
GANの発展の歴史を振り返る!GANの包括的なサーベイ論文の紹介(応用編)
3つの要点
✔️様々な分野で使用されている 「GAN」の包括的なサーベイ論文の紹介
✔️応用編では、GANの品質を測る指標と様々な応用を紹介
✔️ この記事でGANが何に応用できるか網羅的に把握が可能
A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications
written by Jie Gui, Zhenan Sun, Yonggang Wen, Dacheng Tao, Jieping Ye
(Submitted on 20 Jan 2020)
subjects : Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
はじめに
今回の記事は、GANのサーベイ論文(アルゴリズム編)に続き、生成した画像の品質を測る指標とGANの応用を紹介します。
GANの生成する画像をどう評価するかは、まだまだ難しい問題と言われています。モード崩壊をどう捉えるのか、過適合をどう検知するのかなど、現在提案されている指標では測ることが難しいとされています。しかし、現状どのような指標が一般的に使われているかを知ることは重要です。
また、GANは画像生成のために生まれたアルゴリズムですが、現在では様々な分野で GANの考え方を応用した研究が発表されています。この記事を通して、どのような応用があるのか把握して頂けると幸いです。
GANの性能を測る指標
Inception Score(IS)
ISは生成された画像の品質と多様性を測る代表的な手法の一つです。定義式は以下の通りです。
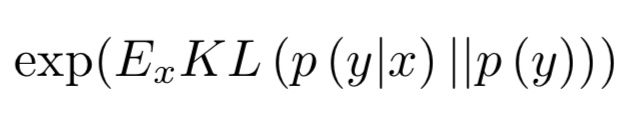
つまり、ISは$p(y|x)$と$p(y)$の差をKLダイバージェンスで測り、二つの分布が大きく異なっていると、大きくなる指標です。
これは、画像分類モデルに生成画像を入力した際に、高い確率でクラスiだと予測されれば、それは生成画像が実画像に似ていると言えます。これは$p(y|x)$で測ることができます。
また、$p(y|x)$を$x$で積分した$p(y)$が平らな分布であれば、生成画像が多様性を持っていると言えます。この二つの観点から生成画像を評価するのがISです。
FID
ISには実画像を考慮していないという欠点があります。それを改善するために考案された指標がFIDです。FIDでは、分類モデルによって、実画像と生成画像から特徴量を抽出します。それらが正規分布に従っていると仮定し、その分布間の距離を測っています。定義式は以下の通りです。
