重要な情報を保持するAugmentation
3つの要点
✔️ 最先端Augmentationに存在した情報欠如を回避
✔️ シンプルで、汎用性の高い手法を提案
✔️ 計算コストを抑えつつも、多様なタスクで精度を達成
KeepAugment: A Simple Information-Preserving Data Augmentation Approach
written by Chengyue Gong, Dilin Wang, Meng Li, Vikas Chandra, Qiang Liu
(Submitted on 23 Nov 2020)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
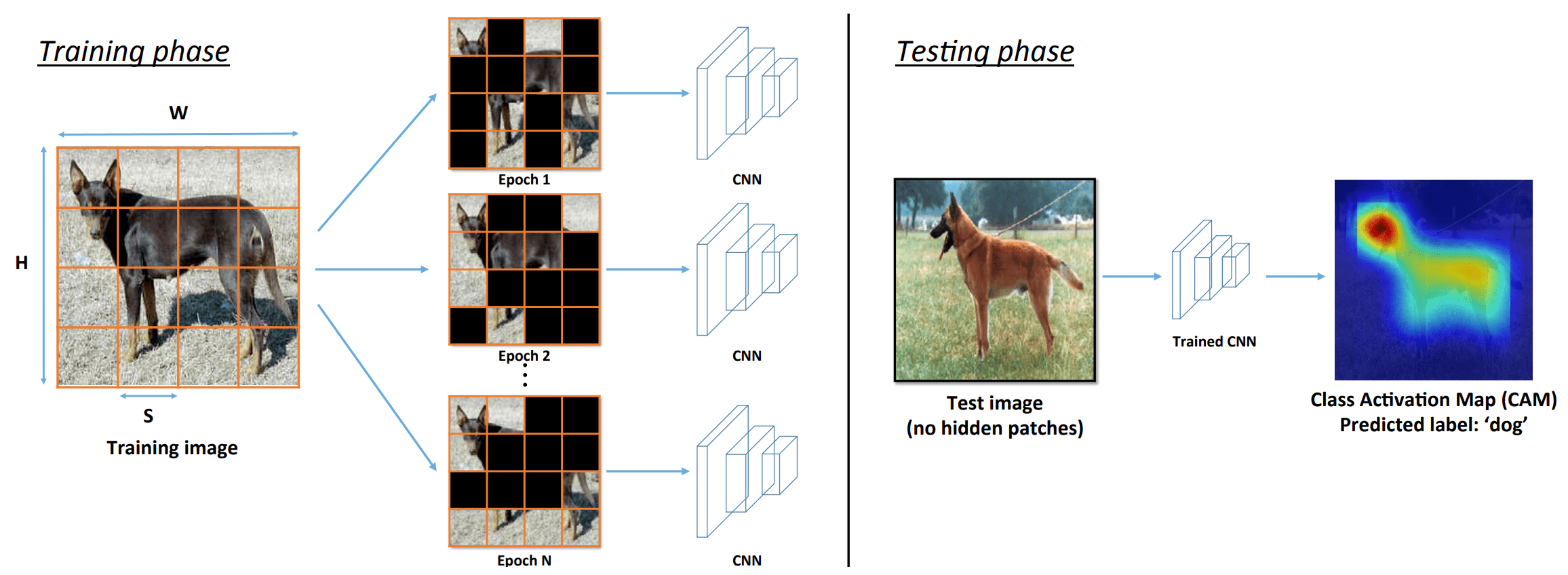
Data Augmentation(DA)は、現在の深層学習モデルを学習するために不可欠な技術です。DAは、overfittingの回避・モデルのロバスト性、画像に対するモデルの感度低減・学習データの増加・モデルの一般化能力の向上・サンプルの不均衡回避などを期待し、多くの人が活用しています。しかしDAは、学習プロセスにノイズや曖昧さがどうしても入ってきてしまいます。 下図を見てください。ランダムなCutout((a2)と(b2))やRandAugment((a3)と(b3))は、分類に必要な元画像の主要な特性情報を破壊し、間違ったまたは曖昧なラベルを持つ拡張画像を作成してしまっています。

