可扩展的贝叶斯反强化学习!实现安全模仿学习的第一步!
三个要点
✔️ 贝叶斯反强化学习的研究,可以量化奖励函数的估计的不确定性
✔️ 提出了一种学习算法,通过避免MCMC迭代,可以应用于大状态空间的问题,而MCMC迭代是传统贝叶斯反强化学习的瓶颈。
✔️ 在医疗诊断数据集的比较实验中,实现了比基准方法更高的推理性能
Scalable Bayesian Inverse Reinforcement Learning
written by Alex J. Chan, Mihaela van der Schaar
(Submitted on 11 Mar 2021)
Comments: ICLR2021
Subjects: Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
介绍
逆向强化学习是一种从预期任务的行为数据中学习奖励函数的方法。然后可以通过使用学到的奖励函数进行强化学习来学习模仿行为数据的策略。这个框架被称为模仿学习并被称为是一种学习代表人类决策的措施的方法,同时将奖励函数的设计自动化,这在传统的强化学习中是一个挑战。
这项研究涉及贝叶斯反强化学习,它使模仿学习通过确定奖励函数的后验分布,考虑到了奖励函数估计的准确性的不确定性。估算奖励功能估计的准确性的不确定性的好处包括评估所学措施的安全性和制定未来的数据收集计划。传统的贝叶斯反强化学习(Ramachandran & Amir, 2007)使用一种基于马尔科夫链蒙特卡洛方法(MCMC)的算法,从后验分布中多次取样,并且奖励函数被估计为这些样本的样本平均值。然而,在计算奖励函数的样本平均值的过程中Q-函数(Q-值)(即样本平均数)的过程中计算奖励函数的样本平均数,从计算复杂性的角度来看,这种方法很难应用于大量状态的问题。
在本研究中,奖励函数的后验分布和由奖励函数的期望值计算出的Q函数由独立的函数近似器表示,而变量推理。提出了一种算法,通过对代表奖励函数和Q函数之间关系的约束条件下的Q函数得出的目标函数进行优化,同时更新两个函数近似器的参数。由于所提出的方法直接对奖赏函数的期望值建立了Q函数模型,它的优点是可以在不进行计算昂贵的MCMC的情况下计算这些措施。此外,所提出的方法学习了由奖励函数的后验分布和奖励函数的期望值计算的Q函数作为函数近似值,使该方法适用于连续状态空间和连续行动空间的问题。
