
ViTに優った!大規模CNNの新たな基盤モデル!: InternImage
3つの要点
✔️ Deformable Convolutionを核としたCNNモデルが分類・検出・セグメンテーションでViTと同等以上の精度を達成!
✔️ 物体検出・セグメンテーションでは堂々の1位を達成!
✔️ DCNv2を改良したDCNv3により3x3カーネルの少ないパラメータで受容野を拡大!
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
written by Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, Xiaogang Wang, Yu Qiao
(Submitted on 10 Nov 2022 (v1), last revised 13 Nov 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
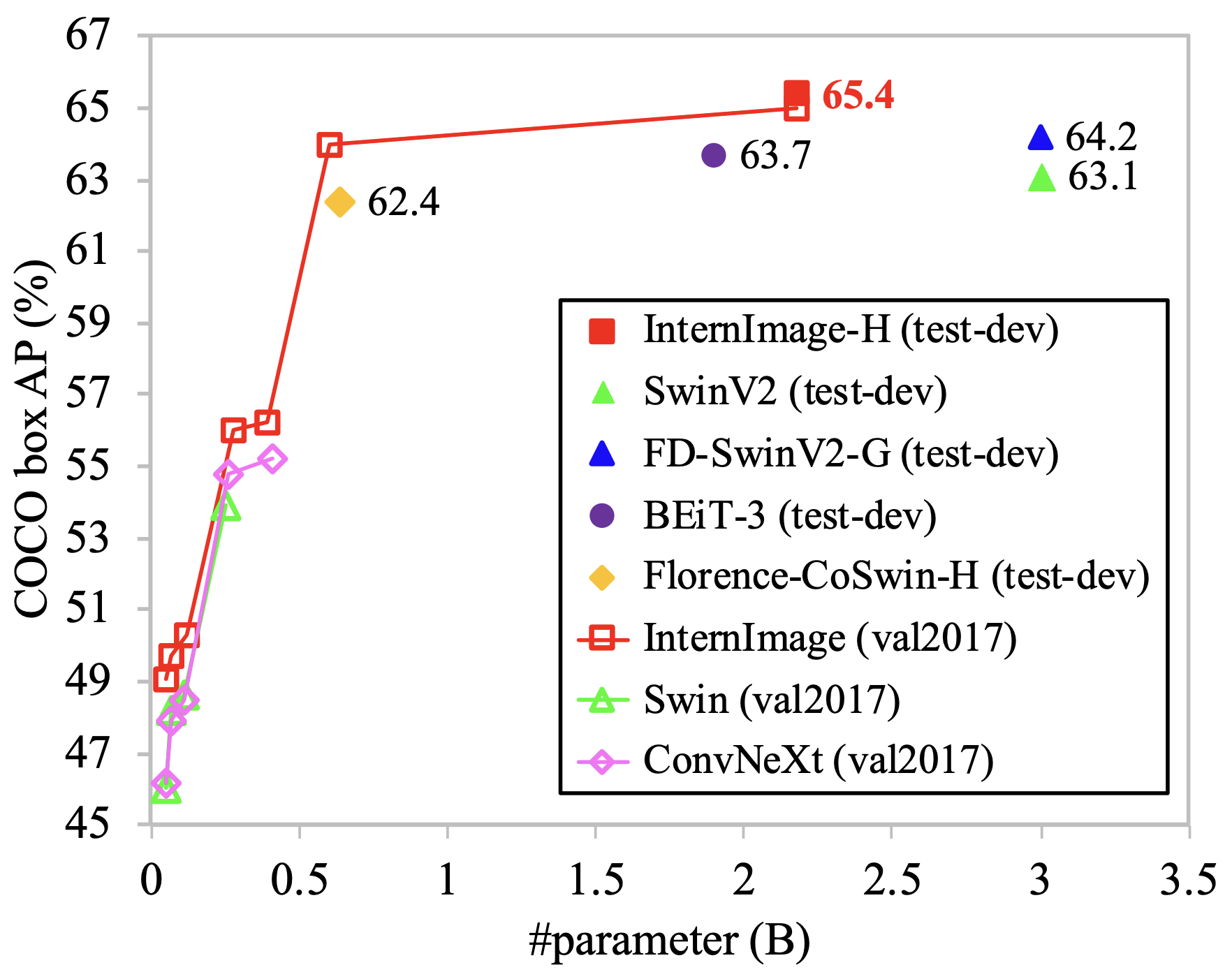
上の図はCOCOデータセットの物体検出におけるViTベースの手法とCNNベースの手法、そして今回紹介するInternImageの精度です。InternImageは少ないパラメータで最高精度を達成しています。
今回紹介するのは変形畳み込みを核としたCNNベースの大規模基盤モデルです。AlexNet以降ComputerVisionの分野で覇権を握ってきたCNNですが、今日では帰納バイアスを持たずに大規模データを学習可能にしたVision Transformer(ViT)が多くのタスクでその座に着いています。CNNとViTの優位性のギャップは以下の2つが挙げられます。
- ViTは帰納バイアスを持たず長距離の依存関係を学習できる
- ViTは動的重みにより入力に対して適応的な依存関係を獲得できる
InternImageはこれに対してDCNを採用することでギャップを埋め、大規模データの学習を少ないパラメータで可能にし、高精度を達成しました。ImageNetでViT相当の精度、COCOデータセット・ADE20Kデータセットで共に1位という結果を出し、CNNベースのモデルに大きな将来性を与えました。ViT同様様々なスケールのモデルを検証しています。それではInternImageを見ていきましょう。
