スケーラブルなベイジアン逆強化学習!安全な模倣学習実現への第1歩となるか!?
3つの要点
✔️ 報酬関数の推定の不確かさを定量化することが可能なベイジアン逆強化学習に関する研究
✔️ 従来のベイジアン逆強化学習のボトルネックであるMCMCの反復実行を回避することで大規模な状態空間を扱う問題に対しても適用可能な学習アルゴリズムを提案
✔️ 医療診断データセットを用いた比較実験でベンチマーク手法よりも高い推論性能を達成
Scalable Bayesian Inverse Reinforcement Learning
written by Alex J. Chan, Mihaela van der Schaar
(Submitted on 11 Mar 2021)
Comments: ICLR2021
Subjects: Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。また、論文中に記載のない数式(あるいは論文中で数式番号が振られていない数式)についてはローマ字で数式番号をふっています。論文中で数式番号が振られている数式については論文中の数式番号をそのまま引用しています。
はじめに
逆強化学習(inverse reinforcement learning)とは所望のタスクの行動データから報酬関数を学習する手法です。更に学習した報酬関数を用いて強化学習を実行することにより行動データを模倣する方策を学習することが可能です。この枠組みは模倣学習(imitation learning)と呼ばれており、従来の強化学習の課題であった報酬関数の設計を自動化しつつ人間の意思決定を表現する方策を学習する手法として知られています。
本研究は、報酬関数の事後分布を求めることにより報酬関数の推定精度の不確かさを考慮した模倣学習を可能にするベイジアン逆強化学習に関する研究です。報酬関数の推定精度の不確かさを見積もることの利点としては、学習した方策の安全性の査定や将来のデータ収集計画の策定を実施することなどが挙げられます。従来のベイジアン逆強化学習(Ramachandran & Amir, 2007)ではマルコフ連鎖モンテカルロ(Markov chain Monte Carlo method, MCMC)を応用したアルゴリズムを用いて事後分布からのサンプリングを複数回繰り返し、それらのサンプル平均として報酬関数を推定することが提案されています。しかしながら、報酬関数のサンプル平均を計算する過程でQ関数(Q-values)を反復計算する必要があるため、計算量の観点から状態数が大きい問題に対する適用は困難であるという課題がありました。
