
【MuLan】対照学習を利用したMusic-Textのマルチモーダル
3つの要点
✔️ 対照学習によるMusic-Textのマルチモーダル
✔️ 2つのエンコーダを使用して音楽に文章を付与
✔️ テキストを用いた音楽検索やタグ付けで高精度を叩き出した
MuLan: A Joint Embedding of Music Audio and Natural Language
written by Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, Daniel P. W. Ellis
(Submitted on 26 Aug 2022)
Comments: To appear in ISMIR 2022
Subjects: Audio and Speech Processing (eess.AS); Computation and Language (cs.CL); Sound (cs.SD); Machine Learning (stat.ML)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
最近では、自然言語でデータを説明・分類するが研究が盛んに行われています。具体的には、画像や音声を、テキストで説明するというアイディアです。たとえば、写真の中の犬を「犬」というテキストで説明したり、ある音声を「鳥の鳴き声」と分類したりします。
特に画像分野では、多くのキャプション付き画像データがあるので、より精度の高い学習が可能です。しかし、音声データは、そのようなキャプション付きデータが少ないため、画像に比べて精度が低いのが現状なのです。
そこで本研究では、音楽のイメージ(「悲しい」とか「ロック」)を、テキストでうまく表現するシステムの「MuLan」が作られました。このMuLanは、音楽とテキストの関係を学ぶための対照学習モデルです。
このMuLanによって、高精度で音楽に関する情報を探したり、言葉で音楽を説明したりすることが可能になりました。
手法
本研究の主な手法は、以下の図のように、「音楽」と「テキスト」を用いた対照学習(Contrastive Leraning)です。
