成本指标是否一定合适?
三个要点
✔️ 讨论各种成本指标的优点和缺点
✔️ 关于成本指标之间出现差异时的讨论
✔️ 关于使用成本指标进行比较何时不再公平的讨论
The Efficiency Misnomer
written by Mostafa Dehghani, Anurag Arnab, Lucas Beyer, Ashish Vaswani, Yi Tay
(Submitted on 25 Oct 2021 (v1), last revised 16 Mar 2022 (this version, v2))
Comments: ICLR2022
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
机器学习模型的效率(EFFICIENCY)是开发和使用模型的一个非常重要的因素。
例如,推理的成本与模型在实践中的易用性和现有硬件的限制直接相关。训练模型时产生的经济和环境影响可能也是需要考虑的。因此,有许多与模型的效率有关的指标,如需要训练的参数数量、浮点运算(FLOPs)的数量和速度/吞吐量。
然而,并非所有这些效率指标都是详尽的,在许多情况下,只报告了其中的一些指标,例如,只报告了参数数和FLOPs。但只根据模型效率的某些指标来判断模型效率是否合适?
本文介绍了调查这一问题各个方面的研究,包括常用的模型成本指标的优点和缺点,以及根据一些指标进行决策的风险。
关于成本指标
首先,介绍了机器学习模型效率的各种成本指标。
... FLOPs。
FLOPs是一个常用的衡量标准,代表了一个模型的计算成本,表示浮点乘法和加法运算的数量(浮点运算的数量)。请注意,这是一个与FLOPS(每秒浮点运算)不同的指标,后者被用来衡量计算机处理速度。
应该注意的是,论文中报告的FLOPs是根据理论值计算的,它忽略了实际因素,如模型中的哪些过程可以并行化。
参数的数量
可学习参数的数量被用来作为计算复杂性的间接衡量标准。许多关于缩放法(Scaling Law)的研究,特别是在NLP领域,将参数的数量作为一个关键的成本指标。
速度
速度是比较不同模型效率的最有用指标之一。在测量速度时,可以考虑到管道的成本,以反映实际配置。
自然,速度取决于所使用的硬件和实现方式,因此,固定硬件或根据用于比较的资源进行归一化是很重要的。
有几种形式的报告速度指标,包括
- 吞吐量:在特定时间内处理的例子或标记的数量("每秒的例子 "或 "每秒的标记")。
- 延迟:在给定的例子或一批例子中,模型的推理时间("每次向前传递的秒数")。这是一个重要的因素,例如在需要用户输入的实时系统中,由于批处理引起的并行性被忽略了。
- 挂钟时间/运行时间:模型处理某一组例子所需的时间。通常用于衡量训练成本,例如,直到模型收敛的总训练时间。
- 管道泡沫:计算设备在每个批次的开始和结束时的空闲时间。它是一个间接的指标,反映了流程中非管道部分的速度。
- 内存访问成本:内存访问的数量。通常是运行时间的很大一部分,是在GPU、TPU等上运行模型时的实际瓶颈。
这些成本指标反映了模型效率的各个方面。
然而,这些指标不一定是针对模型设计的,而是取决于各种因素,如模型运行的硬件、实施的框架和编程技巧。
例如,尽管FLOPs与硬件无关,但它们不一定能带来模型速度。
另一方面,能更好地反映模型在现实世界环境中的效率的吞吐量和内存使用,在很大程度上取决于硬件和实现。每个成本指标对不同因素的这种依赖性导致了比较上的困难。在下面的章节中,我们将讨论模型效率的指标,重点是参数的数量、FLOPs和速度。