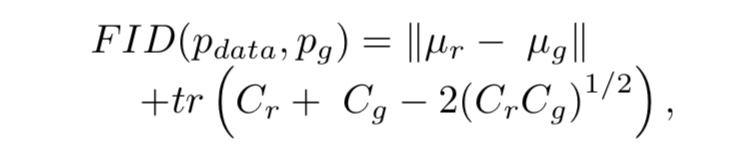
ここで、μrとCrはそれぞれ実画像から抽出された特徴量の平均と共分散、μgとCgはそれぞれ生成画像から抽出された特徴量の平均と共分散です。
MS-SSIM
Multi-scale structural similarity(MS-SSIM)は画像の類似度を測る指標であり、学習したGANがモード崩壊しているかどうか、この指標を用いて捉えることが出来ます。MS-SSIMの定義式は以下の通りです。
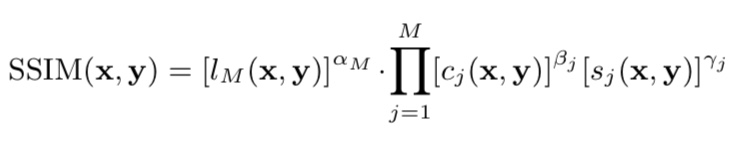
ここで、$x$と$y$はそれぞれ比較したい画像、$l(x,y)$は画像間のピクセル値の変化、$c(x,y)$は画像間のコントラストの変化、$s(x,y)$は画像間の相関係数を表します。
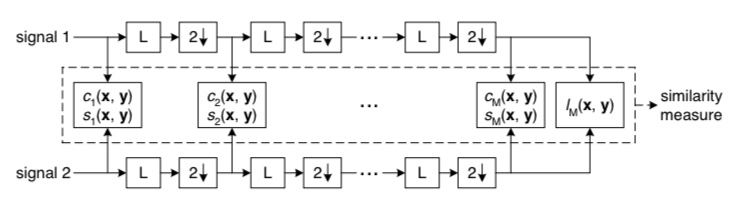
名前にもあるようにMS-SSIMは画像間の変化を異なるスケールで測る指標です。つまり、MS-SSIMでは画像をぼかしていき、それぞれのスケールjの画像に対して$c$と$s$を計算します。なお、$l$はスケールMの画像に対してのみ計算します。これを表したものが以下の図です。
以下の図はMS-SSIMによって、画像間の類似度を計算した例です。

MS-SSIMの値が小さいほど、画像間の類似度が小さい、つまり生成した画像に多様性があることを示しています。
GANの応用
ここからはGANそのもの、もしくはGANの考え方を応用した研究を紹介します。
半教師あり学習
GANは半教師あり学習において、良く使用されます。SGANはGANを拡張して、画像分類における半教師あり学習に適応したものです。
一般的なGANでは、識別器(以後、D)は0〜1の値を取りますが、SGANのDは分類数+1の数の次元を持ちます。最後の次元は生成された画像が偽物であるというクラスです。
つまり、生成器(以後、G)によって生成された画像がどのクラスに所属するのかDによって識別し、クラスiに分類されれば、それを学習データとして用います。ラベル付きの実画像と、ラベルなしの生成画像を用いているという点で半教師あり学習と言えます。
ドメイン適応
ドメイン適応は、学習データ(ソース)とテストデータ(ターゲット)の分布に差がある場合に用いられる手法です。例えば、学習データは日中撮られた画像で、テストデータは夜間に撮られた画像という場面では、データ間の分布に差があります。この差を吸収する手法がドメイン適応技術です。