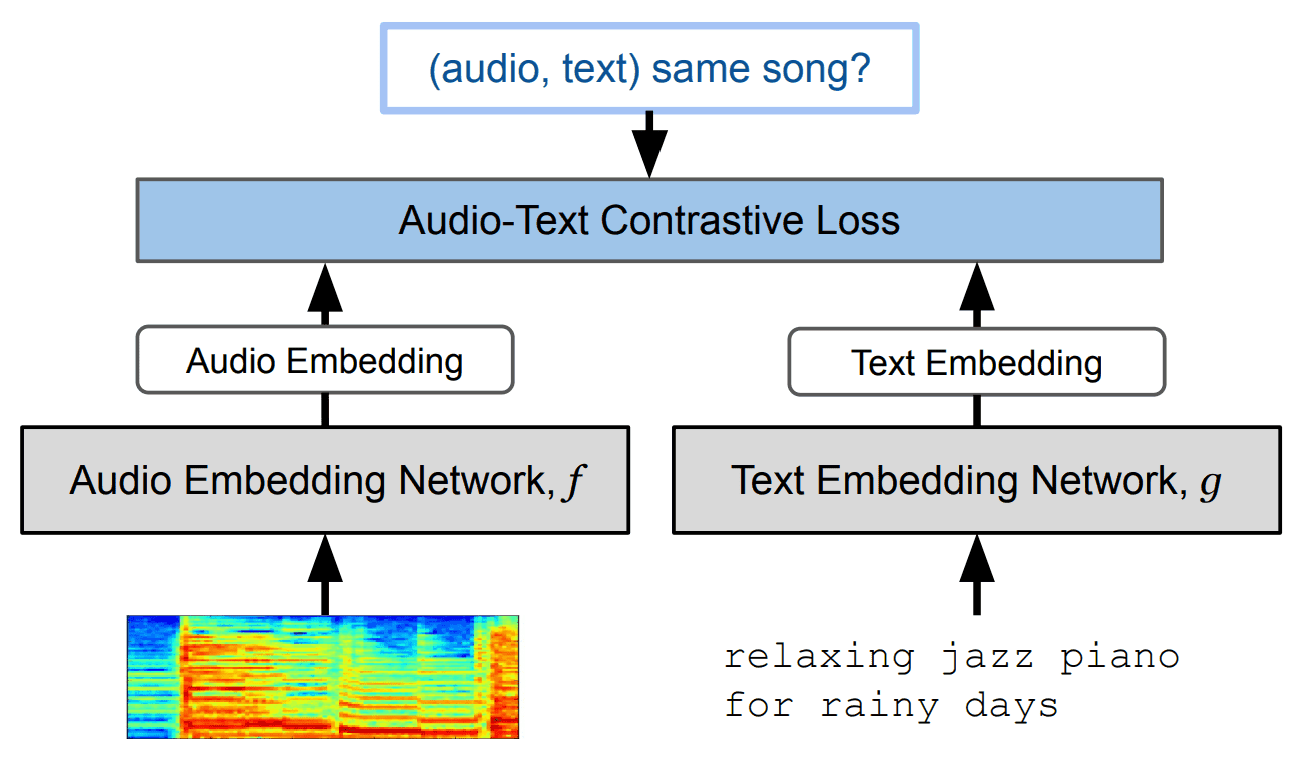
具体的には、以下の手順です。
- 音楽のlog-mel spectrogramをResnet-50またはAudioSpectrogramTransformerでエンコード
- テキストをBERTでエンコード
- 上記2つのembeddingを用いて以下の損失関数を最小化
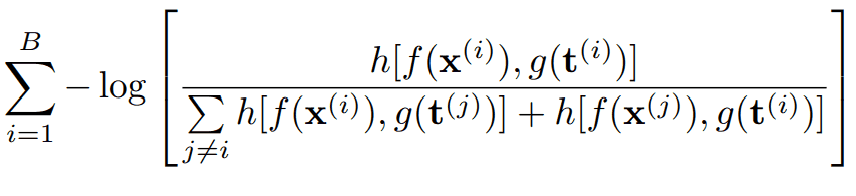
この損失関数の構成要素は、それぞれ以下の通りです。
- B: ミニバッチサイズ
- f(x): 音楽embedding
- g(t): テキストembedding
- h[a, b]: critic function
ここで「Audio Spectrogram Transformer(AST)」は、画像処理の分野で成功を収めた「Vision Transformer(ViT)」という技術を基に作られました。特に、音声分類において、高い性能を持っていると言われています。ASTは、Transformerを12層重ねて使用し、スペクトログラムを「トークン」として処理します。
また、Resnet-50も使用されていることから、音楽データのエンコードでは、音楽のlog-mel spectrogramを「画像」として扱っていることが分かります。
データセット
MuLanの学習には、インターネット上の5000万の音楽動画から集められたデータセットが用いられています。
音声データ
まず、インターネットの音楽動画から音声データとして、「30秒目から始まる30秒間の音声」を切り取られます。その次に、これらの音声が実際に音楽であるかを判定するために、半分以上が音楽でない音楽データは捨てられています。この結果、合計で約370,000時間のデータセットとなりました。
テキストデータ
また、テキストデータとしては、以下の3種類のテキストが使用されています。
- SF: 楽曲のタイトルなどの短いテキスト
- LF: 楽曲の説明文や視聴者によるコメントなどの長いテキスト
- PL: この楽曲が含まれているプレイリストのタイトル
テキストデータの例は、以下の通りです。