在这项研究中,所提出的方法的优势在网格世界任务、连续状态空间的控制任务和关基于对网格世界任务、连续状态空间的控制任务和离线医疗诊断任务的三类实验结果,显示了所提方法的优越性。特别是表明,在离线医疗诊断任务中,所提出的方法可以取得比现有基准方法更好的推理性能,用于离线反强化学习。

以前的工作
在本节中,我们概述了贝叶斯反强化学习的前期工作(Ramachandran & Amir, 2007)。在下文中,我们假设已经获得了所需任务的行为数据集$/mathcal{D} = \{tau_1, \tau_2, \cdots, \tau_N \$。每个行为数据$tau_n$被表示为一系列数据,由成对的状态$s\in\mathcal{S}$和行为$a\in\mathcal{A}$组成。
$$ \tau = {(s_0, a_0), (s_1, a_1), \cdots, (s_T, a_T)} \tag{a}$$
在贝叶斯的反强化学习中,在$S$状态下的国家行动值。选择使$Q^{\pi}_{R}$最大化的行动$a$是最佳策略$=pi(s)$是假设最优政策$pi(s)$为$Q^{pi}_{R}$。
$$ \pi(s)\in \underset{a\in\mathcal{A}}{operatorname{argmax}}Q^{pi}_{R}(s, a) \tag{b}$$
其中$Q^{\pi}_{R}$是Q函数(状态-行动价值函数),以及在已知奖励函数$R$的环境中,在状态$s$下执行动作$a$,然后遵循政策$pi$。的情况下它代表了预期的总赢得的回报。
$$ Q^{{pi}_{R}(s, a) =\mathbb{E}_{pi, \mathcal{T}}\left\lbrack\sum_{t}\gamma^{t}R(s_t, a_t)\middle| s_0=s, a_0=a, \pi \right\rbrack\tag{c}$$$$
其中$gamma\in\lbrack 0, 1)$是贴现率,这是一个超参数,表示在当前决策中考虑未来所得报酬的程度。
