语言模型能否以非语言的概念空间为基础?
三个要点
✔️ 语言模型能否只用几个例子就能对类似真实世界的概念空间进行接地?
✔️ 测试学习网格上的2D和3D颜色空间与语言空间之间的映射的能力。
✔️ 用GPT-3实现一些非随机的准确性
Mapping Language Models to Grounded Conceptual Spaces
written by Roma Patel, Ellie Pavlick
(Submitted on 29 Sep 2021)
Comments: ICLR2022
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
大规模的预训练语言模型,如GPT-3,已经在各种自然语言任务上显示出优秀的结果。
除了回答问题和产生流畅的句子外,这种模型还显示出对语言空间内概念结构的良好掌握,包括对他们没有实际观察过的物体和属性进行推理的能力。
本文提出了具有挑战性的研究,解决了仅在文本数据上训练的语言模型是否能学习到概念空间的基础知识的问题,例如,现实世界的空间信息。(本文已被ICLR 2022接受(海报))。
实验装置
模型
实验中使用了GPT-2和GPT-3模型。参数的数量包括124M、355M、774M、1.5B和175B。而不是更新这些模型的参数,通过给出少量的例子来控制行为。
更具体地说,在给模型一个形式为 "World:~~"的问题和 "Answer:~~"的答案的例子任务后,可以给模型一个新的问题和数据 "Answer: "来生成问题的答案(这可以在上下文中完成这被称为学习或少许提示)。
基础概念领域
实验涉及三个与现实世界相关的概念(接地气)的问题,如二维空间的方向和RGB空间的颜色,如下图所示。

下面将逐一解释。
空间术语
这个问题考虑了六个空间概念(左、右、上、下、顶、底)。具体来说,一个二维空间由多个 "0 "和一个 "1 "组成的网格表示,这个网格被作为一个问题交给语言模型("世界:~"),语言模型被要求回答 "1 "的位置。
红衣主教的方向
该任务涉及在一个网格二维空间中代表东西南北以及它们之间的八个方向。
与空间术语类似,但包括构成性术语(复合词?),如 "东北"。不同的是,它包括
RGB颜色
考虑使用RGB367颜色数据集在三维空间中表示颜色,其中颜色的名称(红色、青色、森林绿色等)由RGB代码表示。
例如,如果 "RGB:(255,0,0) "作为一个问题,正确答案是 "答案:红色"。
然而,实验中使用的语言模型(GPT-x)是在CommonCrawl语料库上训练的,所以这些领域可能在预训练中遇到过。
例如,互联网上有许多表格将(255,0,0)映射为 "红色"。
为了避免模型在这种数据的简单存储上取得成功,一个额外的旋转过程被应用于上述的任务。
例如,在RGB色域中旋转的例子如下所示。

如果语言模型能够掌握空间中概念之间的结构关系(在这个例子中是颜色),那么即使进行不破坏空间结构的旋转处理,它也应该能够解决这个任务。
相反,如果空间中的概念是随机分配的,性能应该下降到随机水平。在实验中,对原始世界以及旋转90°、180°和270°的世界和随机世界的模型进行了评估。
如果该模型成功地以期望的方式映射概念,预计它在原始/旋转的世界中表现良好,而在随机世界中则表现不佳。
评价指标如下。
- Top-1准确度:如果基础事实或其子串(词)序列在生成的答案的前$n$ tokens中,则准确度为1。例如,如果地面真相是 "深托斯卡纳红",如果模型答案是 "托斯卡纳红 "或 "红",准确率就是1,而 "深红"、"葡萄酒 "或 "朱砂 "的准确率就是0。在原论文的附录中,还进行了一个实验,即只用完全匹配而不是部分匹配来计算准确性。
- 前三名准确率:如果正确答案存在于模型中最有可能的三个答案序列1-3中的任何一个,则准确率为1。
- 接地距离:用于评估模型的误差程度。如果模型产生的答案是领域中的一个词(例如颜色领域中的 "粉红色"),该空间中两点之间的欧几里得距离就被用来评估。如果答案在域外,就会设置一个非常大的值作为这个指标的值。
对于接地距离,该指标对地面实况和预测结果的例子显示如下。