体系的位置付け
CNNとViTの大きな違いは帰納バイアスの有無です。CNNは特徴の局所性をバイアスとして仮定し、小さなカーネルで局所的特徴抽出を多層に渡り重ねる構造を取っています。この構造のためにCNNは比較的小規模なデータセットでの学習が可能ですが、一般的に深層学習モデルは大規模データセットでの学習が高精度の鍵となります。CNNは帰納バイアスにより特徴抽出の幅を制限してしまっているため、大規模データから得られるはずの多様な特徴を学習できずにいます。一方でViTは帰納バイアスを仮定せず画像の全ての局所パッチ間の関連性を学習する長距離依存性を持つ機構です。小規模データでの過学習が課題として挙げられますが、大規模データでの学習は圧倒的にViTが有利なのが現状です。
もう1つ、重みが動的か静的かという違いがあります。CNNは推論時は局所パッチに依らず一意の学習済みカーネルで特徴抽出を行います。一方でViTはAttentionを取る直前に局所パッチをQ,K,Vに線形射影させているため、抽出すべき依存関係に合わせた重みを動的に獲得し、推論時にも入力によって異なる重みを持つパッチ間の関連性を抽出します。
ViTとCNNのギャップを埋める鍵はこの2つです。直近で提案された大規模CNNモデルRepLKNetは長距離依存性と有効受容野の関係に着目し、大きなカーネルを組み込むことで大規模データセットの学習を可能にしました。CNNも層を重ねることで受容野は広がるはずですが、実際の有効受容野はさほど大きくない事を指摘し、feature re-parameterizationやdepth-wise畳み込みを組み込む事で、31x31という大胆なサイズのカーネルでの学習を成功させました。しかしそれでもViTとのギャップは存在し、また31x31という大きなパラメータや、それを学習可能にするためのギミックが複雑である事など課題が多くある事を本論文は指摘しています。
提案手法であるInternImageは3x3という小さなカーネルで上記2つの課題を解決し、効率的に大規模化させる新たなCNNの基盤として提案されています。最近のCNNの大規模化の研究と同様、ViTの様々な機構を参考に構築しています。
DCNv3
本論文では長距離依存性・動的重みを実現するためにDeformable Convolution Network(DCN)に着目しています。利点は次のとおりです。