贝叶斯反强化学习估计了奖励函数$P(R\mid\mathcal{D})$的后验分布,在此情况下,行为数据$mathcal{D}$得到了。后验分布可以通过贝叶斯定理计算如下:。
$$P(R\mid `mathcal{D}) = `frac{P(`mathcal{D}mid R)P(R)}{P(`mathcal{D})}`tag{d}$$
$P(R)$是奖励函数的先验分布,如果选择得当,代表奖励函数的先验知识。另外,$P(\mathcal{D}\mid R)$是似然函数,一个代表从假定模型中获得参数的观察值的可信度的量。在贝叶斯反强化学习中,假定似然函数可以用波尔兹曼分布表示,Q函数为能量函数。
$$begin{align}P(\mathcal{D}\mid R) &=\prod_{n=1}^N P(\tau_n \mid R)\cp&prop to \prod_{n=1}^N \sum_{(s, a)\in\tau_n}\expleft(\beta)Q^{\pI}_{R}(s, a)\tag{e}$$$} \tag{e}$$$$
其中$\beta\in\lbrack 0, 1)$是反温度,是代表示范者选择最优行为程度的超参数。
在贝叶斯反强化学习中,奖励函数的期望值由后验分布中的样本平均值来近似,而Q函数则使用作为样本平均值得到的奖励函数来估计。在这种情况下,使用MCMC从后验分布中取样,在MCMC内部使用基于奖励函数后验分布的比率的拒绝条件迭代地进行样本选择。另一方面,从公式(e)中可以看出,在贝叶斯反强化学习中,似然函数取决于Q函数,所以每次计算拒绝条件时都需要计算Q函数。因此,它在处理大状态空间的问题设置中的应用被认为在计算复杂性方面很困难。
建议的方法
本文提出了一种不需要从奖励函数的后验分布中取样的算法,这正是传统贝叶斯反强化学习的瓶颈所在。这里解释了所提方法的目标函数的推导过程。首先,寻找后验分布$P(Rmidmid\mathcal{D})$的近似后验分布$q_{midmid\mathcal{D})的问题可以写成最小化分布之间的KL分歧问题.
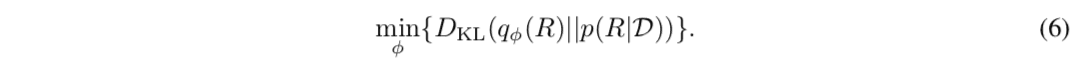
(6)方程。可以根据KL发散的定义进行扩展,并进行如下转换