ここで、テキストをクリーンにするためにBERTを使い、LFとSFに対して音楽の内容とは無関係なテキストを取り除いています。その結果、テキストデータのサイズは以下のようになりました。
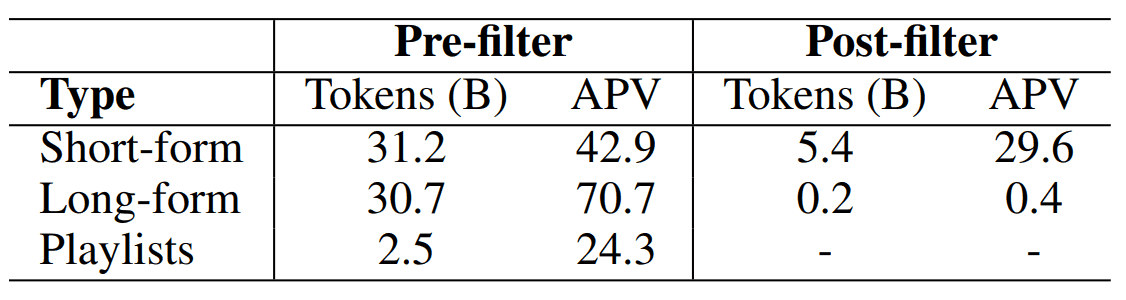
(APV は、テキスト注釈のないものを含む、データ1個あたりのテキスト注釈の平均)
AudioSet
AudioSetというデータセットを使って、10秒間の音声-テキストのペアを作成し、約200万のデータをデータセットに加えています。
これら異なるデータソースは、サイズや質が大きく異なるため、「ミニバッチ」という小分けのデータに分けて、バランスよく混ぜ合わされています。
評価実験と結果
性能評価のために、以下の4つのタスク性能が評価されました。
- ゼロショット音楽へのタグ付け
- 上記モデルへの転移学習
- テキストクエリからの音楽検索
- テキストエンコーダ評価
また、MuLanの音声エンコーダに関しては、先述の通りResNet-50(M-ResNet-50)とAudioSpectrogramTransformer(M-AST)があるため、それぞれの場合に分けて比較が行われています。
それぞれ、方法と結果を順番に見ていきましょう。
ゼロショット音楽へのタグ付けと転移学習
この評価には、以下の2つのベンチマークで実施されています。
- MagnaTagATune(MTAT)
- AudioSet
ゼロショット音楽へのタグ付けの予測スコアは、音楽クリップの「音声埋め込み」と各タグの「テキスト埋め込み」との間のコサイン類似度で定義されます。
また、転移学習の評価でも、先ほどと同じ2つのベンチマークを使用しています。
それらの結果は、以下の通りです。
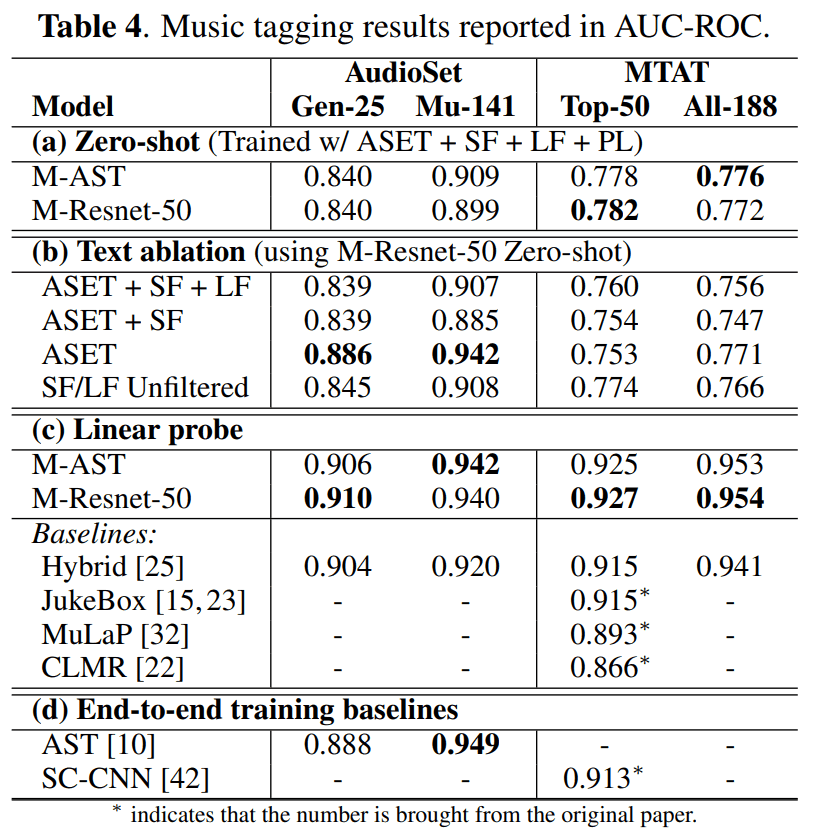
・ゼロショットによる音楽へのタグ付け性能
Table 4(a)は「ゼロショットによる音楽へのタグ付け」の結果を示しています。音声エンコーダのResnet-50とASTでは、似たような性能を示しています。
・テキストデータのフィルタリングの影響
