
See Finer, See More. テキストベースの人物検索のための暗黙のモダリティアライメント
3つの要点
✔️ テキストおよび画像に同一のエンコーダを用いることで、両モーダルの相互作用を学習できるようにした。
✔️ テキストを文レベル・センテンスレベル・単語レベルに分け、マルチレベルで画像-テキストマッチングをした。
✔️ 画像とテキストの両方の埋め込みを用いてマスク言語モデリングを解かせることで画像-テキストマッチングをした。
See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
written by Xiujun Shu, Wei Wen, Haoqian Wu, Keyu Chen, Yiran Song, Ruizhi Qiao, Bo Ren, Xiao Wang
(Submitted on 18 Aug 2022 (v1), last revised 26 Aug 2022 (this version, v2))
Comments: Accepted at ECCV Workshop on Real-World Surveillance (RWS 2022)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
人物画像を検索する人物再識別は、防犯カメラからの容疑者や迷子の発見など多くの需要があります。その中でも、入力画像と同じ人物が映っている画像を検索するのではなく、テキストからそれに合致する人物が映った画像を検索するテキストベースの人物再識別が注目されています。この分野はかなりホットで、最新のものだと4月5日に投稿された論文([2304.02278] Calibrating Cross-modal Feature for Text-Based Person Searching (arxiv.org))でSOTAを更新しています。(4月13日現在)
テキストベースの人物再識別タスクにおけるメインアプローチは画像とテキストの両モダリティを同一の潜在空間にマッピングすることです。従来手法では、画像エンコーダにResnet、テキストエンコーダにBERTを用いるなど、特徴抽出に別々のモデルを利用することが多いですが、このアプローチには2つの課題があります。