今回ご紹介する論文は、そんなDAをシンプルかつ効果的な手法によって、DA画像の忠実度を高めるものになります。アイデアは、元画像上の重要な領域を検出するためにsaliency mapを使用し、次にDA時にこれらの情報領域を保持することである。この情報保存戦略により、より忠実な学習例を生成することができるというものです。 本質的な部分はAttentive CutMixと同じところにあると思います。
データ拡張(復習も含むので、飛ばしても大丈夫です)
ラベル不変なDAに焦点を当てています。xを入力画像とするとDAにより、xと同じラベルを持つ新しい画像$x'$=$A(x)$を生成します。ここで、Aはラベル不変の画像変換を表し、通常は確率関数です。最先端なコンピュータビジョン研究で広く使用される最先端DAを復習も兼ねて、軽く見ていきましょう。
入力画像の矩形領域をランダムにマスキングしたりすることで、学習データを作成しています。画像の中で小さな正方形領域がランダムに選択され、この領域のピクセル値が0に設定されますが、ラベルは変わりません。Cutoutによって、モデルが特定領域の視覚的特徴に頼りきることを防ぎ、画像のグローバルな情報をより有効に利用できることを目的としています。

Cutoutでは固定された正方形を使用し、置換値はすべて同じですが、Random Erasingはマスク領域の長さと幅、および領域内のピクセル値の置換値がすべてランダムです。

画像をS×Sのパッチでグリッド分割し、それぞれのグリッドが一定の確率(0.5)でマスクされるます。パッチの隠し方はエポックごとに変えることで、これによって物体に関連する複数の領域を学習することができます。
データセットの中からランダムに選ばれた2枚の画像を、タグの値も含めて一定の比率で融合させます。例えば、犬と車を0.5割程度で融合するなどを行います。
ここまでは2017年に提案された手法たちになります。
この方法は、Cutout、Random erasing、Mixupに、中間的ブレンドの変更を加えたもので、小さな領域を選択してマスキングを行いますが、他の画像がその領域に重なるようにマスキングを行います。

上記の方法は、マスク領域の選択がランダムであるため、重要な領域が完全にマスクされてしまうという問題がありましたが、これを改善したのがGridMaskです。決められたグリッドによって、 並べられた正方形の領域でマスキングを行います。

GridMaskを改良したものです。単純な話で、マスキングするのにより良い形状としてFenceMaskを提案しているといった形です。

異なるラベル不変変換(回転・色反転など)を選択して組み合わせるための最適な戦略を見つけ、適切な拡張パラメータを選択する方針を学習する手法です。DA手法で最適な組み合わせを見つける手法です。

高速化れたAutoAugmentになります。 また、同時に何度も学習するというGPU消費を回避する手法も提案され、100~1000倍の高速化が実現しています。
AutoAugmentの欠点である「学習の複雑さと計算コストの増大・モデルやデータセットのサイズに応じて正則化の強さを調整することができない」などを改善しています。RandAugmentationでは、DAによって発生するサンプル空間の増分を大幅に削減することができるため、モデルの学習プロセスと一括して行うことができます。