Table 4(b)は、テキストデータのフィルタリングによる性能への影響の結果を示しています。見ての通り、AudioSetのみを使用した学習の場合、最も精度が高いです。
ここで、驚くべきことに、フィルタリングされていないデータを使用した学習は、フィルタリングされた場合と同等の性能を達成しました。これには、テキストフィルタリングが過度であった可能性があり、明確に音楽に関係ない判断されたテキストにも、実は重要な意味があったと考えられています。もしくは、MuLanによる対照学習が、ノイズに対して頑健であることも考えられるでしょう。
・転移学習の結果
Table 4(c)によれば、MuLanの音声埋め込みに線形探査を適用すると、すべてのタギングタスクの転移学習での最高性能を達成しています。
そのため、MuLanの事前学習された音声エンコーダは、その他のタスクにも流用できる可能性があります。
テキストクエリからの音楽検索
この評価では、学習で使用されたプレイリスト情報とは重複しない、7,000の専門家が厳選したプレイリストのコレクションが使用されています。各専門家が厳選したプレイリストには、タイトルと説明があり、10100の音楽録音が含まれています。
プレイリストのタイトルは、通常短いフレーズであり、ジャンル、サブジャンル、気分、活動、アーティスト名などで構成されています。以下の表の「Playlist」が例になります。

ここでは、AUC-ROCと平均適合率(mAP)が指標です。また、ゼロショットタギングのケースと同様に、コサイン類似度に基づいて評価されています。
結果は以下の通りです。
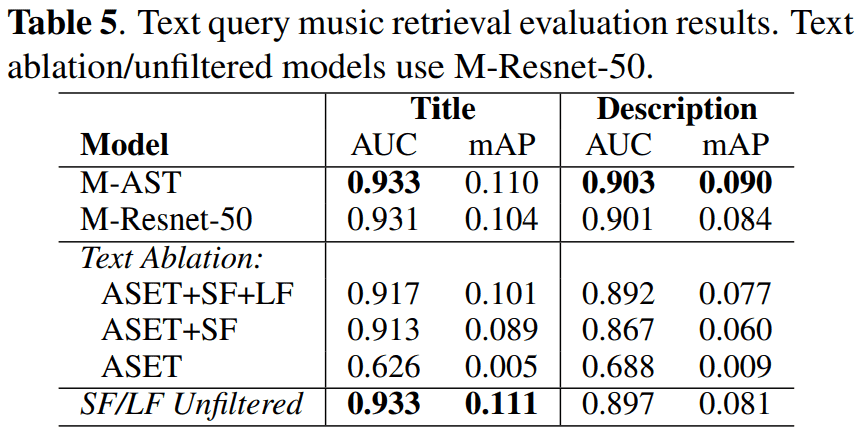
この結果より、ASETに対して「インターネットから取得した大規模なSF」を追加することで、モデルはより細かい音楽の概念を学習するのに役立つことが分かりました。さらに、コメントやプレイリストのデータを含めることで、より複雑なクエリを理解することが可能になったのです。
また、ここでも、フィルタリングされていないテキストでも、良好な性能が得られることが確認されました。
テキストエンコーダ評価
従来の事前学習済みBERTモデルと比較して、MuLanのテキストエンコーダの性能を測定するために、トリプレット分類タスクを用いて評価しています。
