Robust Overfitting 抑制のための平滑化手法
3つの要点
✔️ Robust Overfittingを抑えるために二つの平滑化手法を導入
✔️ 平滑化手法として、ロジットの平滑化、重みの平滑化を使用
✔️ 標準精度とロバスト精度を同時に向上させることに成功
Robust Overfitting may be mitigated by properly learned smoothening
written by Tianlong Chen, Zhenyu Zhang, Sijia Liu, Shiyu Chang, Zhangyang Wang
(Submitted on 29 Sept 2020 (modified: 25 Feb 2021))
Comments: Published as ICLR 2021 Poster
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
研究概要
深層学習モデルに対する攻撃手法として、Adversarial Attacksというものがあります。これは、Adversarial Exampleと呼ばれる、通常のデータに小さなノイズを乗せたデータをモデルに入力することで、誤った分類をさせる攻撃です。この攻撃を防ぐために有効であると考えられているのがAdversarial Trainingと呼ばれる学習手法で、これは、通常の学習データに加えてAdversarial Exampleも予め学習させておくことで、Adversarial Exampleを正しく分類できるようにしようというものです。
このAdversarial Trainingは一定の成果を上げていますが、overfittingが起こりやすいという欠点もあります(Robust Overfittingと呼びます)。そこで、著者らはこのRobust Overfittingを防ぐために、二つの平滑化手法を導入し、標準精度とロバスト精度の両方を同時に向上させることに成功しました。
関連研究
敵対的攻撃(Adversarial Attacks)とその対策