ADDAはGANをドメイン適応に応用した手法です。下記の図は、ADDAの概要図です。
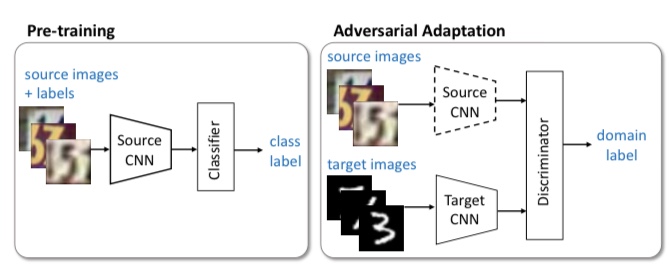
ADDAでは、まずソースドメインのデータでSource CNNを学習します。次に、Source CNNのパラメータで初期化したTarget CNNを用意し、Dはソースから抽出された特徴量なのか、それともターゲットから抽出された特徴量なのか識別するできるように学習します。
CNNを敵対的に学習させ、どちらのドメインからの特徴量なのか、Dが分からなくなるようにCNNを学習させることが出来れば、Target CNNはドメイン不変の特徴量を抽出できるようになったことを示しています。
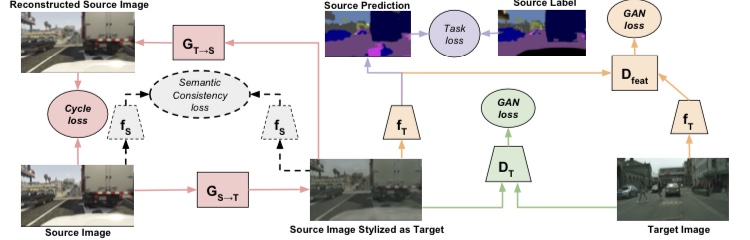
CyCADAと呼ばれる手法では、ソースドメインからターゲットドメインの変換をC ycle GANで行います。この変換後のデータと、ターゲットからの特徴量分布は似ている必要があるので、ADDAと同じように敵対的学習を行うことで分布間の距離を近づけます。下記の図はCyCADAの学習を表した図です。
物体検出
Perceptual GANは小さな物体を検出するために、提案された手法です。物体検出において、大きな物体と小さな物体の特徴マップが大きく異なっていることによって、小さな物体が検出しにくくなっていると論文では指摘しています。下記の図は、Perceptual GANの概要図です。
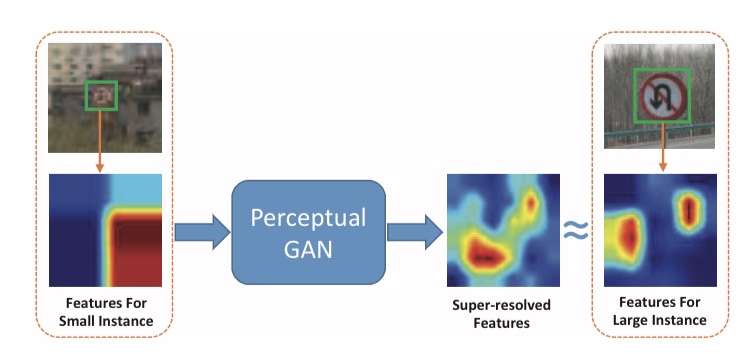
Perceptual GANは、小さな物体の特徴マップを大きな物体の特徴マップに近づけるGと、大きな物体の特徴量マップなのか、小さな物体の特徴量マップからGによって生成された特徴量マップかを識別するDから構成されます。以下の図は、Gによって小さな物体から生成された特徴量マップの例です。
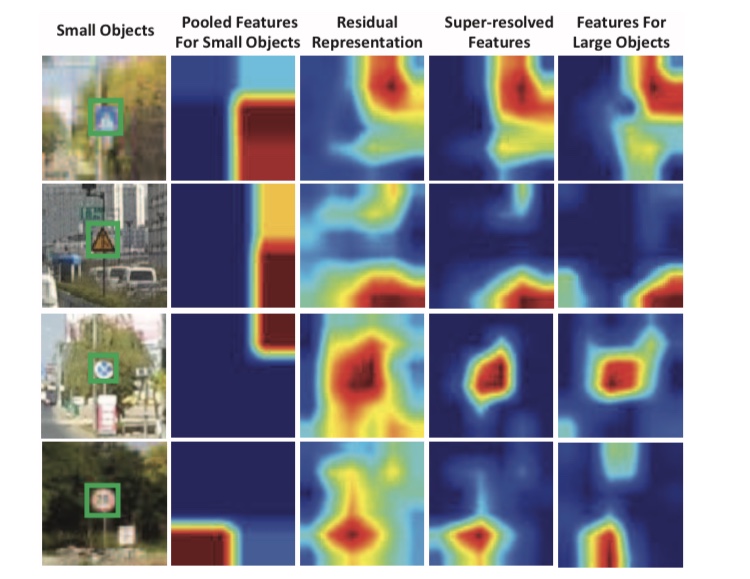
右から2番目の特徴量はGによって生成された特徴量マップで、一番右の列は大きな物体の特徴マップです。これにより、小さな物体でも精度良く検出することが可能となりました。
セグメンテーション
教師なし学習セグメンテーションにGANが使用されています。この手法をReDOと呼びます。