- 通常の畳み込みと異なり長距離依存性と入力に適応的に対応する畳み込みが行える
- MHSAと異なり帰納バイアスを受け継いでいるため少ない学習データと時間で効率的に学習できる
- MHSAやRepLKNetなどと異なり3x3カーネルで完結し、計算・メモリ効率が良い
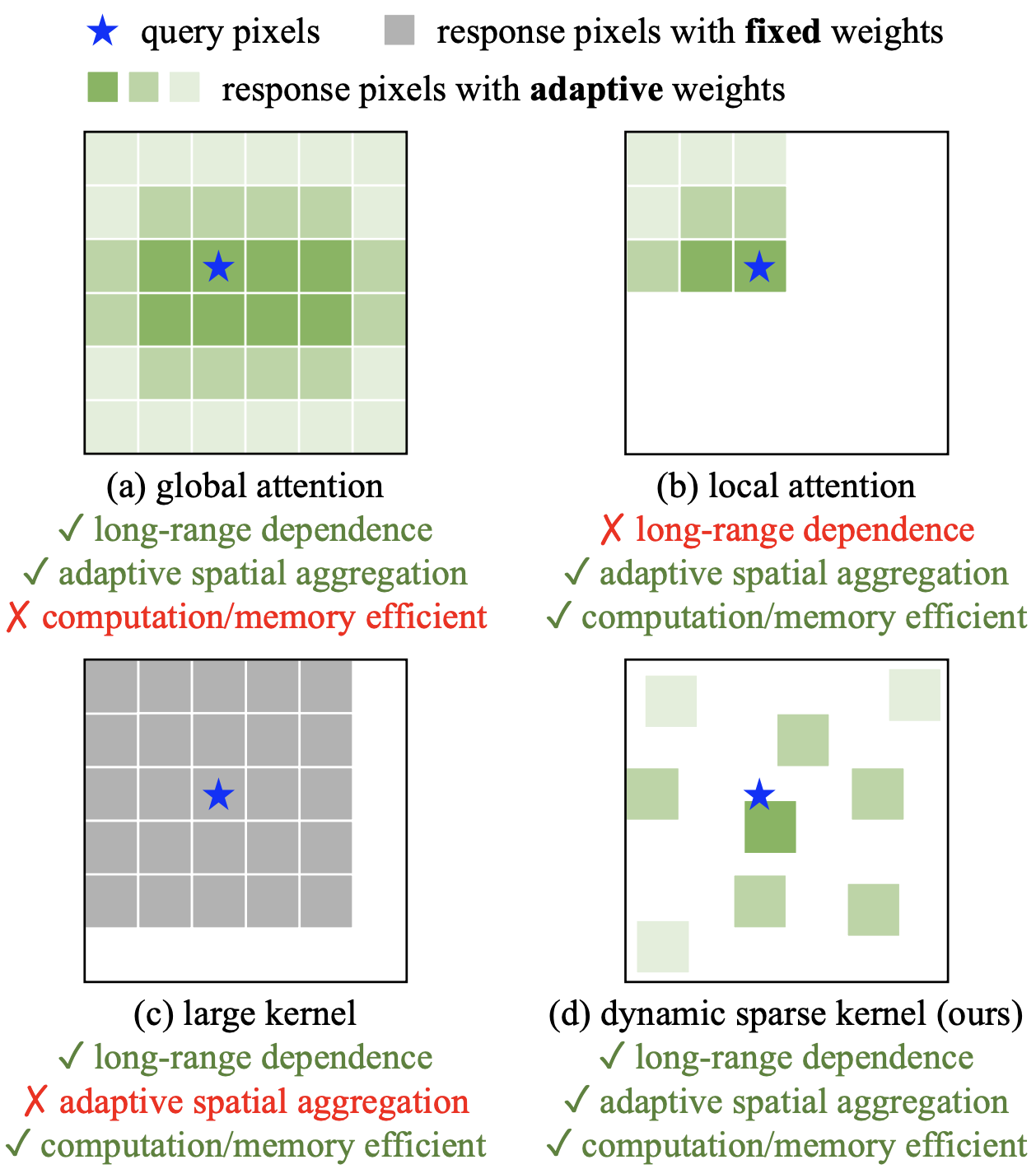
DCNは通常矩形の窓を取るカーネルをデータに応じて変形可能にした畳み込みです。下の図を見てください。(a)ローカルなAttentionと(b)グローバルなAttention、(c)RepLKNetなどの大きなカーネル、そして(d)DCNの計算のイメージを示しています。Attentionは入力に対して動的に重みを調整していますが、グローバルなAttentionは計算コストが大きく、ローカルなAttentionは長距離の依存性を捉えられない問題があります。大きなカーネルでは計算コストをAttentionと比べて下げ長距離の関係を捉えられる反面、入力に対して動的に処理することができません。しかし(d)のDCNでは3x3カーネルと小さい窓のまま変形により長距離の関係を捉えることができ、その変形の仕方や重みが入力によって適応的に変わるため、長距離依存性・動的重み・計算コスト全ての条件を達成できることが分かります。
DCNv2
本論文は既存のDCNv2に改良を加えたDCNv3を提案し、InternImageに採用しています。DCNv2は次の式で表されます。
%3D%5Csum_%7Bk%3D1%7D%5EK%20%5Cmathbf%7Bw%7D_k%5Cmathbf%7Bm%7D_k%5Cmathbf%7Bx%7D(p_0%2Bp_k%2B%5CDelta%20p_k)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
CxHxWである入力画像xの座標p0における畳み込みを示しています。ただ表記が統一されていない気がするため少し訂正します。Kはカーネルのパラメータ数、kはカーネル内の各マス、pkは画像中の座標です。カーネルの重みwkは入力の座標に寄らず共通した値を持つ静的な重みですが、DCNではこれに対して重み付ける座標を変化させるΔpと入力に応じてxを重み付けるmを持ちます。これにより、写っている物体の形状やスケールに合わせて受容野や重みを適応的に変えることができます。各座標p0に依存しているため、上式では引数を表示すべきです。xを畳み込む事で2xHxWのΔp、1xHxWのmを学習・出力しています。