敵対的攻撃とは,モデルに入力するデータに何らかの加工を加えることで,モデルの出力を誤らせるような攻撃です.DNNはこの敵対的攻撃に脆弱であることが近年の研究で明らかになっており,問題視されています.
敵対的攻撃の対策として有名なのが,敵対的訓練(Adversarial Training)と呼ばれるものです.これは,モデルを学習させる際に通常のデータだけではなく,敵対的サンプルも一緒に学習させることで,モデルのロバスト性を向上させるものです.
詳しくは下の記事をご覧ください。
https://ai-scholar.tech/articles/adversarial-perturbation/Earlystopping
この記事では、本論文の関連研究である、Robust Overfittingを防ぐために早期終了が有効であることを示した論文を解説しています。
ロジット平滑化
ロジット平滑化とは、分類モデルにおいて出力する確率分布を平滑化することをいいます。本論文では、事前学習済みの同じモデルを教師とした知識蒸留を用いてロジット平滑化を行っています。これは、ロジット平滑化の方法として知られているラベル平滑化という手法が、知識蒸留の特別なパターンの一つであるという論文に影響を受けています。
重み平滑化
本論文では、Stochastic Weight Averaging (SWA) という手法を用いて重みを平滑化しています。この手法は、Fast Geometric Ensembling (FGE) と呼ばれる手法を近似した手法です。
FGEは、モデルの汎化性能を向上させる手法です。FGEでは、80%ほど学習させたモデルに対して独自の学習率スケジューリングを用いて残り20%を学習させます。この20%を学習させる過程において、独自のスケジューリングに基づいた学習率は、大きな値と小さな値の間を何度か振動します。この学習率が一番小さな値になった時のモデルの重みを保存しておき、20%の学習がすべて終わった時点で集まった重みたちを用いてアンサンブルを行います。この手法は、損失関数の局所解たちが、損失の値をあまり変化させることなく単純な曲線で接続することができるという発見に基づいて考案されました。
