分類モデルの精度評価にラベルは常に必要であるか?
3つの要点
✔️ ラベルなしテストセット上での分類モデル精度を予測する手法の提案
✔️ データセットの統計情報から分類精度を予測する回帰モデルを学習
✔️ ラベルなしテストセット上での精度推定を実証
Are Labels Always Necessary for Classifier Accuracy Evaluation?
written by Weijian Deng, Liang Zheng
(Submitted on 6 Jul 2020 (v1), last revised 25 May 2021 (this version, v3))
Comments: CVPR 2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
画像認識をはじめとするコンピュータビジョンタスクにおいて、モデルの性能の評価にはラベル付きのテストセットを利用します。
しかし、ラベル付きのテストセットがあらかじめ用意されている一般的なベンチマークとは異なり、現実にモデルを利用したい場合には、このようなラベル付きのテストセットの用意は難しいかもしれません。
例えば、シミュレータによる合成データを訓練セットとして学習させたモデルを実世界で利用したい場合、実世界のラベル付きテストセットを準備することは困難かもしれません。
本記事で紹介する論文では、この問題に対処するため、ラベルのないテストセットでモデルの性能を推定する手法(AutoEval)を提案しています。
この問題設定は、例えば以下の図に要約されます。
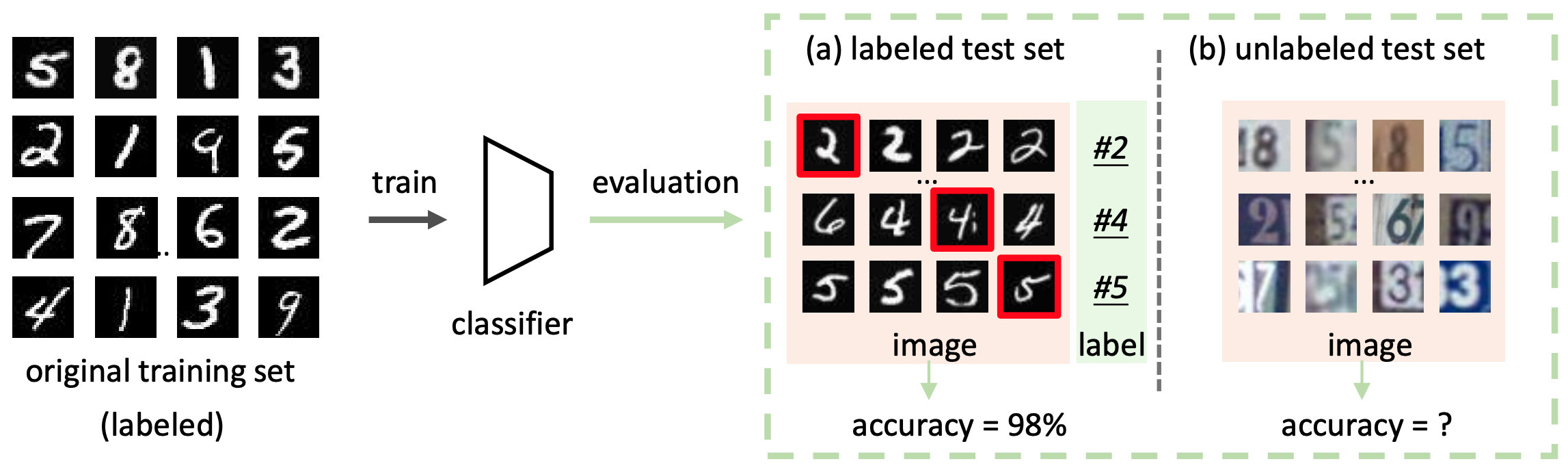
図の(b)のように、ラベルなしテストセットに対する分類モデルの性能の評価を行うことがAutoEvalの目標となります。
分布シフトと分類モデル精度の相関について
提案手法であるAutoEvalは、ラベルなしテストセットに対する分類モデルの性能の評価を目標とする手法です。このAutoEvalは、訓練セットとテストセットの分布シフトが、分類モデルの精度と強い負の相関があるという知見に基づいています。
これは以下の図で示されます。

この図では、数字画像の分類(digit classification)、自然画像の分類(natural image classification)について、訓練セットとテストセットの分布のずれを示すフレシェ距離(FD:Fréchet distance)が横軸に、分類精度が縦軸に示されています。
図の通り、分布シフトの大きさに対応するフレシェ距離と分類精度には強い負の相関が見られ、実際にスピアマンの順位相関係数$rho$は約-0.91となっています。また、数字画像分類における実際の事例は以下の通りです。