本研究では、報酬関数の事後分布と報酬関数の期待値から計算されるQ関数を別々の関数近似器で表現し、変分推定(Variational Inference)から導出された目的関数を報酬関数とQ関数の関連を表す制約条件の上で最適化することにより、2つの関数近似器のパラメタを同時に更新するアルゴリズムが提案されています。提案手法は報酬関数の期待値に対するQ関数を直接モデリングする手法であるため、計算量が大きいMCMCを実行することなく、方策の計算を行うことができるという利点があります。更に、提案手法は報酬関数の事後分布と報酬関数の期待値から計算されるQ関数を関数近似器として学習するため、連続状態空間や連続行動空間上の問題に対しても適用可能な手法と言えます。
本研究では、Grid Worldタスク、連続状態空間上の制御タスク、オフライン医療診断タスクの3種類の実験結果に基づいて提案手法の優位性が示されています。特に、オフライン医療診断タスクにおいては提案手法が既存のオフライン逆強化学習に関するベンチマーク手法を上回る推論性能を達成可能あることが示されています。

先行研究
ここでは、先行研究としてベイジアン逆強化学習(Ramachandran & Amir, 2007)について概説します。以下では、所望のタスクの行動データ集合$\mathcal{D} = \{\tau_1, \tau_2, \cdots, \tau_N \}$が得られているものとします。各行動データ$\tau_n$は状態 $s\in\mathcal{S}$ と行動 $a\in\mathcal{A}$ の組から成る系列データとして表されます。
$$ \tau = \{(s_0, a_0), (s_1, a_1), \cdots, (s_T, a_T)\} \tag{a}$$
ベイジアン逆強化学習では、状態$s$において状態行動価値$Q^{\pi}_{R}$が最大となる行動$a$を選択することが最適方策$\pi(s)$であると仮定します。
$$ \pi(s) \in \underset{a\in\mathcal{A}}{\operatorname{argmax}}Q^{\pi}_{R}(s, a) \tag{b}$$
ここで、$Q^{\pi}_{R}$はQ関数(状態行動価値関数)であり、報酬関数$R$が既知の環境中で状態$s$において行動$a$を実行し、その後は方策$\pi$に従う場合の期待総獲得報酬を表します。
$$ Q^{\pi}_{R}(s, a) = \mathbb{E}_{\pi, \mathcal{T}} \left\lbrack \sum_{t}\gamma^{t}R(s_t, a_t)\middle| s_0=s, a_0=a, \pi \right\rbrack \tag{c}$$
ここで$\gamma \in\lbrack 0, 1)$は割引率であり、現在の意思決定において将来の獲得報酬をどの程度考慮するかを表すハイパーパラメタです。