该表显示了GPT-3模型的实际预测结果。例如,如果预测的是 "葡萄酒",而地面真相是 "暗红色",那么计算出的接地距离是76.5。
基准线
两个随机基线被设定为基线
- R-IV(随机词汇表):从模型的整个词汇表中选择随机标记。(自然,它在所有任务上显示的性能几乎为零)。
- R-ID(域内随机):随机选择域内的词(如颜色)。
实验结果
关于对看不见的世界进行概括的能力
在三个任务中,对空间术语和基本方向进行了实验。给予模型的输入的例子将如下。
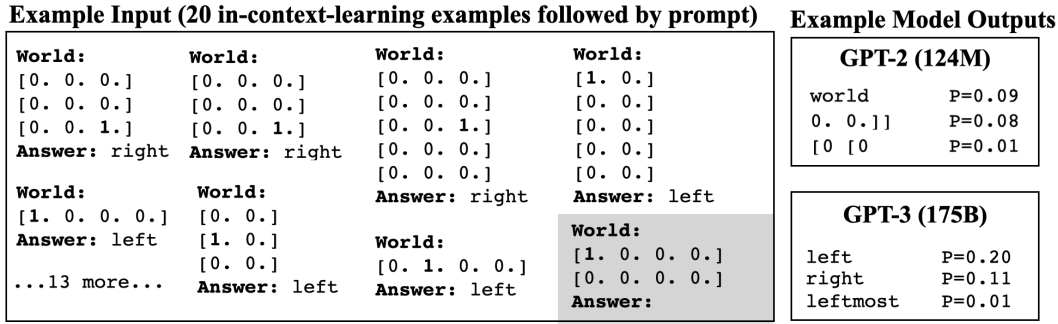
在这里,评估时每个任务中包含的概念(方向和方位)都包含在之前提供给模型的数据中。换句话说,虽然只有 "右 "和 "左 "出现在训练中,但 "上 "和 "下 "不会出现在评估中。数据是以20个概念例子的形式交给模型的,这些概念由八个方向或上/下/左/右对组成。
结果如下。
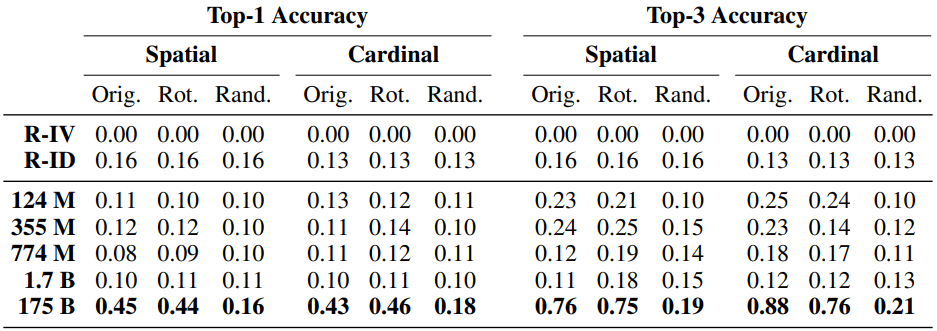
具有最大数量参数的模型(GPT-3)对原始世界和旋转世界的表现都达到了0.45左右的最高精度,而对随机世界的表现则有所下降。这是一个理想的结果,尽管精度不高,而且在某种程度上,该模型成功地推广到二维空间。
另一方面,对于其他模型,其性能甚至低于R-ID设置,这意味着它们几乎无法学习。
关于对未见过的概念进行概括的能力
下一步是对包括RGB颜色的任务进行实验。在这一点上,对模型的输入示例可以是如下内容。

