少,这可能导致可重复性的损失。这一点在表二中很明显,随着FP惩罚的增加,召回分数下降,准确分数增加。
对假阴性的惩罚的影响。
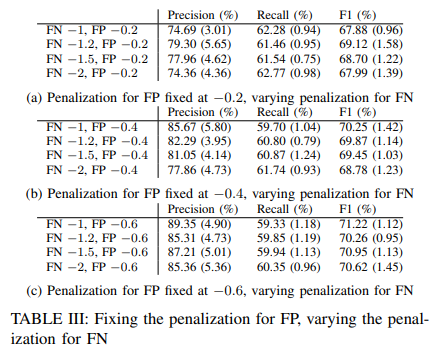
对假阳性的惩罚是固定的,对假阴性的惩罚是不同的。结果列于表三。增加对假阴性的惩罚鼓励模型在报告异常情况方面变得 "更大胆"。当假阴性的成本(即错过真正的异常情况)很高时,代理人的最佳策略是尽可能多地报告异常情况,以避免错过许多真正的异常情况。在这种情况下,模型更有可能对小的偏差过于敏感,导致精度的损失。另一方面,它也更有可能标记出实例中的异常情况,从而覆盖更多的实际异常情况,实现更高的召回率。这可以从表三中准确率分数的普遍下降和召回分数的上升中得到证明。
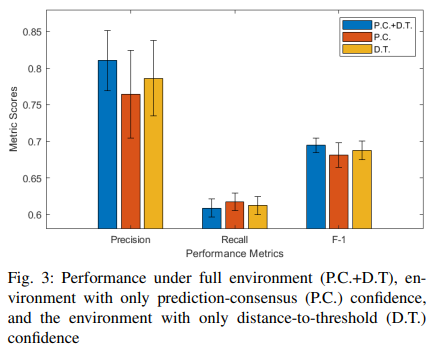
3) 划分研究
采用切入式方法来研究两种信心水平的影响:距离-阈值信心(D.T.)和预测-共识信心(P.C)。在这里,除了原来的强化学习环境外,还构建了两个强化学习环境。在这两种环境中,两个置信度的分数分别从状态变量中删除。我们在这三种环境中分别重新训练了策略,并在图3中报告了检测性能。从图3中,我们可以看到,去除两个信心分数中的任何一个,都会导致准确性和F-1分数的大幅下降。获得。
摘要
本文提出了一个基于强化学习的模型选择框架,用于时间序列异常检测。
具体来说,首先引入了两个分数来描述基础模型的检测性能:距离-阈值信心和预测-共识信心。其次,模型选择问题被表述为马尔可夫决策过程,两个分数被用作RL的状态变量。其目的是学习异常检测的模型选择策略,以优化长期预期性能。对真实世界的时间序列进行的实验证明了该方法的模型选择框架的有效性。未来的工作将集中在提取适当的特定数据特征并将其嵌入到状态转换中。这可能使RL代理获得更丰富的状态描述和更强大的性能。



与本文相关的类别