今回の手法はこれらの進化です。Gridmaskでも指摘されていた「重要な領域が完全にマスクされてしまう」という問題とAutoAugmentの進化により、どんどん自動的に最適なDAが行われることで把握しない情報の欠落があります。これらの問題に対して、改善をしていくという内容になります。下記の検討でも著者たちの考えが読み解けます。
DAとトレードオフ
上記の考えを検討するために、著者らはCIFAR-10データセットにおいて、CutoutとRandAugmentationの2つの手法を用いた実験を行い、DA手法の強さと精度の関係を分析しています。Cutoutの強さはCutoutの長さで制御され、RandAugmentationの強さはDistortionの大きさで制御されます。 実験結果を以下の図に示します。
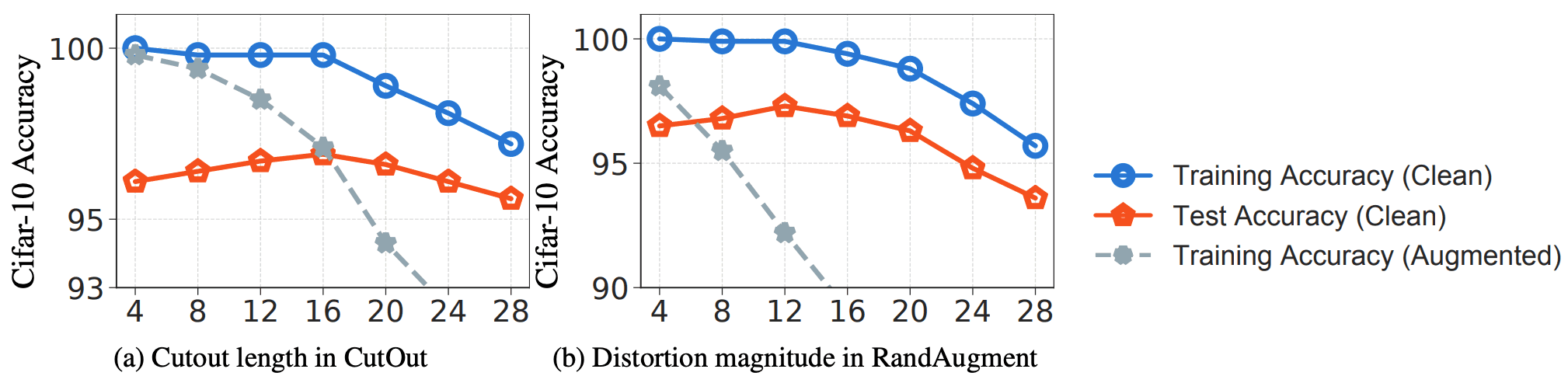
通常予想されるように、どちらの場合も変換の大きさに応じて汎化度(元データの学習精度とテスト精度のギャップ)が大きくなります。 しかし、変換の大きさが大きすぎると(Cutout ≥ 16、RandAugmentation ≥ 12の場合)、学習精度(青線)とテスト精度(赤線)が低下し始めます。これは、DAデータがもはや純粋な学習データを忠実に表現しておらず、DAデータ上の学習損失が純粋なデータ上の学習損失の良い代替を形成していないことを示しています。
提案手法
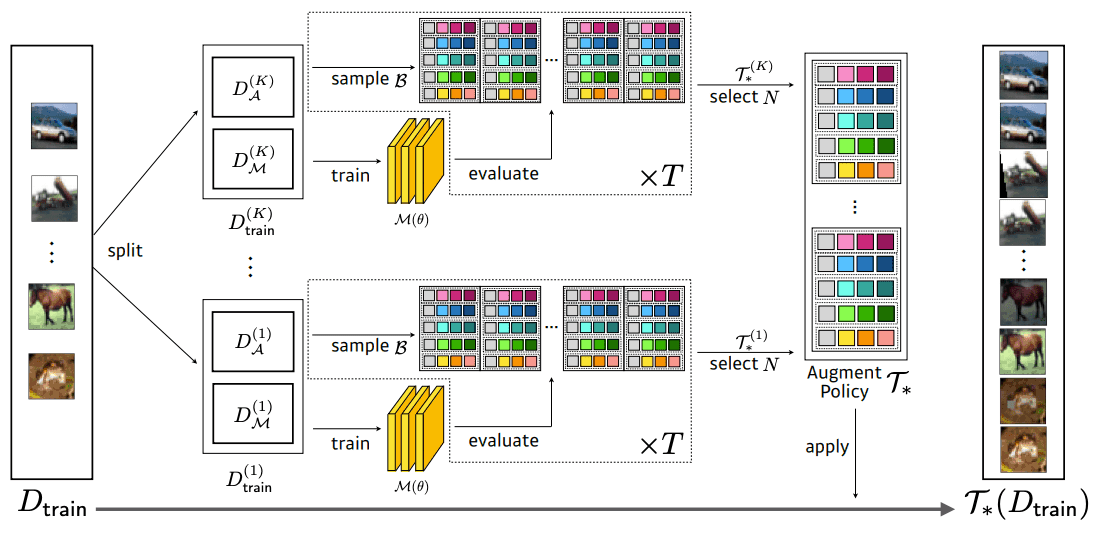
KeepAugmentのアイデアは、a4とb4のように、saliency mapを介して画像内の重要性を測定し、重要度のスコアが最も高い領域がDA後に保持されるようにすることです。Cutoutについては、重要な領域をカットしないようにすることで実現し(a5、b5)、RandAugmentationのような画像レベルの変換については、重要な領域を変換後の画像の上部に貼り付けることで実現しています(a6、b6)。