在这里,评估时每个任务中包含的一些概念(方向、方位和颜色)并不包括在之前提供给模型的数据中。换句话说,会有这样的情况:在训练中只出现 "右 "和 "左",但在评估中出现 "上 "和 "下"。
更具体地说,对于空间术语和基本方向,事先给出的20个例子的数据包含n-1$的概念,在评估过程中使用包含其余的数据。
由于RGB颜色的概念很多,在预先给定的数据中给出了60个例子。
结果如下。
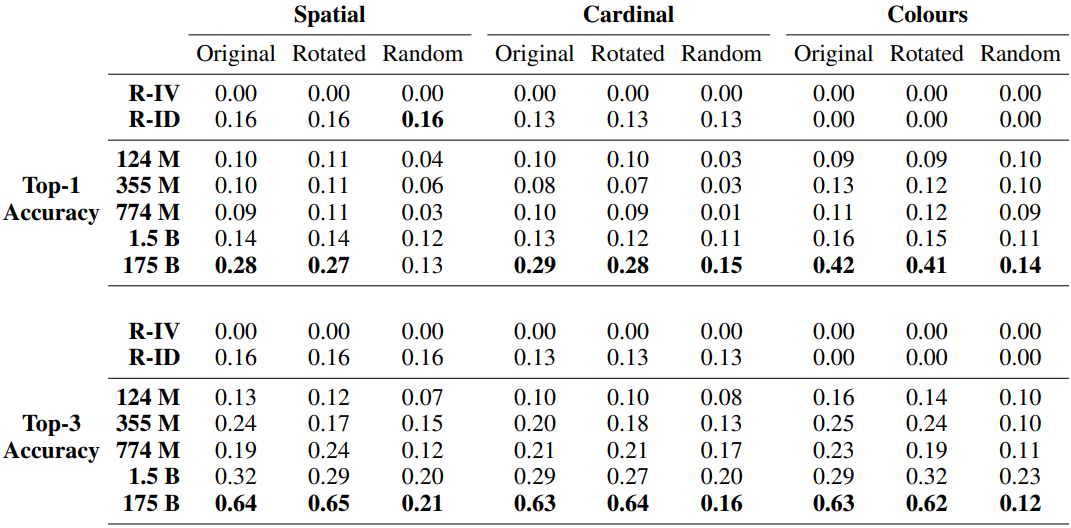
和以前一样,参数数量最多的模型(GPT-3)表现比随机好。特别是,RGB颜色任务显示出超过40%的Top-1准确率,尽管该任务难度很大,但这是令人满意的。请注意,当只用完全匹配而不是部分匹配来计算Top-1和Top-3的准确性时,结果如下。
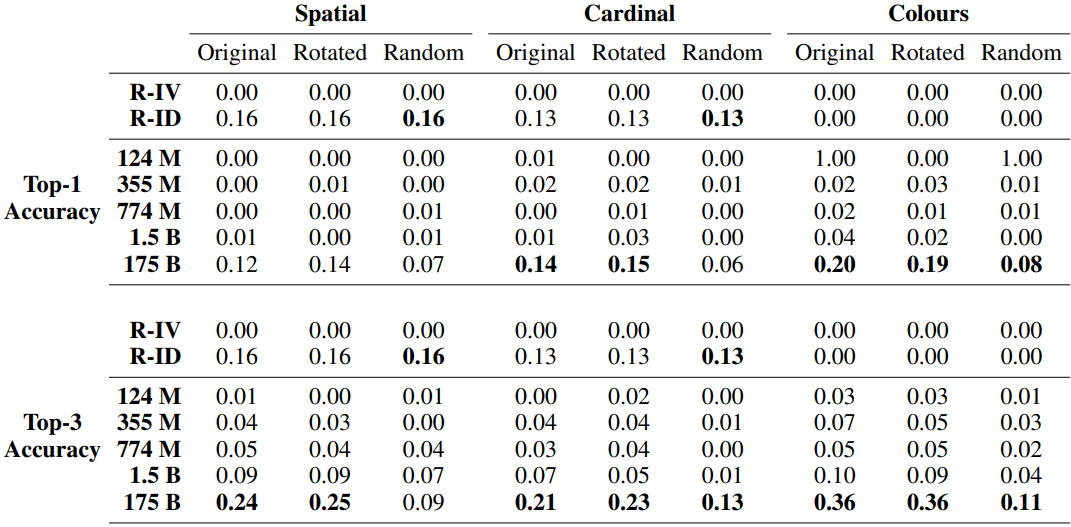
RGB颜色任务的平均接地距离的结果也显示如下。
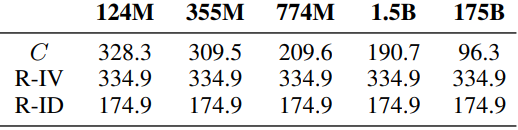
最大的模型表现明显好于随机模型(数字越小越好)。此外,当调查模型的预测结果是否是其领域内的概念时(例如,对于红心方向任务,是否产生了八个方向中的任何一个),最小的模型产生了其领域内53%的反应,最大的模型产生了98%的反应。
摘要
这篇文章介绍了一项处理与接地有关的非常有趣的问题的研究,它涉及到只在文本数据上训练的语言模型是否可以接地到(类似于现实世界的)概念空间,如三维颜色空间或二维空间。
实验结果表明,GPT-3的这种尝试取得了一定的成功,因为它的参数数量非常多。
这些结果可能表明一种有趣的可能性,即只对文本进行训练的语言模型可能能够成功地映射或落地到不同于语言空间的概念空间,这取决于极少的例子。



与本文相关的类别






