
Teach Augment:教師モデル活用によるデータ拡張の最適化
3つの要点
✔️ 教師モデルを敵対的データ拡張に導入し、慎重なパラメータ調整がいらないデータ拡張戦略Teach Augmentを提案
✔️ 色に関するデータ拡張を行うモデルと、幾何的な変換に関するデータ拡張を行うモデルを組み合わせたニューラルネットを用いてデータ拡張を行う手法について提案
✔️ 画像分類、セマンティックセグメンテーションの各タスクにおいて、各タスクのハイパーパラメータを調整することなく、最先端手法を含む既存のデータ拡張探索フレームワークを上回る性能を示すことを確認
TeachAugment: Data Augmentation Optimization Using Teacher Knowledge
written by Teppei Suzuki
(Submitted on 25 Feb 2022 (v1), last revised 28 Mar 2022 (this version, v3))
Comments: CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
近年、データ拡張はモデルの汎化を実現するための重要な手法として注目を集めています。
そうしたデータ拡張の先行研究として、モデル汎化のための効率的な拡張手法を自動的に探索するAutoAugmentが提案されています。
この手法は、ターゲットモデルのタスク損失を最大化する拡張手法を探索する敵対的戦略に基づいており、モデルの汎化を改善することが知られています。
しかし、図1左側に示すように、損失の最大化は画像に内在する意味を崩壊させることによって達成されるため、敵対的データ拡張は制約がないと不安定になることがあります。
こうしたことが起こることを避けるため、従来手法では経験則に基づいてオーグメンテーションを正則化したり、探索空間における関数の大きさパラメータの探索範囲を制限したりしているが、調整する必要があるパラメータが多いことが問題となっています。
この問題を解決するために、この論文では教師知識を用いたオンラインデータ拡張最適化手法TeachAugmentが提案されています。
TeachAugmentも敵対的データ拡張に基づいていますが、図1右側に示すように変換後の画像が教師モデルに対して認識可能な範囲で拡張手法を探索することができます。また、従来の敵対的データ拡張とは異なり、事前分布やハイパーパラメータを必要としないため、画像本来の意味を崩壊させるような過剰な拡張手法を回避することができます。
その結果、Teach Augmentは変換された画像が認識可能であることを保証するためのパラメータチューニングを必要としません。
さらに、この論文では幾何的な変換に関するデータ拡張と色に関するデータ拡張の2つの機能を持つニューラルネットワークを用いたデータ拡張手法が提案されています。 本手法は、2つの変換を行うだけで、AutoAugmentの探索空間に含まれるほとんどの関数とその合成関数を表現することができます。
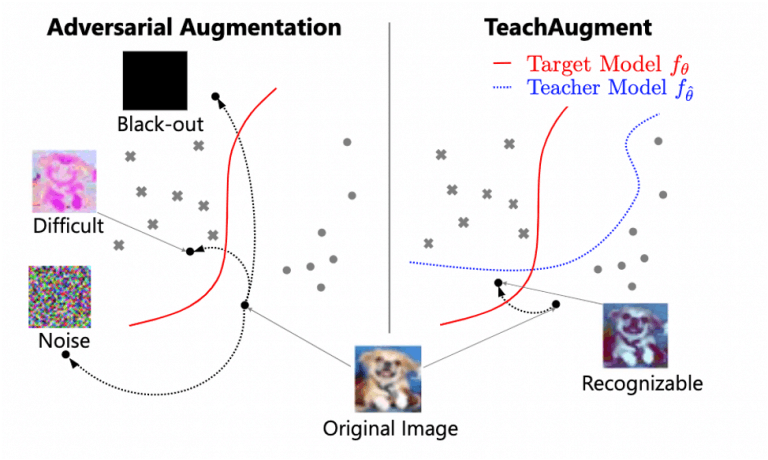
図1:従来手法と提案手法の違い
この論文の貢献は以下の通りです。
- TeachAugmentと呼ばれる教師知識を用いた敵対的戦略に基づくオンラインデータ拡張最適化フレームワークを提案する。