この図では、訓練セットと大きく分布が異なるsample set 1では60%、分布のずれが比較的小さいsample set 2では86%の分類精度を示しています。
このことから、訓練セットとテストセット間での分布シフトの大きさなど、データセットの分布に関する情報を用いることで、ラベルなしテストセットでの分類モデル精度を推定することができると考えられます。
提案手法(AutoEval)
AutoEvalの定式化
前述の知見に基づき、AutoEvalでは、訓練セットとテストセット間の分布の差異をもとに、分類モデルの精度を予測することを目標とします。
具体的には、データセットをサンプルとみなし、そのデータセットに対する分類モデルの精度をラベルとみなして、データセットから分類モデルの精度を予測する回帰モデル$A:(f_{\theta}, D^u) \rightarrow a$を学習します($f_{\theta}は分類モデル、$D^u={x_i}$はラベルなしデータセット、$a$は分類モデルの精度の推定値)。
ここで、$N$個のサンプルデータセットが存在するとして、$j$番目のサンプルデータセット$D_j$を$(f_j,a_j)$と表します。
$f_j$はデータセット$D\j$についての何らかのベクトル表現、$a_j \in [0,1]$は$D_j$に対する分類モデル$d_{\theta}$の分類精度となります。
このときAutoEvalの目標は以下の式で表される回帰モデル$A$を学習することです。
$a_j=A(f_j)$
このモデルの学習には、標準的な二乗損失関数を用います。
$L=\frac{1}{N} \sum^N_{j=1} (\hat{a_j}-a_j)^2$
$hat{a_j}$は$D_j$に対する$A$の分類精度の予測値です。
このモデルを学習させた後、ラベルなしテストセット$D^u$に対応するベクトル表現$f^u$について、$a=A(f^u)$により分類精度の推定値を求めます。
AutoEvalについて
前述した定式化に基づきAutoEvalを学習させるには、以下に示す三つの設計を行う必要があります。
- データセット表現$f_i$
- 回帰モデル$A$
- 回帰モデルの学習に用いる$N$個のサンプルセット(メタデータセット)
それぞれ順番に見ていきましょう。
データセット表現$f_i$・回帰モデル$A$について
線形回帰モデル
回帰モデル$A$のシンプルな例として、以下の線形回帰モデルを導入します。
$a_{linear} = A_{linear}(f) = w_1f_{linear}+w_0$
このとき、$f_{linear}$はサンプルセット$D$の表現、$w_0,w_1$は線形回帰モデルのパラメータを示します。また、$f_{linear}$は訓練セット$D_{ori}$とサンプルセット$D$間のフレシェ距離(FD:Fréchet distance)を示し、以下の式で与えられます。