- 別々のモデルにはモダリティ間の相互作用がない。マッチングロスを用いるだけでは、膨大なパラメータかつ深い層を持つモデルに相互作用を考慮させることは難しいです。(図1a)
- テキストの多様性によってパーツのマッチングが困難。例えば、同じ人物を示すテキストでも、ヘアスタイルやパンツに関する記述があるテキストとアクセサリや色に関する記述があるテキストがある。
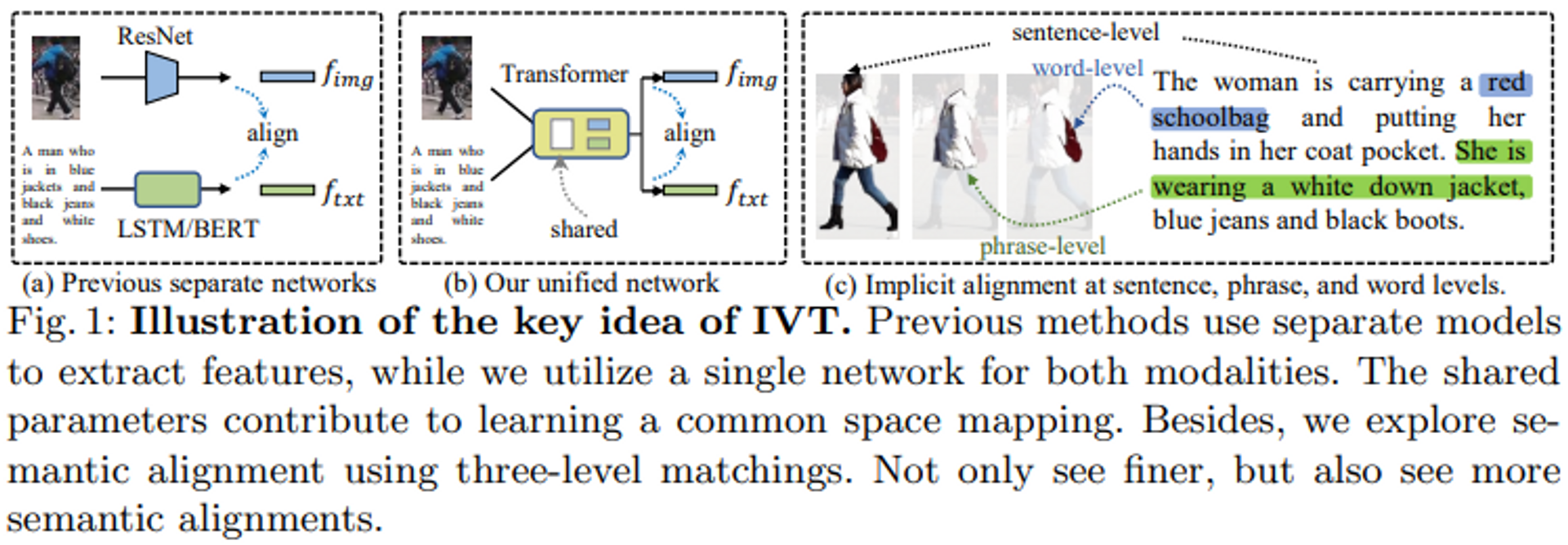
本論文では、1つ目の課題に対しては同一のエンコーダを用いることで、2つ目の課題に対しては局所的な意味マッチングはより細かく見るのではなく、より多く見ることに焦点を当てることでアプローチしています。
1つ目のアプローチとして、ネットワークを用いて両モダリティの表現を学習できる暗黙的視覚・テキスト学習(IVT)フレームワークを導入しています(図1b)。
2つ目のアプローチとして、細粒度なモダリティマッチングを実現するために、マルチレベルアライメント(MLA)と双方向マスクモデリング(BMM)という2つの暗黙のセマンティックアライメントパラダイムを提案しています。具体的には、図1(c)に示すように、MLAは文、フレーズ、単語レベルのマッチングを利用し、細粒度なアライメントを探求することを目的としています。BMMは、ある割合の視覚的・文字的トークンをマスクすることで、モデルにより有用なマッチングキューを掘り起こさせます。提案された2つのパラダイムは、より細かく見ることができるだけでなく、より多くの意味的な整列を見ることもできます。
提案手法
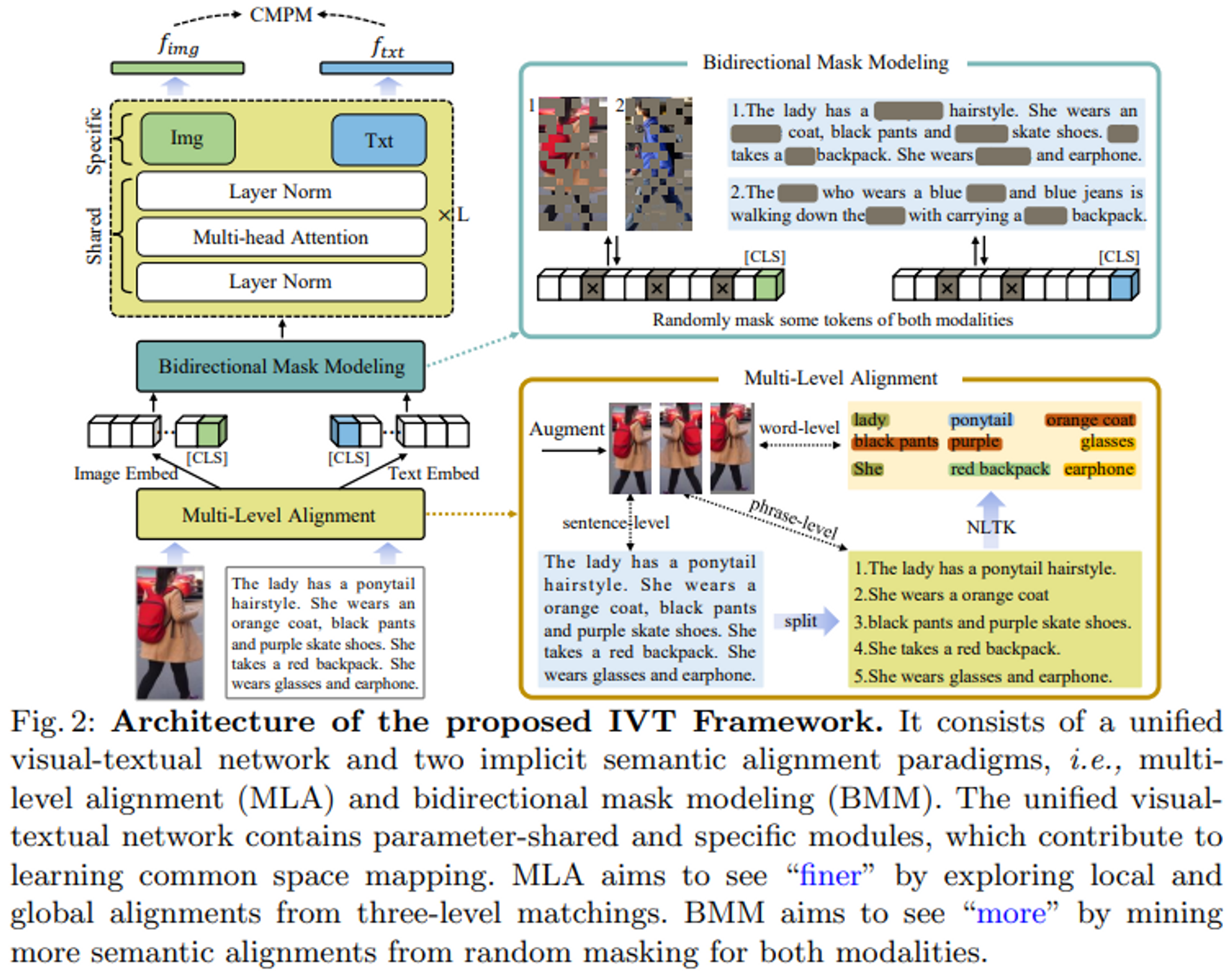
IVTフレームワークは、統一された視覚-テキストネットワークと、2つの暗黙の意味的アライメントパラダイム(マルチレベルアライメントと双方向マスクモデリング)で構成されます。
IVTの重要な考え方の一つは、統一されたネットワークを用いてモダリティアライメントに取り組むことにあります。レイヤーの正規化やマルチヘッドアテンションなど、いくつかのモジュールを共有することで、統一ネットワークは視覚とテキストモダリティ間の共通空間マッピングの学習に寄与します。また、異なるモジュールを用いて、モダリティ固有の手がかりを学習することもできます。