ベイジアン逆強化学習では、行動データ$\mathcal{D}$が得られた下で、報酬関数の事後分布$P(R\mid\mathcal{D})$の推定を行います。事後分布はベイズの定理により次のように計算することができます。
$$P(R\mid \mathcal{D}) = \frac{P(\mathcal{D}\mid R)P(R)}{P(\mathcal{D})} \tag{d}$$
$P(R)$は報酬関数の事前分布であり、適切に選択することにより報酬関数に対する事前知識を表します。また、$P(\mathcal{D}\mid R)$は尤度関数であり、仮定したモデルから引数の観測値が得られることの妥当性を表す量です。ベイジアン逆強化学習では、尤度関数がQ関数をエネルギー関数とするボルツマン分布で表現できると仮定します。
$$\begin{align}P(\mathcal{D}\mid R) &= \prod_{n=1}^N P(\tau_n \mid R) \\&\propto \prod_{n=1}^N \sum_{(s, a)\in\tau_n}\exp\left(\beta Q^{\pi}_{R}(s, a)\right)\end{align} \tag{e}$$
ここで$\beta\in\lbrack 0, 1)$は逆温度であり、デモンストレーターがどの程度最適な行動を選択しているかを表すハイパーパラメタです。
ベイジアン逆強化学習では、報酬関数の期待値を事後分布からのサンプル平均で近似し、サンプル平均として得られた報酬関数を用いてQ関数の推定を行います。この際、事後分布からのサンプリングはMCMCを用いて行います。MCMCの内部では報酬関数の事後分布の比率に基づく棄却条件を用いたサンプル選定を繰り返し行います。一方で、(e)式で見たように、ベイジアン逆強化学習では尤度関数はQ関数に依存するため、棄却条件の計算の度にQ関数の計算が必要となります。従って、大規模な状態空間を扱う問題設定に対する適用は計算量の観点で困難とされています。
提案手法
本論文では従来のベイジアン逆強化学習のボトルネックである報酬関数の事後分布からのサンプリングが不要なアルゴリズムが提案されています。ここでは提案手法の目的関数の導出過程を解説を行います。まず、事後分布$P(R\mid\mathcal{D})$の近似事後分布$q_{\phi}$を求める問題は分布間のKLダイバージェンスの最小化問題として書き下すことができます。
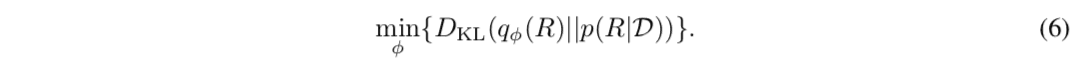
(6)式をKLダイバージェンスの定義に従って展開すると次式のように変形することができます。
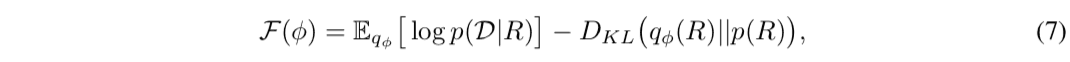