これらのことから、KeepAugmentは、saliency mapの計算と重要な矩形領域の保持の2つのステップに分けられます。 重要な矩形領域の保持はDA手法によって、"Selective-Cut"と"Selective-Paste"に分けられます。
Saliency map
KeepAugmentは一般的な勾配法によって、saliency mapを取得します。具体的には、画像xの画素(i,j)にラベルyが与えられたときのsaliency mapを$g_{ij}$(x, y)とすると、画像上のある領域Sについて、その重要度スコアは下記のように定義されます。
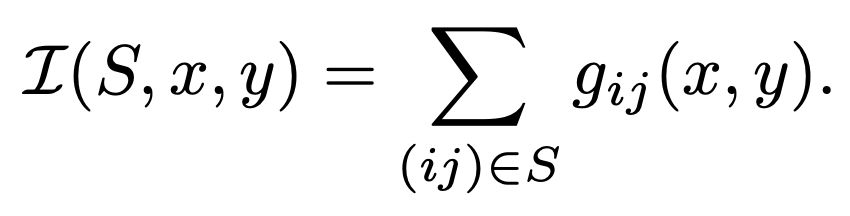
具体的には、画像xとそれに対応するラベルロジット値y(x)が与えられた場合、KeepAugmentは$g_{ij}$(x, y)を勾配の絶対値$|∇_(x)l_{y(x)}|$に設定します。 RBG画像では、チャンネルの最大値を用いて各画素(i,j)について1つの有意値を求めます。
Selective-Cut
KeepAugmentはDA手法では、削除される領域の重要度スコアが大きくならないようにすることで、DA忠実度を制御します。 これは実際には下図のアルゴリズム1(a)によって達成されます。アルゴリズム1では、カットされる領域Sを、その重要度スコアI(S,x,y)が所定の閾値τよりも小さくなるまでランダムにサンプリングしています。