成本指标之间可能存在的差异。
下一节将介绍前面提到的成本指标之间可能存在的差异。
参数共享
对于共享参数的模型,与不共享参数的模型相比,可训练参数的数量减少,而FLOPs和速度保持不变。
例如,一个通用变压器和一个具有共享参数的香草变压器等之间的比较可以是这样的。
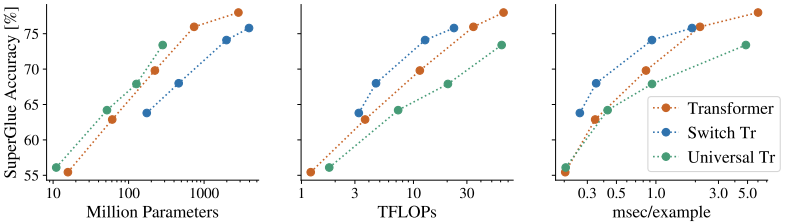
仅从参数的数量来看(图的左侧),万能变压器似乎比其他型号更有效率。然而,当看FLOPs和吞吐量时(图的中间和右边),通用变压器的相对排名下降了。因此,对于共享参数的模型来说,参数的数量并不是一个有效的成本指标。
引入稀疏性。
在神经网络中引入稀疏性(Sparsity)时,也会出现成本指标的不一致。
如果在神经网络中根据输入实例使用不同的权重子集,例如在混合专家(MoE)中,参数的数量可能非常大,但质量的FLOPs可以得到改善。对于操作包括许多零(或接近零的值)的(稀疏化)模型,FLOPs也可以显著减少。
前面的图显示了使用MoE的开关变压器的情况,质量的参数数量并不有利,但质量、FLOPs和速度之间的比较显示了非常好的结果。
还应该注意的是,稀疏模型可以导致FLOPs在理论上的显著减少,但不太可能导致速度的显著提高。
例如,MoE由于要使用模型的哪些部分的路由部分,有效使用批处理的困难等,产生了额外的开销。另外,即使在使操作包括许多零的模型中,由于内存访问的巨大成本,也不能使低级算术操作的效率等同于相应的密集计算。
平行化程度:模型深度和宽度比例的比较。
如果你想改变模型的尺寸,最简单的方法是改变模型的深度(层数)和宽度(隐藏尺寸的数量)。
下面是各种成本指标和模型精度的变化情况,如果视觉变压器的深度(D)和宽度(W)实际发生变化,正如下面调查的那样。
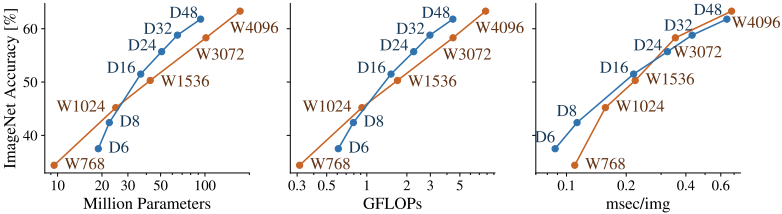
在这个图中,考虑到参数和FLOPs的数量,可以得出结论,在低成本区域增加宽度,在高成本区域增加深度,将以较少的成本提高性能。
然而,在速度(msec/img)方面却观察到不同的趋势。
例如,在比较W3072和D48时,从FLOPs的数量和参数来看,D48在成本相当的情况下似乎显示出明显更好的性能。
然而,在比较速度时,不可能判断W3072明显比D48差(由于有更多的并行处理)。因此,在有些情况下,不同的平行化程度会导致成本指数之间的结果不一致。
目标平台和实施方案
硬件和实施也可能造成成本指标的差异。
例如,在引入降低模型成本的技术时,GPU和TPU可能在速度效率方面表现出不同程度的改进。另外,ViT中的全局平均池而不是CLS可以大大降低TPU-V3的内存成本,但这是由于TPU的规格问题。因此,在有些情况下,硬件和实施会影响一个模型的成本指数。
考虑
在机器学习通信中,成本指标主要用于
- 利用成本指标比较不同模式的效率。
- 在相同的成本设置下,比较不同型号的质量。
- (例如,在NAS中),选择一个在质量和成本之间做出正确权衡的模型。
为这些目的使用成本指标,有时会导致不准确的结论。
不同模型的效率比较
首先,考虑(1)根据成本指数比较不同模式的效率的情况。
下图显示了不同模型的FLOPs、参数数量、运行时间和精度的比较。
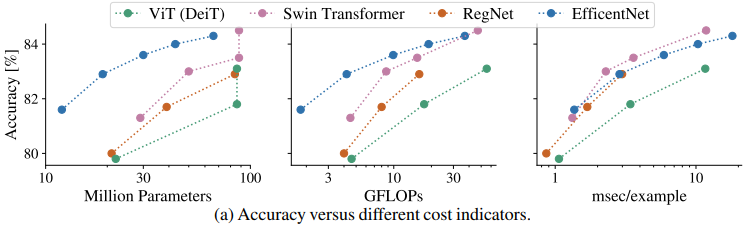
这些模型准确性-成本指标之间的相对关系表明,每个模型之间的相对关系取决于成本指标。