%3D%5Csum_%7Bk%3D1%7D%5EK%20%5Cmathbf%7Bw%7D_k%5Cmathbf%7Bm%7D(p_0)_k%5Cmathbf%7Bx%7D(p_0%2Bp_k%2B%5CDelta%20p(p_0)_k)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
DCNv3はこれに対して以下の変更を加えています。
- depth-wise畳み込みとpoint-wise畳み込みに分離し計算コストを削減
- グループ畳み込みにより異なる視点で変形・重み付け
- 各m(p0)kをカーネル単位で正規化し学習を安定化
Separable Convolution
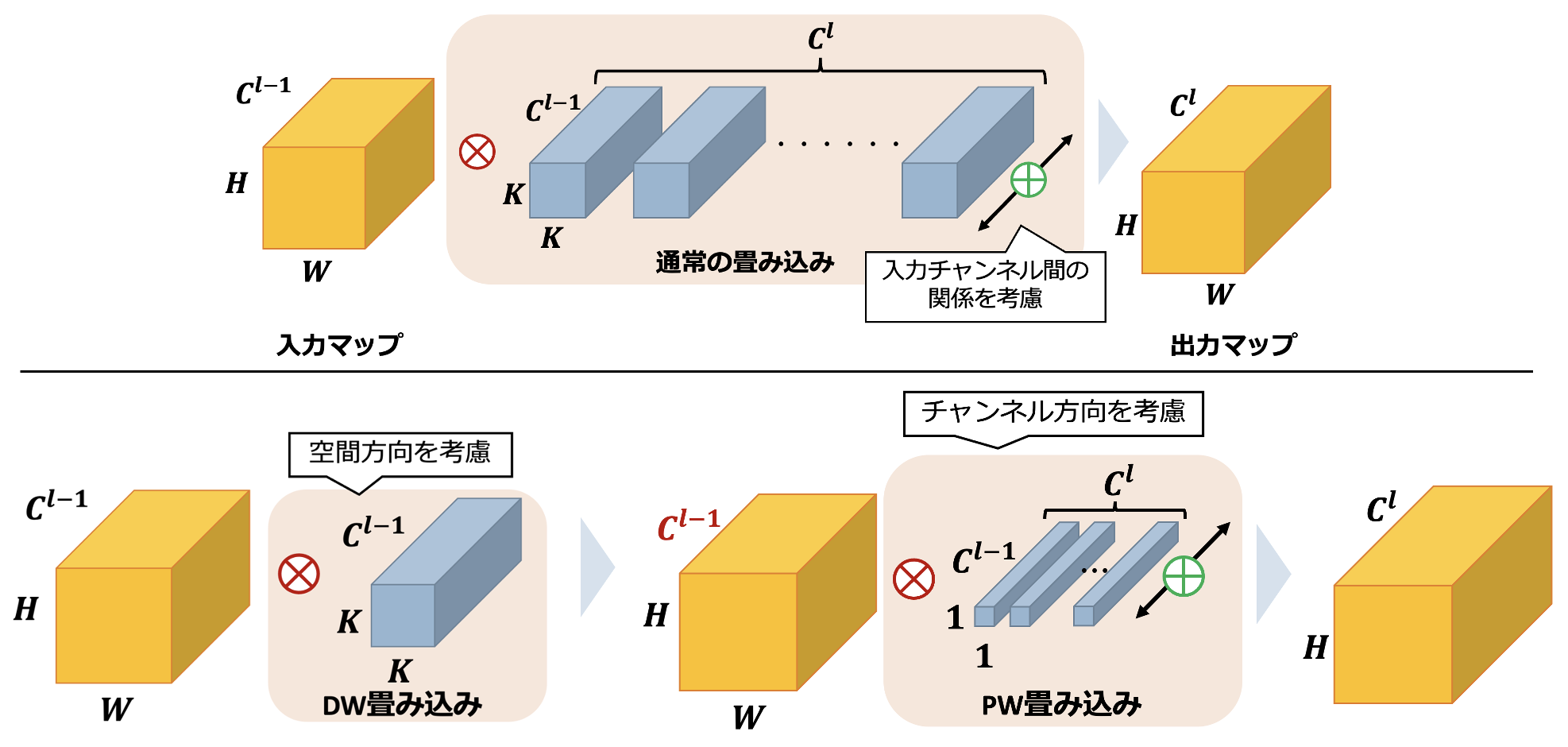
畳み込みの分離(Separable Convolution)のイメージ図を示します。lはレイヤーです。通常の畳み込みは入力の空間方向(各座標)・チャンネル方向を一度に畳み込み、それをClチャンネル分演算しています。それに対し、Separable Convolutionは出力マップのサイズを保ったまま空間方向の畳み込みとチャンネル方向の畳み込みに分離することでパラメータを大幅に削減しています。空間方向のみを畳み込むdepth-wise畳み込みの後、チャンネル間のみを重み付けるpoint-wise畳み込みを行うことで実現しています。
マルチグループ畳み込み
カーネルの重みwkはチャンネル毎異なる視点を持っていますが、mkやΔpkは入力画像の位置で決まり全チャンネルで共通した値を持ちます。DCNv3では複数の畳み込みのグループを構築し、それぞれで異なるmk・Δpkを持たせることでMulti-Head Self-Attention(MHSA)のように異なる依存関係を捉えられるようにします。G個のグループのうち各グループをgとしてDCNv3は次の式で表されます。G個分チャンネルが増えているわけではなく、各グループ毎の入力チャンネルをC'=C/Gと分割しているようです。式中のxgはそれを表しています。