SWAは、FGEの欠点である、予測に複数のモデルが必要であるという欠点を克服した手法です。重みを
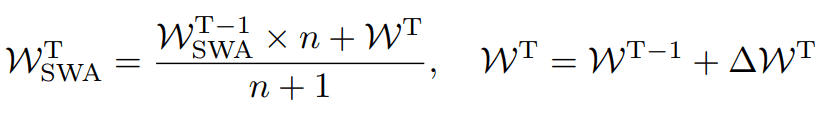
という規則で更新していくことで、FGEの性能に近似した結果を残すことができます。この方法ではアンサンブルをすることがないので、複数のモデルが不要となり、予測にかかる計算量を減少させることができます。
提案手法
Adversarial Trainingにおけるロジット平滑化
著者らは、Robust Overfittingは、Adversarial Trainingの初期段階に生成されたAdversarial Exampleに過剰適合することが一つの原因であると考えています。そこで著者らは、初期のAdversarial ExampleへのOverfittingを防ぐために、ロジット平滑化を用いました。具体的には、以下の最適化問題を解くことで学習を行います。
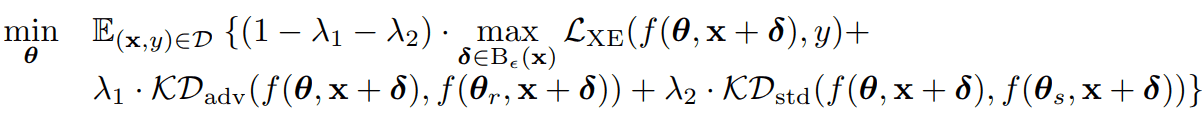
これは、普通のAdversarial Trainingの損失関数(第一項)、Adversarial Trainingしたモデルを教師とした知識蒸留の損失関数(第二項)、通常の学習を行ったモデルを教師とした知識蒸留の損失関数(第三項)の三つの損失関数を重みつき和で足し合わせたものを損失関数として定義しています。この損失関数を用いることで、普通のAdversarial Trainingを、残り二つの正則化項(知識蒸留の損失項)で正則化することができます。
Adversarial Trainingにおける重み平滑化
重み平滑化にはSWAを用います。SWAはAdversarial Trainingにもそのまま用いることができ、
この式を更新ルールに取り入れるだけで実装することができます。
実験と分析
標準精度とロバスト精度
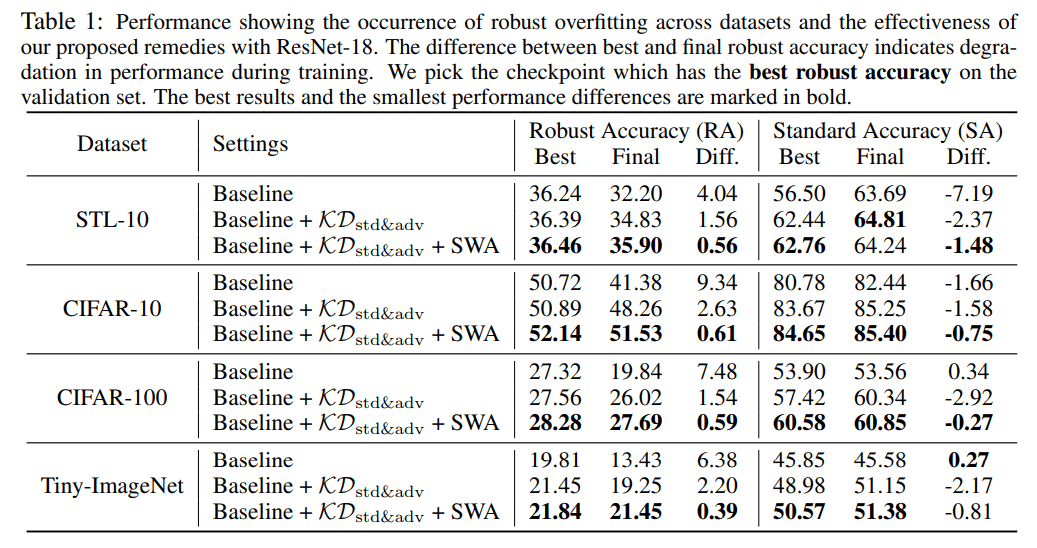
すべてのデータセットにおいて、提案手法を用いたモデルが最も高いロバスト精度を達成しました。また、標準精度もほとんどが最も高い精度を達成しました。