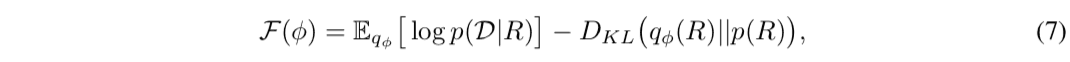
其中$mathcal{F}(phi)$为变量下限(Evidence Lower BOund,ELBO)。是一个叫做$\mathcal{F}(\phi)$的量,已知变异下限的最大化问题等同于公式(6)的优化问题。此外,通过用方程(e)替换方程(7)中第一项的期望值中的似然函数,目标函数可以写成
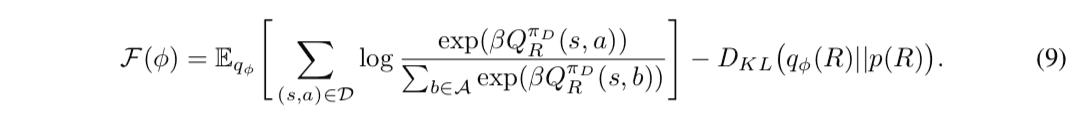
这里,方程(9)中的近似后验分布$q_{phi\}$的期望值计算很难分析,所以是通过$q_{phi\}$的样本平均数来近似计算。这时,由于期望值里面的似然函数取决于Q函数,为了计算样本的平均数,有必要对奖励函数的每个样本计算Q函数。因此,Q函数的迭代计算成为一个瓶颈,在需要处理大量状态的问题设置中,它仍然是计算复杂性方面的挑战。因此,所提出的方法引入了一个函数近似值$Q_{mathbb{E}_{R\sim q_{phi}}\lbrack R\rbrack$,表示奖励函数$mathbb{E}_{R\sim q_{phi}}\lbrack$的期望值的Q函数,相对于近似后验分布$q_{phi}}$,并同时进行训练。在这种情况下,Q函数和奖励函数的更新贝尔曼方程必须以符合以下条件的方式进行:1.贝尔曼方程是一个表达式,它给出了Q函数的递归定义,可以用奖励函数$R$写下来,如下所示
$$ R(s, a) = \mathbb{E}_{pi, \mathcal{T}}\lbrack Q(s, a) - \gamma Q(s^{\prime}, a^{\prime}) \rbrack \tag{f} $$
因此,可以增加一个约束条件,即$q_{phi}$的负对数似然小于使用代表Q函数的函数近似器$Q_{theta}$计算的奖励函数值中的一个足够小的正数$epsilon$。
$$ -log q_{phi}\left( \mathbb{E}_{pi, \mathcal{T}}\lbrack Q(s, a) - \gamma Q(s^{\prime}, a^{prime}) \rbrack\right) < \epsilon\tag{g} $$
