セマンティック・セグメンテーションの主な失敗に対処するSelf-Regulationとは?
3つの要点
✔️ セマンティックセグメンテーションにおける主要な失敗例に対処
✔️ 様々なバックボーンに適用できるSelf-Regulation損失を提案
✔️ 弱教師付き/教師付きセグメンテーションタスクで既存手法の性能を向上
Self-Regulation for Semantic Segmentation
written by Zhang Dong, Zhang Hanwang, Tang Jinhui, Hua Xiansheng, Sun Qianru
(Submitted on 22 Aug 2021)
Comments: ICCV 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
画像の各ピクセルに対応するクラスラベルを予測するセマンティックセグメンテーションの研究は、深層CNNなどの進歩により大きく進展しています。例えばEfficientFCNでは、複雑な自然画像のセグメンテーションタスクであるPASCAL Contextにて、約85%のmIOUを発揮しています。
本記事で紹介する論文では、このような既存のセマンティックセグメンテーションモデルにおける主な失敗例に対処するため、Self-Regulationと呼ばれる損失を提案しました。
セマンティックセグメンテーションにおける主な失敗例について
元論文では、セマンティックセグメンテーションにおける主な失敗例として、大きく2つの事例を挙げています。
失敗例1:小さなオブジェクト、またはオブジェクトの小さなパーツの見逃し
第一の失敗は、例えば以下の図のような事例を示します。

この図はDeepLab-v2による予測結果を示しています。図の通り、馬の胴体の予測には成功しているものの、脚の部分の予測には失敗しています。
失敗例2:大きなオブジェクトの一部に別のクラスラベル予測を行ってしまう
第二の失敗事例は以下の通りです。

この図では、画像の約半分を占める牛のうち、一部を馬と誤って予測してしまっています。
元論文で提案された損失関数であるSelf-Regulationは、これら2つの主な失敗例に対処することを目標としています。
失敗例1への対処
以下の図は、DeepLab-v2の馬画像に対するセマンティックセグメンテーション予測時の浅い層・深い層の特徴を可視化したものとなります。
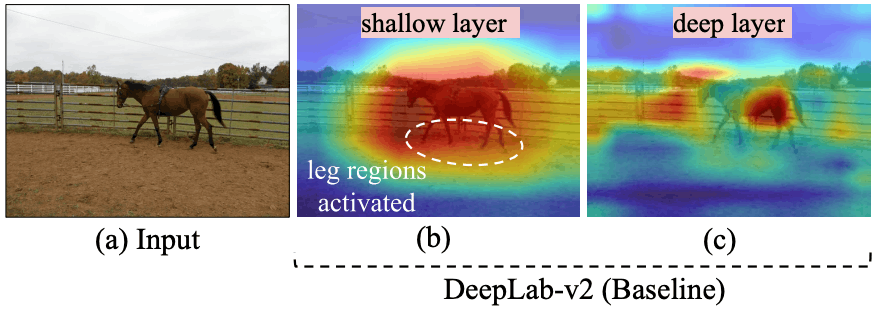
この図を見ると、浅い層の時点では馬の(予測に失敗した)脚部もしっかりと活性化されている一方、深い層では背景の影響を受けており、脚部の情報が軽視されています。
提案手法では、浅い層の特徴マップを教師、深い層の特徴マップを生徒とする蒸留損失を導入することで、浅い層の情報を深い層へと効果的に伝達します。
失敗例2への対処
前述した失敗例2では、牛の一部を誤って馬と予測してしまいました。こうした事例への対処のために、提案手法では画像レベルの分類損失を利用します。
例えば、画像全体に対するクラス予測が「牛」であるならば、画像の中に「馬」のクラスが存在することは直感的に不自然です。