ReDOは物体の境界を識別し、その中身を描き直すGと、Gによって生成された画像か、本物の画像かどうかを識別するDで構成されます。敵対的に学習させることで、Gはセグメンテーションを行うことが可能となります。こちらに解説記事があるので、是非ご覧下さい。
超解像度化
超解像度化とは、荒い画像を高画質の画像に変換するという試みです。SRGANは、初めて超解像度化にGANを適応した研究です。基本的な構造はDCGANと同じで、損失関数は以下の通りです。
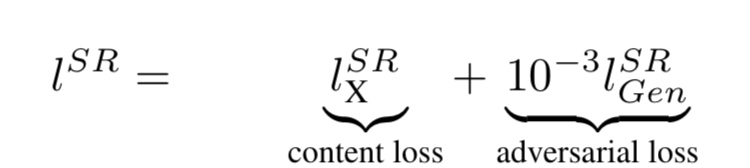
SRGANでは、Gの学習において、通常の の敵対的ロスに加えて、コンテンツロスを加えて学習を行います。これは、生成画像から抽出した特徴量と正解画像から抽出した特徴量の間のロスです。ピクセル単位ではなく、特徴量ベースのロスを考えることで、より人間が見ても違和感のない高画質の画像を生成することに成功しています。
情報検索
IRGANはあるクエリqに対して関連のあるドキュメントdを返すという、情報検索に用いられた初めてのGANです。
情報検索の目的は、あるクエリqと関連のあるドキュメントdを関連づける真の確率分布$p(d|q)$を求めることです。
IRGANでは、 クエリqに対して、Gは関連のあるdをサンプリングできるように学習を行います。一方、DはGの提示してくるdと真に関連のあるdtを精度良く識別するように学習します。学習が収束したとき、Gは真の確率分布に近いものを得られていると期待されます。
自然言語からの画像生成
自然言語を入力として、その言語を反映した画像生成がConditional GANの枠組みで行われています。
TAC-GANは本物の画像Irealに付与されている自然言語tを潜在変数に埋め込み、それとノイズzを合わせたものをGに入力します。下記の図はTAC-GANの概要図です。
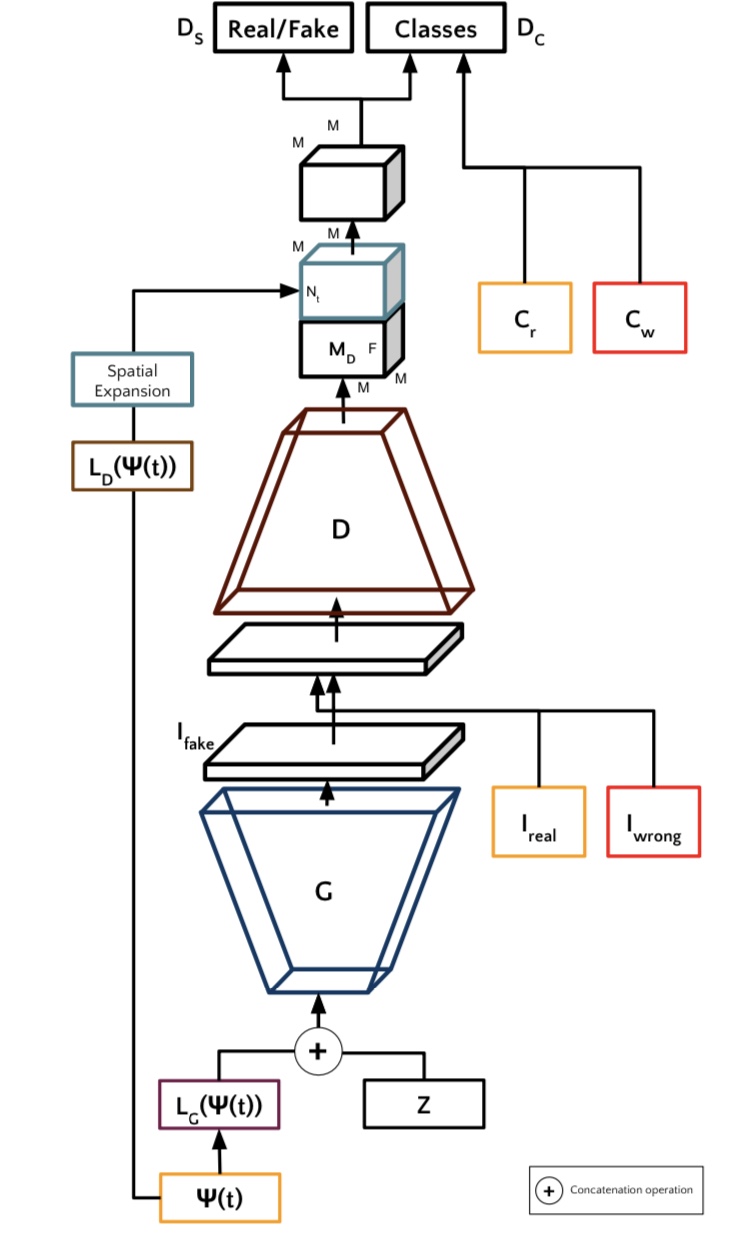
ここで、IwrongはIrealとは異なるクラスに属する画像、CrはIrealのクラス、CwはIwrongのクラスです。TAC-GANのDは通常のGANとは異なり、生成された画像が本物であるかどうかという識別だけでなく、その画像がどのクラスに属するかということまで識別します。
つまり、画像としては本物に近いけれども、クラスとしては異なる(入力言語はCrに付与されている自然言語で、予測されたクラスがCw)とき損失を与えます。こうすることで、その自然言語に対応する画像を生成することが可能となります。以下の図は生成した図の例です。