%3D%5Csum_%7Bg%3D1%7D%5EG%5Csum_%7Bk%3D1%7D%5EK%20%5Cmathbf%7Bw%7D_g%5Cmathbf%7Bm%7D(p_0)_%7Bgk%7D%5Cmathbf%7Bx%7D_g(p_0%2Bp_k%2B%5CDelta%20p(p_0)_%7Bgk%7D)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
動的重みm(p0)kをカーネル単位で正規化
DCNv2ではmが各座標毎[0,1]の値を持つようsigmoidが適用されています。しかしこれではカーネル内の重みの和が0~Kまで大きく変化してしまい、学習が不安定になってしまうことが指摘されています。そこでDCNv3ではカーネル単位で重みの和が1になるようsoftmax関数を採用しています。これにより学習の安定化が望めます。
InternImage
DCNv3の優位性を把握したところで、InternImageを構築していきます。重要なのはStem・downsampling・stageの各ブロック、そしてそれらのハイパーパラメータの決定方法です。InternImageは通常のCNNと異なり全体としてViTの構造を参考にLayer NormalizationやFFN、GELUといった構造を採用します。この機構は様々な画像処理タスクで有効であることが示されています。
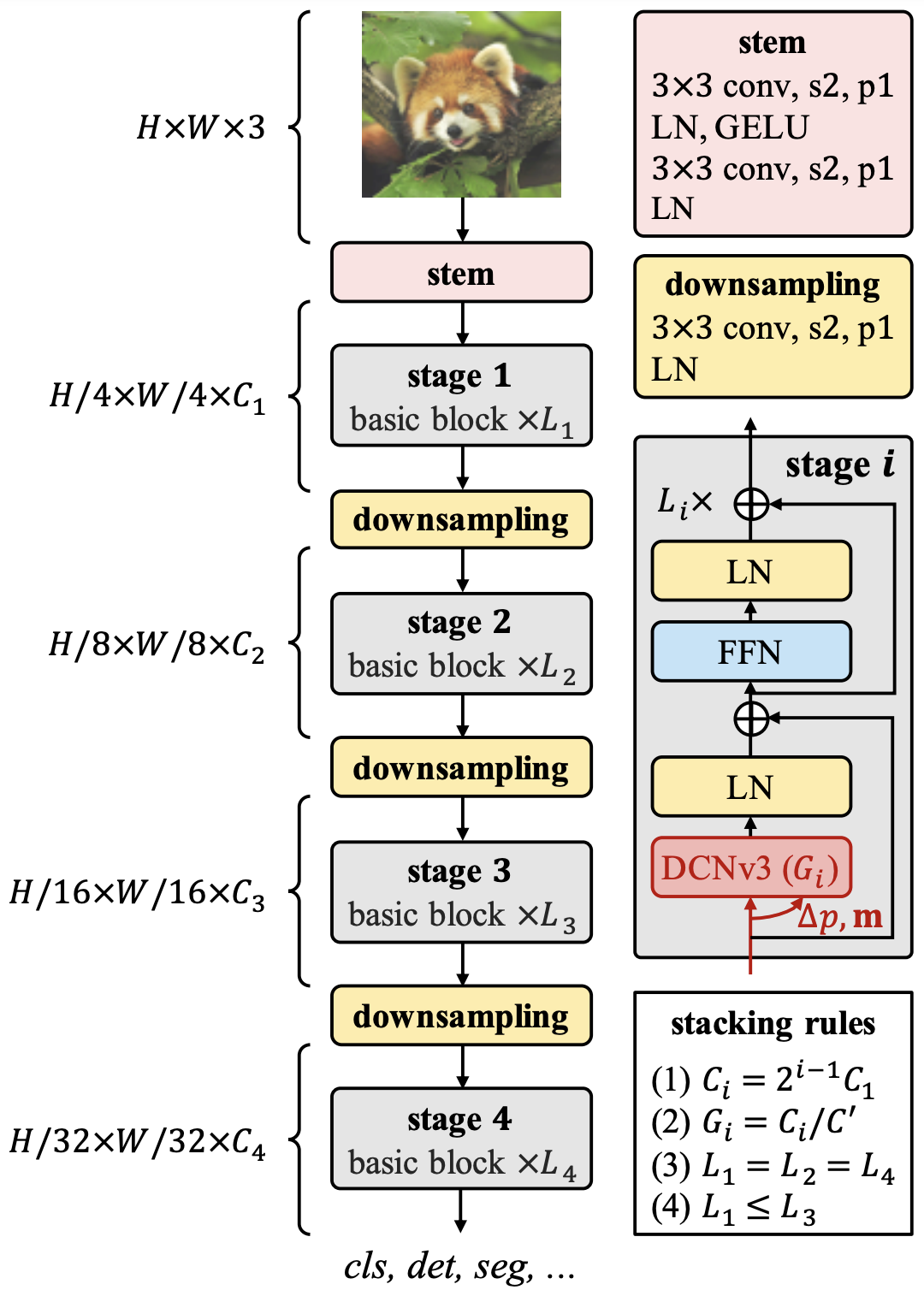
Stem・Downsampling・Stage
DCNv3があるstageの前にStemを適用します。Stemは3x3の畳み込みとLN、GELUから成ります。RepLKNetも同じような構造を持っており、序盤に局所的特徴を網羅的に抽出する必要があるという説明をしています。この段階で解像度は1/4に下がります。downsamplingはその名の通り2倍にダウンサンプリングするためのブロックです。各stageの間に挟まれます。StageはInternImageの核であるDCNv3を含みます。図にあるのは最も素なベースブロックであり、これを積み重ねたのが各Stageになります。
アーキテクチャ
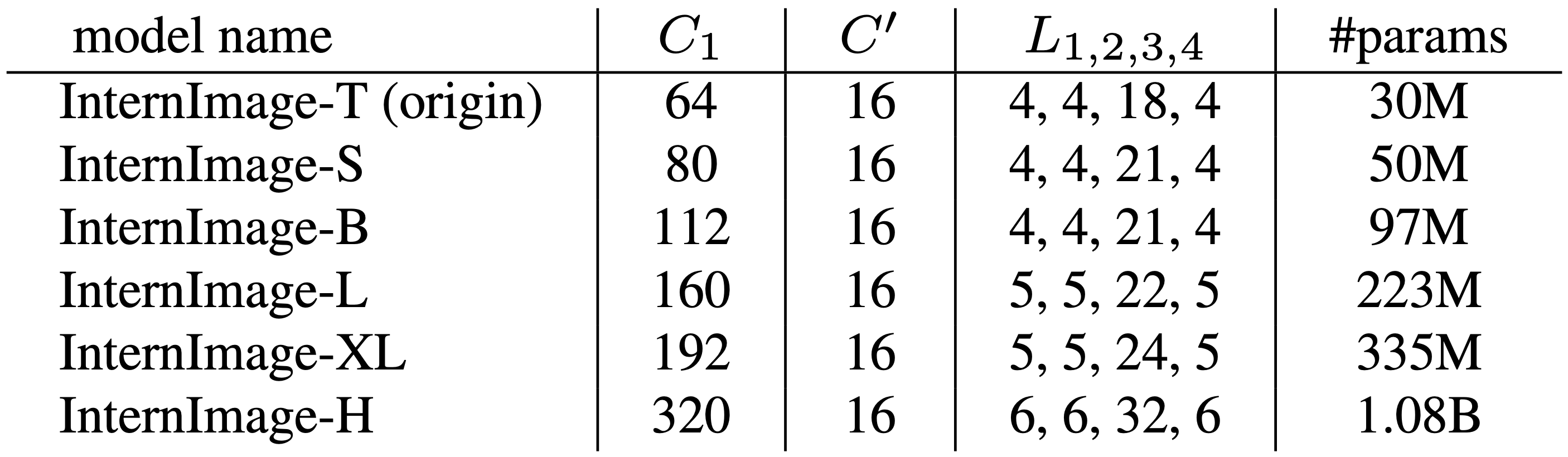