提案手法では失敗例2への対処として、既存手法であるMEA損失(Multi-Exit Architecture loss)の利用に加えて、深い層の分類ロジットを教師、浅い層の分類ロジットを生徒とする蒸留損失を導入します。
これらの対処法は以下の図で示されます。
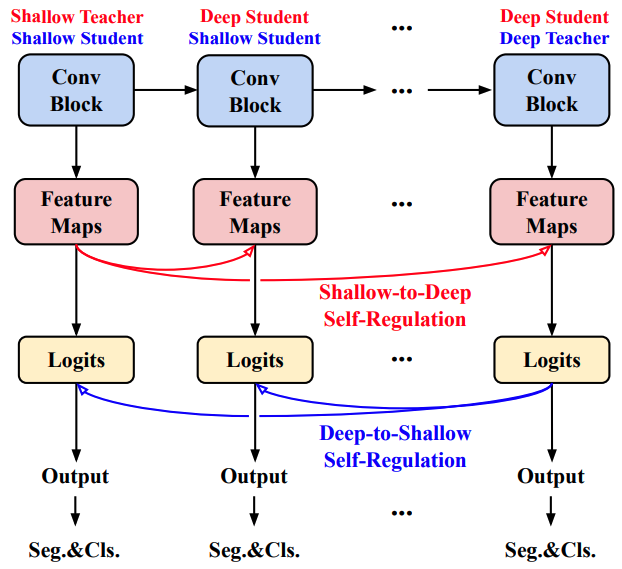
図の通り、各層の特徴マップでは浅い層が深い層を(蒸留損失により)調整し、分類ロジットでは深い層が浅い層を調整することで、前述した問題に対処します。
[提案手法(Self-Regulation)]
Self-Regulationは、三種類の損失を組み合わせて設計されています。順番に見ていきましょう。
損失1:特徴マップを利用したSelf-Regulation損失(SR-F)
SR-Fは前述した失敗例1への対処を目的とした損失であり、浅い層の特徴マップ情報を深い層でも保持するよう促すことを目的としています。これは、前掲した図のShallo-to-Deep Self-Regulationに対応します。
具体的には、最も浅い層(Shallow Teacher)の特徴マップ$T^{[1]}_{\theta}$と、$i$番目の層(Deep Student)の特徴マップ$S^{[1]}_{\phi}$について、SR-F損失$L_{SR-F}$は以下のように求められます。
$L_{ce}(T^{[1]}_{\theta},S^{[1]}_{\phi})=-\frac{1}{M}\sum^M_{j=1} \sigma(t_j)log(\sigma(s_j))$
$L^{\tau}_{ce}(T^{[1]}_{\theta},S^{[1]}_{\phi})=-\tau^2 \frac{1}{M}\sum^M_{j=1} \sigma(t_j)^{1/\tau}log(\sigma(s_j)^{1/\tau})$
$L_{SR-F}=\sum^N_{i=2} L^{\tau}_{ce}(T^{[1]}_{\theta},S^{[1]}_{\phi})$
$L_{ce}$について、$t_j$は特徴マップ$T^{[1]}_{\theta}$の$j$番目のピクセルに対応するベクトル、$s_j$は特徴マップ$S^{[1]}_{\phi}$の$j$番目のピクセルに対応するベクトル、$\sigma$はチャンネルごとのソフトマックス正規化、$M$は特徴マップの幅×高さを示します。
SR-F損失には、知識蒸留において一般的に用いられる温度スケーリングを利用しており、$\tau$は温度パラメータにあたります。
損失2:分類ロジットを利用したSelf-Regulation損失(SR-L)
SR-Lは前述した失敗例2への対処を目的とした損失であり、深い層の分類ロジット情報を浅い層が捉えるよう促し、背景のノイズに対するロバスト性を高めることを目的としています。これは、前掲した図のDeep-to-Shallow Self-Regulationに対応します。
具体的には、最も深い層(Deep Teacher)の分類ロジット$T^{[N]}_{\theta}$と、浅い層(Shallow Student)の特徴マップ$\{S^{[k]}_{\phi}\}^{N-1}\}^{N-1}_{k=1}$について、SR-L損失$L_{SR-F}$は以下のように求められます。