ここで、$\mathcal{F}(\phi)$は変分下界(Evidence Lower BOund, ELBO)と呼ばれる量であり、変分下界の最大化問題は(6)式の最適化問題と同値であることが知られています。更に、(7)式の第1項の期待値に含まれる尤度関数を(e)式で置き換えることにより目的関数を次のように書き下すことができます。
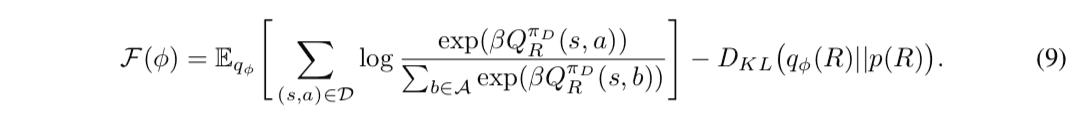
ここで(9)式の近似事後分布$q_{\phi}$についての期待値計算は解析的に計算することが困難であるため、$q_{\phi}$からのサンプル平均により近似的に計算を行います。この時、期待値内部の尤度関数はQ関数に依存するため、サンプル平均を計算するためには報酬関数のサンプル毎にQ関数を計算する必要があります。従って、Q関数の反復計算がボトルネックとなり、大規模な状態数を扱う問題設定においては計算量の観点で課題が残ります。そこで、提案手法では、近似事後分布$q_{\phi}$に関する報酬関数の期待値$\mathbb{E}_{R\sim q_{\phi}}\lbrack R \rbrack$に対するQ関数を表現する関数近似器$Q_{\theta}$を導入し、近似事後分布$q_{\phi}$と同時に学習を行います。この際、Q関数と報酬関数の更新をベルマン方程式(Bellman equation)に矛盾しないように実行する必要があります。ベルマン方程式とはQ関数の再帰的な定義を与える式であり、報酬関数$R$を用いて次のように書き下すことができます。
$$ R(s, a) = \mathbb{E}_{\pi, \mathcal{T}}\lbrack Q(s, a) - \gamma Q(s^{\prime}, a^{\prime}) \rbrack \tag{f} $$
従って、Q関数を表現する関数近似器$Q_{\theta}$を用いて計算した報酬関数の値において$q_{\phi}$の負の対数尤度が十分小さな正数$\epsilon$未満になることを拘束条件として加えることが考えられます。
$$ - \log q_{\phi}\left( \mathbb{E}_{\pi, \mathcal{T}}\lbrack Q(s, a) - \gamma Q(s^{\prime}, a^{\prime}) \rbrack\right) < \epsilon \tag{g} $$
以上を踏まえて(9)式の最適化問題の近似として(10)式の最適化問題を得ることができます。(以下の(10)式は論文中の数式をそのまま引用していますが、拘束条件の表記に誤植があると思われます。拘束条件は正しくは(g)式で表されると思われます。)
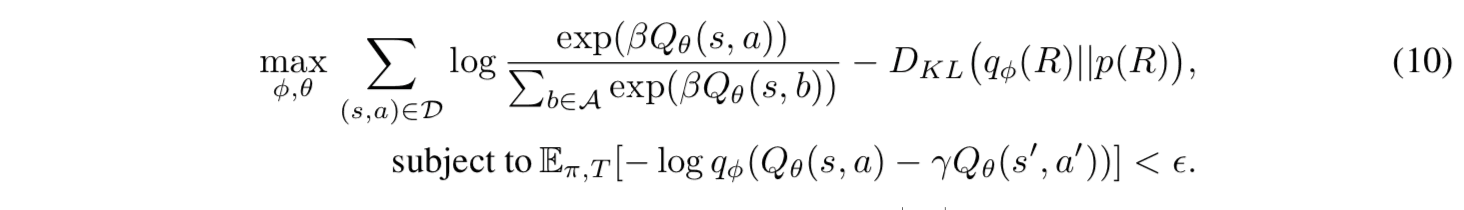
