AIにとって難しいクイズ問題を集めた新しい質問応答データセット
3つの要点
✔️新しい早押しクイズ形式の質問応答データセットが登場
✔️人間がAIを「騙そう」と試行錯誤しながら、クイズ問題を執筆
✔️「人間には簡単だが、AIには難しい」新しい質問応答データセットが作成された
ディープラーニングを用いた自然言語処理の手法によって、文書読解や自然言語理解などの様々なタスクで、AIのモデルが人間と同等、もしくは人間を超える性能を獲得しはじめています。例えば、文書読解のデータセットSQuADのリーダーボードや、自然言語理解のデータセットGLUEのリーダーボードをみれば、これらのデータセットでAIのモデルが実際に人間を超える性能を出したことが分かります。
しかし、AIは本当に言語を理解していると言えるのか、というと、多くの研究者は、そうではないと答えるでしょう。なぜなら、現状のAIは、言語を理解するのではなく、言語の表層的なパターンをデータセットから学習することで、高い性能を獲得していると考えられているからです。
こうした背景から、より深い言語の理解を行わないと解けない新しいデータセットの開発が進んでいます。このような現状のAIが間違えやすいものを集めたデータセットは、敵対的(adversarial)なデータセットと呼ばれていて、AIの研究における一つのトレンドにもなっています。
では、敵対的なデータセットはどのように作成したら良いのでしょうか。従来の研究では、単にデータセットから簡単な問題を除外したり、問題をなんらかの方法で自動的に書き換えることで、敵対的なデータセットの作成を行っていました。しかし、データセットを自動的に作成する手法では、単純なものしか作成できず、より複雑な問題を作成する手法が求められていました。
この記事で紹介する論文では、人間がAIを騙そうと試行錯誤しながら、敵対的な質問応答のデータセットの作成を行う方法を提案しています。AIの挙動や推論結果を確認できる専用のウェブインターフェイスを開発し、そのインターフェイスを用いて、人間が、AIはどんな問題だとうまく解けないのかを把握し、試行錯誤しながら問題を作成することで、新しい敵対的な質問応答のデータセットを作成しています。
データセットの作成
この論文では、「クイズボウル」と呼ばれる形式で、質問応答のデータセットを作成しています。具体的には、下記のような回答について説明している問題文を受け取って、その問題に対応する回答(例 : Madama Butterfly) を推定するタスクです。なお、クイズボウルは、日本での知名度はあまり高くありませんが、英語圏を中心に普及している最もポピュラーな競技クイズの形式の一つで、早押し形式であることが特徴になっています。 参考 : Madama Butterfly (Wikipedia)

この論文で面白い点の一つは、AIが解きにくい問題を作成するためのウェブインターフェイス(下図)を開発し、そのインターフェイスを通じて、人間(クイズライター)がクイズを作成している点です。クイズライターは、問題を右上のボックスに入力しながら、問題に対するAIの予測(左側)や、AIが予測を行った根拠(右下)を見ることができます。これによって、データセットやWikipediaの中に回答の強い根拠となるような記述がないかどうかを確認しながら、AIが簡単に解けない問題を試行錯誤しつつ書けるようになっています。このウェブインターフェイスをオンラインで公開し、クイズライターに賞金を出すことで、新しいクイズ問題を作成しています。
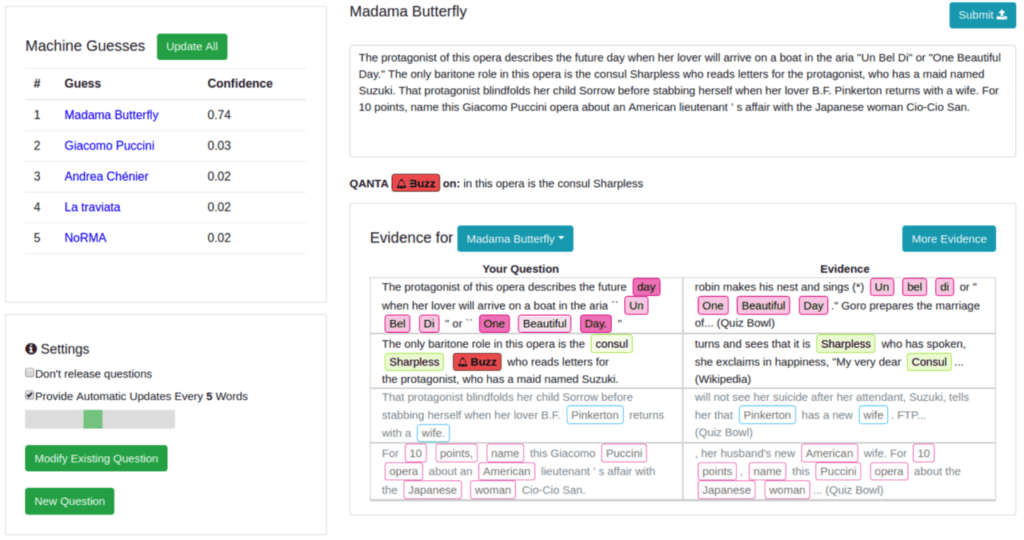
本論文では、ウェブインターフェイス上で、予測やその根拠を提示するAIとして、リカレントニューラルネットワーク(RNN)を用いたAIと、情報検索(IR)の手法を用いたAIの2つの異なるAIを使用しています。そして、RNNを用いたAIの予測を提示して406個の問題(RNN Adversarial)を作成し、情報検索を用いたAIの予測を提示して807個の問題(IR Adversarial)を作成しています。また、作成したデータセットは、下記のページで公開されています。
Adversarial Writing of Quizbowl Questions
データセットの評価
