最新的基于VAE的完全无监督对象检测和背景分割方法 "SPACE"
三个要点
✔️ 完全无监督的对象检测
✔️ 完全无监督每个背景组件都会分离
✔️ 作为下游任务,有在强化学习中的潜在应用。
SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition
written by Zhixuan Lin, Yi-Fu Wu, Skand Vishwanath Peri, Weihao Sun, Gautam Singh, Fei Deng, Jindong Jiang, Sungjin Ahn
(Submitted on 8 Jan 2020 (v1), last revised 15 Mar 2020 (this version, v3))
Comments: In proceeding of ICLR2020
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV); Machine Learning (stat.ML)
概况
近年来,面向对象的表征学习(OORL)领域的研究*1很多。OORL中的无监督对象分离是基于使用Variational AutoEncoder(VAE)的对象检测(基于空间注意力)和使用VAE的图像对象分离(基于场景混合)。
然而,虽然物体检测基础能够检测和分离前景物体,但只有在已知背景的情况下才能使用。另外,每个物体分离基数的分离图像非常模糊,在前景物体较多的情况下,效果不佳。
正如本文标题所示,这里介绍的最新OORL方法SPACE,结合基于对象检测(Spatial Attention-based)和基于对象分解(Scene Decomposition-based)的技术,它在前景物体多的情况下也发挥作用,并实现State of the Art对象的分离性能。
他还证明它在Atari数据集(强化学习中的标准数据集)中有效地作用, 可以看到它作为下游任务*2应用于强化学习的潜力。
让我们来看看
1 OORL是某种以对象为中心的学习领域,但在本文中,我们将OORL定义为对象分离的领域。
2下游任务是指利用模型解决任务A的任务B。比如,如果将分类中训练的识别模型用于物体检测,物体检测属于下游任务。
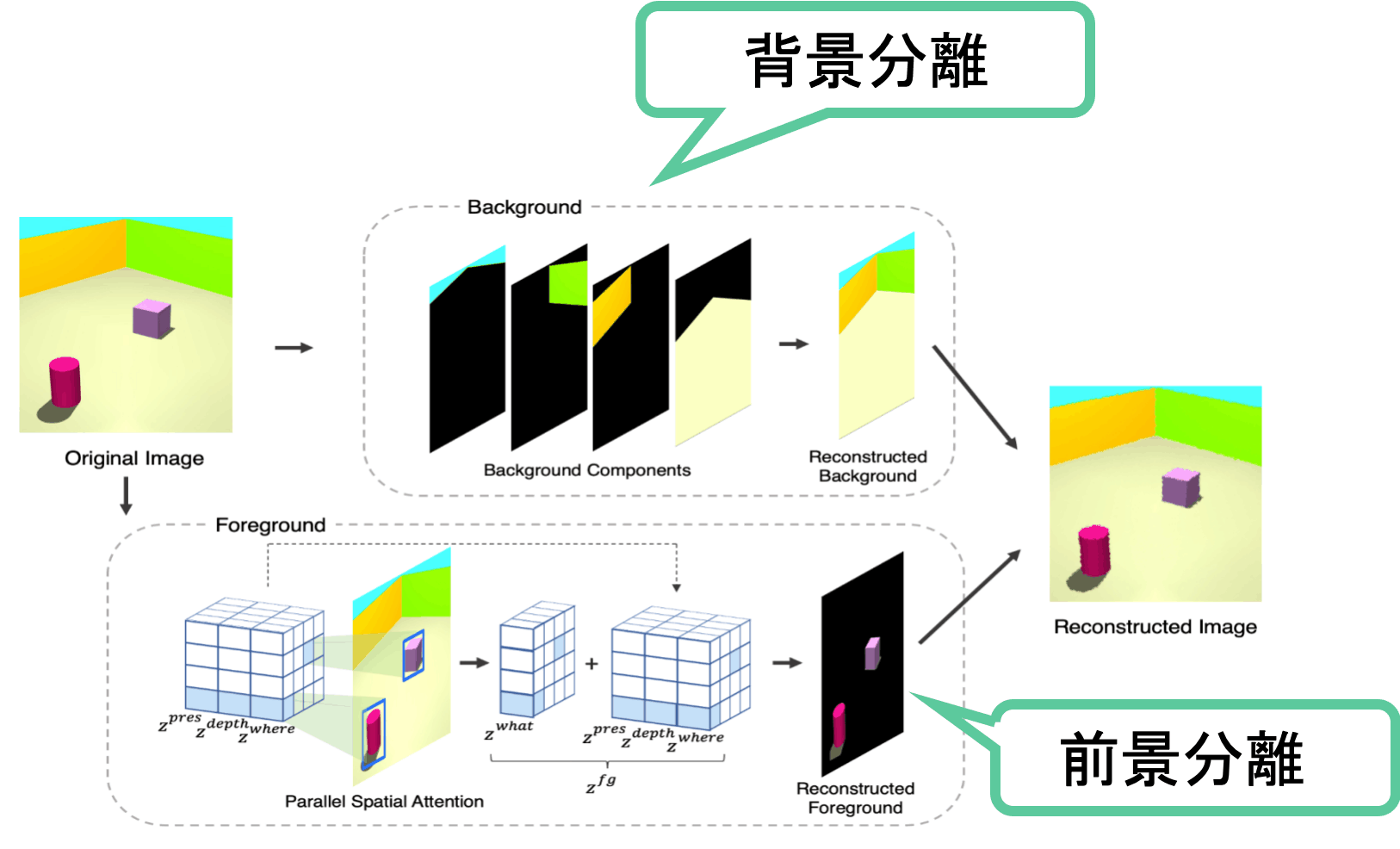
图1:SPACE概述
本论文的主要观点和贡献
主要观点
本文的主旨很简单。为了前景分离采用Spatial Attention Base, 而为了背景分离采用Scene Decomposition。是一个非常合理的想法。
为了理解本文,先要了解VAE和基于空间注意力和基于场景混合的方法。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别