更に、(10)式の目的関数をラグランジュ未定乗数法を用いて書き換え、拘束条件の期待値を行動データのサンプル平均で近似することにより、目的関数$\mathcal{F}(\phi, \theta, \mathcal{D})$が得られます。
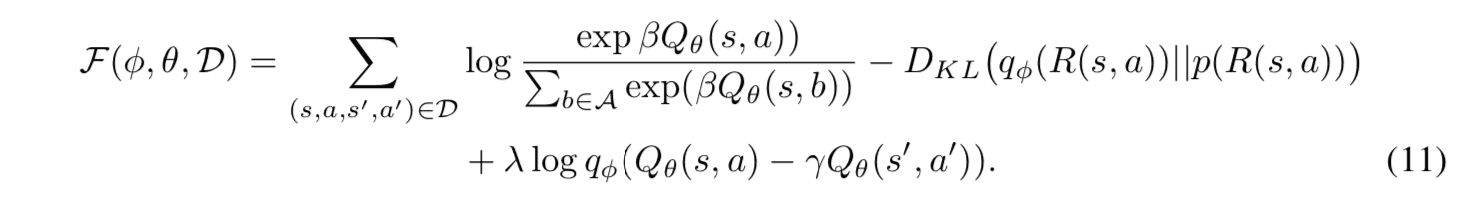 ここで、$\lambda$は拘束条件の影響の強度を決める正の定数です。提案手法では、(10)式の$\theta$と$\phi$に関する勾配に基づいてモデルの更新を繰り返します。以下に、学習アルゴリズムの擬似コードを示します。
ここで、$\lambda$は拘束条件の影響の強度を決める正の定数です。提案手法では、(10)式の$\theta$と$\phi$に関する勾配に基づいてモデルの更新を繰り返します。以下に、学習アルゴリズムの擬似コードを示します。

実験
本研究では、Grid Worldタスク、連続状態空間上の制御タスク、オンライン医療診断タスクの3種類の実験結果に基づいて提案手法の優位性が示されています。ここでは各実験の内容と結果について解説します。
Grid World
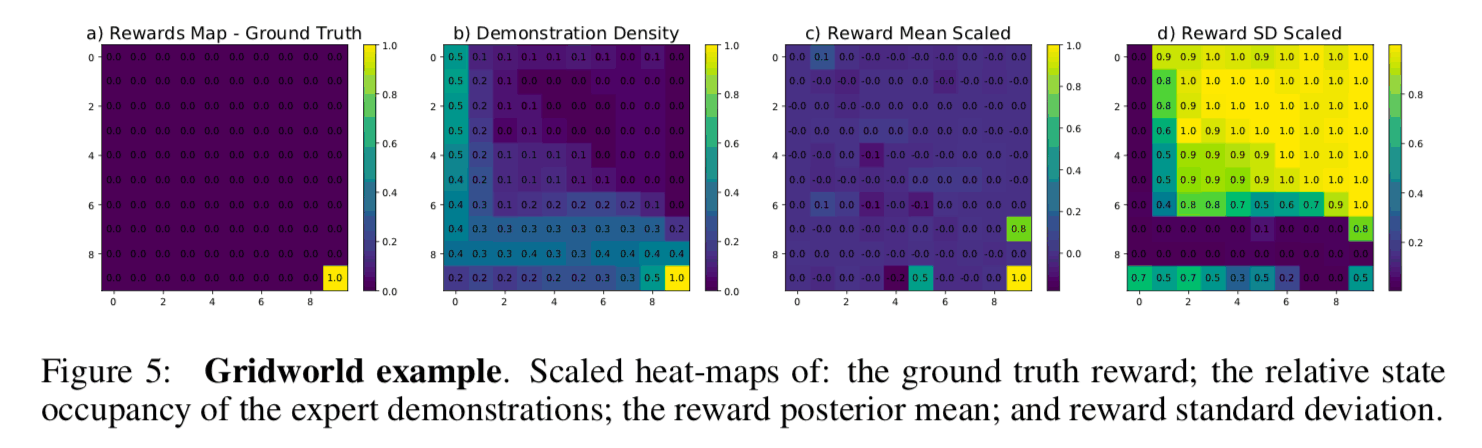
このタスクの目標は碁盤上に配置された状態間を遷移して目標地点まで到達することです。下図のa)は手動で設計した真の報酬関数、b)は教師データが各状態を訪問した頻度分布、c)は学習した報酬関数のサンプル平均、d)はサンプルの標準偏差をヒートマップで可視化した図です。a)とc)を比較すると、概ね真の報酬関数に近い推定結果を得ることができていると言えます。また、b)とd)を比較すると、教師データにおいて訪問頻度が低い領域(図中右上の領域)においては事後分布からのサンプルの標準偏差が大きくなっており、報酬関数の推定の不確実性が高いことが分かります。このようにベイジアン逆強化学習では報酬関数の推定の「信頼度」を定量化することが可能であるため、方策の安全性を評価することができるという利点があります。
連続状態空間上の制御タスク
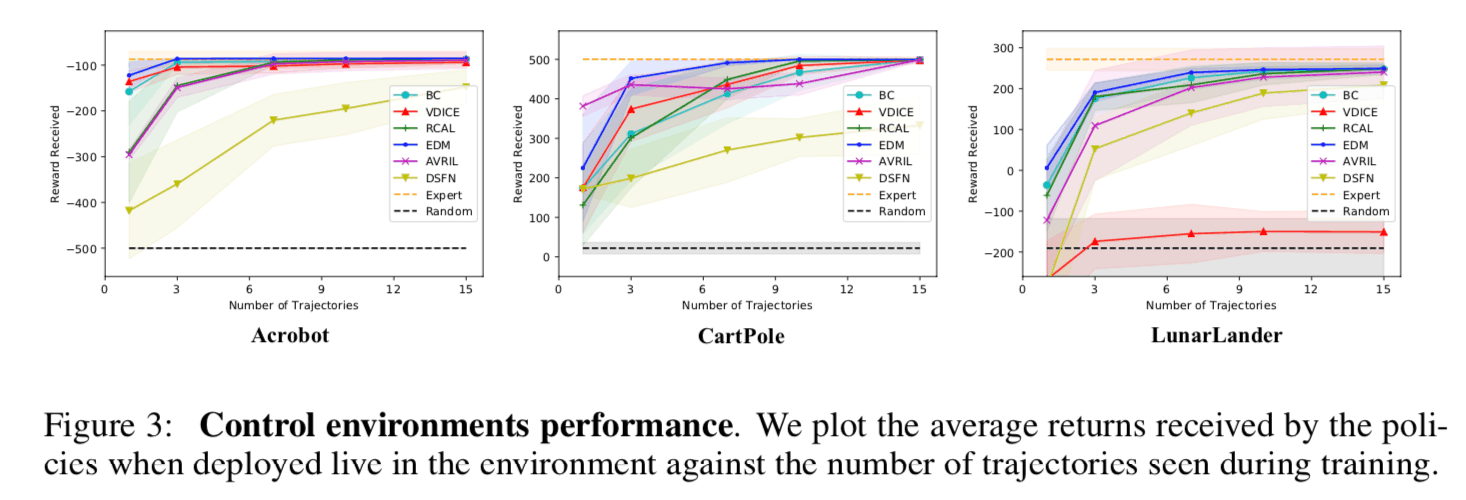
本実験では、OpenAI gym上の3種類のロボット制御タスク(Acrobat, CartPole, LunarLander)において、ベンチマーク手法とのサンプル複雑度(sample complexity)の比較が行われています。サンプル複雑度とは大雑把には、モデルが十分な推論性能に達するまでに必要な教師データの量を表しており、サンプル複雑度が低い手法ほど学習に要する教師データが少量で済むモデルと言えます。下図に各制御タスクにおいて、横軸を教師データの数、縦軸を総獲得報酬としてプロットした図を示します。この図からは、提案手法(AVRIL, ピンク)はいずれのタスクにおいても他のベンチマーク手法と同程度の教師データ数でエキスパートと同等の性能を達成していることが分かります。他のベンチマーク手法は、報酬関数を点推定するアプローチであるため、提案手法は同程度の教師データでより情報量が多い結果(報酬関数の事後分布)を学習できる手法であると言えます。