各トリプレットは、「アンカー」「ポジティブ」「ネガティブ」という形の3つのテキスト文字列から成り立っています。テキストの埋め込み空間で、ポジティブがネガティブよりもアンカーに近い場合、それは正しいとみなされます。
この評価には、以下の2つのデータセットが用いられています。
| データセット | 内容 |
|---|---|
| AudioSetオントロジー | 141の音楽関連クラスのそれぞれに対して、ラベルの文字列をアンカーテキストとし、長い形式の説明をポジティブテキスト、5つのランダムなクラスの長い形式の説明をネガティブテキストとして使用し、5つのトリプレットを構築 |
| 専門家が集めたプレイリストデータ |
・プレイリストをサンプリングし、そのタイトルと説明をそれぞれアンカーテキストとポジティブテキストとして設定 ・ネガティブテキストをランダムにサンプリングされた別のプレイリストの説明として設定 |
データセットの中身の例は、先ほどのTable 3にあります。
結果は以下の通りです。
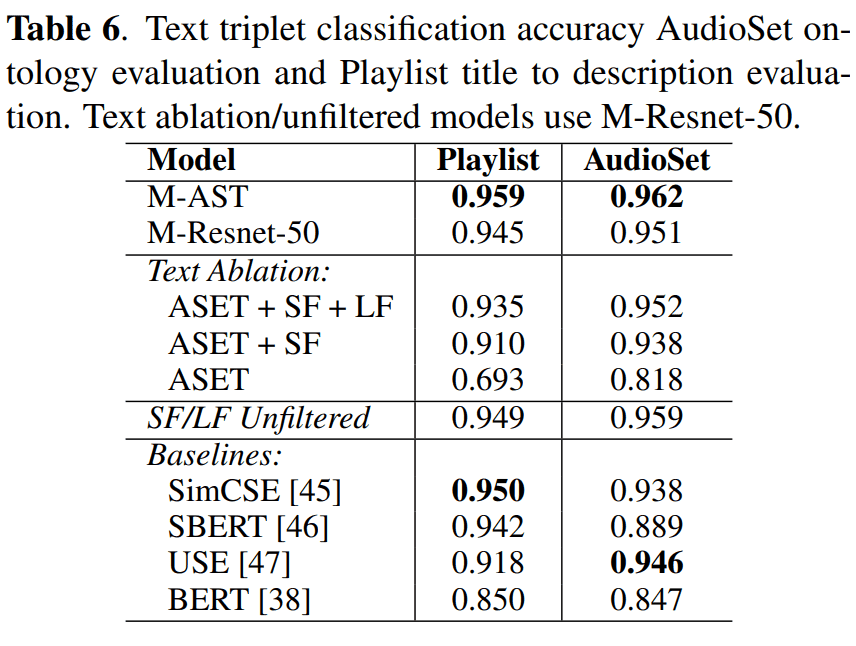
ここでは、以下の4つのモデルと比較しています。
- Sentence Transformer
- SimCSE
- Universal Sentence Embedding
- BERT
結果より、MuLanテキストエンコーダの方が、他の汎用モデルよりも性能が良いことがわかります。このことに関して、MuLanは音楽に特化したモデルでなので、音楽分野での性能が高いこと自体に驚きはありません。
しかし、ファインチューニングなどを使用せずにSOTAを達成されたことは、素晴らしいことだと思います。
まとめ
本記事でご紹介したMuLanは、Text-to-Musicの生成モデルである「MusicLM」でも利用されています。このMusicLMは、テキストプロンプトを入力として、その内容に沿った音楽を生成するモデルです。
このように、MuLanは「音楽とテキストを結びつける」ということに対して、役立てることができるでしょう。






この記事に関するカテゴリー