$f_{linear} = FD(D_{ori}, D)$
$= ||\mu_{ori}-\mu||^2_2 + Tr(\Sigma_{ori}+\Sigma-2(\Sigma_{ori}\Sigma)^{\frac{1}{2}})$
このとき、$mu_{ori},\mu$はそれぞれ$D_ori,D$の平均特徴ベクトル、$\Sigma_{ori},\Sigma$は共分散行列を示します。
これらは$D_ori$で学習した分類モデル$f_{\thteta}$により、$D_ori,D$内の画像特徴量を計算して求められます。
ニューラルネットワーク回帰モデル
線形回帰モデルとは別に、ニューラルネットワークを用いた回帰モデルについても考えます。
これは$a_{neural} = A_{neural}(f_{neural})$と表され、回帰モデルのアーキテクチャには単純な全結合ニューラルネットワークを用います。
また、データセットに対応する表現$f_{neural}$について、データセットの平均ベクトル\mu$、共分散行列$\Sigma$、前述した$f_linear$を用いて以下のように定義されます。
$f_{neural}=[f_{linear}; \mu; \sigma]$
ここで、共分散行列$\Sigma$は高次元で学習が困難なため、$\Sigma$の各行の加重和により次元削減を行った$\sigma$を利用します。
回帰モデルの学習に用いるメタデータセットについて
前述した回帰モデルの学習には、サンプルデータセットとそれに対応する分類精度が必要となります。
このとき、サンプルセットが十分に多様であり、テストセットがメタデータセットの分布に含まれることが理想的です。
このようなメタデータセットを構築するため、多様なデータセットを合成します。
具体的には、訓練セット$D_{ori}$と同じソースドメイン$S$からサンプリングされたシードデータセット$D_s$(D_{ori}と同じ分布をもつ)に対して様々な変換処理を行い、サンプルセット$D_j$を生成します。
変換処理は以下の二段階に分かれています。
- 背景の変換:COCOデータセットからランダムに選択された画像をランダムに切り取り、背景として置き換えます。
- 画像変換:6種類の画像変換処理(autoContrast, rotation, color, brightness, sharpness, translation:AutoAugmentを参照)のうち3つをランダムに選択して組み合わせ、サンプルごとに異なる大きさの変換を行います。
画像変換処理の例は以下の通りです。

