
モデルの弱点を克服するデータ拡張手法AugMax登場!
3つの要点
✔️ データの多様性と難易度を戦略的に向上させることで、頑健性を大幅に向上させる新しいデータ拡張戦略である「AugMax」を提案
✔️ AugMAXでは、データ拡張処理を施した複数の変換画像を凸結合することで多様性を維持しつつ元画像と乖離しすぎないデータを生成するAugMixと敵対的摂動を組み合わせることでデータの多様性と難易度を向上
✔️ CIFAR-10-C、CIFAR100-C、ImageNet-C、Tiny ImageNetに対する性能を3つの指標を用いて検証、最新の性能を上回ることを確認
AugMax: Adversarial Composition of Random Augmentations for Robust Training
written by Haotao Wang, Chaowei Xiao, Jean Kossaifi, Zhiding Yu, Anima Anandkumar, Zhangyang Wang
(Submitted on 26 Oct 2021 (v1), last revised 1 Jan 2022 (this version, v3))
Comments: NeurIPS, 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
画像認識において深層学習を用いた手法が高い性能を発揮して以降、画像分類においても畳み込みニューラルネットワークを用いたモデルが多く提案されています。こうしたモデルの多くは、学習データの分布とテストデータの分布が同一であれば高い精度を達成することができますが、実利用において学習データとテストデータの分布は必ずしも一致するわけでなく(例:画像データのカメラのブレやノイズ、雪、雨、霧などによる画像の自然破損や、夏→冬などのドメインシフト)、一致しない場合モデルの推定精度が大きく低下することがあります。
実際、先行研究において最新のモデルの分類誤差が通常のImageNetデータセットに対して22%であったのに対し、ImageNetデータセットの画像に様々な処理を加え、破損させた画像からなるImageNet-Cデータセット(図1参照)で64%に上昇することが報告されています。また、学習データに破損画像を入れることによって、テスト時に学習データに含まれる種類の破損画像を正しく分類できるようになりますが、分類できるようになるのは学習データに含まれている破損のみで未知の破損に対して正しく分類することはできません。これらの結果は、モデルが学習データと異なる分布の画像に汎化できないことを示唆しており、このような場合に対して、モデルの頑健性を向上させる技術は現状ではほとんど存在しません。

図1:ImageNet-Cデータセットの画像例
この問題に対応するようモデルの頑健性を向上させる方法として、データ拡張、リプシッツ連続、安定学習、事前学習、頑健ネットワーク構造などの技術が提案されています。これらの手法の中で、データ拡張は、経験的な有効性、実装の容易さ、低い計算オーバーヘッド、およびプラグアンドプレイの性質から特に注目されています。
データ拡張によるモデルの頑健性向上には大きく2つのアプローチがあります。
一つ目は、AugMixをはじめとした複数のランダムな変換を組み合わせて学習データの多様性を高める方法です。