ここで、$M(S)$ = $[M_(ij)(S)]_(ij)$はSのバイナリマスクで、$M_(ij)$= $I((i, j) ∈ S)$です。
Selective-Paste
画像レベルの変換は、画像全体をまとめて修正するため、重要度スコアの高いランダムな領域を貼り付けることで、変換の忠実度を確保します。アルゴリズム1(b)は、実際にどのようにしてこれを実現するかを示したもので、画像レベルの拡張データ$x_0$= A(x)をプロットし、閾値τに対してI(S, x, y)>τを満たす領域Sを一様にサンプリングし、元画像xの領域Sを$x_(0)$に貼り付けることで下記を実現しています。
同様に、$M_(ij)$= $I((i, j) ∈ S)$は、領域Sのバイナリマスクである。
KeepAugmentの効率的な実装
KeepAugmentでは学習ステップごとに、バックプロパゲーションによってsaliency mapを計算する必要があります。これを直接計算すると、計算コストが2倍になってしまいます。 ここで著者らはsaliency mapを計算するための効率的な手法を提案しています。
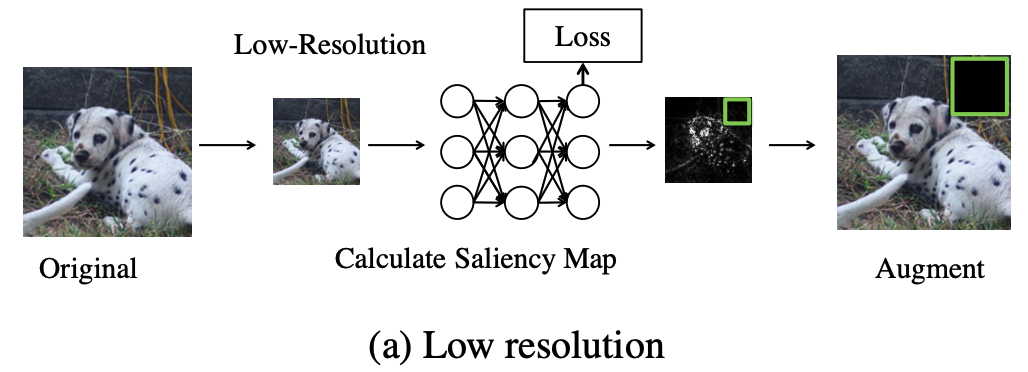
低解像度近似に基づいて、著者らは以下の操作を行なっています。
- 与えられた画像 x に対して、まず低解像度のコピーを生成し、そのsaliency mapを計算する。
- 低解像度 saliency mapを対応する元の解像度にマッピングする。
これにより、例えばImageNetでは、解像度を224から112に下げることで、計算コストの3倍削減を達成し、saliency mapの計算を大幅に高速化することができます。
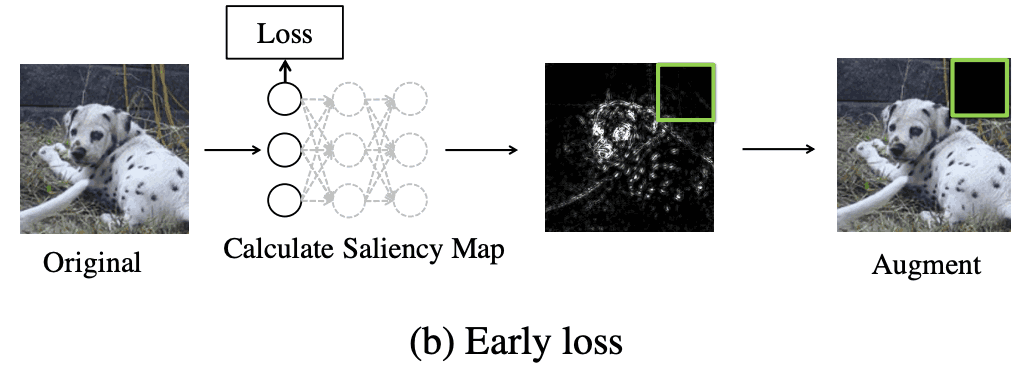