$L_{SR-L}=\sum^{N-1}_{k=1} L^{\tau}_{ce}(T^{[N]}_{\theta},S^{[k]}_{\phi})$
これら二つのSelf-Regulation損失に加えて、MEA損失を利用します(論文の主題ではないため詳細は省きます)。全体として、損失関数は以下のようになります。
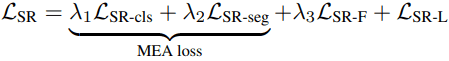
$\lambda_1,\lambda_2,\lambda_3$は各損失の重みを示すハイパーパラメータとなります。
実験結果
実験では、教師付きセマンティックセグメンテーション(FSSS)、弱教師付きセマンティックセグメンテーション(WSSS)の二つのタスクについて、Self-Regulationの評価を行います。
WSSSでは、PASCAL VOC 2012(PC)とMS-COCO 2014(MC)の二つのベンチマークを利用します。
FSSSでは、Cityscapes(CS)とPASCAL Context(PAC)の二つのベンチマークを利用します。
各損失についてのアブレーション研究
提案手法に含まれる三種類の損失(SR-F、SR-L、MEA)についてのアブレーション実験結果は以下の通りです。
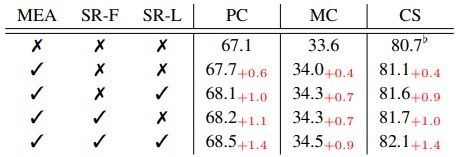
SR損失の導入により、一貫して性能が向上していることがわかります。
提案手法のWSSS/FSSSに対する効果
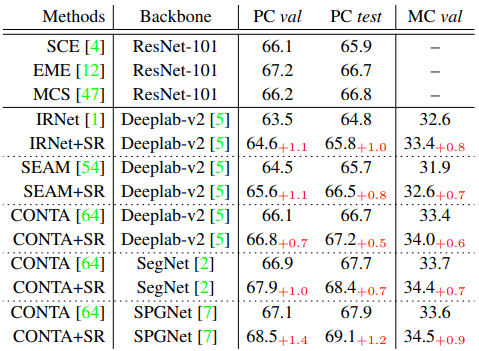
WSSSにおけるベースラインモデルに提案手法を導入した結果は以下の表に示されます。
FSSSの場合は以下の通りです。
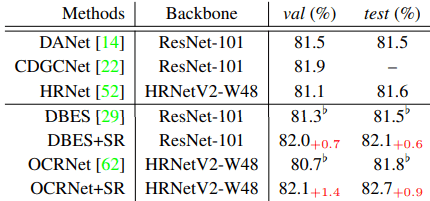
表に示される数値はmIOU(%)を示しています。
WSSS/FSSSどちらのタスクについても、ベースラインモデルに提案手法を導入する(ベースライン名+SR)ことで、一貫して性能が向上しました。
提案手法の計算コストについて
提案手法であるSRを既存のセマンティックセグメンテーションモデルに導入することによる計算コストの増大例は以下のようになります。
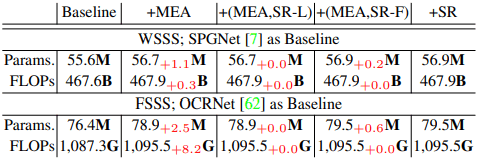
WSSS/FSSSどちらについても、提案手法の導入に伴う計算コストの増大(モデルパラメータ数・FLOPs)は非常に小さく抑えられることがわかりました。
まとめ
本記事では、セマンティックセグメンテーションにおける主な二種類の失敗例に対処することを目標とした損失であるSelf-Regulationについて紹介しました。Self-Regulationは、浅い層から深い層、または深い層から浅い層への蒸留損失により、効果的に浅い層と深い層の特徴マップ・分類ロジットを調整します。提案手法は弱教師付き/教師付き問わず、セマンティックセグメンテーションモデルの性能を一貫して向上させることが示されました。
計算コストの少なさ、既存の様々なモデルに導入することができるなど、汎用性・効率性ともに優れた手法であると言えるでしょう。



この記事に関するカテゴリー