TeachAugmentは、教師モデルを利用して画像の固有な意味を崩さないようにすることで、パラメータを慎重に調整することなく、敵対的データ拡張戦略をより有益なものにすることが可能である。 - また、ニューラルネットワークを用いたデータ拡張手法を提案する。
この方法は、探索空間の設計を簡略化し、TeachAugmentの勾配法によってパラメータを更新することができる。 - TeachAugmentは、オンラインデータ拡張や最新の拡張戦略などの従来手法を、分類、半統合、教師なし表現学習課題において、課題ごとにハイパーパラメータや探索空間の大きさを調整せずに高い性能を発揮することを示す。
次章以降では、事前知識としてデータ拡張について簡単に説明した後に提案手法と実験内容、結果について解説していきます。
データ拡張とは
データ拡張とは、図2に示すように画像に何らかの変換をかけて擬似的にデータ数を増加させる手法です。
変換の種類は図2に示した以外にも無数にあり、画像の一部を塗りつぶすErasingと呼ばれる手法や、ガウシアンフィルタを適用するGaussianBlurといった手法があります。
このように様々ある拡張手法を用いて学習したモデルは通常、元データのみを学習したモデルに比べて汎化性の高いモデルとなることが知られていますが、時にはパフォーマンスを低下させたり予期せぬバイアスを誘発したりすることがあります。
そのため、モデルの汎化率を向上させるには,ドメインに基づいて効果的なデータ拡張手法を手動で見つける必要があります。
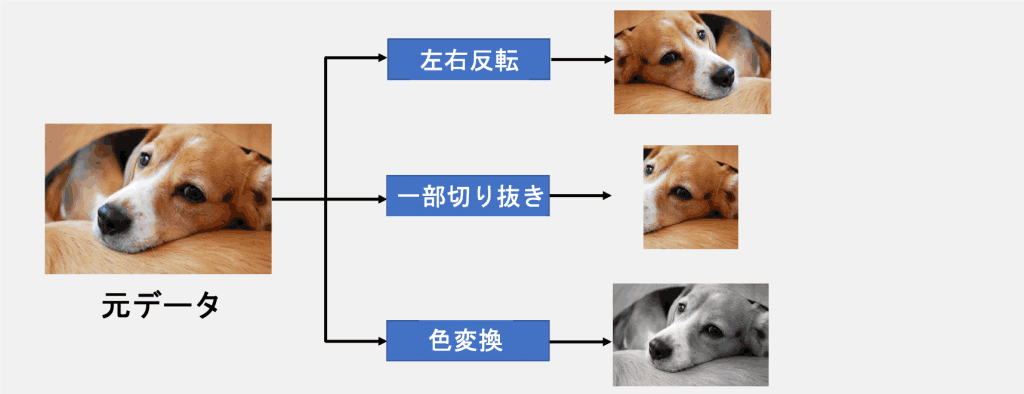
図2:データ拡張概要
提案手法
この論文では、Teach Augmentと呼ばれるデータ拡張戦略とニューラルネットを使用したデータ拡張手法という2つについて提案しています。
Teach Augment
1つ目の提案であるTeach Augmentの説明に入る前に、データ拡張を用いた一般的な学習と敵対的データ拡張について簡単に説明します。
それぞれの式で出てくる文字は以下のように定義します。
- $x \sim \mathcal{X}$:$\mathcal{X}$からサンプルした画像
- $a_\phi$:$\phi$をパラメータとするデータ拡張関数
- $\phi$:ニューラルネットのパラメータ
- $f_\theta$:ターゲットモデル
- $f_{\hat{\theta}}$:教師モデル
データ拡張を用いた一般的な学習
ミニバッチサンプル$x$をデータ拡張関数$a_\phi$に入力することで変換し、ターゲットネットワーク$f_{\theta}$に入力します。($f_\theta\left(a_\phi(x)\right)$)
その後、以下の式を用いてSGDにより損失$L$を最小化するようにターゲットモデルのパラメータを更新します。
$\min _\theta \mathbb{E}_{x \sim \mathcal{X}} L\left(f_\theta\left(a_\phi(x)\right)\right.$
敵対的データ拡張
敵対的データ拡張では、モデルの汎化性を向上させるため、以下の式のようにターゲットモデルの損失を最大にするパラメータ$\phi$を探索します。
$\max _\phi \min _\theta \mathbb{E}_{x \sim \mathcal{X}} L\left(f_\theta\left(a_\phi(x)\right)\right.$