Stemの後はStageとDownSamplingを4回重ねます。各ステージiにおいてチャンネル数Ci、ブロック数Li、そして畳み込みのグループ数Giがあります。12個のハイパーパラメータでは探索範囲が広すぎるため、ここで3つのルールを設け構造やスケーリングを決定します。
- チャンネル数は最初のステージC1を基準に2倍に増えていく
- グループ数は各ステージのチャンネル数Ciと各グループのチャンネル数C'で決める
- ステージ毎のブロック数はステージ1,2,4が同じ数で、ステージ3が大きな値を持つ「AABA」パターン
こうすることでモデルのハイパーパラメータは(C1,C',L1,L3)で決定します。
スケーリング
(C1,C',L1,L3)=(64,16,4,18)の計3000万の学習パラメータのモデルをInternImage-Tとしてスケーリングさせます。深さD(3xL1+L3)とチャンネル数C1をα=1.09,β=1.36,Φで増加させます。
![]()
このようにして得られたInternImageの各スケールは下の表の通りです。-Tから-XLはConvNextと同等の計算複雑性を持ち、最も規模の大きいInternImage-Hは10億個のパラメータを持ちます。
実験
実験ではImageNetの画像分類、それを事前学習としたCOCOの物体検出とADE20Kのセグメンテーションの実験で優位性を実証しています。それぞれの実験でCNNベース・VITベースのSoTAモデルを様々なスケールで比較しています。アブレーションが補足資料に載っているそうなので細かな機構の優位性が知りたい方はそちらもみてみると良いでしょう。
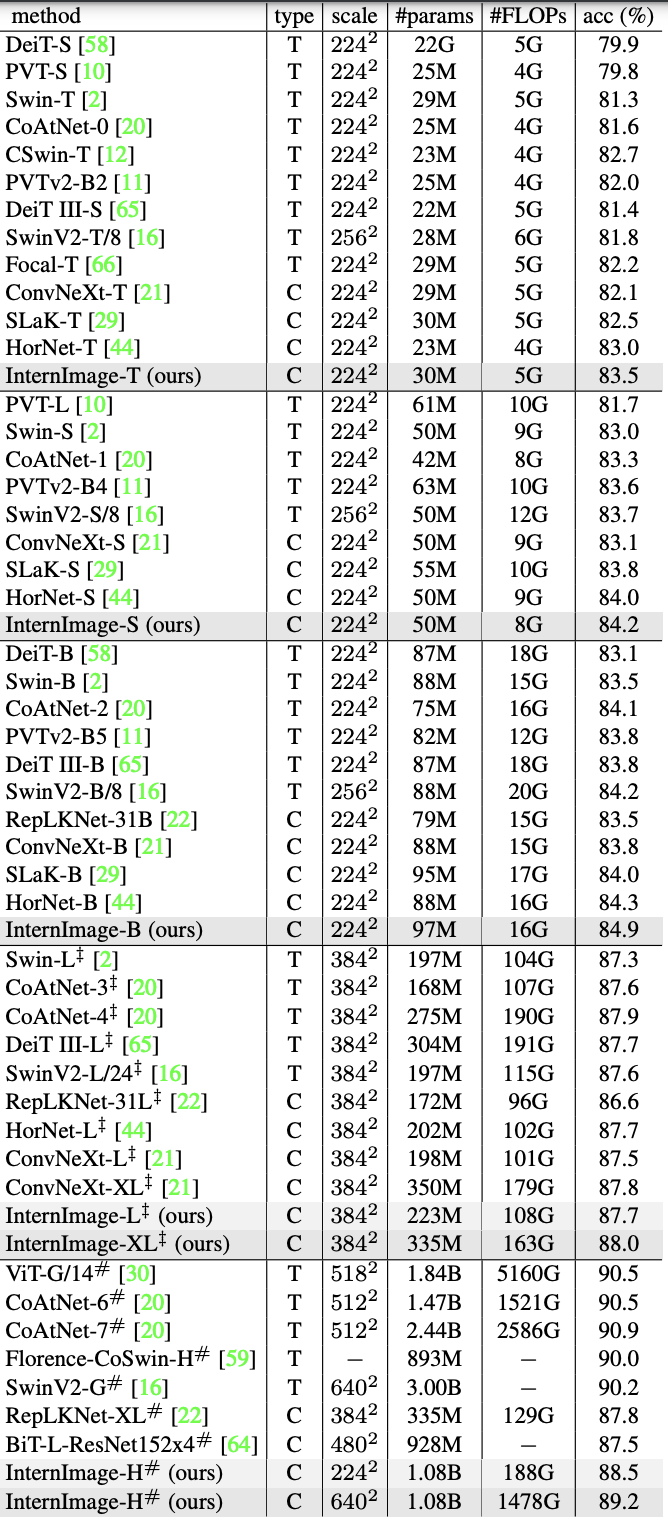
分類タスク(ImageNet)
比較するモデルのスケールに合わせた公平な比較を行うために、-T/S/BはImageNet-1Kの130万枚を300epochs、-L/XLはImageNet-22Kの1420万枚を90epochsで事前学習したものを30epochsでfine-tuningさせています。大規模な-HについてはM3I事前学習を採用しています。これは教師あり・弱教師あり・教師なしの各事前学習を統合させ一段階の事前学習だけで理想的なパラメータを獲得するもので,Laion-400M・YFCC-15M・CC12Mという合計で4億2700万枚のデータを30epochs学習させています。その上でImageNet-22Kと-1Kそれぞれで30epochsのfine-tuningさせています。