AugMixは、多様なデータ拡張操作を確率的にサンプリングし、それらをランダムに混合して非常に多様なオーグメンテーション画像を生成する手法であり、標準的なデータ拡張手法(例えば、ランダムな反転や平行移動)と比較して、学習データの多様性を高めることに成功しています。
二つ目は、PGD Attackをはじめとした敵対的摂動(adversarial perturbation)を用いてモデルの頑健性を向上させる方法です。
敵対的摂動を用いた方法では、学習用データにノイズなどを加えモデルにとって分類が難しい画像を生成し、それを学習(敵対的学習)することによって、モデルの汎化性・頑健性を向上させることに成功しています。
これまでの研究では、これら2つのいずれかを活用して頑健性を向上させることに焦点が当てられてきました。そこで、本論文ではモデルの頑健性を向上させることを目的に、この2つのアプローチ(AugMixと敵対的摂動)を1つのフレームワークに統一することで、データの多様性と難易度を向上させるAugMixの改善手法「AugMax」が提案されています。AugMaxはAugMixと比べ、より強力なデータ拡張であり不均質な入力分布をもたらすだけでなく、実験において、提案手法は破損に対する最新の頑健性を達成するだけでなく、他の一般的な分布シフトに対する頑健性を向上させることを確認しました。
次章以降では、事前知識としてデータ拡張とAugMix(リンクは自分が執筆したAugMixの論文解説記事です)、敵対的摂動について簡単に説明した後に提案手法と実験内容、結果について解説していきます。
事前知識
データ拡張とは
データ拡張とは、図2に示すように画像に何らかの変換をかけて擬似的にデータ数を増加させる手法です。
変換の種類は図2に示した以外にも無数にあり、画像の一部を塗りつぶすErasingと呼ばれる手法や、ガウシアンフィルタを適用するGaussianBlurといった手法があります。
このように様々ある拡張手法を用いて学習したモデルは通常、元データのみを学習したモデルに比べて汎化性の高いモデルとなることが知られていますが、時にはパフォーマンスを低下させたり予期せぬバイアスを誘発したりすることがあります。
そのため、モデルの汎化率を向上させるには,ドメインに基づいて効果的なデータ拡張手法を手動で見つける必要があります。
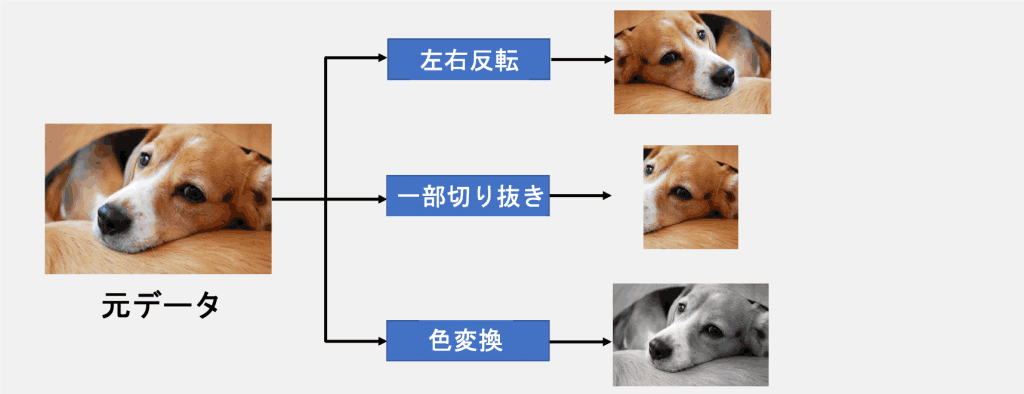
図2:データ拡張概要
AugMix
AugMixの操作に関して概要図を図3に示します。
AugMixは、多様なデータ拡張操作をAutoAugmentから確率的にサンプリングし、それらをランダムに混合して非常に多様なオーグメンテーション画像を生成する手法です。
こうして組み合わされたものをAugment Chainと呼び、Augment Chainは1~3つの拡張操作の組み合わせによって構成されます。
AugMixではこのAugment Chainを$k$個ランダムにサンプリングし、(デフォルトは$k=3$)サンプリングされたAugment Chainを要素単位の凸結合を用いて合成します。
最後に、合成された画像と元画像を「スキップ接続」を用いて結合することで画像の多様性が維持された画像を生成しています。
さらに詳しい部分が知りたい方はこちら(自分が執筆したAugMixの論文解説記事です)を見てみてください。
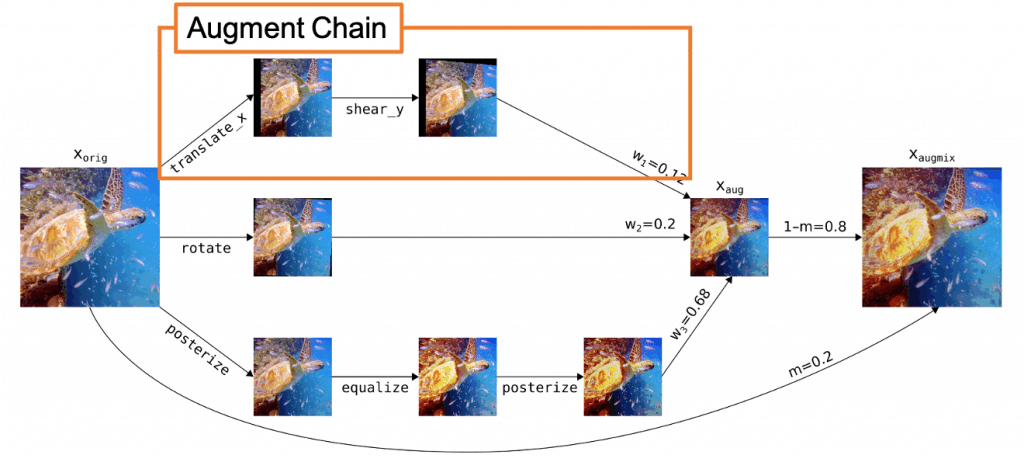 図3:AugMixの操作概要
図3:AugMixの操作概要
敵対的摂動(adversarial perturbation)とは