Teach Augment
冒頭にも述べた通り、敵対的データ拡張では$\phi$に関する最大化によって画像そのものの特徴(意味)がなくなることもあり、そうした問題に対処するため従来は正則化や探索空間を制限するなどの制約を設けていました。
しかしながら、この論文では教師モデルを使用することでそうした制約を設ける必要がなくなるデータ拡張戦略が提案されています。
以下の式に従ったデータ拡張戦略をTeachAugmentと呼びます。
$\max _\phi \min _\theta \mathbb{E}_{x \sim \mathcal{X}}\left[L\left(f_\theta\left(a_\phi(x)\right)\right)-L\left(f_{\hat{\theta}}\left(a_\phi(x)\right)\right)\right]$
変換後の画像が元画像から離れすぎると、2項目の$L\left(f_{\hat{\theta}}\left(a_\phi(x)\right)\right)$が大きくなり、全体の最大化問題に対してマイナスに働くことでそうした変換手法が選ばれることを防いでいる。
この式は、SGD(確率的勾配降下法)において図3のように$a_\phi$と$f_\theta$を交互に更新することで解けます。
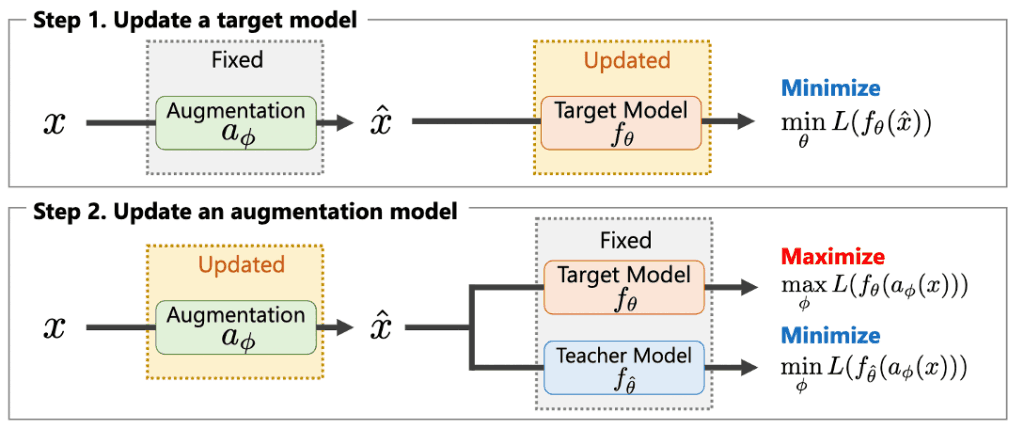
図3:パラメータの更新アルゴリズム
また、Teach Augmentの式の第1項の勾配は、ターゲットモデルの精度が非常に高い場合、$\phi$に関する最大化問題で飽和することが多くあります。
これを防ぐため、通常の損失関数をクロスエントロピーで$\sum_{k=1}^K-y_k \log f_\theta\left(a_\phi(x)\right)_k$とするが、今回は$\sum_{k=1}^K y_k \log \left(1-f_\theta\left(a_\phi(x)\right)_k\right)$を使用しています(非飽和損失)。
ニューラルネットを使用したデータ拡張
2つ目の提案であるニューラルネットワークを用いたデータ拡張手法について説明します。
ここでは、色に関するデータ拡張を行うモデル$c_{\phi_c}$と、幾何的な変換に関するデータ拡張を行うモデル$g_{\phi_g}$を組み合わせたニューラルネット$a_\phi$を用いてデータ拡張を行います。
それぞれの式で出てくる文字は以下のように定義します。
- $c_{\phi_c}$:色に関するデータ拡張を行うモデル
- $g_{\phi_g}$:幾何的な変換に関するデータ拡張を行うモデル
- $a_\phi=g_{\phi_a} \circ c_{\phi_c}$:$c_{\phi_c}$と$g_{\phi_g}$を組み合わせたニューラルネット($c_{\phi_c}$と$g_{\phi_g}$の合成関数)
- $\phi=\{\phi_c, \phi_g\}$:ニューラルネットパラメータ($\phi_c$と$\phi_g$の集合)
- $x \in \mathbb{R}^{M \times 3}$:変換前画像($M$はピクセル数、3はRGBに対応)
- $\tilde{x}_i \in [0,1]$:色拡張した画像