実際に生成されたサンプルセットの例は以下のようになります。

これらのサンプルセットのラベルは、シードセットのラベルをそのまま継承しているため、それぞれについて分類精度を予測することが可能です。
そのため、以上の手順によって生成された各サンプルセットについて、訓練セット$D_{ori}$で学習された分類モデル$f_{\theta}$を用いて分類精度を予測し、それを回帰モデルのためのサンプル$(f_j,a_j)$として利用します。
confidenceベース手法(ベースライン)
AutoEvalの評価のためのシンプルなベースラインとして、「SoftMax層の出力が大きければ(≒Confidenceが大きければ)、その予測は正しい可能性が高い」という仮定に基づく直感的な解決策を導入します。
具体的には、分類モデル$f_{\theta}$のSoftMax層の出力$s_i$が閾値$\tau$より大きければ、画像$x_i$についての分類は正しく行われたとみなします。
$a_max=A_max(f_{\theta},D^u)=\frac{\sum^M_{i=1}[max(s_i) > \tau]}{M}$
$M$は$D^u$に含まれる画像数です。
実験設定
数字分類・自然画像分類の二つの分類タスクでAutoEvalの実験を行います。それぞれの実験設定は以下の通りです。
数字画像分類タスク
- オリジナルの訓練セット$D_{ori}$:MNISTのtrainセット
- メタデータセット生成のためのシードセット$D_s$:MNISTのtestセット
- テストセット:USPS、SCHN
- サンプルセット数:trainセット3000、validationセット1000
- アーキテクチャ:LeNet-5
サンプルセット生成時の背景置換時には、COCOのtrainセットを利用します。
自然画像分類タスク
- オリジナルの訓練セット$D_{ori}$:COCOのtrainセット
- メタデータセット生成のためのシードセット$D_s$:COCOのvalidationセット
- テストセット:PASCAL、Caltech、ImageNet
- サンプルセット数:trainセット1000、validationセット600
- アーキテクチャ:ImageNetで事前学習済みのResNet-50
サンプルセット生成時の背景置換時には、COCOのtestセットを利用します。
また、各データセットについて12の共通クラス(aeroplane, bike, bird, boat, bottle, bus, car, dog, horse, monitor, motorbike, person)を選択して利用します(personクラスは画像数を600枚に制限します)。
実験結果