もう一つのアイデアは、初期損失近似に基づいたもので、ネットワークの初期層に損失を追加し、この損失を使ってsaliency mapを作成するというものです。実質的には、ネットワークの最初のブロックが評価された後に、追加の平均化プーリングレイヤーとリニアヘッドが追加されます。 学習の目的は、「Inception Network」と同じですね。ニューラルネットワークは、標準的な損失と補助的な損失で学習されます。このアイデアにより、saliency mapを計算する際に、3倍の計算コストの削減を実現しましています。
実際の実験を通して、どちらの近似戦略も性能の低下が起きませんでした。
実験
著者らは、KeepAugmentが、画像分類、半教師あり画像分類、マルチビュー・マルチカメラ・トラッキング、ターゲット検出など、様々な深層学習タスクにおいて精度向上を達成することを実験的に示していきます。いくつかピックアップして、見ていきます。
Dataset
使用したデータセットは以下の4つになります。
- CIFAR-10
- ImageNet
- COCO 2017
- Market1501
・CIFAR-10 Classification
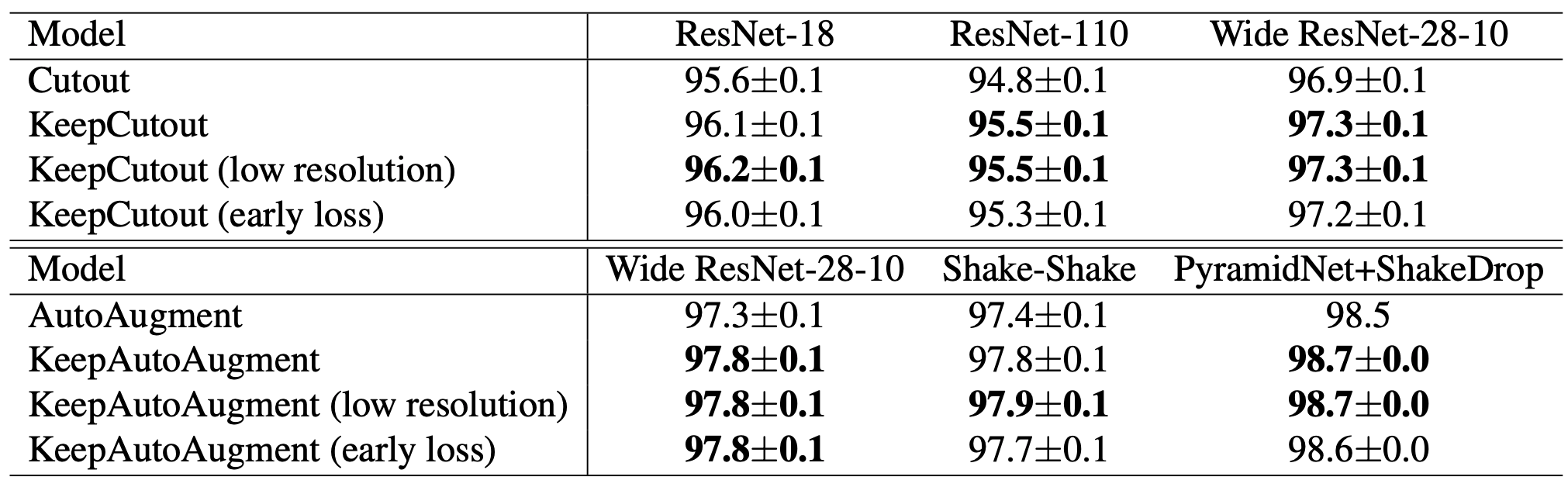
精度改善が、分類で行えることがわかります。多少なりとも画像へのノイズがあったのかもしれません。(複数回試行の平均値で算出されています)
・学習コスト
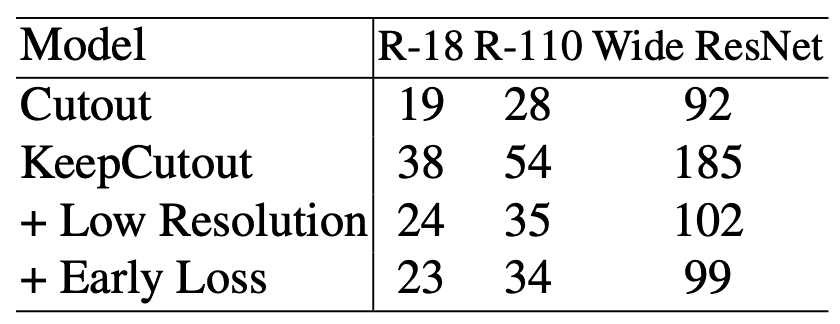
分類ではKeep手法が精度改善に寄与していましたが、学習コストを見ていくと、単純なKeepCutoutは通常のCutoutのほぼ2倍も学習コストがかかってしまっています。しかし、ここはすでに手法でもいった通りで、学習コスト削減用の2つのアプローチがしっかりとその効果を出しています。低解像度画像やearly lossを用いて、saliency mapを計算することで、Cutout に比べて学習コストがわずかな増加で精度を向上させていることがわかります。
・Semi-Supervised Learning
以下に結果を示します。4,000という表現は、4,000枚の画像にはラベルがついており、残りの4,6000枚にはラベルがない状態です。