- $\alpha_i, \beta_i \in \mathbb{R}^3$:スケールとシフトのパラメータ
- $z~\mathcal{N(0,I_N)}$:平均0、分散$I_N$のN次元ガウス分布
- $c$:画像分類でone-hotの正解ラベル、それ以外のタスクでは省略
- $t(\dot)$:三角波($t(x)=\arccos (\cos (x \pi)) / \pi$)
- $A \in \mathbb{R}^{2 \times 3}$:残余パラメータ
- $I \in \mathbb{R}^{2 \times 3}$:単位行列
色に関するデータ拡張は以下の式で定義されます。
$\tilde{x}_i=t\left(\alpha_i \odot x_i+\beta_i\right),\left(\alpha_i, \beta_i\right)=c_{\phi_c}\left(x_i, z, c\right)$
色に関するデータ拡張を行うモデル$c_{\phi_c}$は普遍近似定理により、モデルサイズが十分に大きい場合、原理的に入力画像を任意の画像に変換することができます。
次に、幾何的な変換に関するデータ拡張は以下の式で定義されます。
$\hat{x}=\operatorname{Affine}(\tilde{x}, A+I), A=g_{\phi_g}(z, c)$
ここで、$\operatorname{Affine}(\tilde{x}, A+I)$は$\tilde{x}$をパラメータ$A+I$でアフィン変換(平行移動、拡大縮小、回転)することを意味します。
実験設定
既存のデータ拡張手法探索との比較のために、画像分類タスクで本手法を評価しました。
CIFAR-10とCIFAR-100に対して、WideResNet-40-2(WRN-40-2),WideResNet-28-10(WRN-28-10),Shake-Shake (26 2×96d),PyramidNet with ShakeDrop regularizationを、そして ImageNetに対してResNet-50を訓練し、その結果を用いて本手法の評価を行いました。
また、上記の画像分類タスクに加えて,セマンティックセグメンテーションを用いて本手法を評価しました。
セマンティックセグメンテーションでは,FCN-32s,PSPNet,Deeplabv3をCityscapes上で学習させました。
結果と考察
目的関数の評価
提案する目的関数(TeachAugmentで紹介した式)の有効性を評価する。
ベースラインとして、我々のフレームワークの目的関数を、敵対的オートオーグメント(Adv. AA)とポイントオーグメント(PA)の損失に置き換えて比較を行いました。
公平に比較するために、目的関数以外は全て同じ条件で実験を行いました。
それぞれの条件での誤り率(%)の結果を図4に示します。
Adv.AAの誤り率がベースラインより低下していることが確認できます。
これはデータ拡張を行うモデルが認識できない画像を生成し、ターゲットモデルを混乱させるためだと推察されます。
また、Adv.AAの場合 AAでは収束を保証するために探索空間の大きさを慎重に調整する必要があるが、提案手法ではそうした制限はありません。
本手法は、PointAugmentよりも優れたエラーレートを達成することができることが確認でき、3つの中で最も良い性能を発揮することを確認できました。