例如,在观察参数数量和FLOPs时,EfficientNets显示了良好的权衡。然而,在准确性-吞吐量图中,SwinTransformer似乎更好。
因此,根据使用哪种成本指标进行比较,可能存在不同的最佳模式。此外,显示成本指标之间相关性的图表如下。
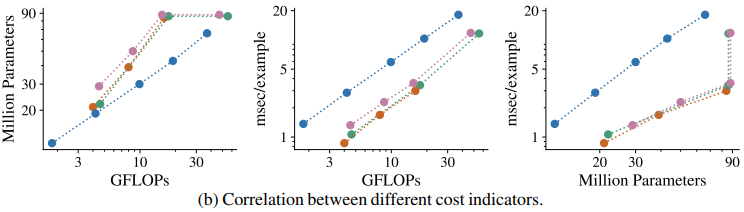
从图中可以看出,当FLOPs固定时,EfficientNet的模型参数数量比其他模型要少。
另一方面,针对FLOPs的吞吐量显示,EfficientNet的吞吐量比其他模型要差。即使在参数数量相同的情况下,基于变压器的模型的其他指标也有很大差异。
这是由于模型的输入分辨率发生了变化(从224 x 224到384 x 384),编码器的输入标记数量也不同。相反,可以看出,对模型设置的改变可能只对某些成本指标产生重大影响。
不同模型的质量比较
接下来,考虑(2)在同一成本设定下比较不同模型的质量的情况。
在这种情况下,主要有两种比较模式,一种是模型中的参数数量相同,另一种是计算成本相同,如FLOPs,并将依次讨论。
在比较相同数量的参数时出现问题。
首先,讨论了比较具有相同数量参数的模型的潜在问题。
无令牌模式。
无标记模型涉及在字符或字节层面而不是在标记层面进行建模。
在这种情况下,许多来自嵌入矩阵的参数被删除,使得与非无标记模型的公平比较非常困难。
稀疏模型和专家混合模型(Mixture-of-Expert)。
如前所述,在使用稀疏性的模型中,用相同数量的参数来比较模型显然是不公平的。
在前面的例子中,如果用相同的参数设置比较开关变压器和普通变压器,普通变压器总是有优势。
视觉变压器和序列长度
像Vision Transformer这样的模型,序列的长度可以变化,对于相同数量的参数,可以创建计算成本(FLOPs和速度)非常不同的架构。因此,这种类型的模型不应该在参数数量的基础上进行比较。
例如,下表显示了不同贴片尺寸(序列长度)的ViT成本指标。

如表所示,存在这样的情况:一些模型的参数数量是相同的,但其他指标却有很大差异。
在比较相同的计算成本时存在问题。
另一方面,在比较具有相同计算成本的模型时也会出现问题。
例如,考虑所提出的方法以不影响模型中参数数量的方式降低计算复杂性的情况。如果需要与基线进行比较,可以减少基线中的层数或隐藏维度,直到计算复杂性相匹配。
然而,在这种情况下,基线因参数数量的简单减少而受到阻碍,这大大降低了模型的容量。
例如,在收发器IO中,基线BERT在计算匹配比较中被减少到20M参数和6层。请注意,在比较中,拟议方法的最大参数数和层数分别为425M和40。一般来说,通过匹配计算量来进行公平的比较是一个非难事和困难的问题。
在不容易进行公平比较的情况下,建议尽最大努力找到最佳的比较设置,并在可能的情况下,指出一个以上的候选人。
NAS中的成本指标
在NAS中,成本指标通常被添加到损失函数中,作为对模型资源的约束。
例如,使用参数的数量、FLOPs、内存访问成本和实际延迟。正如已经表明的那样,成本指标可以导致彼此不同的结论,所以在架构探索期间选择成本指标时必须非常谨慎。
摘要
这篇文章就各种成本指标的利弊以及成本指标之间何时可能出现差异提出了一份广泛的讨论文件。
最近的研究经常根据参数数量或FLOPs等成本指标来比较不同的模型。
然而,每个指标都有各种优点和缺点,这可能使其难以用于公平的评估。因此,可以说,应该使用所有可用的成本指标进行比较。



与本文相关的类别