一貫して精度はRandAugより、高いことがわかります。しかし、その改善度は若干でした。
・Multi-View Multi-Camera Tracking

ベースラインと他の手法との比較を出しています。提案手法が最高の性能を達成していることがわかります。
・Transfer Learning: Object Detection
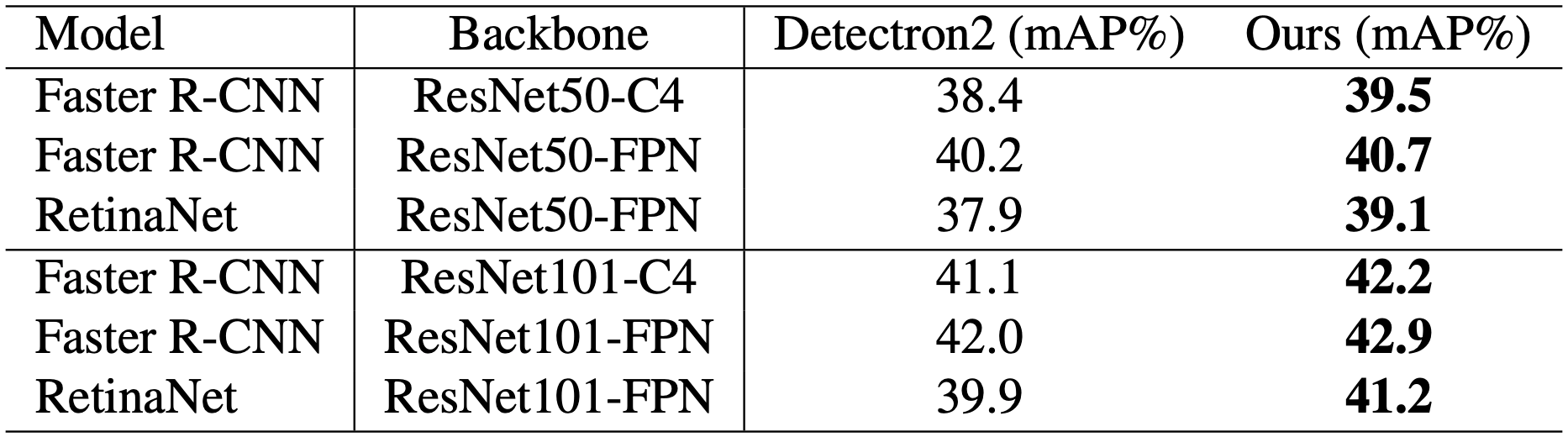
ベースラインよりも一貫して向上していることがわかります。バックボーンネットワークを提案手法で学習したものに置き換えるだけで、COCO 2017の物体検出タスクにおいて、追加のコストをかけずに性能が向上しています。特に、シングルステージ検出器のRetinaNetでは、ResNet-50とResNet-101で、それぞれ37.9 mAPを39.1に、39.9 mAPを41.2に向上させています。
しかし、ResNet50 + CutMixは、C4、FPN、RetinaNetの設定で、それぞれ23.7、27.1、25.4 (mAP)となり、極端に悪いものになりました。CutMixは非常に有効なDA手法ですが、タスクやモデルによっては強力な精度低下を引き起こす可能性があるかもしれません。
発展
DAの忠実性と多様性の影響を経験的に研究し、優れたDA戦略はこれらの2つの側面を共同で最適化する必要があることを明らかにしたと言えます。最近では、他の多くの研究でも、忠実性と多様性のバランスの重要性が示されています。例えば、"MaxUp: A Simple Way to Improve Generalization of Neural Network Training"や"Adversarial AutoAugment"では、最悪な最適化を行なったり、最も困難な補強方針を選択することが有効であることを示しており、これは多様性の重要性を示す結果となっていました。
また"Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification"では、CutMixのノイズを減らすために、最も情報量の多い領域を抽出することを検討しています。アイデアは本手法と同じです。しかし彼らの提案手法であるAttentive CutMixでは、教師となる事前学習済みの分類モデルを追加する必要があるのが欠点です。さらに、Attentive CutMixではできない、より多くのDA手法やタスクに適用することができるのも本手法の優位的なポイントです。
まとめ
既存のDA手法は、ノイズや曖昧なサンプルを導入する可能性があるため、全体的なパフォーマンスを向上させる能力が制限されることが示唆されています。 そこで著者らは、saliency mapを用いて各領域の重要性を測定し、重要な領域をカットする領域レベルのDA手法(cutout)を避けること、あるいは、重要な領域を元のデータから貼り付けて画像レベルのDAを行うこと(RandAugment)を提案しました。
かなり直感的で、今後の発展も期待できます。例えば、ラベル不変なDAに焦点を当てていますが、ラベル可変にも応用する研究ができそうです。それだけではなく、重要度の測定にもいくつか工夫が考えられます。今までのDAをして、精度改善は昔の話で、以下にして正しいDAを行い、精度をあげるかというフェーズにきています。





この記事に関するカテゴリー