基于上述,可以得到方程(10)中的优化问题是对方程(9)中优化问题的近似。(下面的公式(10)是直接取自论文中的公式,但在约束条件的符号中似乎有一个印刷错误。该约束条件应该由公式(g)正确表达)。
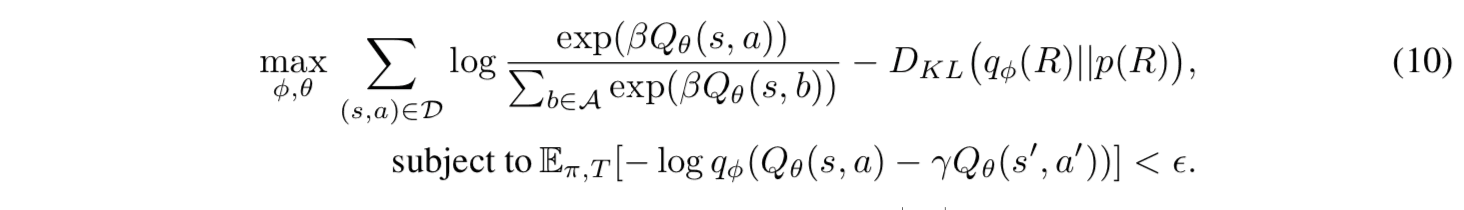
此外,通过使用拉格朗日未定乘数法重写方程(10)中的目标函数,并通过行为数据的样本平均值近似约束条件的期望值,可以得到目标函数$/mathcal{F}(phi, \theta, \mathcal{D})$。
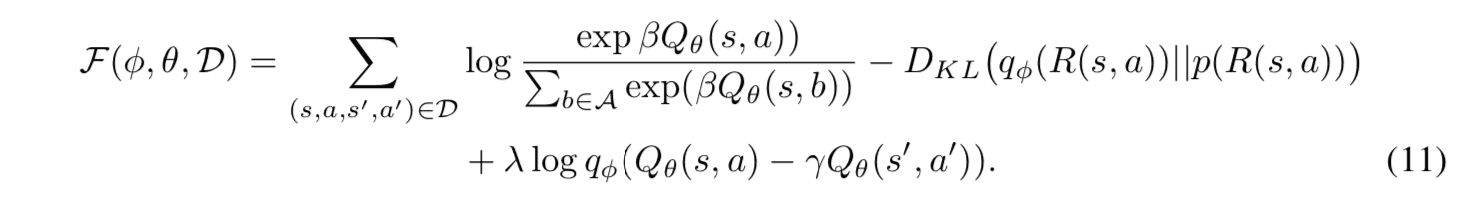 其中$lambda$是一个正常数,决定了约束条件的影响强度。建议的方法是根据方程(10)中$theta$和$phi$的梯度来迭代更新模型。学习算法的伪代码如下所示。
其中$lambda$是一个正常数,决定了约束条件的影响强度。建议的方法是根据方程(10)中$theta$和$phi$的梯度来迭代更新模型。学习算法的伪代码如下所示。

实验
在这项研究中,网格世界任务、连续状态空间上的控制任务,以及在线。医学诊断任务,基于三个不同实验的结果。所提方法的优越性表现在本节介绍了每个实验的内容和结果。
网格世界
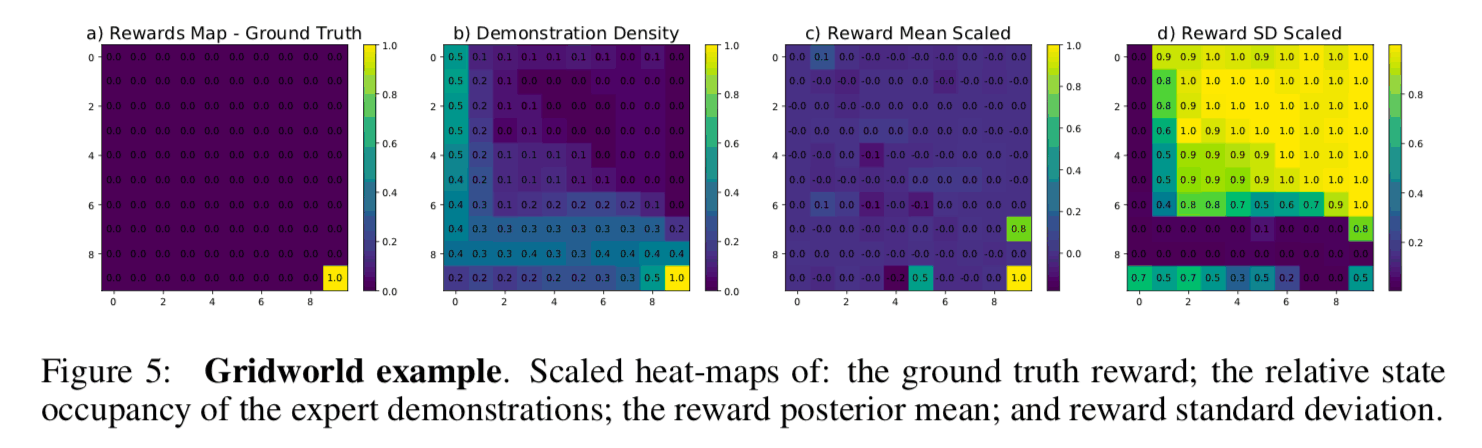
这个任务的目标是通过在棋盘上排列的状态之间的转换来达到目标点。在下图中,a)是人工设计的真实奖励函数,b)是教师数据访问每个状态的频率分布,c)是学习的奖励函数的样本平均值,d)是样本标准偏差的热图可视化。a)和c)的结果可以进行比较。比较b)和d),可以看出,在教师数据中访问频率较低的区域(图中的右上角区域),后验分布的样本标准差较大,表明奖励函数的估计存在较高的不确定性。因此,贝叶斯逆向强化学习的优点是可以量化对奖励函数估计的 "信心",从而可以评估策略的安全性。
连续状态空间上的控制任务。
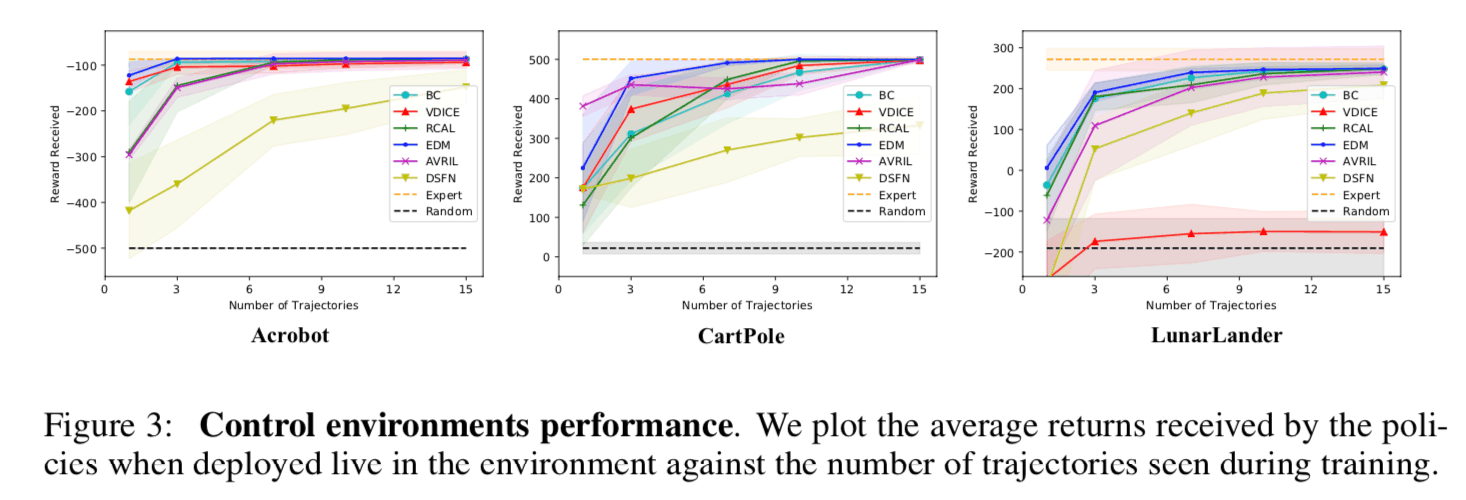