オフライン医療診断タスク
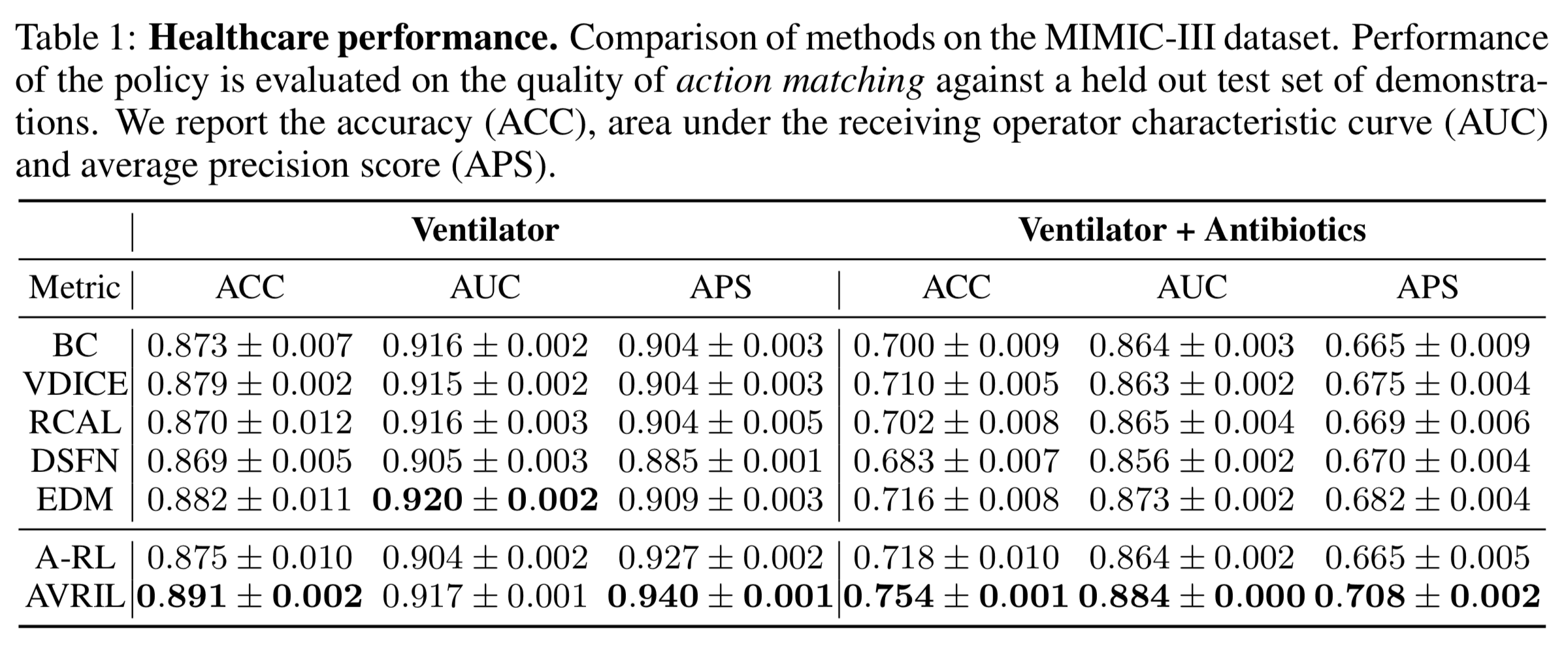
近年、物理ロボットの制御などの環境の探索コストが高いタスク、あるいは医療診断などの環境の探索が倫理的に問題となるタスクにおいて、適切な意思決定を実行可能な方策を学習するオフライン強化学習(Offline refinforcement learning)が注目されています。本実験では、集中治療室中の患者の容態と医師の治療介入を1日おきに記録したMIMIC-III データセットを用いて、医療診断に関する意思決定タスクにおける性能評価を行います。評価指標としてはACC(ACCuracy)、AUC(Area Under the receiving operator Characteristic curve)、APC(Average Precision Score)の3種類のメトリックが用いられています。下図の左側は「人工呼吸器を装着すべきか否か」に対する評価結果、右側はそれに加えて「抗生物質療法を行うべきか否か」という判断も行なった場合の評価結果が示されています。提案手法(AVRIL)は、いずれのタスクにおいても概ねベンチマーク手法を上回る性能を達成していることが分かります。ここで、A-RLは提案手法を用いて学習した報酬関数の事後分布からのサンプル平均に対するQ関数を学習したモデルですが、AVRILの学習過程で獲得したQ関数に基づく方策の方が推論性能が良い結果となることが分かります。
まとめ
本稿ではスケーラブルなベイジアン逆強化学習について解説を行いました。ベイジアン逆強化学習は報酬関数の事後分布を学習するため、報酬関数の推論結果の不確実性を見積もることが可能となります。しかし従来手法ではロボットの制御タスクなどの状態数が大きい問題設定においては計算量の観点で適用が難しいという課題がありました。本稿で紹介したアルゴリズムは従来のベイジアン逆強化学習のボトルネックであったMCMCの反復実行を回避することにより、状態数が大きい問題に対してもスケーラブルな手法であると言えます。この枠組みを用いれば、報酬関数の推定精度が低い状態を回避しつつ目的を達成するための方策を学習することができるため、現実世界の実用的なタスクにおいて安全性の高い模倣学習を実現できるかもしれません。皆さんも、ぜひ試してみてはいかがでしょうか?





この記事に関するカテゴリー