前述した三つの手法(confidenceベース手法、線形回帰モデル、ニューラルネットワーク回帰モデル)それぞれについて、実験を行った結果は以下の通りです。
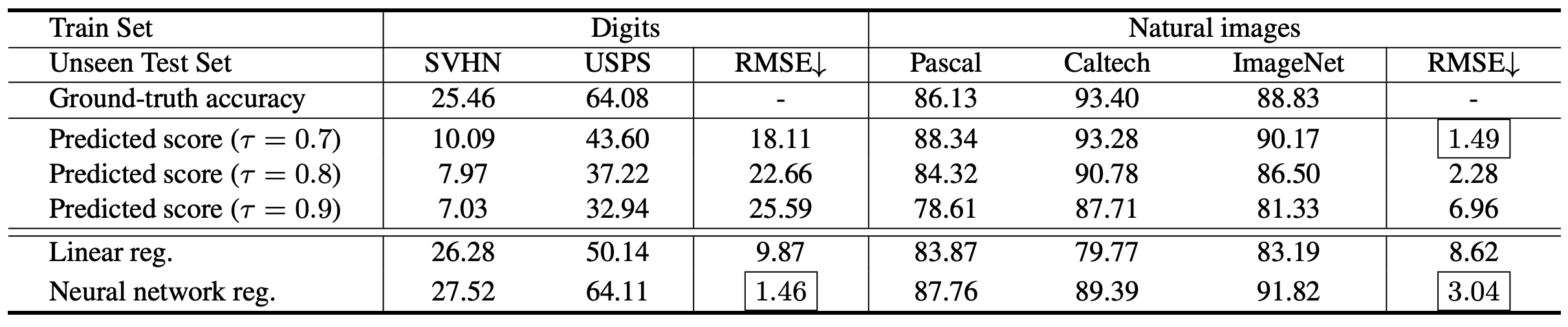
confidenceベース手法は閾値に対して敏感にRMSE(小さいほど良好)が変化し、数字画像分類では非常に性能が低くなるのに対し、AutoEval(Linear reg./Neural network reg.)は安定して機能していることがわかります。
また、Caltechデータセットにおいて線形回帰モデルが著しく劣っていますが、これはCaltechデータセットの背景がシンプルであることに線形回帰モデルが影響を受けたと考えられます。
線形回帰/ニューラルネットワーク回帰モデルの比較
二種類の回帰手法に検証のため、自然画像データセット(PASCAl、Caltech、ImageNet)に画像変換を行った場合の比較実験結果は以下の通りです。
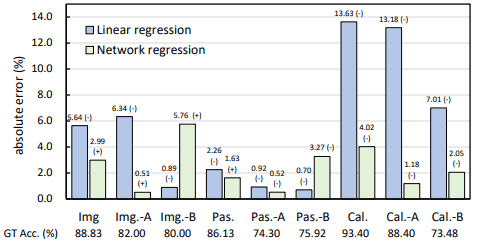
画像変換処理を行った場合は"-A","-B"で示されています。
線形回帰モデルはCaltechデータセットを除き良好な結果を示し、ニューラルネットワーク回帰モデルは安定して良好な結果を示すことがわかりました。
メタデータセットについて
メタデータセットのサイズ(サンプルデータセットの数)とサンプルデータセットのサイズ(サンプルデータセットに含まれる画像の数)について、回帰モデルへの影響を調査した結果は以下の通りです。
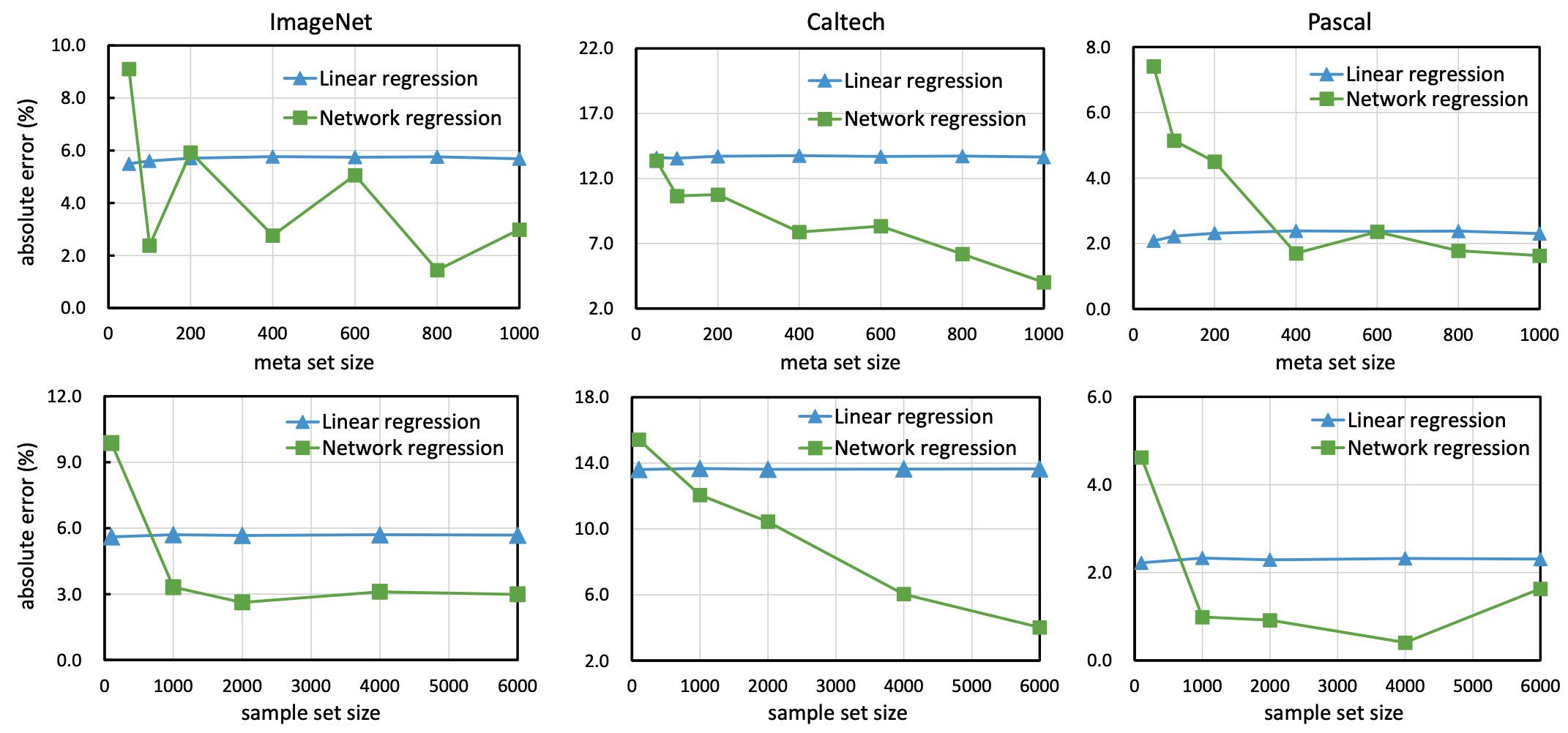
総じて、線形回帰モデルはデータ数が少なくても安定して機能する一方、ニューラルネットワーク回帰モデルはメタデータセット/サンプルデータセットサイズどちらについても、ある程度大きい場合が最も良好に機能することがわかりました。
まとめ
本記事で紹介した論文では、ラベルが存在しない場合におけるテストセットの分類精度を予測するという新たな問題について取り組んでいます。
提案手法のAutoEvalでは、背景置換・画像変換処理により合成サンプルデータセットを作成し、各サンプルセットに対応する分類精度を予測する回帰モデルを学習することで、この問題に対してある程度の成功を収めました。
ただし、(1)メタデータセットが合成データに頼っているため、テストセットの分布によっては良好に機能しない可能性があること、(2)データセットの表現として、平均と共分散以外にも有効な表現が存在しうること、(3)データセット間の類似度測定にFDスコアを用いているものの、他にも有効な基準が存在しうること、などなど、さらなる改善の可能性も大きいと考えられます。






この記事に関するカテゴリー