MLAとBMMという2つの暗黙のセマンティックアライメントパラダイムを提案し、きめ細かなアライメントを探求します。
エンコーダ
従来手法の多くはテキストエンコーダと画像エンコーダに別々のモデルを利用しており、モダリティ間相互作用を欠いています。そこで、本論文では統一的な画像-テキストネットワークを採用することを提案しています。
図2に示すように、このネットワークはViTの標準的なアーキテクチャに従い、全部でL個のブロックを積み重ねます。各ブロックでは、2つのモダリティがレイヤー正規化(LN)とマルチヘッドセルフアテンション(MSA)を共有し、画像とテキストのモダリティ間の共通空間マッピングの学習に寄与しています。共有されたパラメータは共通のデータ統計の学習に役立ちます。例えば、LNは入力トークン埋込の平均値と標準偏差を計算し、共有LNは両モダリティの統計的に共通する値を学習することになります。これは、データレベルの観点からは「モダリティの相互作用」とみなすことができます。画像とテキストのモダリティは異なるため、各ブロックはモダリティ固有のフィードフォワード層、すなわち図2の「Img」「Txt」モジュールを備えており、モダリティに特化した情報を取得します。各ブロックの完全な処理は、以下のように表すことができます。
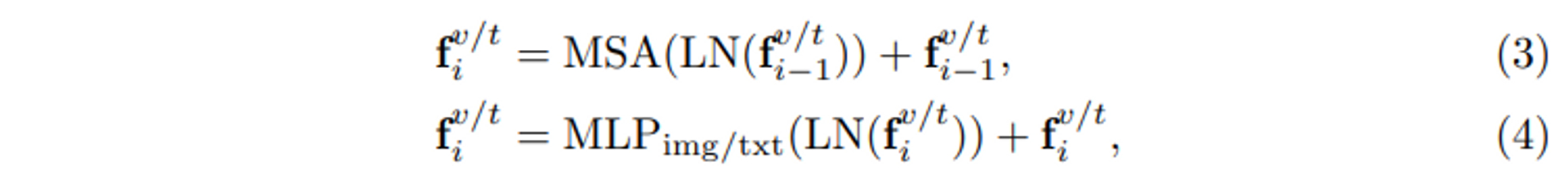
暗黙的意味アラインメント
マルチレベルアラインメント
直感的でありながら非常に効果的な暗黙の位置合わせ手法、すなわち多段階位置合わせを提案しています。
図2に示すように、入力画像はまず、水平反転やランダムな切り抜きなど、3種類の拡張を行います。入力テキストはピリオドやカンマで分割し、より短い文章にします。これらの短文を、人体の部分的な外観特性を記述する「フレーズレベル」表現とします。さらに細かい部分を抽出するために、自然言語ツールキット(NLTK)を利用して、バッグ、服、ズボンなど特定の局所的な特徴を表す名詞と形容詞を抽出します。文レベル、フレーズレベル、単語レベルという3レベルのテキスト記述は、3種類の増強画像に対応します。3レベルの画像とテキストのペアは、各反復でランダムに生成されます。このようにして、グローバルからローカルへと徐々に洗練されていくマッチングプロセスを構築し、モデルにより細かい意味的アラインメントを採らせることができます。