作成した問題の人間にとっての難易度を評価するために、人間のクイズプレーヤーを招いたイベントを開催し、通常のコンペティションで出題されている問題と、今回の論文で作成した問題の双方を出題し、回答の精度を比較しています。
結果、クイズプレイヤー(人間)は通常のコンペティションで出題されている問題について、28.3%の問題に84.2%の正解率で回答を行ったのに対し、今回の論文で作成された問題では41.6%の問題に89.7%の正解率で回答を行いました。この結果から、一般的なコンペティションで出題されているような質問と比較して、人間にとっては今回の論文で新しく作成した問題のほうが簡単であると結論づけています。
続いて、今回作成した問題を用いて、著名な人間のクイズボウルプレイヤーチームと、Studio Ousiaの開発した最先端のクイズボウルAIとの対戦イベントを実施し、評価を行いました。このAIは、国際会議NIPS2017で行われたコンペティションで、著名な人間のクイズチャンピオンチームを破ったシステムです。しかし、このシステムは、通常のクイズボウルコンペティションで出題されていた問題では高い性能を発揮していたものの、この新しく開発した問題においては性能をうまく発揮できず、人間のチームが勝利するという結果になりました。
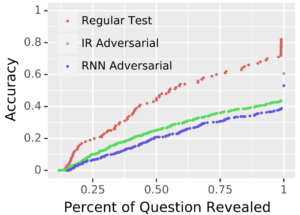
下記の図は、Studio OusiaのAIの性能を、通常のコンペティションで出題されている標準的な問題(Regular Test)、上述したIR Adversarialに含まれる問題、RNN Adversarialに含まれる問題の3つのデータで評価したものです。横軸は、問題文の全体に含まれる単語のうちAIに与えられた単語の割合、縦軸は、回答精度を示しています。図からもわかるように、Regular Testと比較して、今回の論文で開発した敵対的なデータセット(IR Adversarial、RNN Adversarial)では、AIがうまく性能を発揮できていません。これらの結果から、このデータセットが、狙い通りに「人間には簡単だが、AIには難しい」性質を持っていることがわかります。
まとめ
本記事では、AIにとって難しい、敵対的な手法で作成された新しい質問応答データセットを紹介しました。専用のウェブインターフェイスを通じて、人間が試行錯誤しながら、AIが苦手とする問題を作成している点が面白い点だと思います。
また、質問応答システムの研究は、コンピュータが人間の任意の質問に対して回答できることを目指していて、チャットボットやロボット、ウェブ検索エンジンなど、幅広い応用があります。SiriやAmazon Alexaのように、人間がコンピュータに対話形式で接する機会が増えてきている中で、人間の質問に回答する質問応答タスクの重要性はさらに増してくるものと考えられます。また、今回の論文で扱っているクイズボウルのAIは、Wikipediaから質問に対応するエントリを探す機能を持つもので、固有名詞や専門用語が思い出せないときなどに便利に使えるものになっています。
最近のAIの研究の現場は、新しいデータセットやタスクが提案され、それを解けるAIのモデルがすぐに開発されるというような良いサイクルが短期間にまわることで、どんどん賢いAIが実現されていくエキサイティングな環境になっています。私は、この論文で紹介したStudio OusiaのクイズボウルAIの開発者でもあるのですが、より難易度の高いデータセットがリリースされてきたので、今回の新しいデータセットでも、人間を超える精度のAIの開発を行っていきたいと考えています。
論文:Trick Me If You Can: Human-in-the-loop Generation of Adversarial Examples for Question Answering
written by Eric Wallace, Pedro Rodriguez, Shi Feng, Ikuya Yamada, Jordan Boyd-Graber
Submitted on 7 Sep 2018
Status : Accepted for publication in TACL 2019




この記事に関するカテゴリー






