
シンプルだけど最強!?モデルの汎化性と不確実性両方を改善するデータ拡張手法AugMix登場!
3つの要点
✔️ モデルの頑健性と不確実性データに対する評価を向上させるデータ拡張手法「AugMix」を提案
✔️ AugMIXでは、データ拡張処理を施した複数の変換画像を凸結合することで多様性を維持しつつ元画像と乖離しすぎないデータを生成し、学習に使用することでモデルの頑健性を向上
✔️ CIFAR-10とCIFAR-100、ImageNetに対して、破損画像に対する判定誤差を、それぞれ28.4%から12.4%、54.3%から37.8%、57.2%から37.4%に減少させることを確認
AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty
written by Dan Hendrycks, Norman Mu, Ekin D. Cubuk, Barret Zoph, Justin Gilmer, Balaji Lakshminarayanan
(Submitted on 5 Dec 2019 (v1), last revised 17 Feb 2020 (this version, v2))
Comments: Published on arxiv.
Subjects: Machine Learning (stat.ML); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
画像認識において深層学習を用いた手法が高い性能を発揮して以降、画像分類においても畳み込みニューラルネットワークを用いたモデルが多く提案されています。
こうしたモデルの多くは、学習データの分布とテストデータの分布が同一であれば高い精度を達成することができますが、実利用において学習データとテストデータの分布は必ずしも一致するわけでなく、一致しない場合モデルの推定精度が大きく低下することがあります。
実際、先行研究において最新のモデルの分類誤差が通常のImageNetデータセットに対して22%であったのに対し、ImageNetデータセットの画像に様々な処理を加え、破損させた画像からなるImageNet-Cデータセット(図1参照)で64%に上昇することが報告されています。
また、学習データに破損画像を入れることによって、テスト時に学習データに含まれる種類の破損画像を正しく分類できるようになりますが、分類できるようになるのは学習データに含まれている破損のみで未知の破損に対して正しく分類することはできません。
これらの結果は、モデルが学習データと異なる分布の画像に汎化できないことを示唆しており、このような場合に対して、モデルの頑健性を向上させる技術は現状ではほとんど存在しません。
そこで、本論文では、モデルの頑健性と不確実性データに対する評価を向上させる手法として「AugMix」が提案されています。
AugMixは、データ拡張処理を施した複数の変換画像を凸結合することで多様性を維持しつつ元画像と乖離しすぎないデータを生成するデータ拡張手法であり、実験で、モデルの頑健性と不確実性データに対する評価を大幅に改善し、いくつかのケースでは従来の手法と最良の性能との差を半分以下に縮めることを確認しました。
図1:ImageNet-Cデータセットの画像例
次章以降では、事前知識としてデータ拡張について簡単に説明した後に提案手法と実験内容、結果について解説していきます。