双方向マスクモデリング
本論文では、ローカルアライメントがより細かいだけでなく、より多様であるべきだと主張しています。微妙な視覚的・文字的手がかりは、グローバルアライメントを補完するものである可能性があります。図2に示すように、より意味的なアライメントをマイニングするために、双方向マスクモデリング(BMM)法を提案します。画像とテキストのトークンのうち、何割かをランダムにマスクし、視覚とテキストの出力が一致するように強制する。一般に、マスクされたトークンは、画像の特定のパッチまたはテキストの単語に対応する。特定のパッチや単語がマスクされた場合、モデルは他のパッチや単語から有用なアライメントキューを探し出そうとします。図2の女性を例にとると、「オレンジ色のコート」と「黒いズボン」という顕著な単語がマスクされている場合、モデルは他の単語、例えばポニーテールの髪型や赤いバックパックに注目するようになります。このようにして、より微妙な視覚的なテキストの位置関係を探索することができます。この方法は、学習段階では、モデルによる画像とテキストの位置合わせが難しくなりますが、推論段階では、より意味的な位置合わせを探索するのに役立ちます。
損失関数
マッチングロスとしてCMPMロスを使用しています。詳細はDeep Cross-Modal Projection Learning for Image-Text Matching (thecvf.com)に任せますが、簡単にいうと、KLダイバージェンスによってテキスト-画像埋め込みマッチングを行っています。
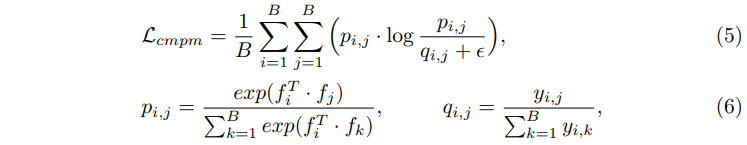
実験
提案手法IVTは3つのデータセットでSOTAを達成しています。評価はRecall@n(n=1,5,10)で行っています。
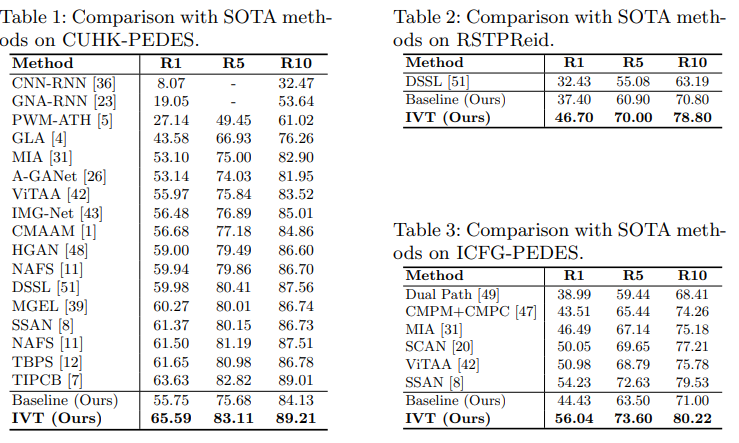
図4にベースラインと提案手法IVTの判断根拠の可視化を示しています。([CLS]トークンとのアテンションマップを可視化したものです。)一般に、テキストによる説明は人体に対応することができ、モデルが視覚とテキストのモダリティの意味的関連性を学習したことを実証している。