敵対的摂動とは、モデルに誤分類させるような敵対的な摂動(ノイズなど)のことです。敵対的摂動をデータに加えることで、モデルが高い信頼度で誤った答えを出力してしまうということが問題となっています。
敵対的摂動に関する有名な先行研究として「EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES」があります。この研究の結果として、図4に示すものがあります。
これはノイズを加える前の画像(図4左側)の際は、モデルがパンダと判定していたのにも関わらず、ノイズを加えた画像(図4右側)に対しては手なが猿と判定していたという結果です。(ただ間違えていただけでなく高い信頼度で間違えていることもポイントです)このことは、AIを実利用する際に問題となります。(例:自動運転の際、モデルが標識を誤認してしまい事故につながる可能性があるなど)
そこで、モデルの頑健性(ノイズなどが加わった画像に対しても正確に分類できる)を向上させる方法が研究されています。
敵対的摂動を用いた方法では、学習用データにノイズなどを加えモデルにとって分類が難しい画像を生成し、それを学習(敵対的学習)することによって、モデルの汎化性・頑健性を向上させることに成功しています。
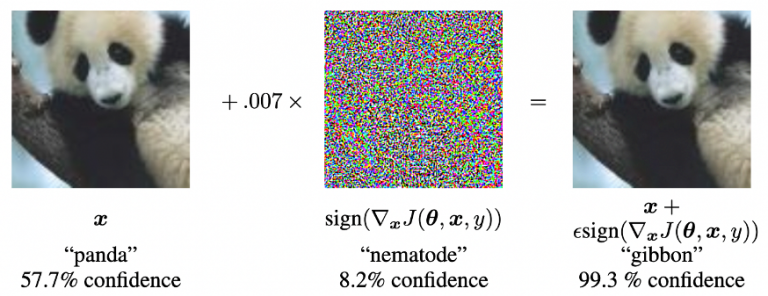
図4:敵対的摂動に関する先行研究の結果
提案手法
ここから、この論文の提案手法であるAugMaxについて解説していきます。
AugMaxはAugMixと敵対的摂動を1つのフレームワークに統一することで、データの多様性と難易度を向上させ、モデルの頑健性を向上させるデータ拡張技術です。
AugMaxの概要図を図5に示します。図5の左側はAugMixと同様の処理を、図5の右側で敵対的摂動に関する処理を行い、これらの処理を通して敵対的混合パラメータ$w$と$m$の更新をしていきます。AugMixでは$w$と$m$をランダムに決定するため、これが提案手法であるAugMaxとの主な違いです。
AugMaxの目的は、画像$\boldsymbol{x} \in \mathbb{R}^d$とラベル$\boldsymbol{y} \in \mathbb{R}^c$のデータ分布$\boldsymbol{D}$が与えられたとき、画像から$\theta$でパラメータ化された分類器$f$:$\mathbb{R}^d$→$\mathbb{R}^c$を学習し、その結果、未知分布に対して頑健性を得ることとなります。そこで、初めに$\theta$について損失を最小化する以下の式を解く。
$\min _{\boldsymbol{\theta}} \mathbb{E}_{(\boldsymbol{x}, \boldsymbol{y}) \sim \mathcal{D}} \mathcal{L}(f(\boldsymbol{x} ; \boldsymbol{\theta}), \boldsymbol{y})$
ここで、$ \mathcal{L}(\cdot,\cdot)$は損失関数を表します。
次に図5右側でAugMaxによって生成されている画像$\boldsymbol{x}^*$は敵対的混合パラメータ$w$と$m$の学習により生成されているため、$\boldsymbol{x}^*$は以下の式で表せる。
$\boldsymbol{x}^*=g\left(\boldsymbol{x}_{\text {orig }} ; m^*, \boldsymbol{w}^*\right)$