データ拡張とは
データ拡張とは、図2に示すように画像に何らかの変換をかけて擬似的にデータ数を増加させる手法です。
変換の種類は図2に示した以外にも無数にあり、画像の一部を塗りつぶすErasingと呼ばれる手法や、ガウシアンフィルタを適用するGaussianBlurといった手法があります。
このように様々ある拡張手法を用いて学習したモデルは通常、元データのみを学習したモデルに比べて汎化性の高いモデルとなることが知られていますが、時にはパフォーマンスを低下させたり予期せぬバイアスを誘発したりすることがあります。
そのため、モデルの汎化率を向上させるには,ドメインに基づいて効果的なデータ拡張手法を手動で見つける必要があります。
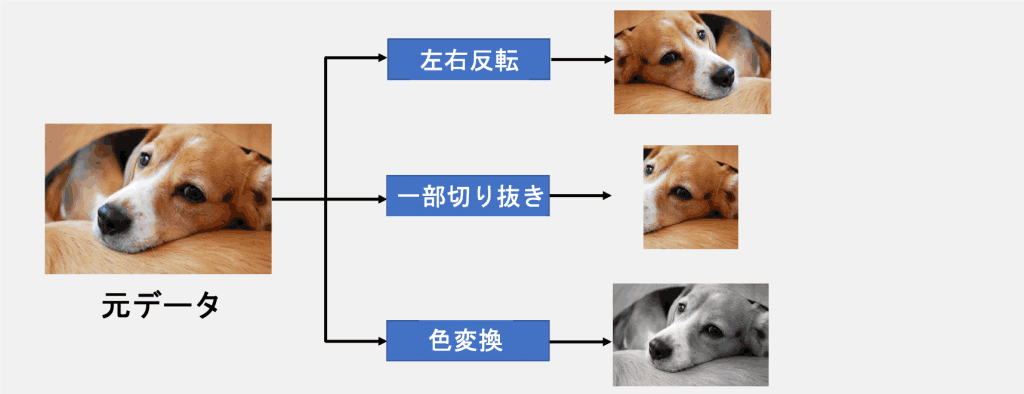
図2:データ拡張概要
提案手法
ここから、この論文の提案手法であるAugMixについて解説していきます。
AugMixは、単純なデータ拡張操作を利用することでモデルの頑健性と不確実性データに対する評価を向上させるデータ拡張技術です。
先行研究から、深層モデルは学習データに含まれる種類の破損画像に対しては、テスト時に分類可能であることがわかっています。
そのため、あらゆるデータ拡張操作を混合することによって、頑健性を高めるために重要な多様な変換画像を生成し、それを学習に用います。
これまでの手法では、複数のデータ拡張操作を直接連鎖的に構成することで多様性を高めようとしてきましたが、そうすると図3に描かれているように画像がすぐに劣化し、変換画像が元データから離れすぎることで、お互いの特徴が矛盾し学習不足に陥ってしまうことがあります。
そこで、提案手法では複数のデータ拡張操作を凸状に組み合わせて合成することで、画像の劣化を抑え、画像の多様性が維持された画像を生成しています。

図3:複数のデータ拡張の組み合わせによる失敗例
AugMix
AugMixの操作に関して概要図を図4に示します。
AugMixにおいて複数のデータ拡張操作を組み合わせるにあたり、各データ拡張操作にはAutoAugmentからの操作を使用しています。
この時、提案手法が破損画像に対して汎化性があるかを確認するためImageNet-Cに含まれる破損と重複する操作を除外しています。
具体的には、コントラスト、カラー、明るさ、シャープネス、カットアウト、画像ノイズ、画像ぼかしの操作を削除し、提案手法のデータ拡張操作とImageNet-Cの破損が切り離されるようにしています。
上記の条件を満たした上で、元画像に対してはランダムに選択されたデータ拡張操作が適用され組み合わされます。
こうして組み合わされたものをAugment Chainと呼び、Augment Chainは1~3つの拡張操作の組み合わせによって構成されます。
提案手法ではこのAugment Chainを$k$個ランダムにサンプリングし、(デフォルトは$k=3$)サンプリングされたAugment Chainを要素単位の凸結合を用いて合成します。
最後に、合成された画像と元画像を「スキップ接続」を用いて結合することで画像の多様性が維持された画像を生成しています。
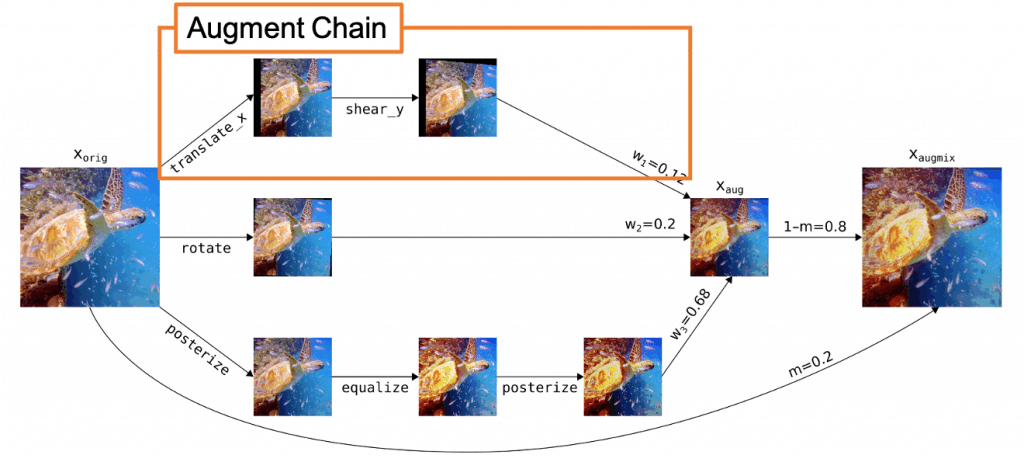 図4:AugMixの操作概要
図4:AugMixの操作概要
実験設定