結果が次の表です。typeはViT(T)かCNN(C)か、scaleは入力サイズを表しています。モデルのスケール毎みるとそれぞれCNNベース・ViTのSoTAモデルと同等かそれ以上の精度を達成しています。InternImage-Tは83.5%とトップ、InternImage-S/BはハイブリッドViTであるCoAtNet-1も上回る精度を出しました。InternImage-XLは88.0%、InternImage-Hは89.2%を達成し、同じ大規模データで学習した従来のCNNモデルより向上し、大規模ViTのSoTAモデルとの差も1.0程度に縮めました。この結果から先に定めたスケーリングと大規模データセットの学習の有効性が実証されました。
物体検出(COCO)
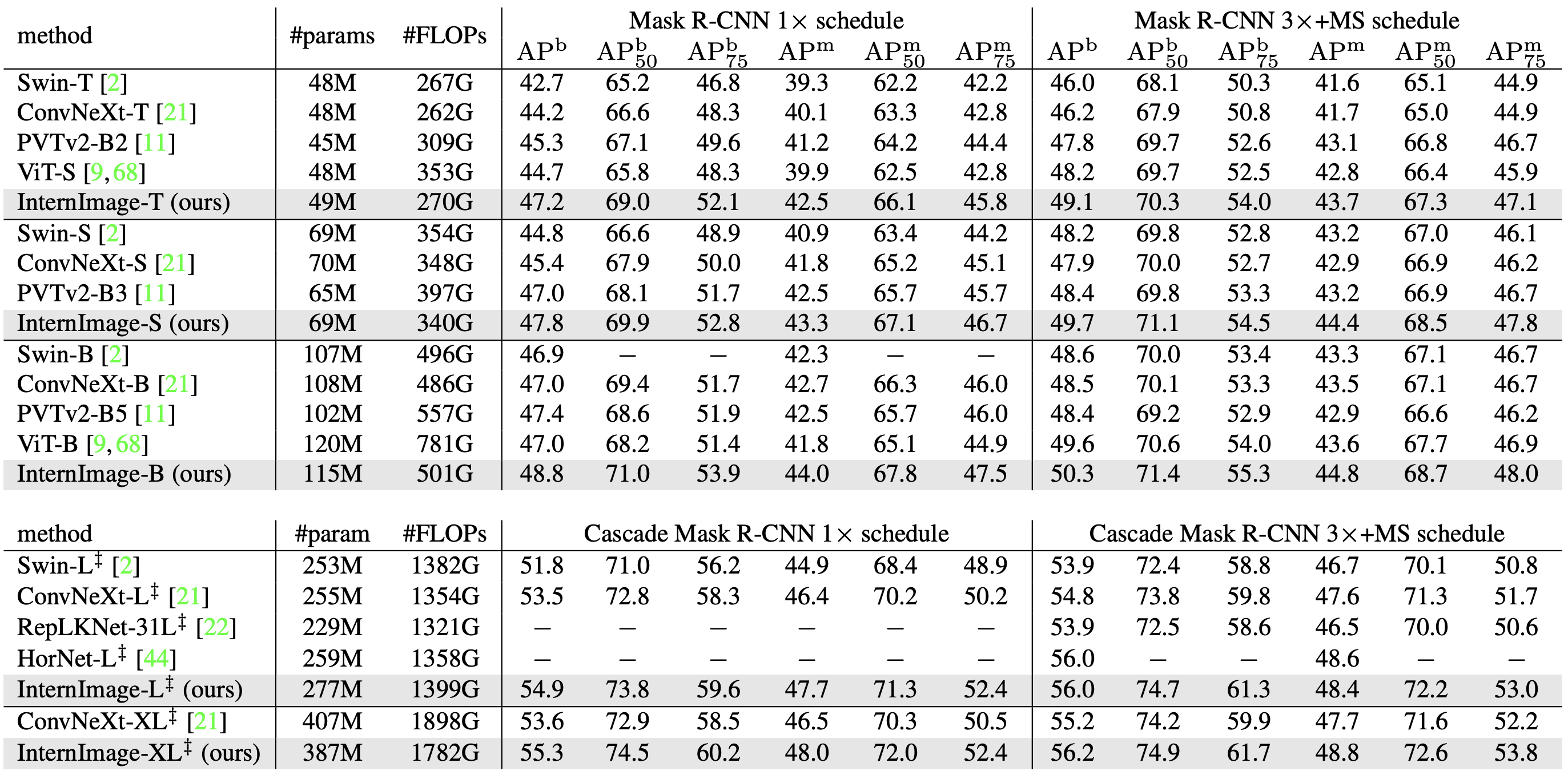
COCOでは2つの実験で精度検証をしています。1つはMask R-CNNとCascade Mask R-CNNを検出器としたバックボーンの比較実験、もう1つは各バックボーン毎様々な検出器を採用した時の比較実験です。それぞれ先のImageNetを事前学習したものをfine-tuningさせています。
・Mask R-CNN/Cascade Mask R-CNN
Mask R-CNN・Cascade Mask R-CNNそれぞれにおいて12epochs(1x)と32epochs(3x)を学習させた時の精度比較が次の表です。3xの学習はマルチスケールで学習させています。
box-AP(APb):Mask R-CNNでは同等のパラメータ数の元でInternImageが大きく上回っています。1xではInternImage-TのAPbがSwin-Tより4.5高くConvNeXt-Tより3.0も高い結果です。3xで学習したCascade Mask R-CNNではInternImage-XLがAPb56.2を達成し、ConvNeXt-XLを1.0上回っています。
mask-AP(APm):1xの学習ではInternImage-Tが42.5を達成しSwinT・ConvNeXtを上回っています・最高精度はInternImage-XLのCascade Mask R-CNNで48.8APmを達成しました
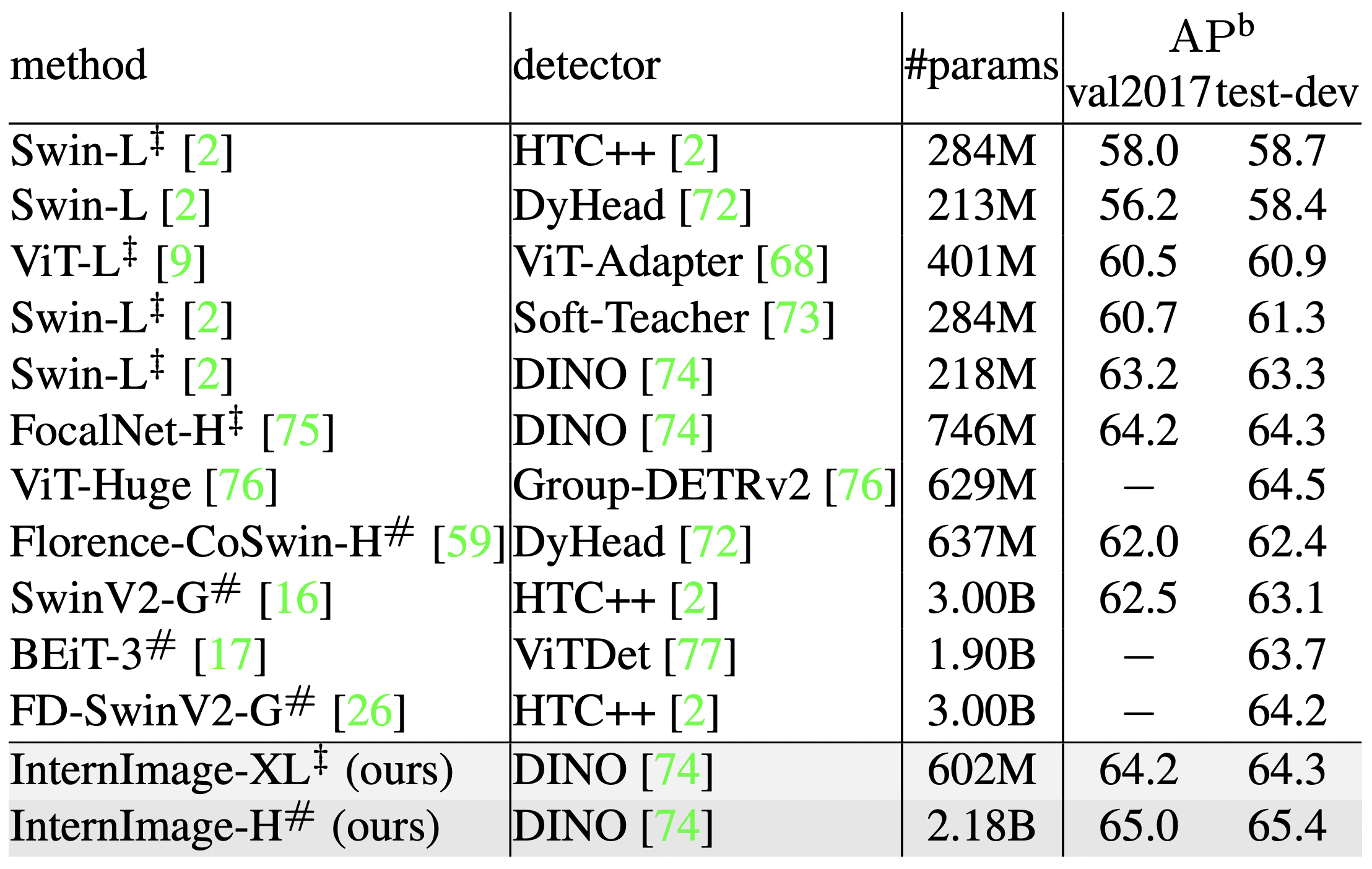