ここで、$g(\cdot,\cdot)$はAugMaxのデータ拡張関数を、$\boldsymbol{x}_\text {orig}$は変換前のオリジナル画像を表します。また、敵対的混合パラメータ$w$と$m$は以下の最適化問題を解くことで得られます。
$m^*, \boldsymbol{w}^*=\underset{m, \boldsymbol{w}}{\arg \max } \mathcal{L}\left(f\left(g\left(\boldsymbol{x}_{\text {orig }} ; m, \boldsymbol{w}\right) ; \theta\right), \boldsymbol{y}\right), \quad$ s.t. $m \in[0,1], \boldsymbol{w} \in[0,1]^b, \boldsymbol{w}^T \mathbf{1}=1$
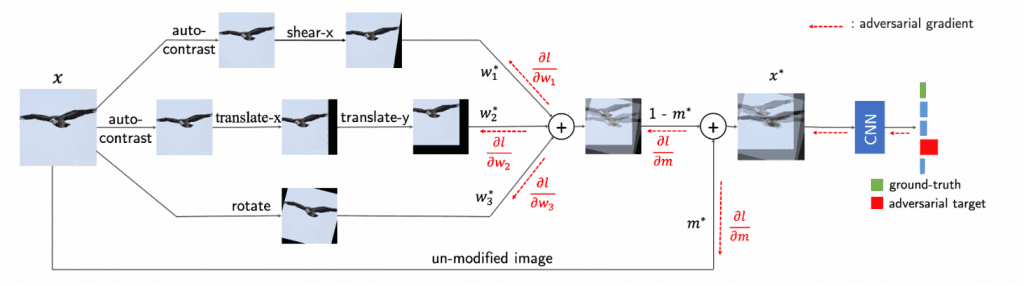 図5:AugMaxの概要図
図5:AugMaxの概要図
実験設定
CIFAR10, CIFAR100, ImageNet, Tiny ImageNet(TIN)を使用して、提案手法の評価を行いました。
また、一般的な自然破損に対するモデルの頑健性の評価のためのデータセットには、テストセット画像に破損を加えて生成したCIFAR10-C、CIFAR100-C、ImageNet-C、Tiny ImageNet-C (TIN-C)を使用しています。
モデルアーキテクチャとしては、CIFARデータセットではResNet18、WRN40-2、ResNeXt29を、ImageNetとTiny ImageNetではResNet18を使用しています。
評価指標
CIFAR10-CとCIFAR100-Cでは、15種類の破損の平均分類精度をRobustness accuracy(RA)と定義し、モデルの頑健性を評価しました。
また、ImageNet-CとTiny ImageNet-Cでは、RAとMean corruption error(mCE)の両方を用いて頑健性を評価しました。
ここで、mCEは異なる種類の破損に対するベースラインモデルの破損誤差で正規化したターゲットモデルの破損誤差の加重平均を意味します。
ベースラインモデルとして、ImageNetでの実験ではAlexNetを、Tiny ImageNetの実験ではTiny ImageNet上で従来から学習されているResNet18を使用しました。
また、分類精度はStandard accuracy(SA)を用いており、これはオリジナルのクリーンなテスト画像に対する分類精度を表します。
結果と考察
CIFAR10-C&CIFAR100-C
CIFAR10-CとCIFAR100-Cにおいて、各アーキテクチャごとに本手法と最先端手法であるAugMixを比較しました。
図6にCIFAR10-Cの結果を、図7にCIFAR100-Cの結果を示します。
ここで、表のNormalとはデフォルトの標準拡張手法(ランダム反転や並進など)を用いて学習することを意味します。
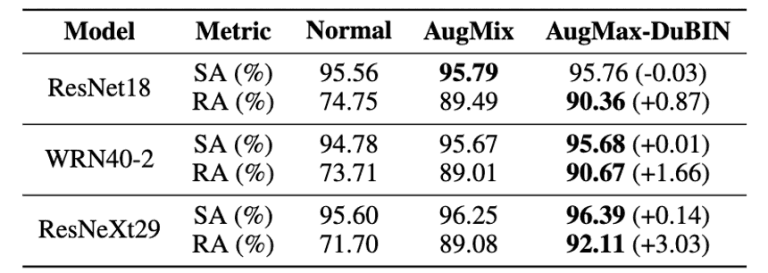
図6:CIFAR10-Cの比較結果
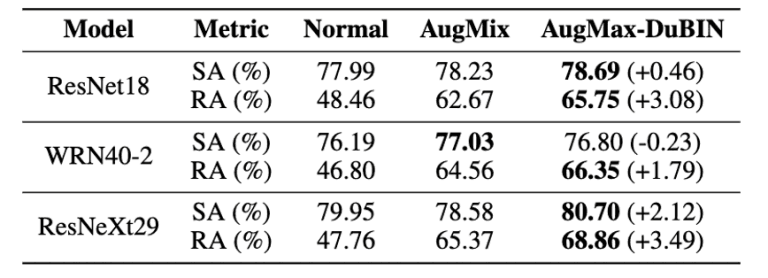
図7:CIFAR100-Cの比較結果