ベースラインと比較して、IVTは、テキストによって記述された人体のより多くの属性に焦点を当てていることが確認できます。例えば、男性(1行目、1列目)はグレーのショートパンツを履いています。ベースラインはこの属性を無視していたが、IVTはこの属性を捉えることができました。したがって、提案するIVTは、ベースライン法よりも正確で多様な人物属性に対応することができます。

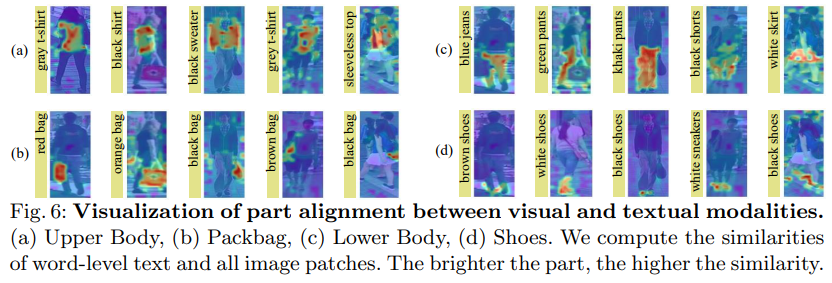
図6にローカルトークンとのアテンションを示しています。上半身、カバン、下半身、靴の4種類の人物属性を与えています。図6の各行は、同じ属性を共有しています。図6に示すように、本手法は、服やズボンなどの目立つ部位だけでなく、ハンドバッグや靴などの微妙な部位も認識できることがわかります。これらの可視化結果は、単語レベルの属性記述があれば、我々のモデルが正確に正しい身体部位に焦点を当てることができることを示しています。これは、我々のアプローチが、明示的な視覚的・テキスト的パーツアライメントがなくても、細かいアライメントを探索することが可能であることを示しています。これは、提案された2つの暗黙の意味的整列パラダイム、すなわち、MLAとBMMの恩恵であるといえます。したがって、本提案手法は、テキストベースの人物検索において、See Finer and See Moreを実際に達成することができるという結論を導き出すことができる。
まとめ
本論文では、バックボーンネットワークと暗黙のセマンティックアライメントという2つの観点からモダリティアライメントに取り組むことを提案しました。まず、テキストベースの人物検索のための暗黙的視覚的テキスト(IVT)フレームワークを紹介しました。これは、単一のネットワークを用いて、視覚的表現とテキスト的表現を学習することができます。第二に、BMMとMLAという2つの暗黙的なセマンティックアライメントパラダイムを提案し、きめ細かなアライメントを探求します。この2つのパラダイムは、3レベルのマッチングを用いることで「より細かく」見ることができ、より多くのセマンティックアライメントをマイニングすることで「より多く」見ることができます。3つの公開データセットを用いた広範な実験結果により、本提案の有効性が実証されました。




この記事に関するカテゴリー