在这个实验中,在OpenAI体育馆的三个不同的机器人控制任务(Acrobat、CartPole和LunarLander)与基准方法进行了比较复杂性样本已经进行了比较。样本复杂度大致代表了一个模型达到足够推理性能所需的教师数据量,较低的样本复杂度方法需要较少的教师数据进行训练。下图中,横轴是教师数据的数量,纵轴是每个控制任务获得的总奖励。图中显示,所提出的方法(AVRIL,粉红色)在两项任务中都取得了与专家相同的性能,教师数据的数量与其他基准方法相似。由于其他基准方法是基于奖励函数的点估计,可以说,所提出的方法能够在类似数量的教师数据下学习到更多的信息结果(奖励函数的后验分布)。
离线医疗诊断任务
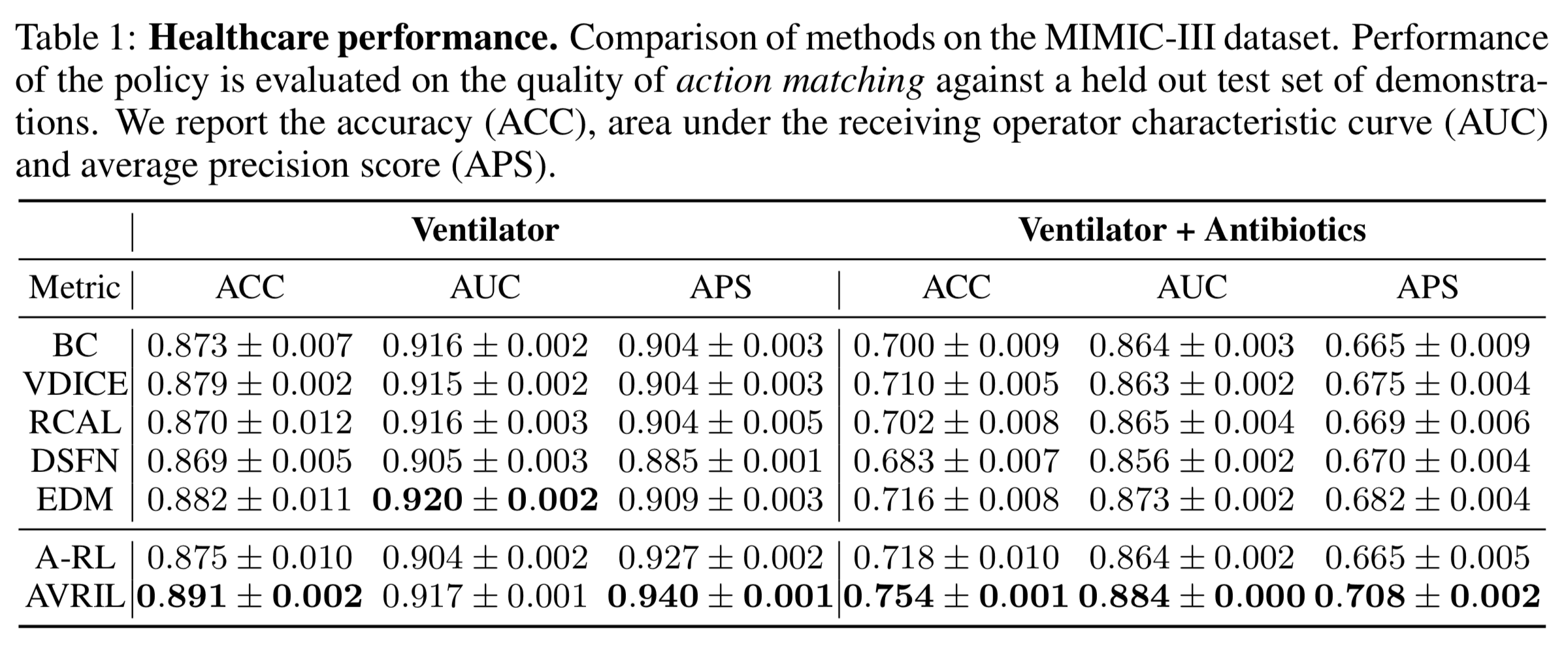
近年来,在探索环境的成本很高的任务中,如物理机器人控制,或者探索环境在伦理上有问题的任务中,如医疗诊断,能够做出适当决定的学习策略。离线强化学习(Offline refinforcement learning)。吸引了很多人的注意。在这个实验中,MIMIC-III数据集,其中每隔一天记录一次病人的情况和医生在重症监护室期间的治疗干预,被用来评估与医疗诊断有关的决策任务的性能。有三个指标被用于评估:ACC(ACCuracy)、AUC(接收操作者特征曲线下的面积)和APC(平均精度得分)。下图左侧显示的是 "是否应该安装呼吸机 "的评估结果,而右侧显示的是 "是否应该进行抗生素治疗 "的额外决定时的评估结果。可以看出,所提出的方法(AVRIL)在这两项任务中普遍优于基准方法。这里,A-RL是一个模型,Q函数是从使用所提出的方法学习的奖励函数的后验分布中学习的样本平均值,但基于AVRIL训练过程中获得的Q函数的措施显示出更好的推理性能。
摘要
本文介绍了可扩展的贝叶斯反强化学习。贝叶斯反强化学习学习了奖励函数的后验分布,这使得估计奖励函数推理结果的不确定性成为可能。然而,从计算复杂性的角度来看,传统的方法很难应用于有大量状态的问题设置,如机器人控制任务。本文提出的算法避免了MCMC迭代执行,而MCMC迭代执行一直是传统贝叶斯反强化学习的瓶颈,并且可以扩展到具有大量状态的问题。利用这个框架,可以学习措施来实现目标,同时避免奖励函数的估计准确度低的状态,所以在实际的现实世界任务中,可能会实现安全的模仿学习。你们为什么不都试一试呢?



与本文相关的类别