図6、図7よりAugMax-DuBINは、異なる構造を持つ両データセットにおいて、最も良い性能を達成したことが分かります。
例えば、CIFAR10-CとCIFAR100-Cでは、AugMixと比較して、それぞれ3.03%と3.49%という高い精度の向上が確認できます。
さらに、本手法はより大規模なモデルに有効であることも確認しました。
具体的には、CIFAR10とCIFAR100の両実験において、3つのモデルのうち最も容量の大きいResNeXt29で最大の頑健性向上が得られています。
ImageNet-C&Tiny ImageNet-C
先行研究においてAugMixはDeepAugmentなどの他の手法と組み合わせることで、ImageNet-Cでの性能をさらに向上させることが確認されており、それらとの性能を比較するため、ImageNet-CとTiny ImageNet-Cでは(1) AugMix v.s. AugMax、(2) DeepAugment + AugMix v.s. DeepAugment + AugMaxの3つの比較実験を行いました。
図8にImageNet-Cの結果を、図9にTiny ImageNet-Cの結果を示します。
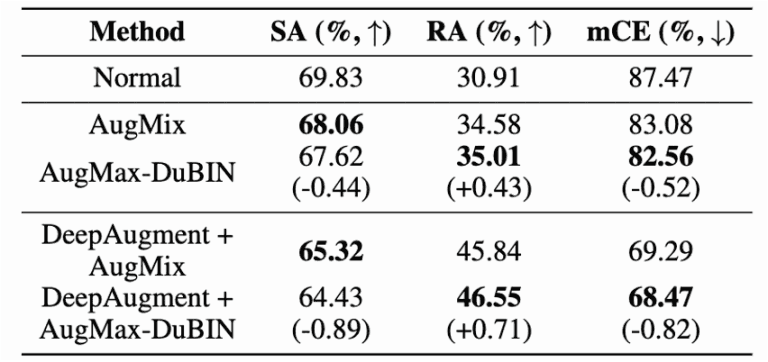 図8:ImageNet-Cの比較結果
図8:ImageNet-Cの比較結果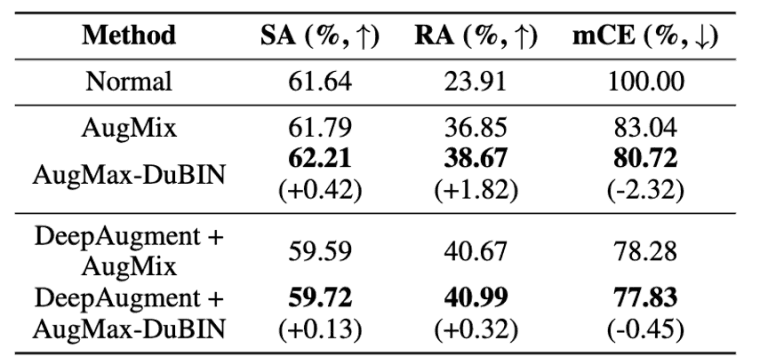 図9:Tiny ImageNet-Cの結果
図9:Tiny ImageNet-Cの結果
図8より、ImageNet-Cでは、AugMax-DuBINがAugMixを0.52%上回るmCEを達成しました。
さらに、AugMax-DuBINとDeepAugmentを組み合わせることで、AugMix + DeepAugmentをmCEで0.82%上回り、ImageNet-Cで最新の性能を達成することを確認しました。
これは、AugMaxがモデル頑健性のためのより高度な基本構成要素として使用できることを示しており、その上に他の防御手法を構築するための今後の研究を促すものです。
図9より、Tiny ImageNet-Cでは、提案手法がAugMixと比較してmCEを2.32%向上させ、DeepAugmentと組み合わせた場合は0.45%向上させることを確認しました。
まとめ
本論文では、データの多様性と難易度を戦略的に向上させることで、頑健性を大幅に向上させる新しいデータ拡張戦略である「AugMax」が提案されています。
提案手法であるAugMaxは、データ拡張処理を施した複数の変換画像を凸結合することで多様性を維持しつつ元画像と乖離しすぎないデータを生成するAugMixと敵対的摂動を組み合わせることでデータの多様性と難易度を向上させ、モデルの頑健性を向上させるデータ拡張技術です。
提案手法の有効性を確認するため、実験ではCIFAR-10、CIFAR100、ImageNet、Tiny ImageNetのそれぞれに対して破損を加えたデータセットである、CIFAR-10-C、CIFAR100-C、ImageNet-C、Tiny ImageNetに対する性能をRobustness accuracy(RA)、Mean corruption error(mCE)、Standard accuracy(SA)の3つの指標を用いて確認しました。
その結果、提案手法は先行研究での最新の性能を上回ることが確認できました。






この記事に関するカテゴリー