・SoTAモデル
更なる精度向上のために様々な検出器を採用しSoTAモデルとの精度比較をおこなっています。この検証ではObjects365データセットを26epochs、COCOを12epochs学習させています。その結果DINO検出器を採用したInternImage-XL/HがCOCOデータセットのval2017とtest-devにおいて65.0APbと65.4APbという最高精度を達成しました。しかも既存のSoTAモデルより27%少ないパラメータで達成しており、InternImageが検出タスクにも有効であることが示されました。
物体検出(COCO)セマンティックセグメンテーション(ADE20K)
検出と同様にImageNetの事前学習の上で、UperNetをモデルとしてADE20Kのセグメンテーションタスクを行っています。InternImage-Hはより高度なモデルMask2Formerのバックボーンに採用しています。
結果としてInternImage+UperNetは一貫して既存手法を凌駕する性能を示しました。ほぼ同じパラメータ数とFLOPsでInternImage-Bは50.8mIoUを達成し、ConvNeXt-BやRepLKNet-31Bといった強力なCNNモデルを上回りました。またマルチスケールではInternImage-Hは執筆現在最高精度の62.9mIoUを達成し、2位のBEiT-3を上回りました。
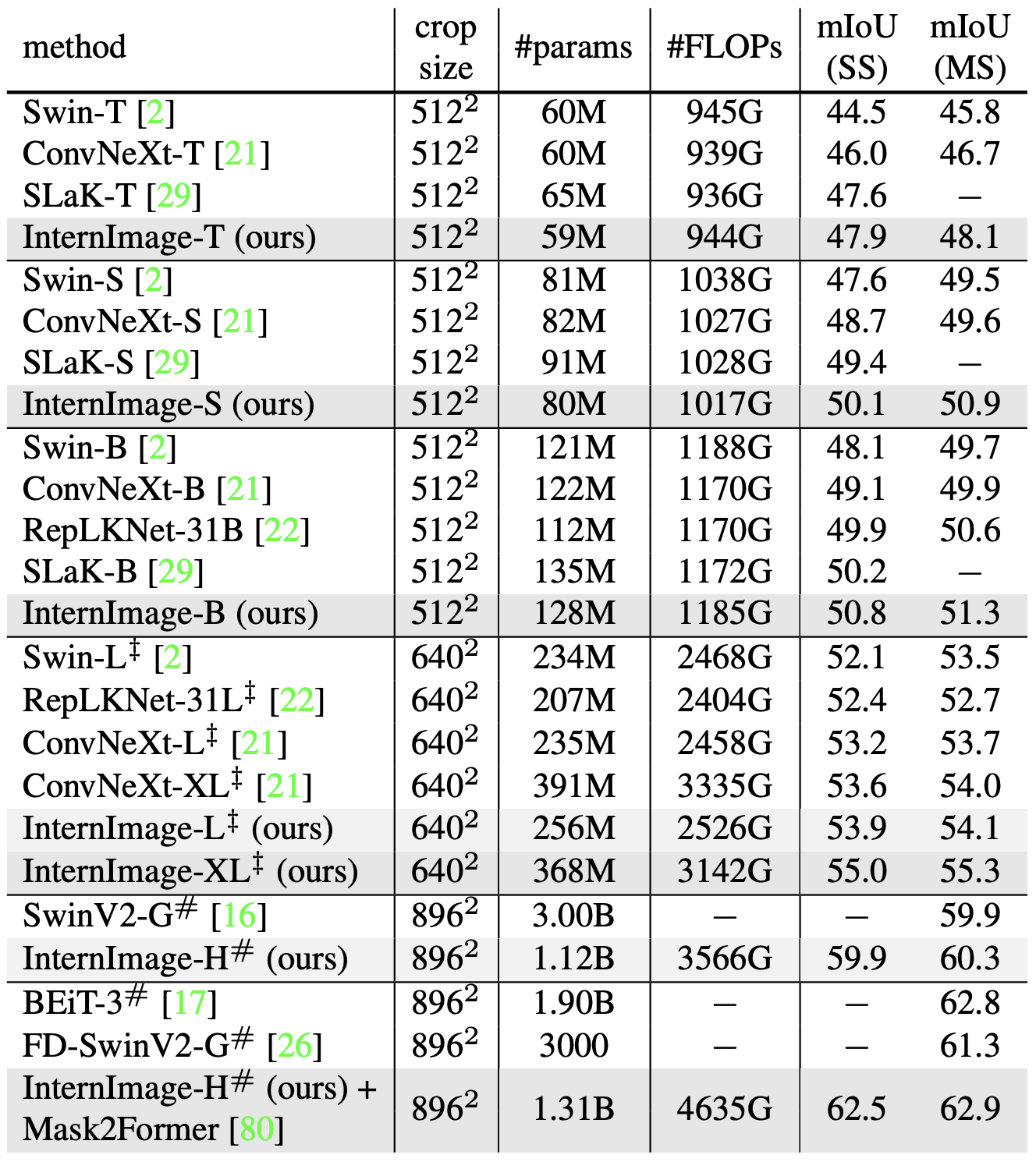
これらの結果はCNNベースの基盤モデルが大規模データの恩恵を受けることができ、ViTベースモデルに大きく迫っていることを示しています。
まとめ
今回はViTを凌駕する大規模CNNモデルInternImageを紹介しました。基盤モデルの要件を見たすためDCNv2を改良したDCNv3を提案し、ベースブロックに用いています。ImageNet・COCO・ADE20Kと広範なベンチマークの実験により、InternImageは大規模データで学習されたViTと同等以上の精度を得られることが実証され、CNNが大規模モデルの選択肢として大きな可能性を持つことを示しました。課題としてDCNベースの手法は処理が重いことを挙げています。これからの発展が楽しみです。






この記事に関するカテゴリー