PointAugmentでは,拡張されたデータに対する損失の上限を動的パラメータで制御していますが,提案手法ではそうした制限はありません。
その結果、本手法はPointAugmentよりも多様な変換を実現し、誤差を改善することができたと考えられます。

図4:目的関数の評価結果
画像分類
本手法の有効性を確認するため、先行手法であるAutoAugment (AA),PBA,Fast AA, FasterAA, DADA, RandAugment (RandAug),OnlineAugment (OnlineAug), Adv. AAと比較検討しました。
それぞれの条件での誤り率(%)の結果を図5に示します。
本手法は、ミニバッチごとに複数の拡張サンプルを用いるAdv.AAを除き、他の手法と同等の誤り率を達成したことを確認しました。
特に、ImageNetでは、複数の拡張手法を用いない手法の中で最も低い誤り率割合を達成している。
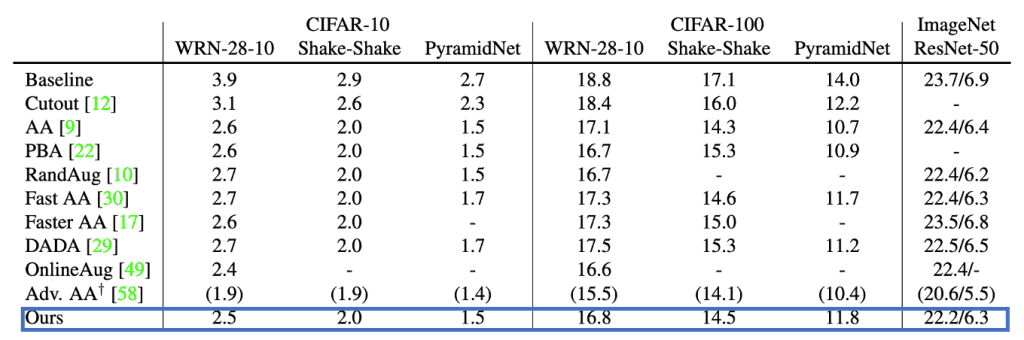 図5:画像分類タスクに対する誤り率
図5:画像分類タスクに対する誤り率
セマンティックセグメンテーション
また、Cityscapesを用いて本手法の評価を行いました。
ResNet-101バックボーン、FCN-32s,PSPNet,Deeplabv3という広く用いられているモデルを使用しました。
また、ベースライン手法として、RandAugmentとTrivialAugmentを採用した。
これらの手法も提案手法同様、ハイパーパラメータがほとんどないため慎重なパラメータチューニングを必要としないという特徴があります。
それぞれの条件でのmIoUの結果を図5に示します。
我々の手法は、各モデルにおいて最良のmIoUを達成していることを確認できます。
RandAugmentはFCN-32sのIoUを悪化させ、TrivialAugmentはどのモデルでもmIoUを向上させることができないことが確認できます。
実際に、先行研究でTrivialAugmentは画像分類以外のタスクではうまく機能しないことが報告されています。
RandAugmentとTrivialAugmentの精度が良くないのは、これら2つの探索空間が、意味分割タスクとモデルの容量に適していないからであると考えられます。
しかし、提案手法では分類タスクからパラメータを調整することなく、全ての条件においてmIoUを改善することができ、提案手法の有効性を確認できました。
 図6:セマンティックセグメンテーションタスクに対するmIoUの結果
図6:セマンティックセグメンテーションタスクに対するmIoUの結果
まとめ
この論文では、教師モデルを敵対的データ拡張に導入し、慎重なパラメータチューニングを必要とせず、より情報量の多いデータ拡張を行うTeachAugmentと呼ばれるオンラインデータ拡張最適化手法が提案されています。
また、色に関するデータ拡張を行うモデルと、幾何的な変換に関するデータ拡張を行うモデルを組み合わせたニューラルネットを用いてデータ拡張を行う手法についての提案も行いました。
実験では、画像分類、セマンティックセグメンテーションの各タスクにおいて、各タスクのハイパーパラメータを調整することなく、最先端手法を含む既存のデータ拡張探索フレームワークを上回る性能を示すことを確認しました。




この記事に関するカテゴリー