CIFAR-10、CIFAR100、ImageNetのそれぞれに対して破損を加えたデータセットである、CIFAR-10-C、CIFAR100-C、ImageNet-Cを使用して、提案手法がモデルの頑健性に与える影響について他の手法と比較実験を行いました。
この時、学習段階で-Cデータセットに含まれる破損と同じものを学習しないように設定されています。
モデルのアーキテクチャとしては、All Convolutional Network、DenseNet-BC (k= 12,d= 100) 、40-2 Wide ResNet 、ResNeXt-29 (32×4)を使用して実験を行いました。
結果と考察
CIFAR10-C
ResNeXt-29をネットワークアーキテクチャに用いて、様々な手法を用いたCIFAR-10-Cの分類誤差をまとめたものを図5に示します。
図5より、提案手法であるAugMixは、ベースライン(Standard)と比較して16.6%低い判定誤差を達成しました。
また、それ以外の先行手法と比べても、誤差を低減させクリーンな誤差に近づけており、提案手法の有効性を確認することができました。

図5:各手法によるCIFAR10-Cの分類誤差
CIFAR10-C&CIFAR100-C
複数のアーキテクチャにおいて、CIFAR-10-CおよびCIFAR-100-Cの破損データセットに対する分類誤差をまとめたものを図6に示します。
提案手法であるAugMixの分類誤差は、従来の性能を超えるものであることを確認しました。
特に、CIFAR10-Cにおいてベースライン(Standard)と比較して分類誤差を半分以下に低減することに成功し、CIFAR100-Cにおいても平均して18.3%の分類誤差低減に成功し、ここでも提案手法の有効性を確認しました。
 図6:CIFAR10-CとCIFAR100-C画像分類タスクに対する分類誤差
図6:CIFAR10-CとCIFAR100-C画像分類タスクに対する分類誤差
ImageNet-C
ImageNet-Cにおける様々な手法のClean Error、Corruption Error(CE)、およびmCE(破損画像に対する分類誤差の平均を取ったもの)をまとめたものを図7に示します。
提案手法であるAugMixは68.4%のmCEを達成し、ベースライン(Standard)の80.6%のmCEから低下しており、ここでも提案手法の有効性を確認できます。

図7:ImageNet-Cにおける様々な手法のClean Error、Corruption Error(CE)、およびmCE
まとめ
この論文では、モデルが学習データと異なる分布の画像に汎化できないという問題に対して、モデルの頑健性を向上させるデータ拡張手法「AugMix」が提案されています。
提案手法であるAugMixは、データ拡張処理を施した複数の変換画像を凸結合することで多様性を維持しつつ元画像と乖離しすぎないデータを生成し、学習に使用することでモデルの頑健性を向上させることに成功しました。
提案手法の有効性を確認するため、実験ではCIFAR-10、CIFAR100、ImageNetのそれぞれに対して破損を加えたデータセットである、CIFAR-10-C、CIFAR100-C、ImageNet-Cに対する分類誤差を確認しました。
その結果、3つのデータセット全てにおいて提案手法はベースラインやその他の手法と比べ分類誤差を低減することを確認しました。



この記事に関するカテゴリー