攻撃手法を変化させた際の精度
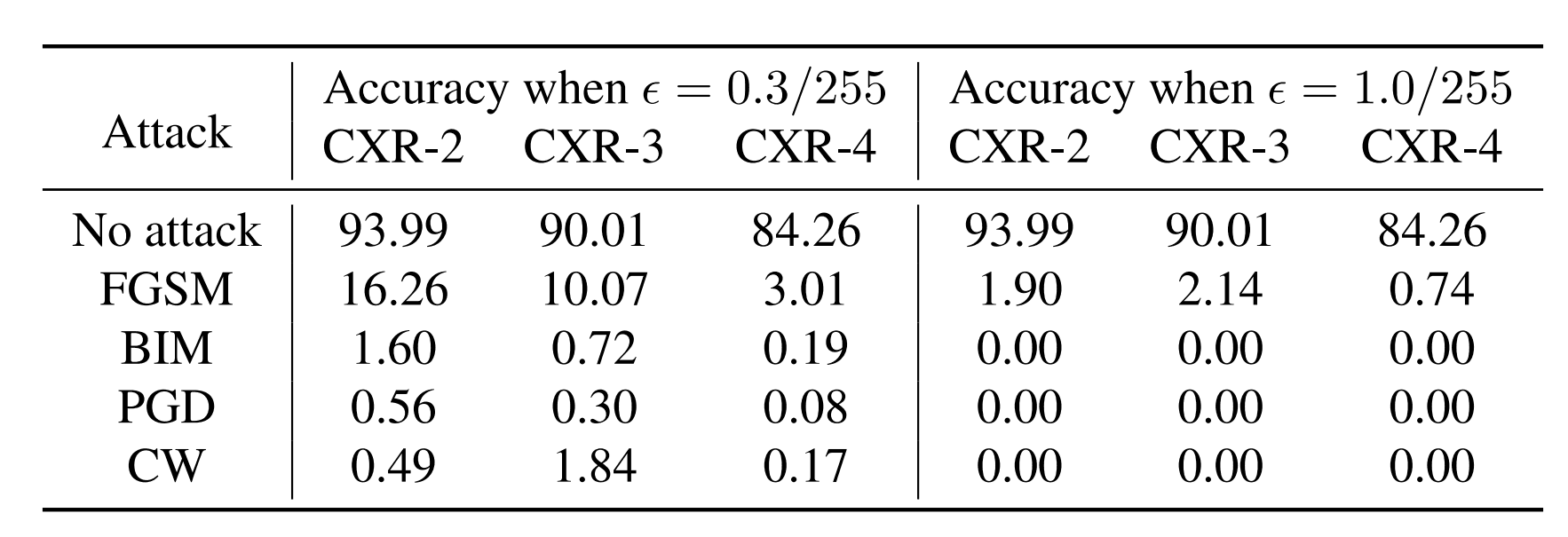
攻撃手法をPGD、FGSM、TRADESの3種類用意し、そのそれぞれに対する精度は以下のようになりました。
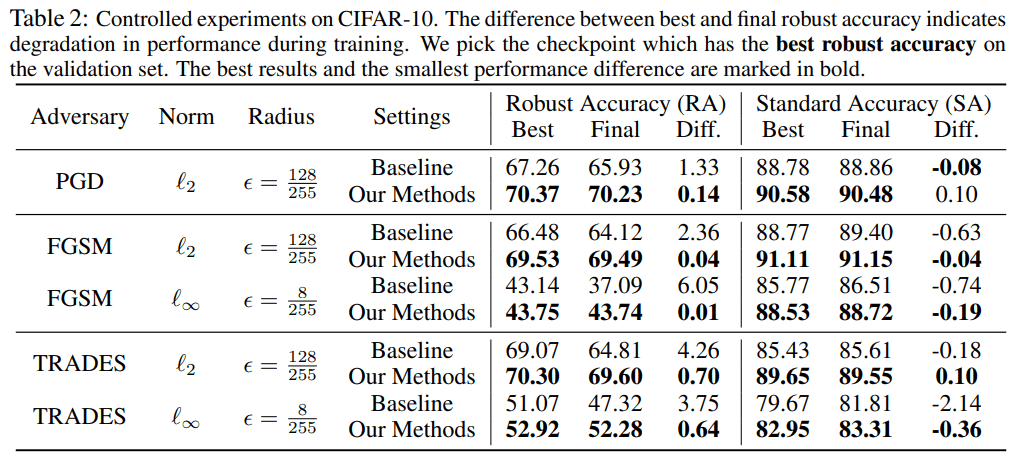
どの攻撃手法に対しても、提案手法がロバスト精度、標準精度と共にベースラインよりも高い値を達成しました。
異なるアーキテクチャにおける精度
VGG-16、WRN-34-4、WRN-34-10の3つのアーキテクチャに対して、CIFAR-10とCIFAR-100の二つのデータセットを用いた時の精度は以下のようになりました。
どのアーキテクチャにおいても、ロバスト精度、標準精度と共にベースラインよりも高い値を達成しています。
平滑化の分析
・ロジットの平滑化
ロジット平滑化を用いることでデータをどのように捉えられているかをt-SNEを用いて確認した様子が下の図になります。
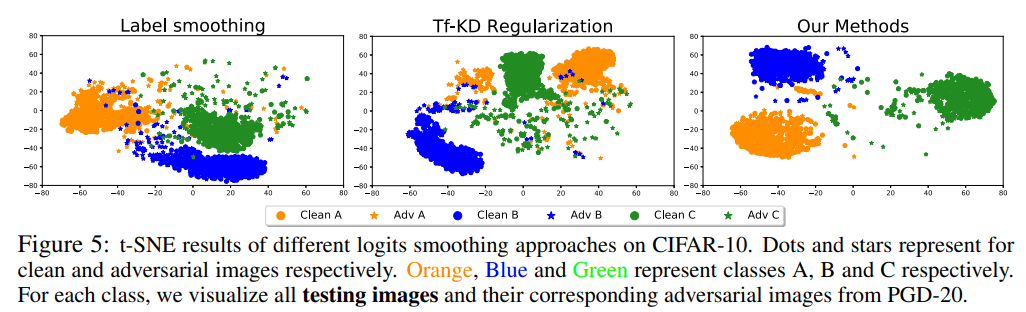
ほかのロジット平滑化手法である、ラベル平滑化やTf-KD(教師フリー知識蒸留)に比べて、Adversarial Exampleも含めて正しく分離できていることがわかります。
・損失関数の平滑化(重みの平滑化)
損失関数が、提案手法を用いることで平滑化できているかを確認したところ、以下のようになりました。
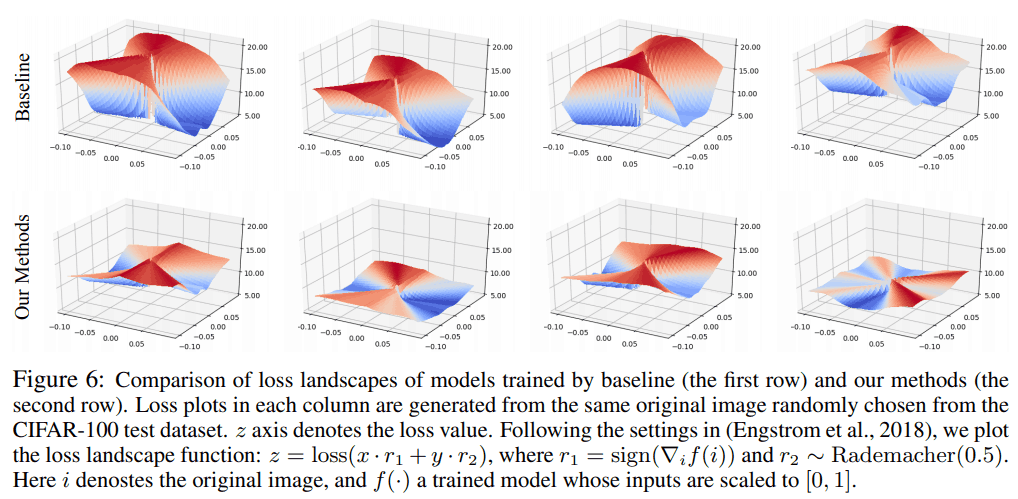
提案手法を用いた場合は、損失関数が平坦になっている様子が見て取れます。
まとめ
本論文では、Robust Overfittingを防ぐ手法として、ロジット平滑化と重み平滑化の二つの平滑化手法を提案しました。これらの手法を用いることで、従来よりも高いロバスト精度を達成することができることがわかりました。しかし、依然としてRobust Overfittingの原理的な部分は不明であるため、引き続き研究が必要です。





この記事に関するカテゴリー