音楽生成
C-RNN-GANは音楽生成にGANを適用した研究です。下記の図はC-RNN-GANの概要を表した図です。
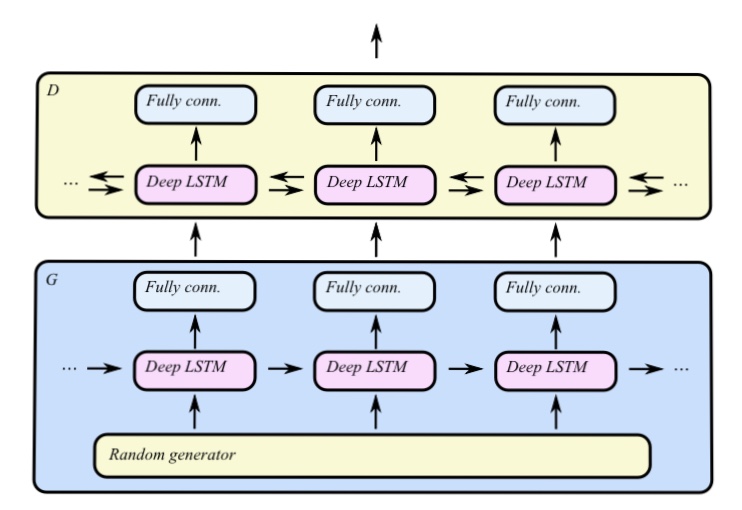
下の青の部分がGを、上の黄色の部分がDを表しています。Gにより生成された音楽が本物か偽物かDは識別し、GはDを騙すような音楽を生成します。
サイバーセキュリティ
近年、マルウェアと呼ばれる悪意のあるソフトウェアやコードによる攻撃が増加しています。この攻撃に対して、マルウェア検知システムを導入することで、ある程度マルウェアを検知し、削除することが可能です。
MalGANはマルウェア検知システムを騙すマルウェアを作成するためのGANです。まず、前提として、マルウェア検知システムの内部情報は知ることができないと仮定します。これをブラックボックス攻撃と呼びます。知ることができるのは、マルウェア検知システムの予測結果だけです。下記の図はMalGANの概要図を表したものです。
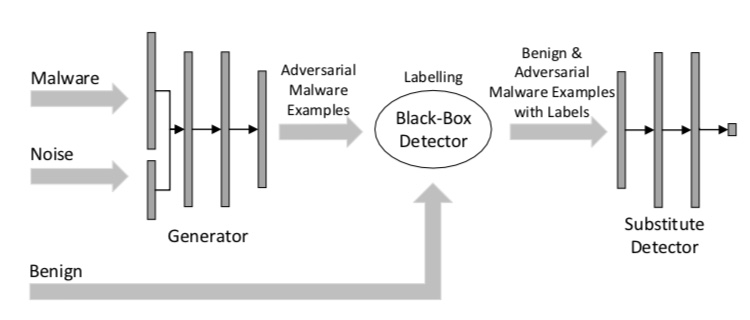
ここで真ん中のBlack-BOX Detector(BBD)が検知システム、右のSubstitute Detector(SD)はBBDの予測結果を模倣するように学習されます。まず、GがBBDを騙すようなマルウェアを生成します。一方、Benign(良性のプログラム)も入力されます。これに対して、BBDは予測ラベルを返すので、それを正解ラベルとして、SDは学習を行います。
このSDがBBDを模倣できれば、あとはSD(つまり、これがDとなります)を騙すように敵対的に学習することができ、その結果、GはBBDを騙すことのできるマルウェアを生成することが可能となります。
まとめ
本記事では、GANの生成する画像を評価する代表的な指標と、GANの応用について紹介しました。この記事を通して、ありとあらゆる分野でGANが応用されていることがお分かり頂けたかと思います。実はまだ、紹介しきれなかったものもあり、GANには無限の可能性が秘められているのだなと改めて感じました。
アルゴリズム編の冒頭で2018年にはGANに関する論文が12000本弱発表されたと述べました。この傾向は、まだまだ続いていき、まだ適応されてない分野にも適応が進んでいくのではないかと思います。皆様も、GANがどのように使用されているのか、チェックしてみてると面白いと思います。






この記事に関するカテゴリー






